「プログラミング技術の変化で得られた知見・苦労話」という Qiita Advent Calendar 2020 への参加記事です。2000 年から 2020 年現在までのプログラミング言語、フレームワークや開発環境などの変遷や経験を振り返り、そこから感じたことを書いています。
出来事を書いてから知見をまとめる書き方だと長ったらしくて分かりにくい「単なるおっさんの昔話」な記事になってしまうので、逆に知見を見出しにしてなぜそう考えるのかを記述する形式をとります。
目次を見て太字のところだけを読めば知見が分かるわけですが、結論だけ見ると、ある程度経験のあるエンジニアにとっては「そんなこと分かってる」という程度です。
中身をちゃんと読むと「おっさんの昔話」が書いてあります。
長い記事ですので、年末年始の暇な時にでも読んでもらえれば。
開発の効率化
有名な「銀の弾丸はない」という言葉の通り、ハードウェアの進化スピードに対してソフトウェアの生産性は急速には上がったりしません。
しかし確実に開発効率は上がる方向に進んでいます。
2001 年にはアジャイルソフトウェア開発宣言が出され、開発手法によって対応しようとする動きが活発化していました。
これはプログラミング技術より上のレベルの、開発プロジェクトのレベルの話です1。
プログラミング技術という下のレベルの話であれば、開発効率をあげるための手段の1つとして、ハードウェアの進化をソフトウェアの生産性に貢献させるというのは自然な流れでしょう。
一言で言うなら「コンピューターにできることはコンピューターにやらせる」ということです。

DRY
設定より規約を
2005 年頃、Ruby on Rails (以下 Rails) が一気に注目を集めました。
15 分でブログを作るデモ、「Java の10倍の生産性」という(誇張された)謳い文句はセンセーショナルなものでした。
Rails の思想の根底にあるのは DRY (Don't Repeat Yourself) です。
当時の Java の Web フレームワークは、いわゆるフルスタックフレームワークではなく、ビュー部分にはこれ、DI コンテナにはこれ、ORM にはこれ、というように複数を選択して組み合わせていました。
これは Java というオープンな技術の利点であり、柔軟性が高く、選択肢が豊富にあること自体は良いことだとも言えます。
ただ柔軟性が高いがゆえに設定を多く書く必要がありました。
当時はまだ Java にアノテーションが導入されておらず、その設定を XML で書かなければいけないという苦行。
XML は HTML を汎用的かつ厳格にした 2「コンピューターに解読しやすく、しかも人間にも読み書きできる」規格として、2000 年代前半頃に一気に普及した技術です。
でもね。「人間にも読み書きできる」けど、「読み書きしやすい」わけじゃないんですよ。
「コンピューターに解読しやすい」ので IDE によるサポートが期待されていたわけですが、これを手書きとなるとメンテナンス性が悪いのなんの。
Rails はそのアンチテーゼとして生まれたのだと思います。
設定で変更できる柔軟性はある程度あってもいいけど、「規約」を決めておいて、それに従っていれば設定を書かなくてもいい。
これは最近の JavaScript 系の開発で使われる Prettier(フォーマッタ)とか Jest(単体テストツール)とかの zero config にも繋がっていると思います。
「デフォルト設定がいい感じになっていて、設定書かなくても使える」というものですね。
Rails の「設定より規約を」はもっと強力で、規約に従っていれば、よく書くようなコードは Rails が自動生成してくれます。
メタプログラミング
Rails が自動生成するものには
- CLI コマンドで雛形を生成する
- Rails が起動時に内部でコードを動的に生成
の2種類があります。
前者はスニペットなどと同様に単なる雛形を生成するだけのもので、全く目新しいものではありません。
当時の Rails のイノベーションは後者にあります。
プログラムを生成するプログラムを書くことを メタプログラミング と言います。
この考え自体は古くからあります。例えば Lex や YACC です。
Lex や YACC はパーサプログラムを生成するツール3で、独自の記述方法で書かれたソースコードから C 言語ソースコードを生成します。
C++ になるとテンプレートプログラミングにより、C++の文法でメタプログラミングができます。
これにより少ない記述量で多くのコードを自動生成させることができますが、自動生成されるのはあくまでコンパイル時です。
一方、Ruby は動的言語です。
Ruby のメタプログラミングの仕組みは、実行時にもコードを自動生成させて実行することができます 4。
Rails ではこれが最大限に活かされています。
2005 年頃 Java で使っていた ORM ライブラリに Hibernate というのがあります(今もあります)。
アプリ側のクラスと RDB 側のテーブルをマッピングするわけですが、そのマッピングの設定を XML で書く必要がありました。
そりゃまぁ SQL を書かなくてもオブジェクトをそのまま保存したり取得したりできるので、インピーダンスミスマッチ5は解消され、ソースコードはシンプルになるかもしれません。
しかし結局は面倒な設定ファイルの記述をしなきゃいけないので、あまり楽になった感じがしないわけです。
Rails の場合はクラスとテーブルとのマッピングは規約に従っていれば設定を書かなくても済みます。
しかもクラス側のコードは中身を何も書かなくても済みます。
これは Rails が動的メタプログラミング6を使って、テーブル構造からモデルクラスを動的に自動生成してくれるからです。
コンピューターにできることはコンピューターにやらせましょう。
IDE
自分はエディタは Vim 派ですが、もう Vim を直接使ってコードを書くことはありません。
IDE が強力すぎるからです7。IDE に Vim キーバインドの拡張を入れて使います。
Vim 使ってて良かったと思うのは、大抵の IDE には Vim 拡張があることです。Emacs など他の有名エディタ利用者も同様でしょう。
Java の普及は IDE による開発支援に大きく支えられていたように思います。
リファクタリング支援
クラス名を変えたり、メソッド名を変えたりするときに、一気に関係する所が変換されます。
ファイル名を変更すると、そのファイルをインポートしている箇所が全部変更されます。
たったこれだけのことで、とても助かります。
メソッドの中身のあるコードブロックを別メソッドや関数に分離したりするのも地味に便利です。
最近は VSCode で TypeScript を書くことが多いですが、リファクタリング支援機能がしっかりしてるのでとても助かります。
