SOLIDの原則とは?
SOLIDは
- 変更に強い
- 理解しやすい
などのソフトウェアを作ることを目的とした原則です。
次の5つの原則があります。
- Single Responsibility Principle (単一責任の原則)
- Open-Closed Principle (オープン・クローズドの原則)
- Liskov Substitution Principle (リスコフの置換原則)
- Interface Segregation Principle (インタフェース分離の原則)
- Dependency Inversion Principle (依存関係逆転の原則)
上記5つの原則の頭文字をとってSOLIDの原則と言います。
今回の記事では Dependency Inversion Principle (依存関係逆転の原則) について解説します。
その他の原則に関しては下記参照。
- Single Responsibility Principle (単一責任の原則)
- Open-Closed Principle (オープン・クローズドの原則)
- Liskov Substitution Principle (リスコフの置換原則)
- Interface Segregation Principle (インターフェース分離の原則)
簡単に言うと...
「使う側と使われる側の関係を見直そう」ということです。
たとえば、画面で保存ボタンを押したらDBに保存されるというシンプルな機能について考えましょう。
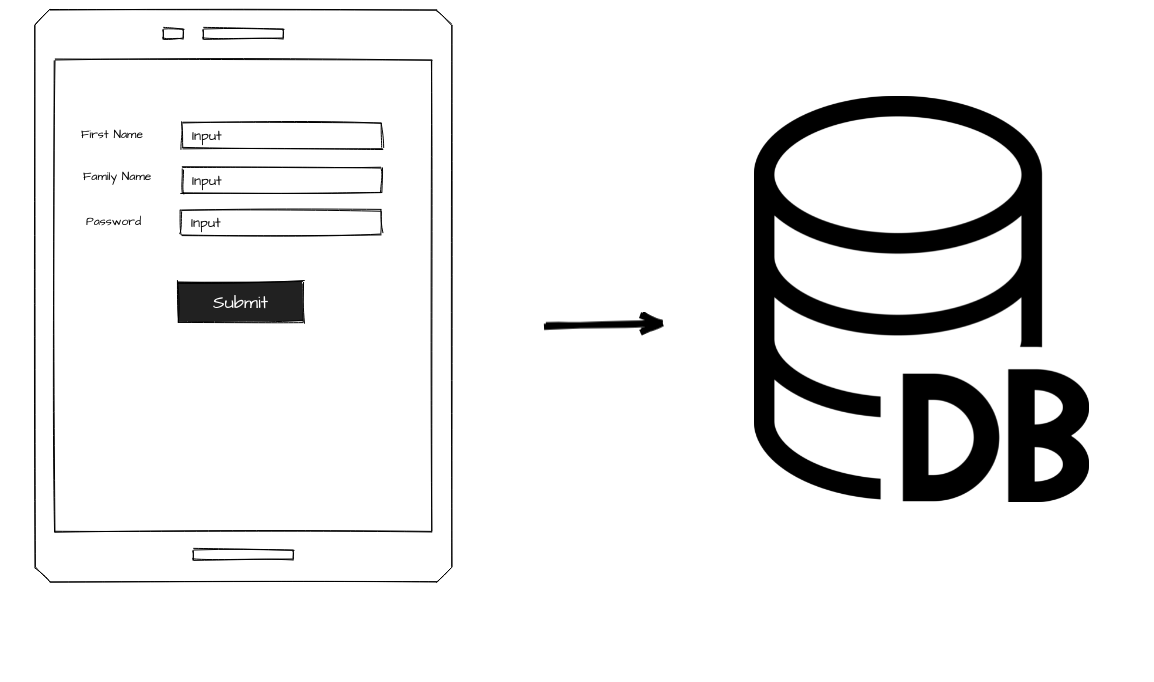
この場合、
- 「画面」が使う側
- 「DBに保存する処理」が使われる側
になります。
普通処理を書こうとすると、「画面」から「DBに保存する処理」を呼び出すため、
「画面」が「DBに保存する処理」に依存することになります。
たとえば、保存先がDBからCSVファイルに切り替わった場合、その影響が画面 (正確に言うと画面側での呼び出しロジック) にも影響が出てしまいます。
この影響を出ないようにするために、「使う側と使われる側の関係を見直そう」というのです。
では、使う側と使われる側の関係を見直した結果、どのようにすればよいのでしょうか?
少し詳しめに言うと...
