1. はじめに:なぜマーケティングにおいて「解釈性」が重要なのか?
データ分析の実務、特にマーケティングの現場において、「予測精度の高さ」と「解釈性の高さ」はしばしばトレードオフの関係になります。
LightGBMやXGBoostといった強力なアンサンブル学習を用いれば、高精度な予測モデルを構築することは可能です。しかし、「なぜその予測になったのか?」がブラックボックス化してしまうと、現場のマーケターは「誰に、どんな施策を打てばいいのか」という具体的なアクションを設計できません。
本記事では、あえて解釈性に特化した分類木アルゴリズムである「CHAID(カイド)」を採用し、Eメールマーケティングの最適セグメントを発見・可視化するプロセスを実践します。
2. 本記事のゴールとビジネス課題
今回は、マーケティングデータセットとして有名な「Kevin Hillstrom Dataset」を使用します。
このデータには、過去の購買履歴(Recency, Historyなど)、顧客属性(Zip_code, Newbieなど)、そして「Eメールキャンペーンに対する反応(Visit, Conversion, Spend)」が記録されています。
【ビジネス課題】
全顧客に無差別にメールを配信すると、配信コストがかさむだけでなく、顧客のオプトアウト(配信停止)を招くリスクがあります。
【ゴール】
「どのような属性を持つ顧客層(セグメント)が、Eメールによって最もコンバージョン(CV)しやすいか」を明らかにし、ROIを最大化するためのターゲティング戦略を立案します。
3. 分析手法の選定:あえて「CHAID」を選ぶ理由
決定木アルゴリズムといえばCARTが有名ですが、今回はCHAID(Chi-square Automatic Interaction Detection)を使用します。その理由は以下の2点です。
- カテゴリ変数の自然な分岐: CARTが必ず「2分岐」を行うのに対し、CHAIDは「都市部」「郊外」「地方」といったカテゴリを、有意差の有無に基づいて柔軟に多分岐(または結合)できます。
- 統計的根拠に基づく剪定: カイ二乗検定を用いて、分岐による差が統計的に有意でない場合は木の成長をストップするため、過学習を防ぎつつ「マーケターが見て納得感のあるセグメント」を自動生成してくれます。
4. データの前処理とモデル構築
Pythonの CHAID パッケージを用いて実装を行います。(データクレンジング等の全コードはこちらのGitHubに公開しています)