コンピューターにできることをコンピューターにやらせるためには、 コンピューターが扱いやすい言語仕様である必要があります。
- 言語仕様が複雑すぎないこと(ダメな例: C++)
- 型情報などコーディング支援に必要な情報を多く与えられること
とはいってもプログラミング言語は人間が読み書きしやすいように作られたものです。
あくまで 人間にとって扱いやすく、その上で出来るだけコンピューターにも扱いやすい言語仕様 が求められます。
型チェック
静的型付けのメリットは以下でしょう。
- コンパイラの最適化によるパフォーマンス
- コンパイル時や IDE 上でのコードの検証
- 保守性
古くからある静的型付け言語の代表 C 言語に型情報がある1番の目的は、コンパイラに型情報を与えることで実行バイナリの最適化を行うことです。上記の 1 ですね。
その後登場した C++や、それをもっと簡略化した Java、Microsoft が Java の代わりに作った C# あたりが前世代の静的型付け言語でしょうか。
最近の静的型付け言語隆盛の理由は 2 や 3 になっています。TypeScript が良い例で、1 の理由がありません。
2000 年代前半から 動的型付け言語は Web 開発で人気の言語でした。2000 年頃は Perl が主力でしたが、徐々に PHP へと移っていきました。2005 年頃 Rails の登場により Ruby が人気になると、動的型付け言語の人気はさらに高まったように思います。
動的型付け言語の利点は開発スピードと、開発の容易さです。
まず何と言ってもコンパイル時間が要りません。型情報がなく、プログラミング初心者にも読みやすく書きやすく実行時エラーも分かりやすくとっつきやすいです。
Rails 登場により動的型付け言語の利点である開発スピード、開発の容易さが、さらに印象的なものになったわけです。
信頼性やパフォーマンス、保守性が重視されるエンタープライズでの業務システム開発では Java や C#、開発スピードとコストが重視される新規 Web サービス開発では PHP や Ruby といったように大まかに棲み分けができていました。
しかし 2010 年代前半頃でしょうか、Haskell や OCaml といった関数型言語を学ぼうといった機運が盛り上ったあたりから潮流が変わりました。
Swift, Kotlin, Go, Rust, TypeScript ... 8
最近登場した主要な言語は静的型付け言語ばかりです。
むしろ PHP や Python にも型指定が可能になっているという有様です。
この流れには Haskell や OCaml が持っていた大きな2つの要素があると思います。
- 型推論
- より厳密な型
です。
型推論により、面倒な型の記述を省略することができるようになりました。
単に記述量が減るだけでなく、見た目もスッキリしてロジックの把握に集中できるため可読性も上がります。
一方で型情報はしっかり持っているので、IDE の支援機能を使えばカーソルを当てるだけで型情報が分かったりします。
型推論のおかげで、動的型付け言語に対するデメリットが大幅に軽減された わけです。
一方で厳密な型によってコンピューターでできることが増え、動的型付け言語では実行時まで気付けないコードの間違いに実行前に気付けるようになります。コンパイル時のチェック以上に、特に IDE 上でのチェックが大きいです。
早くに間違いに気付ければ、それだけ開発効率も上がります。
開発効率が良いという理由で人気だった動的型付け言語ですが、その開発効率で逆転されてしまったわけです。
それに加えてプログラマの意図を伝えられる情報量が増えるためコードが理解しやすくなり、変数に入りうる値の想定が確実に制限されるためデバッグもしやすくなり、保守性が大幅に向上します。
JavaScript という動的言語のプログラミングでさえ、TypeScript という静的型付け言語で行うようになってきています。以下の GitHub の人気言語のグラフで TypeScript が 2017 年から 2020 年にかけて一気に伸びてきています。
静的型付けが1つのトレンドになっていると言えるでしょう。
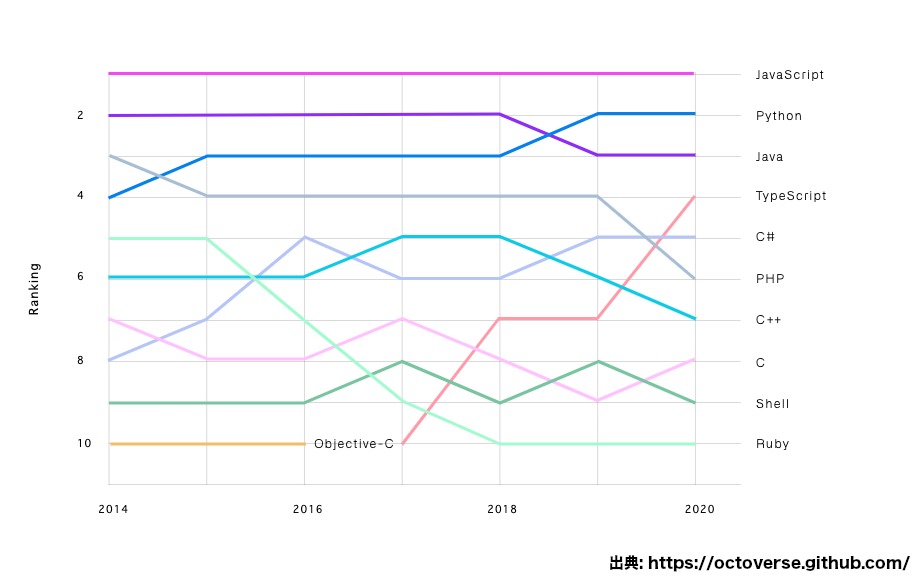
静的型付けの欠点としては、適切に型を利用できるようなるには相応の学習コストがかかるため、初心者向きではないということです。
プログラマが足らない状況でどんどん初心者が流入している市場ですので、まだまだ動的型付け言語は一定の人気を保ち続けそうです。
フォーマッター / リンター
ソースコードの見た目は一定の法則に従っていないと読み辛いです。
/* コンマの後とか波かっこの前とか空白入れてくれよ〜 */
void f(int arg1,int arg2){
if(arg1==0){
/* インデントなんでここは2なんだよ! */
/* 略 */
} else {
/* あれ?elseの時はちゃんと波括弧の前後に空白入れてくれるのね? */
/* 略 */
}
}
自分は空白が入る場所に空白が入っていないと気になって速攻で直してしまうタイプでしたが、気にしない、というか気づかない?人は結構見かけます。
そういう「コードの美しさを意識しない人」はプログラマに向かないとか言われてましたね。
コードの見た目を揃えるために、チームでコーディング規約を作って、その中で「インデントは空白文字で4」とか「if と () の間には空白を設ける」とか、書いていたりしたわけです。
そんなの全部覚えて、意識しながらコード書くって辛くないですか?まぁ多くは「自分の中での標準的な書き方」と同じだったりするので、その規約の違う部分だけを覚えるわけですが。
あと、コードレビューでフォーマットの規約に合っていないことを指摘する時間の無駄さよ。
でも、もうそんなことはどうでもいいです。そんなことはコンピューターに任せてしまいましょう。
今は大抵の言語にフォーマッターが用意されています。さらに IDE の方で保存時にフォーマットしたりしてくれます。
Prettier とか凄いです。
Prettier のようにフォーマッターがやりすぎると「そこで改行して欲しくないんだけど!」という自動フォーマットになったりしますが、チマチマと手作業でフォーマット直す手間を考えたら、そんなことには目を瞑って、コンピューターに任せてしまいましょう。
プログラミング言語の文法上は許されているけれど、例えば「こう書いた方が安全」だといった書き方のチェックを行うのがリンターです。
こういったこともチームでコーディング規約を決めておくわけですが、これも全部覚えて常に意識しておくのは大変です。
構文チェックはコンピューターにやらせてしまいましょう。
さらに手動で実行しなくても IDE でコーディング中に違反に気付けるようにしておくべきです。
リンターもフォーマッターも C 言語の時代からあるものです。まさかこの時代になって使っていないとか、あり得ないですよね?