Wikipediaでは下記のように説明されています。
上位モジュールはいかなるものも下位モジュールから持ち込んではならない。双方とも抽象(例としてインターフェース)に依存するべきである。
抽象は詳細に依存してはならない。詳細(具象的な実装内容)が抽象に依存するべきである。
先程の「画面」から「DBに保存する処理」に上記を適用すると下図のようになります。
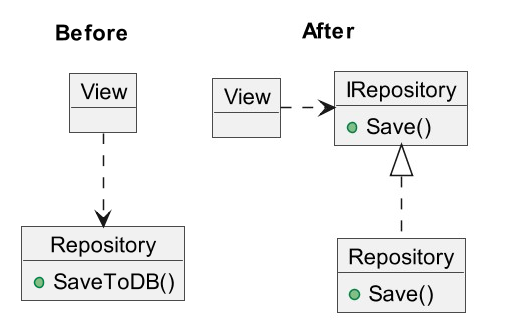
- 上位モジュールはいかなるものも下位モジュールから持ち込んではならない。双方とも抽象(例としてインターフェース)に依存するべきである。
元々は使う側 (View) が使われる側 (Repository) に依存していましたが、
IRepositoryという抽象 (ここではインターフェース) が現れ、使う側 (View) も使われる側 (Repository) も抽象 (IRepository) に依存しています。
- 抽象は詳細に依存してはならない。詳細(具象的な実装内容)が抽象に依存するべきである。
IRepositoryにSaveというメソッドが定義されており、Repositoryはそれを継承して使っています。これは、詳細 (Repository) の具体的な実装内容が、抽象 (IRepository) に依存しているということです。
もう少し具体例を用いながら見ていきましょう。
今回使用する例
テレビの録画を例に考えてみましょう。
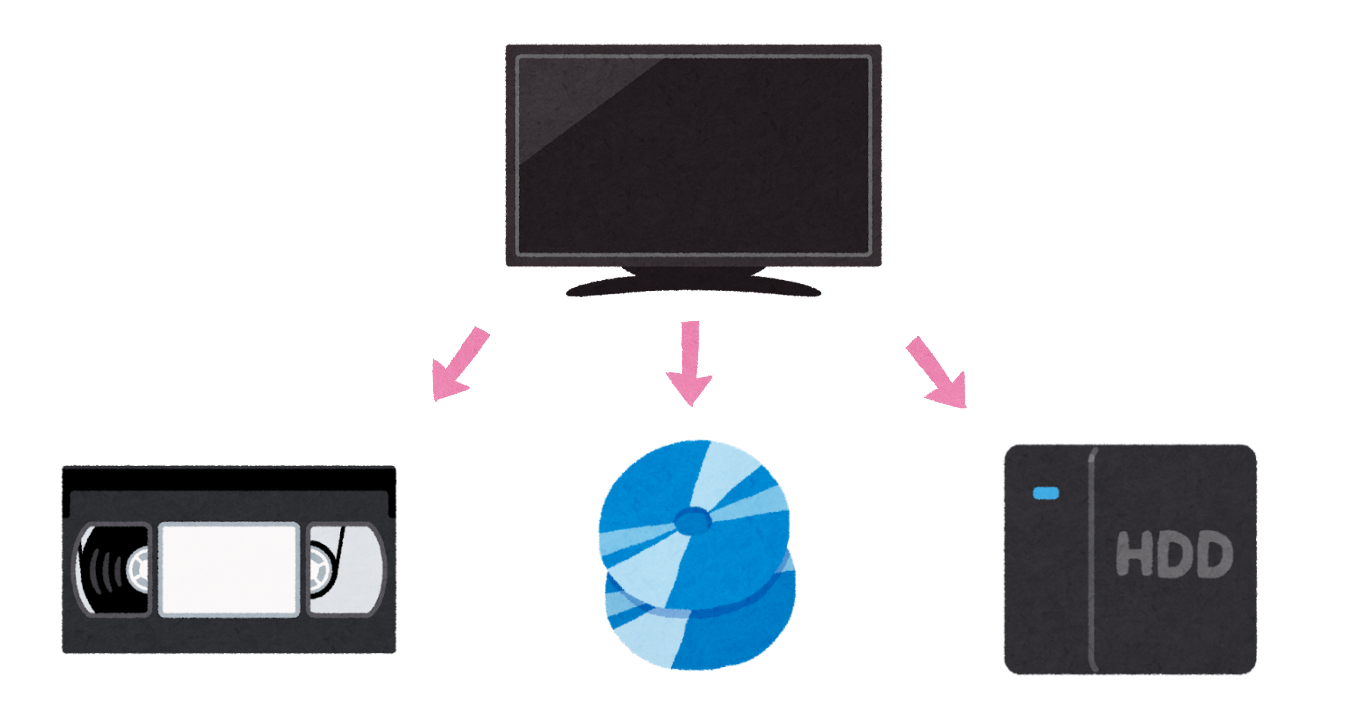
テレビの録画機器として、ビデオ、ブルーレイディスク、HDDなどがあります。
これをコードに落とし込んでいきましょう。
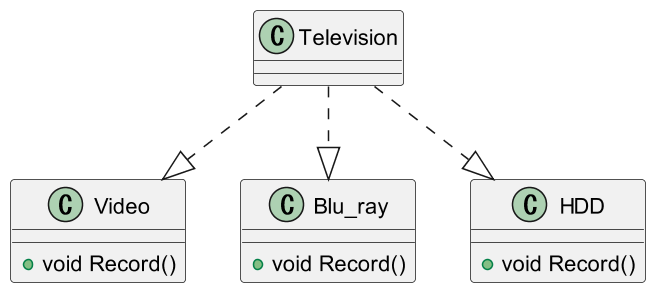
依存関係逆転の原則に違反した例
ビデオ、ブルーレイディスク、HDDの3つのクラスを作り、
テレビから呼び出すという想定で考えてみましょう。
class Television
{
public void Record()
{
if (ConnectsVideo())
{
Video video = new Video();
video.Record();
return;
}
if (ConnectsBluRay())
{
Blu_ray bluRay = new Blu_ray();
bluRay.Record();
return;
}
HDD hdd = new HDD();
hdd.Record();
}
}
public sealed class Video
{
public void Record()
{
// ビデオに録画
}
}
public sealed class Blu_ray
{
public void Record()
{
// ブルーレイに録画
}
}
public sealed class HDD
{
public void Record()
{
// HDDに録画
}
}
テレビ側で、逐一「記録媒体が何であるか」を確認して、各記録媒体に記録指示を出すことになります。
これが、使う側が使われる側に依存している状態です。
依存関係逆転の法則を適用する
テレビと記録媒体の間にインターフェースをかませることで解決できます。
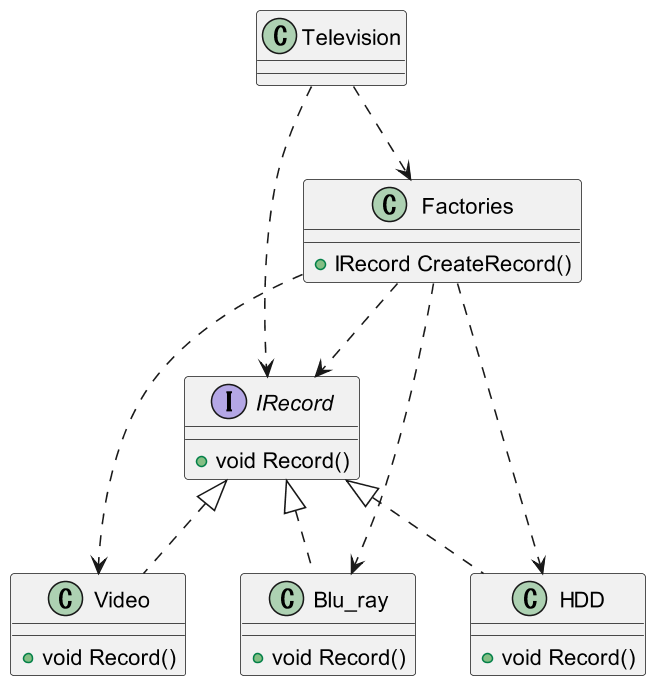
コードでの実装例は下記のようになります。
class Television
{
public void Record()
{
IRecord recorder = Factories.CreateRecord();
recorder.Record();
}
}
public interface IRecord
{
enum Recorder
{
VIDEO,
BLU_RAY,
HDD
}
public void Record();
}
public sealed class Video : IRecord
{
public void Record()
{
// ビデオに録画
}
}
public sealed class Blu_ray : IRecord
{
public void Record()
{
// ブルーレイに録画
}
}
public sealed class HDD : IRecord
{
public void Record()
{
// HDDに録画
}
}
public class Factories
{
public IRecord CreateRecord()
{
// テレビに接続されている機器取得
var recorder = GetRecorder();
if (recorder == IRecord.Recorder.VIDEO)
{
return new Video();
}
if (recorder == IRecord.Recorder.BLU_RAY)
{
return new Blu_ray();
}
return new HDD();
}
}
Factoryを使うことで、テレビ側での呼び出しを簡素にしています。
これにより、ビデオなどの具象クラスになにかの変更があったとしても、その変更の影響が使う側には伝わりにくくなります。
また、それ以外のメリットもあります。
テスト容易姓
依存関係逆転の法則を適用することは、テストをしやすくなることにも繋がります。
例えば、上記例では、
- ビデオ
- ブルーレイディスク
- HDD
などの具体的なものに繋いでの動作確認が必要になります。
もし、それらの機器が手元にない場合、テストをすることができません。
このように、外部機器との接続が必要なものの場合、テスト用のクラス (Fakeクラスなど) を用意しておくことで
テストがしやすくなります。
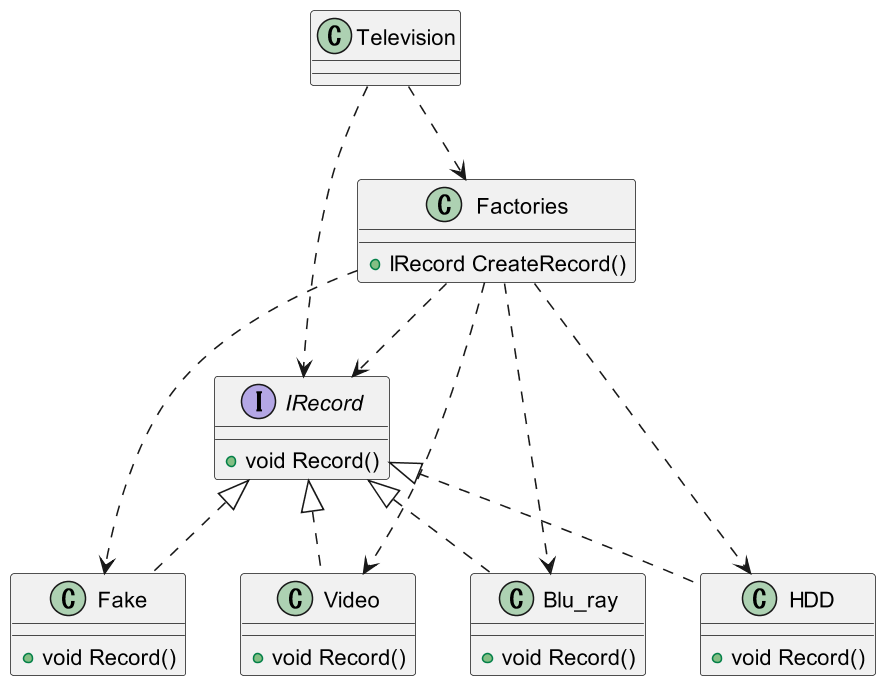
例えば、Factoriesにこのように書いておくことで、デバッグ時は常にFakeから値を返すということができます。
public class Factories
{
public IRecord CreateRecord()
{
// ここを追加