Rust のメモリ管理
C/C++ でプログラムを組んでいると、突然クラッシュしてどこで何が起こったのかサッパリ分からずにデバッグに苦労するということが起こります。
C/C++ は速度最優先の言語なので、メモリを直接扱えるために、メモリ違反でクラッシュするわけです。
大学の講義で学んだプログラミング言語が C 言語だったわけですが、プログラミング初心者に最初に教えるべき言語じゃありません。
脱落者続出9で、プログラミングに苦手意識を持つ人を量産してました。
しかしとうとう、C/C++ 並の速度を持ちつつ、コンパイル時に コンピューターにメモリ違反をチェックさせる 言語が登場しました。Rust です。
AI
「コンピューターにできることはコンピューターにやらせる」ことによる開発の効率化の話をしてきましたが、「人間には簡単にできるけどコンピューターには難しい」ことをやれる技術が AI です。
Visual Studio InteliCode や DeepCodeなど、既に AI を使ったプログラミング支援ツールが登場しています。
将来的には**「コンピューターにできること」がさらに増えていきそう**です。
インフラ構築の自動化
2000 年には既に日本に VMWare が入ってきており、ハードウェア仮想化による仮想マシンが登場していました。
LAMP にしろ Java にしろローカル開発環境は Windows 上でも構築できましたが、仮想マシンがあることで Windows ローカルマシンで本番環境と同じ Linux を動かすことができるようになりました。
ただ、この頃は仮想マシンに Linux をインストールして、その設定を行って、Apache や PHP などをインストールして、といったサーバー構築作業を本番環境と同じように手で行っていました。
2008 年に IaaS である AWS の仮想マシン EC2 が正式版となります(PaaS も、同じ年に GAE (Google App Engine) 、前年に Heroku が登場しています)。
その後 Chef や Ansible といった Infrastructure as Code (IAC) な構成管理ツールが登場します。
これにより、インフラの構築は環境構築の設定を書いてコンピューターにやらせることができるようになりました。
2013 年には Docker が登場し、仮想マシンより軽量なコンテナ技術が一気に普及します。翌年にはもう Kubernetes (K8s) が登場しています。
今やローカル開発環境は Docker (docker-compose) を使って簡単に用意できるようになりました。
本番環境では K8s でオーケストレーションすることもできますし、Fargate や Cloud Run など、Docker コンテナ作ってデプロイすればサーバーレスなサービスを利用できるようになっています。
(番外)フロントエンドもサーバーサイドも同じ言語で
「コンピューターにできることはコンピューターにやらせる」には関係ないのですが、開発の効率化に関係するの番外として記載します。
現在自分が最もよく使っている言語は TypeScript です。
Node.js が登場したおかげで、フロントエンドもサーバーサイドも同じ言語で開発できるようになりました。
ブラウザは JavaScript しか理解してくれませんから、それまではフロントエンドは JavaScript でサーバーサイドは他の言語で開発する必要があり、そのコンテキストスイッチが結構負担に感じていました。
どちらも同じ言語で書けるのは素晴らしいです。
両方に TypeScript を使うようになって、開発効率は上がったと感じています。
また Node.js は Java などのコンパイル言語ほど高速ではないですが、ブラウザ戦争のおかげで JavaScript の実行速度はインタープリタ言語の中では相当高速です。
技術のコモディティ化
開発の効率化とも密接に関係してきますが、プログラミング技術の流れの1つとして技術のコモディティ化10があります。
現在はクレジットカードさえあれば、あらゆるものを借りることができます。
こうした発展には、以前よりもスタートアップの実験が簡単になったという重要な意味があります。
スタートアップとは実験です。現代の企業は想像できるものなら何でも構築できます。
したがって、答えるべき質問は、もはや「構築できるか?」ではなく「構築すべきか?」なのです。
(「Running Lean」のエリック・リースによる前書きより)
新しいサービスを、誰でも、素早く構築できるように、技術は一般化していきます。
フレームワーク
2000 年代前半、PHP で Web サイトを構築するには、1ページ1ファイルというのが一般的でした。一方 Java では MVC フレームワークの Struts がほぼデファクトになっていきました。
その頃に PHP で MVC をやろうとして、自作の簡易フレームワーク(というほどのものでもない)を作った覚えがあります。
全てを index.php で受け取るようにして、http://example.com/?action=home のように action 部分に指定されたもので分岐します。内部で actions/home.php を読み込んでそれを実行し、戻り値に表示する View の指定と表示内容が返ってくるので、views/home.php が読み込まれ、レンダリング結果を返すという数十行程度のものです。
ちなみにユーザー側の URL http://example.com/home が http://example.com/?action=home になるように Apache 側で変換していました。
MVC やる程度のことでさえ、自作していたわけです。
さらにセキュリティに関しても、どのような攻撃があるのか理解した上で、常に注意して意識しながらコーディングする必要がありました。
2000 年前半の Struts の普及、2005 年 Rails 登場の後は、その他の言語(PHP 含む) でもフレームワークを使うのが当たり前になっていきました11。
今ではセキュリティに関してもフレームワークが多くの面倒を見てくれます。
初心者が Web サービスを作る際に、SQL インジェクション対策のためにエスケープしたり、XSS 対策のために HTML をエスケープしたり、CSRF 対策したり、といったことは意識しなくても大丈夫なようになっています。
ライブラリのように一般的に使われる機能を提供するだけでなく、一般的なやり方や設計を枠組みとして提供するフレームワークが登場したことで、「フレームワークの使い方さえ覚えれば、それ以外の詳細は知らなくても Web アプリケーションが作れる」ように、Web 開発は一般化していきました。
PaaS, SaaS, MBaaS, サーバーレス
さてインフラ周りについて、またおっさんの昔話をしましょうか。
2000 年代前半、社員数人しかいないベンチャー企業にいました。自社に専用回線引いて、サーバーラックにルーターと複数台のサーバーマシンを用意し、ケーブルを配線して、そのサーバーに Linux をインストールして設定を施し、当然ネットワーク設定やらファイアーウォール設定やらを行って、
- DNS サーバー (BIND)
- メールサーバー (Sendmail / Postfix)
- Web サーバー (Apache & PHP)
- DB サーバー (MySQL / PostgreSQL)
といったサーバーアプリケーションをインストールして設定していました。
DB サーバーはデータが吹っ飛ばないように HDD は RAID を組んでとか・・・。
あれ?自分はソフトウェアエンジニアのつもりでいたけれど??12 作ったアプリケーション動かすまでが遠い。。。
2005 年に Rails が登場し、2007 年には Heroku が登場しました。
Rails で Web アプリケーション作ったら Heroku という PaaS にデプロイしたらもう動く、という、アプリケーションエンジニアがインフラのことを知らなくても1人でサービスのローンチまで持っていける状況になったわけです。
メール送信だって、自前でメールサーバーなんて立てなくても SendGrid などの SaaS を使うだけで済みます。
さらにスマホが普及し、スマホアプリ開発者がサーバーサイドの開発を出来るだけ行わなくて済むように、モバイル開発でよく使う機能をまとめた Firebase などの MBaaS が登場しました。
モバイル向けとして誕生しましたが、Web でも使えます。
もはやスマホアプリ開発者やフロントエンド開発者がサーバーサイドのことを詳しく知らなくてもアプリケーションが作れる時代になってきています。
2015 年以降大きなトレンドとなった AI(機械学習)も、あっという間に TensorFlow のようなニューラルネットワークを作成するフレームワークが登場し、クラウドプラットフォームは AI を簡単に利用できるサービスを用意しています。
自前の学習モデルを作成するレベルから、事前に用意されているモデルを利用するものまで。
例えば Vision API で事前に用意されたモデルを使って画像解析して分類するなら、機械学習の知識が全くなくても利用できます。
クラウド環境で複数サービスを組み合わせたシステムを作るような場合にも、フルマネージドでオートスケールするサーバーレスアーキテクチャを選択することで、インフラの構築が楽になりインフラの保守が必要なくなります。
実際、私の所属する株式会社 creatoには専門のインフラエンジニアはおらず、全員がアプリケーションエンジニアですが、GCP を使ってインフラの構築も保守もできています。
ノーコード/ローコード
最近はさらにエンジニアでない人でも業務の自動化をグラフィカルなツールを使って行うことができる環境が注目されています。
日本では DX に絡めて注目されています。
実は発想自体は特段新しいものというわけではなく、古くは 1990 年代後半に Visual Basic が RAD (Rapid Application Development) ツールと呼ばれて、画面上に部品をペタペタ貼り付けてウィンドウ画面を作れるようになっていました。
これはローコードのはしりと言えるかと思います。
同じく 1990 年代後半、大学の研究室で LabView を使っていました。これはいわゆるビジュアルプログラミング言語と呼ばれるもので、画面上で部品を配線しながらプログラムを作るものです。
計測機器からやってくるデータを加工したりしながら、ディスプレイにグラフ表示しつつファイルにもデータを保存する、といったことをコードを一切書くことなく GUI で作成できます。
これはノーコードと言えるかと思います。コードに相当するプログラムを GUI で作成してるだけじゃん、とも言えますが。
参考: Labview でできること 4 選!GUI 操作で非プログラマーでもシステム開発を
ノーコード、ローコードとは言っても、自動化する以上、作っているのはプログラムです。
ただ専門のエンジニアでなくても少ない学習コストでプログラムが作成できます。
DX で注目される1番のポイントは「専門のエンジニアに頼まなくても、業務を知っている人が直接作成できる」ことでしょう。
開発の比重がクライアントサイドへ
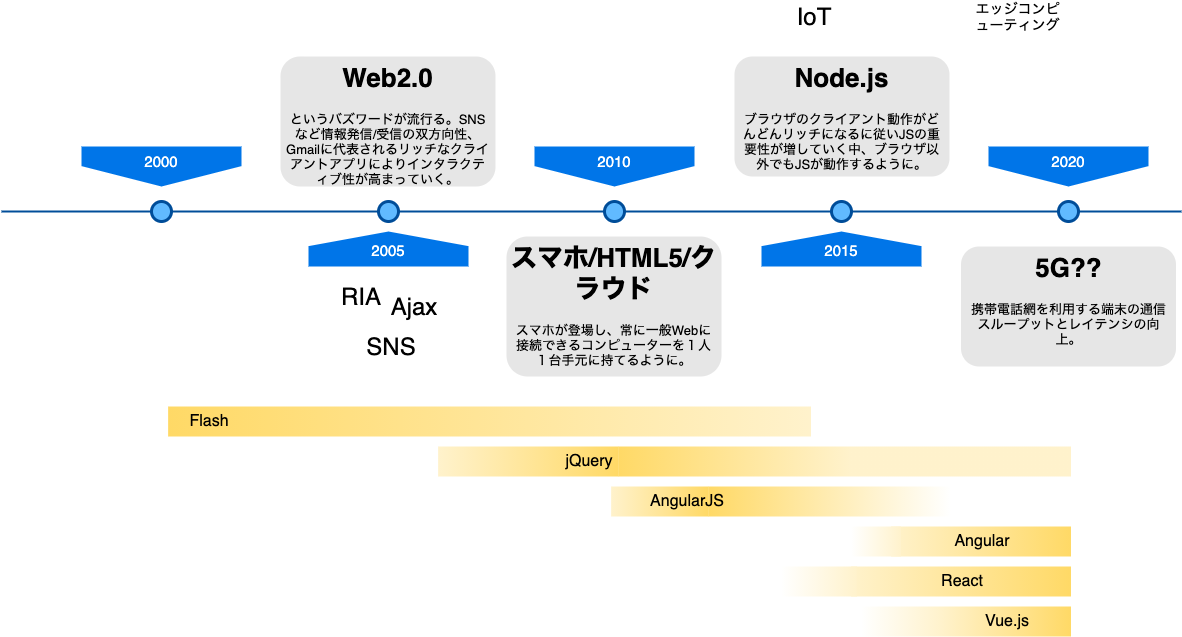
SPA/スマホ、MBaaS
2005 年頃に Web 2.0 というバズワードが流行りました。SNS などの情報発信/受信の双方向性や、Gmail に代表されるリッチなクライアントアプリにより、インタラクティブ性が高まっていくという流れを指しています。
当時は RIA (Rich Interface Application) という言葉をよく聞きました。
つまりネイティブなデスクトップアプリ並みの操作性を持つクライアントアプリケーションを Web 技術で作るというものです。
今となっては React/Vue.js/Angular などで SPA 作るというのが主流ですが、当時は元々普及していた Flash に加えて Microsoft Silverlight や Firefox の XUL を利用するなど、色々なものが登場していました。が、全部消えました。
Web 技術で作るなら、HTML/CSS/JavaScript だけで作れるのが一番良いはずです。
その流れに対して重要な役割を果たした技術が Ajax です。
これによりブラウザ側で「ページ遷移せずに」つまり「サーバーサイドで HTML をレンダリングせずに」、クライアント側でサーバーからデータだけを取得して DOM を書き換えるという方法が確立しました。
2010 年頃になると iPhone の登場によりスマホ時代が幕を開けました。
スマホの登場により、常に手元にある高性能なコンピューターが手に入ったわけです。
そして Web の方では HTML 5 が登場し、Flash が消え去ることになり、RIA は完全に HTML5 に置き換えられました。
クライアントサイドで出来ることが増えるに従い、ソフトウェア開発の比重はどんどんクライアントサイドに移って行っています。
それに伴い、前述した MBaaS が登場して、サーバーサイドのプログラムは最小限で済むようになってきています。
Firestore とか凄いですよね。自分はこれが登場したときに、サーバーサイドよりクライアントサイドだと強く感じました13。
クライアントサイドに比重が移ると、サーバーサイドは API を提供する形になり、例えば REST API なら DB にアクセスする薄いラッパーを大量に書いてるだけといった様相を呈してきます。
様々なクエリに対応する REST API 用意するのは・・・ということで GraphQL 使ってクエリ部分をもっと柔軟に・・・って、それってつまり「クライアントサイドから直接 DB に接続してクエリできたらいいのに」って感じです。
Firestore はそれを実現してくれる上に、変更をリアルタイムに検知することまででき、フルマネージドでデータは分散管理されオートスケールします。
マルチプラットフォーム
クライアントサイドに比重が移ると、プラットフォームごとに別々に開発するのが負担になってきます。
まずブラウザに関しては、ブラウザ戦争で Chrome が勝ったことで劇的に状況は改善されています。
また仕様の標準化もしっかりしています。
polyfill などを利用して憎っくき IE 11 なども対応できますし、そういったブラウザ間の違いをフレームワークが吸収してくれたり、Babel や TypeScript コンパイラで古い JavaScript への変換を行うことで、新しい仕様の JavaScript でプログラムを記述することができます。
スマホアプリでは
- Xamarin(C# で開発できる。UI 部分は iOS, Android 別々が基本)
- Ionic(WebView ベースで純粋に HTML/CSS/JavaScript の Web 技術で開発。Angular ベースだったが、React / Vue.js も使えるように。)
- ReactNative(React と同じ記述方法だが UI コンポーネントは HTML/CSS ではない。UI はネイティブ動作で速い。試すならビルド済みクライアントが使える Expo から。)
- Flutter(UI 部品は独自描画で高速。Dart を使って開発。)
- NativeScript(Angular/Vue.js にとっての ReactNative 相当)
などがあります。Flutter の勢いが一番強いですね。Xamarin 以外は Web 開発者寄りです。
デスクトップに関しては昔から Qt、 wxWidgets などの C++ ライブラリがあり、Windows, Mac, Linux 対応のアプリが作れます。
Qt は iOS, Android にも対応していてスマホアプリも作れますが、メジャーではないので上で紹介しませんでした。
最近では Electron によって Web 技術 (HTML/CSS/JavaScript) で Windows, Mac, Linux 対応のデスクトップアプリが作れます。VSCode や Slack などが Electron を使ってますね。
IoT、エッジコンピューティング