#if DEBUG
return new Fake();
#endif
// テレビに接続されている機器取得
var recorder = GetRecorder();
if (recorder == IRecord.Recorder.VIDEO)
{
return new Video();
}
if (recorder == IRecord.Recorder.BLU_RAY)
{
return new Blu_ray();
}
return new HDD();
}
}
まとめ
依存関係逆転の法則とは「使う側と使われる側の関係を見直そう」ということでした。
具体的には、
- 使う側も使われる側も抽象に依存させる
- 詳細の処理内容を抽象に依存させる
ということです。
そうすることで下記のようなメリットが得られます。
- 変更に強い
- 理解しやすい
尚、今回使用したソースはこちらに上がっています。
参考文献
- 本
- サイト
- 動画
補足
説明として、テレビのメタファーがあることで、かえって理解の妨げになっている可能性があると感じたので、実際のアプリケーションにおける例も追記しておきます。そもそも細かく見ていくとテレビのメタファーは普通に現実と乖離した嘘ついている気がする...
簡単に言うと...のところでも説明をしましたが、使う側と使われる側が存在するとき、素直にコードを書いていくと、使う側は使われる側に依存してしまいます。
例えば、あるAPIのコード内に、
①データソース(DBなど)からデータをとってくる処理
②データソースからとってきたデータを加工して適切な形にしてAPIのレスポンスとして返す処理
がある場合、②の処理から①の処理をそのまま呼び出すと仮定します。
このとき、②が使う側で①が使われる側となります。②が①に依存している状態ですね。
依存関係逆転の原則では、この依存の方向を逆にしようというのです。
つまり、②が①に依存するのではなく、①が②に依存するべきだということです。
その実現方法が抽象(インターフェースなど)を用いるというものです。
では何故、依存関係を逆にしたほうが良いのでしょうか。
先ほどの例で①が仮にRDBでOracleを使っていると仮定します。
APIを保守していくうえで、DBのバージョンを上げたり、他のRDBを使ったり、あるいはKVSなど別の種類のデータソースを使ったりするというような変更を加えるときがあるかもしれません。
そうなると、当たり前ですが①の処理を変更することになります。それに従って、①の引数や返り値が変わり、②の処理も変更を余儀なくされます。
これでは変更容易性が高いとは言えません。
データソースを変更するという外界の影響がAPIのあらゆる処理に影響を与えてしまうという状態を解決するために、②が①に依存するのではなく、①が②に依存するようにすべきです。
そうすれば、データソースを変更しても①だけを修正すればOKになります。
具体的には、依存関係逆転の法則を適用するで述べたように、②を抽象に依存させ、①は抽象の実装(抽象に依存)をすればよいですね。