スマホの登場で常に手元にコンピューターが実現しましたが、さらに様々なものにコンピューターが搭載されてそれがインターネットに繋がるようになってきました。いわゆる IoT (Internet of Things) です。
さらにその IoT 機器に搭載されているマイコンの性能も上がってきて、GPU を搭載するものもあり、IoT デバイス側で画像処理、音声処理なども行われるようになってきました。
IoT デバイス側で多くの処理を行えることで、
- サーバーに送るデータ量を減らして通信量の低減(コスト削減)
- 計算結果をすぐにデバイス側で利用することによる応答性の向上(レイテンシ低減)
- デバイス側での暗号化復号化などのセキュリティ対策
といった問題に対応できます。
いわゆるエッジコンピューティングと言われるものです。ここでもクライアントサイドで行えることが増えてソフトウェア開発の比重がそちらに移ってきています。
ビッグデータ
散々、これからはクライアントサイドの比重が大きくなってきて、サーバーサイドで行うことは減っていくと言ってきましたが、サーバーサイド・・・というかバックエンドで行うことが必ずしも減っているわけではありません。
例えば Facebook は Web は SPA ですし、スマホアプリも提供していて、ユーザーが利用する画面の処理はクライアントサイドの比重が増えているのは間違いないでしょう。
しかし Facebook は広告で稼いでいる会社であり、ユーザーから収集したデータを解析してターゲッティング広告を実現しています。
そのデータを扱うシステムはバックエンドで処理しているわけです。
クライアントサイドの比重が大きくなっているのは UI に関係するところの話です。
大量のデータを利用するようになるにつれ、データを活用する部分のバックエンドの処理はむしろ増えています。
当然のごとくビッグデータを扱うためのデータ基盤を作るクラウドサービスが多く登場しています。
AWS の Redshift、GCP の BigQuery、Azure は・・・使ったことないので知らないです。。。
特に BigQuery は本当に使いやすくて優秀です。
フルマネージドで、データは分散管理され、オートスケールで、クエリは SQL でかけられます。
全然ビッグじゃないデータでも使っています。ビッグデータ用なので料金設定が安いですし、Firestore ではできない集計を BigQuery で補えるためです。
- データを移動する
- データを加工する
- データを可視化する14
といったところも、どんどん発展しています。
特にバックエンドのソフトウェア開発に関係するのは前者2つですね。
ゼロから作ることもできますが、様々な ETL (Extract/Transform/Load) ツール15やサービスが登場しています。
この分野も一気に注目&普及したトレンドで、一気に一般化していっています。
今後も拡大するのは確実ですから、バックエンドに関わるのであれば追っていきたい分野です。
ソフトウェア規模の拡大に対する設計
ソフトウェアの規模が拡大するにつれて、ソフトウェア設計もそれに対処する必要があります。
設計においては考えなければいけないこと、覚えなければいけないことが多く、知識と経験が必要な世界です。
しかし誰もが最初は初心者です。まず最初に考えなければいけない一番大事なことは「理解しやすい単位に分解する」ことだと思います。
設計について詳しく書いたらキリがないので、簡単にまとめます。
オブジェクト指向
2000 年代前半には、オブジェクト指向を使えずに関数単位での分解16しかしない年配エンジニアがいる中で、オブジェクト指向17を積極的に学んで取り入れるのは当たり前という風潮ができてきました。
オブジェクト指向は分解単位であるクラスが現実世界とマッピングしやすいと言われていましたが、実際にはマッピングしやすい所もあれば、そうじゃない所もあります。
オブジェクト指向のライブラリを使うのは簡単ですが、オブジェクト指向で設計するのは実は難しいです。
オブジェクト指向によって実現されたのは
- 状態のカプセル化
- ポリモーフィズム
後者によって設計の幅が広がったのですが、それが設計を難しくしています。より重要なのは前者だと思います。
C 言語の時代、グローバル変数による状態管理がコードの依存関係を複雑にして、デバッグやコードの変更や機能追加を難しくし、保守性を大きく下げる原因になっていました。
オブジェクト指向では、それまでグローバル変数で管理していた状態をクラス内に private なインスタンス変数として閉じ込めます。
その変数へのアクセスはメソッド経由でしかできないようにすることで、状態の影響範囲を制限して管理するわけです。
これによりコード間の依存関係を管理しやすくなり、影響範囲が絞られているのでデバッグもしやすくなり、保守性が大きく向上することになりました18。
ポリモーフィズムについて初心者にアドバイスするならば、「それが必要だと分かる場所以外ではポリモーフィズムのための仕組みを使うな」です。
- 全ての class に対して必ず interface を無駄に用意している Java のコード(DI してるわけでもない、interface を implements してる class は1つしかない。)
- 処理を共通化するために継承を多用している(コンポジションを使うべき)
- GoF の設計パターンを、それで解決したい課題もないのに無駄に利用している(デザインパターン使ったら良い設計になると思ってる)
そういうコードを見てきました。
それ、ポリモーフィズムどこにも使ってないじゃん。。。とか、そこポリモーフィズム使う必要ないじゃん、複雑にしてるだけじゃん19。。。というところで、ポリモーフィズムのための仕組みを使ってしまっているわけです。
設計テクニックは、「新たに複雑さを追加して、より大きな複雑さに対して対処する」というものが多いです。
単にファイルを分割するのだって、「ファイル数が増える」複雑さを追加して、「1ファイルの行数が多くて保守しづらい」複雑さに対処します。
GoF にしろ DDD にしろ、新しいテクニックを覚えて使ってみたくなるのは分かりますが、それ本当に解決したいと思ってる課題でしょうか?かえって複雑になったり、(自分には分かっても他人に)理解しにくくなってないでしょうか?
ポリモーフィズムに限らず、設計のための道具は、何かそれで解決したい課題があって適用するものです。
KISS の原則に従いましょう。
単一責任の原則
ソフトウェアの設計に SOLID 原則という5つの原則があります。その中で一番重要なのは「単一責任の原則」ではないかと思います。
ただこれ、「じゃあどうすればいいの?」となると、中々に理解しにくいです。
「1 つのクラスは 1 つだけの責任を持たなければならない。すなわち、ソフトウェアの仕様の一部分を変更したときには、それにより影響を受ける仕様は、そのクラスの仕様でなければならない。」(by Wikipedia)
何言ってるか分かりますか?
「単一責任」の意味を勘違いすると、1つのメソッドしかないクラスに細かく分解する・・・ってことをやりかねません。
自分はもっとシンプルに「一言で言い表せるか?」を意識しています。
例えば Web サーバーサイドの Controller とか Servlet のやることってなんでしょうか?
- HTTP の入力を受け取る
- 入力のチェックを行う
- ロジック処理を下層に委譲する20
- 結果を(必要であれば HTML にレンダリングして)HTTP の出力として返す
1つじゃないやん。。。
でも「特定の URL パスに対する HTTP の入出力処理を行う」と一言で言い表せそうです。
「クエリ文字列で渡ってくるのか?フォームで POST されるのか?Ajax で JSON が POST されるのか?」を知ってるのはこいつの責務の範囲です。それぞれに合った方法で入力を取得します。
「HTTP で外から渡ってくるデータなのでチェックしないといけない」ことを知っているのはこいつの責務の範囲です。ここで入力のチェックを行います。
コメントで書いた時に、以下のように先頭に一言で何をするクラスなのかを言い表せる単位で分解できているかどうか。
/**
* [ここに一言で表せる責務が書けるか?]
*
* [詳細説明には複数の処理をやってることを書いていい]
*/
export class Hoge {
// 略
}
Hoge クラスを使う側から見て、このクラスが何をするのか?何を任せられるのか?の概要が、最初の1行でパッと理解できます。
そしてそれが出来るだけコメントを見なくても名前を見れば分かるようにしましょう21。
クラスに限らず、それをさらに分解するメソッドも、クラスを束ねるパッケージも、ライブラリも、そうやって「一言で表すと何?」という単位に分解していくことが、「理解しやすい単位に分解する」ことになります。
パッケージの分割単位
パッケージはソフトウェア部品をまとめる単位です。言語自体にその機能があることもあれば、単にディレクトリ構造で表すだけの場合もあります。
ソフトウェアの分解の仕方には幾つかの切り口があります。
その中でも分かりやすいものの1つにレイヤードアーキテクチャがあります。
また機能ごとに分解する切り口は普通に考えるでしょう。
以下の図では、レイヤードアーキテクチャが横方向の分解で、機能ごとの分解は縦方向の分解です。
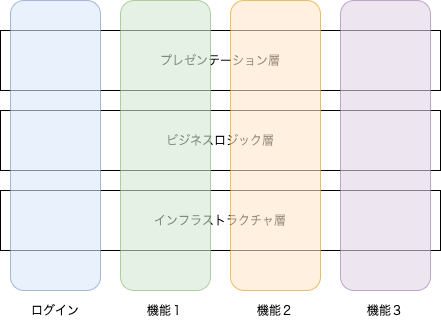
レイヤーの名前は呼び方が色々あります。また何階層に分けるかも、アプリケーションの規模によって変わってくるでしょう。自分がやった例だと、プレゼンテーション層の下に、複数画面にまたがる処理を管理するユースケース層を設けたことがあります。
上図はあくまで概念図です。実際には機能はこんな風に綺麗に縦に分解できないことが多いです。
ビジネスロジック層やインフラストラクチャ層に存在するソフトウェア部品は、上の階層の複数から利用されるものが多数あるのが普通です。
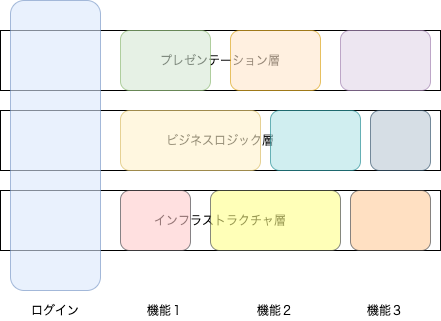
もう1つ分解の単位で分かりやすいものがあります。各部品の種類で分類する方法です。
- views (スマホアプリなら画面部品、Web サーバーサイドなら HTML テンプレートを入れておく)
- controllers, servlets, screens(画面、HTTP 処理)
- data-types, dto(各階層で利用するデータ型、特にデータの受け渡し)
- repositories(DB とのやりとりを行う部品)
- entities, models(ID を持つもの、DB とのやりとりに使うデータ型)
- value-objects(値オブジェクト、色や価格などの ID を持たない単なる値を表す)
- utils(各階層で利用するユーティリティ関数や部品)
名前は色々とあるでしょうけど、ソフトウェア部品の種別で分類しています。
気づいたかと思いますが、レイヤードアーキテクチャと関係しているものと、そうでないものが混ざっています。
例えば views とか controlles ... とかはプレゼンテーション層にあるべきものですし、repositories はインフラストラクチャ層のものでしょう。
今までに三つの軸が出てきました。で、これをディレクトリ構造で表したいのですが・・・。
その場合は優先順位を決める必要があります。
例を出すと、以下は
- 機能
- レイヤー
- 部品種別
の優先順位でディレクトリ構造を表したものです。
.
├── App
│ ├── Presentation
| │ ├── Views
| │ └── ViewModels
| ├── BusinessLogic
| │ ├── Services
| │ ...
| └── Infrastructure
| ├── Repositories
| ...
├── Shared
│ ├── Presentation
| │ ├── Views
| │ └── ViewModels
| └── Utility
| ...
└── Login
├── Presentation
│ ├── Views
│ └── ViewModels
├── BusinessLogic
│ ├── Services
│ ...
└── Infrastructure
├── Repositories
...
ビューしかない機能や、ビジネスロジックしかない機能なども出てくるはずです。
小規模なアプリケーションの場合は、
- レイヤー
- (機能)
- 部品種別
にすることが多いです。
双方向依存や循環依存を避ける
クラス設計やパッケージ設計、ライブラリ設計では、双方向依存や循環依存にならないようにすることが重要です。
パッケージ図やクラス図を書いてそれぞれ何がどれを利用しているか依存関係を矢印で表してみましょう。意識していないと簡単に双方向依存になっていたりします。双方向依存になっていると依存関係が複雑になって保守性が落ちることになります。

依存関係は、インターフェースを使って逆転させることができます。
例えば package3 が pacakge1 に依存している部分を逆転させたいとします。
pakcage3 側に「package1 に対してどういう使い方をしたいか」を表すインターフェースを用意し、package1 側がそれを実現する形をとります。
詳細は「依存関係逆転」でググってみてください。
関数型
何を持って関数型というかの定義が曖昧なので説明しにくいのですが、Haskell などの関数型プログラミング言語が注目されたあたりから、設計やコーディングにもその考え方が入ってくるようになりました。
では関数型から昨今のプログラミング技術に何がやってきたのか?というと、
- map, filter, reduce などの集合に対して処理する関数やメソッド
- ラムダ式(無名関数)
- 出来るだけ不変値を使う
- 純粋関数22を積極的に使う
あたりでしょうか。
どれも元々あったじゃんという話もあるのですが、より強く意識されるようになったり、一部機能が存在していなかった Java などの言語にも取り入れられたり、新しい言語では当然のように利用できるようになっています。
1 によってループの記述がいらずに処理が簡潔に書ける上に、処理途中の状態を管理する変数が必要なくなります。3 にも繋がってきますね。また処理内容はラムダ式があることで簡潔にかけますので 2 も関係あります。
2 によってポリモーフィズムを使う場面が減ります。継承などという大袈裟なことをしなくても、ポリモーフィズムで解決できるような多くのことが、もっと簡単に依存性も少なく解決できます。
3 は、状態が変化しないことが保証されていることでコードが理解しやすく、デバッグしやすくなります。
そもそもオブジェクト指向の普及理由の1つが状態管理にあったわけですから、状態は少ない方がいいです。
4 については、純粋関数は状態を持たないし副作用もないので、コードが理解しやすくデバッグもテストもしやすくなります。3 と密接に関係しています。
状態管理
React は元々関数型言語でコンセプト実装が作られていたらしく、設計が極めて関数型に寄っています。
その React の有名状態管理ライブラリが Redux です。
Redux の元となったのが Elm Architecture で、Elm は Haskell から難しいものを全部取り除いたシンプルな純粋関数型言語を使った SPA フレームワークです。
Elm はフレームワークのランタイムが状態を管理していて、アプリケーションコードでは一切変数への再代入ができません。
この Elm Architecture のような「状態をフレームワークやライブラリの側で管理しておいて、アプリケーションコード側は不変値と純粋関数で処理を書く」という状態管理のやり方が Redux が普及して以降23、一般的に利用されるようになりました。
とはいえ、実際のところは状態管理ライブラリ側で管理するのは複数コンポーネントで共有するようなグローバルな状態だけにして、各コンポーネントに閉じた状態はオブジェクト指向的にコンポーネント内の状態として管理した方がわかりやすいのではないかと思います。
例えばクリックされると内容が表示されるアコーディオンコンポーネントを作るとして、その「開いているか閉じてるか」の状態はコンポーネント側で管理した方が、理解しやすいし保守しやすいし再利用しやすいでしょう?
マイクロサービス
パッケージの分割について先述しましたが、1つのアプリケーションが大きくなってくると、(特に他でも再利用できそうなものを)さらにライブラリに分割するでしょう。
そのうちアプリケーションも分割して・・・というように、分割する単位を増やす方向に進みます。
サーバーを複数台に分けて処理内容を分割すること自体は全く新しい概念ではなく、昔からやられていたことです。
それには以下の動機があるのではないでしょうか。
- 大きくなったシステムを、もっと分かりやすい単位に分割したい
- サーバー負荷が耐えられなくなってきたので、処理を分けて複数台に分割したい
- いわゆるコンウェイの法則
自分が以前関わっていた現場では、マイクロサービスという言葉を聞く前からサービスが分割されていましたが、単純にその方が並行して開発しやすいからです。
サブシステムの改修を、複数人で同時にやらずに出来るだけ1人が担当することで管理コストを抑えていました。
これは 3 のコンウェイの法則ですね。1 の理由もあったと思います。
ではなぜマイクロサースという言葉が最近こんなによく使われるのか?というと、ビジネスにスピードと変化への追従が求められていることと、ビジネスを実現するソフトウェア全体の大規模化、技術面ではそれを支えるコンテナ技術、分散・オートスケールといったことが関わっていそうです。
- 手分けして作業しやすい
- 改修の影響範囲を限定しやすい
- 1つのサブシステムが小規模になり、サブシステム単位では保守しやすい
- サブシステム単位で作り直したり、実験的なサブシステムを追加したりしやすい
- サブシステムごとに別のフレームワーク、言語、インフラサービスなどを選択できる
- サブシステムごとに負荷分散やスケーラビリティを持たせることができる
システム全体を把握して設計、保守するのは難しくなる傾向ですが、個々のサブシステムは小規模になるので設計・開発・テスト・保守が楽になります。
またマイクロサービスがトレンドであることもあり、当然クラウド側にもそのためのサービスが充実しています。
GCP であれば、
などです。
新しい技術は実は新しくない
自分が社会人になった 2000 年以降の技術の変遷と流れを説明してきましたが、ここで紹介してきた多くのものは実は 2000 年以前から既に存在していたか、あるいはコンセプトは存在していました。
IDE は存在していて、フォーマッターもリンターも使えたし、Haskell も OCaml も既にあったし、ORM もメタプログラミングもローコード/ノーコードも、ニューラルネットワークを使った機械学習も。
携帯電話は既に i-mode の登場時からインターネットに繋がっていました。
Wikipedia の IoT の歴史の章 には、コンセプトは 1982 年とあります。IoT という言葉の登場は 1999 年です。
- 環境が整ったことにより実用的になって普及
- その時点で抱えていた問題を解決するコンセプトが登場して注目を集める(が、要素技術自体は前からある)
- 元々あって使われていたものが順調に進化、あるいは他のものにも波及
- 本当に新しい技術が登場、あるいはその技術との組み合わせにより元からある技術が普及
- 何かのトレンドに引っ張られて、そこで使われているものもトレンドに
などにより、トレンドを作り出しているように思います。
他のトレンドに乗っかっている古くからある技術に注意
プログラミング言語の人気でいくと、最後の「何かのトレンドに引っ張られて、そこで使われているものもトレンドに」は曲者に思えます。
iPhone が登場して Objective-C が人気になりましたが、これは Objective-C がトレンドというより iPhone がトレンドだったわけです。
でも Swift が登場して、Objective-C はもうトレンドから外れてしまっています。
最近だと Python ですかね。Python 2.0 は 2000 年に登場していて、Ruby と同じく Perl の置き換えを狙った言語として Rails 登場前は Ruby よりずっとメジャーな言語でした。
Python が最近一気に人気になったのは AI がトレンドになったからです。Jupyter Notebook に代表されるように、トライアンドエラーを何度も繰り返すような研究や実験などの学術分野で特に Python が好まれて使われてきた経緯があります24。
勿論 Python は応用範囲の広いとても良い言語ですが、しかしシステム開発に特に向くかと言われると、「同様の目的で作られた Ruby と同程度には」といったところかと思います。Ruby(と PHP)の人気が下降気味であるのに Python が伸びているのはやはり AI トレンドに引っ張られてでしょう。
ここ 20 年を振り返って、現時点でどうか
Web サーバーサイド
Rails のようなサーバーサイドで Web アプリケーションを構築する技術は、これからもまだまだ使われるでしょうけど、もはや古い手法になってきています。
新しい開発手法は、フロントエンドは React/Vue.js/Angular で SPA で作り、サーバーサイドは Firebase などの MBaaS やサーバーレス技術を使って構築する方法です。
- フロントエンド
- リッチで軽快な UI の提供
- 動作確認の容易な開発環境
- TypeScript による静的型付けの恩恵
- サーバーサイド
- インフラ保守がいらない(フルマネージド)
- ダウンタイムが短い(分散)
- 急にアクセスが増えても処理できる(オートスケール)
- コード量が少ない(開発効率)
といった多大なメリットがあるのに、Rails のようなスケールしにくいモノシリックな技術を使い続けるのは不利です。
Rails のエンジニアは今はまだ需要もありますが、今後は新規開発での採用は減っていく可能性が高いと想像されます。
扱えるエンジニアの数が多ければ(そして単価が安ければ)PHP と同様に需要の減りは緩やかかと思いますが、GitHub の人気言語のトレンドを見ると、より古くから普及して長く使われ続けている PHP に比べて Ruby の衰退スピードは早いようです。
プログラミング言語
トレンドは厳密な型チェックが効く静的型付け言語に移っています。
動的型付け言語は保守性の観点で静的型付け言語に劣る上に、メリットであった開発効率に対しても、型が厳密に進化してさらに IDE の支援が受けられるようになった静的型付け言語が有利になってきています。
しかし動的型付け言語もそのトレンドを指を咥えて見ているわけではなく、Python, PHP は最近は型を指定できるようになってきましたし、Ruby も(アプリケーションコードでは型指定は書かないで)型チェックを導入するつもりのようです25。衰退はずっと緩やかか、あるいは衰退しないかもしれません。しかし Python を使ってて思うのは、現状の型指定の効果は中途半端過ぎです。
一方でサーバーレスが普及してきており、サーバーサイドで AWS Lambda や Cloud Functions でスクリプトレベルの小規模なプログラムを書いて実行して動作確認、といった用途では、スクリプト言語は向いていると言えます。
またプログラマは不足しているので、初心者でも扱いやすい動的型付け言語の利用は、
- エンジニアを集めやすい
- エンジニアの単価が安い
という、PHP が今でもよく利用されるのと同じ理由で、今後も継続すると思われます。
そのため仕事が減るというより、単価が上がらないことや、現場の技術レベルが低いプロジェクトに配属されやすいことを気にすべきかと。
比重が移ってきて肥大化傾向にあるクライアントサイドのプログラミングでは、TypeScript, Swift, Kotlin, Dart といった静的型付け言語が主流であり続けそうです。
動的型付けの Ruby, Python, PHP を覚えるのは無駄じゃありませんし、まだまだ仕事はあります。向くところでは使っていくべきでしょうし、自分も使っています。
しかしそれしか使えないというのからは脱却した方が将来の潰しが効きます。
今 Ruby を使っている人は、次に Python を覚えるのではなく、フロントエンド部分で JavaScript ではなく TypeScript を使うなど、静的型付け言語も使えるようにすると良いのではないでしょうか。
特に TypeScript は any を使えば JavaScript と同レベルになって型チェックが台無しになるものの、静的型付けに慣れていなくてもすぐに使える敷居の低さがあります。
一方で型に習熟すれば、Java よりもずっと厳密な型チェックを行ってくれます。
徐々に静的型付けに慣れていくのに最適です。
Web エンジニアが増えるに従い、Web 技術が使える場面は増えています。
Web フロントエンド / バックエンド、スマホアプリ開発、Electron でデスクトップアプリ開発...
TypeScript は現時点では最もオススメな言語だと思っています。
インフラ
今はインフラエンジニアがいなくてもアプリケーションエンジニアだけでサービスを構築できる時代になってきています。
とはいえ、インフラエンジニアがいらなくなったわけではありません。
クラウドサービスが充実しすぎて、詳しい人がいないと使いこなせないという状況があります。
また、今でも古くからのやり方から抜け出せない開発現場は多いので、オンプレミスで動作させるのと似たような環境をクラウド上に作るような仕事はまだまだ残っています。
もしあなたがインフラエンジニアなのであれば、GCP よりも AWS に詳しくなった方がいいでしょう。
単純に AWS の方がシェアが多くて仕事も多いという理由がまず1つ26。
2つ目の理由は、GCP より AWS の方が詳しい人がいないと使うのが難しい印象があるためです。
GCP の方があまり設定をしなくてもそのまま使えるような配慮がされていて、簡単に使えるサーバーレスなサービスが整っている印象です。
逆に AWS は歴史が長いこともあってサービスの数がずっと多く、技術の選択に GCP 以上に知識が必要です。細かい設定でできることが多い・・・が細かい設定をしないといけない印象があります。
この辺りは弊社が GCP をメインに使っている贔屓目もあるかもしれませんが、AWS のプロジェクトに関わっていると、そのように感じてしまいます。
残念ながら Azure に関しては経験がないので分からないです。
最後に
急いで書いたのもありますし、知識不足なところもあるでしょうし、正確性に欠ける書き方をしているところは多々あるかと思います。
暖かい目で見て頂ければ幸いです。
Advent Calendar の期日に結局間に合わなくて、当初予定より端折った部分もあります。
正直、設計の部分とか別記事にした方が良かったかなとも思いますが、長文にお付き合い頂きありがとうございました。
-
当時はその奇抜さから XP (eXtreme Programming) が話題になっていましたが、取り入れやすいのは Scrum と言われていました。結局、主流は Scrum になった感じですね。 ↩
-
正確には HTML の元になった汎用的な SGML をもっと簡素化した。 ↩
-
自作のプログラミング言語を作るなどで使ったことがある人もいるかと思います。参考: http://kmaebashi.com/programmer/devlang/yacclex.html ↩
-
Ruby だけじゃなくて動的言語は大抵できます。特別にメタプログラミングの仕組みがなくても eval があればとりあえず実現できますし。ただ Ruby はメタプログラミングがしやすい仕組みがあったということかと。 ↩
-
オブジェクト指向とリレーショナルデータベースの設計モデルのミスマッチを表す言葉。電気回路用語を拝借している。 ↩
-
動的メタプログラミングは黒魔術とも呼ばれます。フレームワークやライブラリが使うと、アプリケーションコード側の記述量が減ったり可読性も向上したりする強力な機能です。しかしアプリケーションコードでむやむに使うと、そのメタプログラミングしている部分は理解が難しくなってしまいます。 ↩
-
Vim 側に Language Server Protocol 入れて、Vim 自体を IDE 並にするというのも考えられます。しかし IDE(特にメインでよく使う VSCode)には便利な拡張が色々あってそれも使いたいですし。VSCode の NeoVim 拡張は NeoVim 側のプラグインも使えるようになりますし。 ↩
-
Elixir や Julia などの注目されている動的型付け言語は登場していますが、「主要」とは言えない状況です。 ↩
-
「課題のプログラム写させて」とよく頼まれたのを覚えてます。自分のとは違う書き方で課題通りの動きをするプログラムを別に作って渡してました。それをさらに複数人がコピーしちゃって結局バレたみたいですが。 ↩
-
コモディティ化は本来は経済用語で、「各メーカーの商品が次第に個性を失って、どのメーカーの商品を購入しても大差がなくなっていくこと」を指します。最初は先進的だったものも、段々と「あって当たり前」の日常品になっていきます。 ↩
-
未だに PHP で1ページ1ファイルが頑張っている人もいますが。PHPer というのが侮辱的に使われるのは、「古いやり方」だけしか使えずに、そこから抜け出せない人が多いためでしょう。私は今でも Laravel 使って PHP の仕事する時もあります。PHP がダメってわけじゃないと思いますよ。 ↩
-
学習しなきゃいけないことが多すぎて「自分が 2 年後に持ってるだろう技術力が今すぐ欲しい」が口癖でした。しかも半分は IT のプロジェクト、半分は組み込み開発のプロジェクトで、どっちの学習も必要という。 ↩
-
Firebase には Firestore の前から Realtime Database がありました。単に自分が使ったことなかっただけです。社内でサーバーサイドで使っていた Cloud Datastore が Firestore に置き換わるという話が出たタイミングで知りました。 ↩
-
こちらは UI 側の話になります。しかしフルスクラッチで作らなくても Tableau のような既成のアプリケーションが充実しています。 ↩
-
変換をデータベース自身の機能でやる ELT (Extract/Load/Transform) なんていうのもありますね。 ↩
-
今は当たり前ですが、その前は goto でジャンプして戻るといったコードだったり、BASIC のサブルーチンは引数を渡すこともできない「return できる goto」でしかなくグローバル変数経由でやり取りする必要がありました。自分が学生だった 1990 年代、処理を括り出す C 言語の関数の考え方は大きな進歩だと教えられました。 ↩
-
アラン・ケイの提唱した「オブジェクト指向」は、オブジェクト間がメッセージ通信を行うというものでした。概念としては(関数型言語だけれど) Erlang に極めて近いように思えます。歴史的な経緯を説明し出すと自分が全く知らない SmallTalk の話が出てきます。ここではオブジェクト間のメッセージのやりとりをメソッド呼び出しで表す C++ 的な、現在のほとんどの主流言語が持っているオブジェクト指向の仕組みを指します。 ↩
-
当然ですが Singleton をグローバル変数代わりに使うのはバッドパターンです。Singleton パターンの目的は「1つしか作れないことを保証すること」であり「どこからでも取得できること」ではありません。Singleton にするかどうかは DI コンテナに任せるのが良いかと。 ↩
-
アプリケーションコードでは実はあまりポリモーフィズムを使いたい場面は多くありません。言語自体やライブラリやフレームワークがそういったところをカバーしてくれているためです。テストのモックを作りやすくするためにインターフェースが必要な場合以外に、使う場面はそんなに多くはないです。そのモックも、最近はインターフェースを用意しなくてもクラスを直接モック化できるツールが用意されていたりします。 ↩
-
特に Rails などでは Controller に直接書いちゃってることが多いですが、ここでは説明の都合上、行儀正しくロジック処理は委譲することとします。 ↩
-
Servlet とか Controller とか、名前見ても責務が分からないじゃん!って思うかもしれませんが、Rails 使ってたら Controller が何かはフレームワーク使ってる人には分かるはずです。ただ Servlet はいいですが Controller という一般的な名前を使うのはやめて欲しかったところ。 ↩
-
同じ入力なら必ず同じ出力が行われる関数。またコンソールへの出力などの、関数の戻り値以外の出力(副作用と呼ばれる)を含まない。 ↩
-
React に Hooks が導入されたことで、Redux を使わずとも Elm Architecture のような仕組みが実現できるようになっています。Vuew.js だと vuex、Angular だと NgRx が使われています。 ↩
-
C 言語系の既存主流言語に文法が似ていて、ずっと読みやすくて書きやすいためだと思います。トライアンドエラーを繰り返す用途ではスクリプト言語が向いています。「保守性が悪い」ことはあまり問題にならず、それよりすぐ改造して動かせる方が重要です。さらに研究者はソフトウェアエンジニアではありません。専門でない人が簡単に使えるものが望まれます。 ↩
-
「ストレスなくプログラミングを楽しむ」を重要価値としている Ruby らしさを失わない方針だと思います。参考: Ruby3 で導入される静的型チェッカーのしくみ まつもとゆきひろ氏が RubyKaigi 2019 で語ったこと ↩
-
逆張りをすればライバルが少ないので、希少価値が生まれるという戦略も考えられます。 ↩