import pandas as pd
from CHAID import Tree
# データの読み込みと前処理(一部抜粋)
# 目的変数をコンバージョン(CV: 1 or 0)に設定
df = pd.read_csv('kevin_hillstrom_data.csv')
features = ['recency', 'history_segment', 'zip_code', 'newbie', 'channel']
target = 'conversion'
# CHAIDモデルの構築
# alpha_merge=0.05 とし、p値が5%以上ならカテゴリをマージする設定
tree = Tree.from_pandas_df(
df,
i_variables=features,
d_variable=target,
alpha_merge=0.05,
max_depth=3,
min_child_node_size=50
)
5. 分析結果:データが示す「3つの重要セグメント」
モデルを学習させた結果、単なるCVRの高低だけでなく、「どのメールを送るべきか(あるいは送るべきではないか)」が明確に分かれる興味深いセグメントが抽出されました。
ダッシュボードを用いたシミュレーションにより、以下の主要なインサイトが得られました。
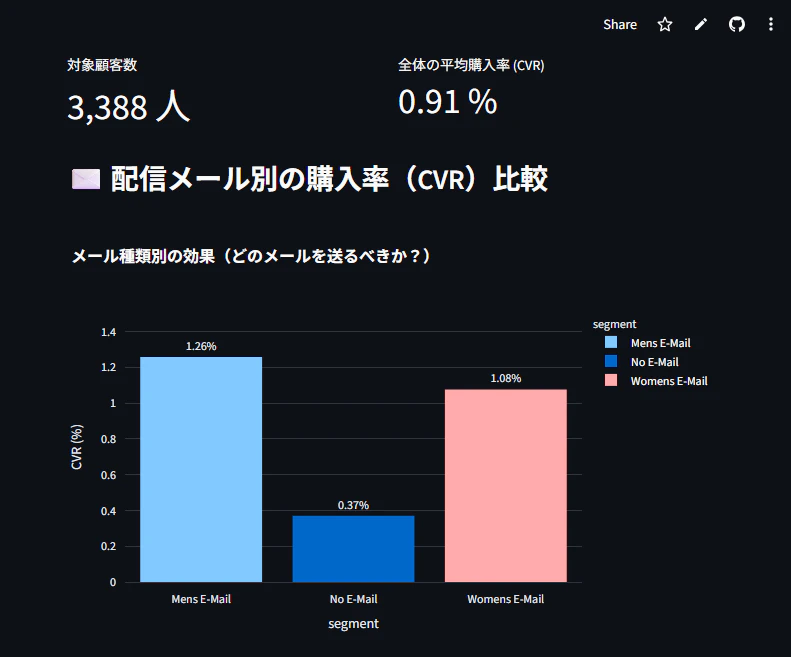
💎 セグメントA:隠れたポテンシャル層(低単価 × 地方在住)
-
条件: 過去の購買金額が低く(
$0 - $100)、地方(Rural)に住んでいる層 - 結果: 何も配信しない(No E-Mail)場合のCVRは 0.37% と低いですが、Mens E-Mailを配信するとCVRが 1.26%(約3.4倍)に跳ね上がることが判明しました。「購買意欲が低い」と切り捨てられがちな層ですが、適切なアプローチで確実な売上増が見込めます。
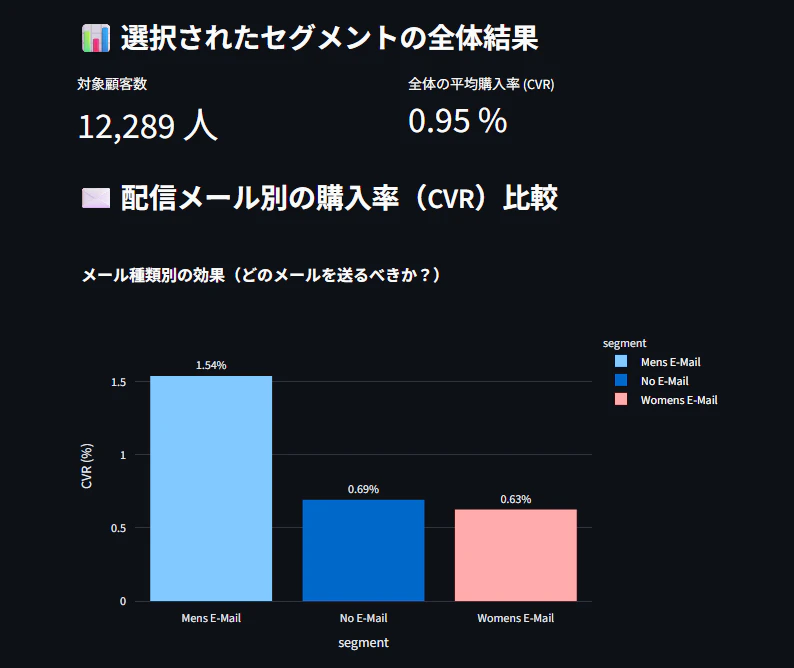
🎯 セグメントB:Mens E-Mail特化層(中単価層)
-
条件: 過去の購買金額が中程度(
$200 - $350)の層 - 結果: この層に対しては、Womens E-Mailを配信しても「未配信(No E-Mail)」とCVRに有意な差が出ない(=女性向けメールの効果がない)ことがCHAIDの分岐から読み取れました。一方で、Mens E-Mailを配信した時のみCVRが有意に上昇します。
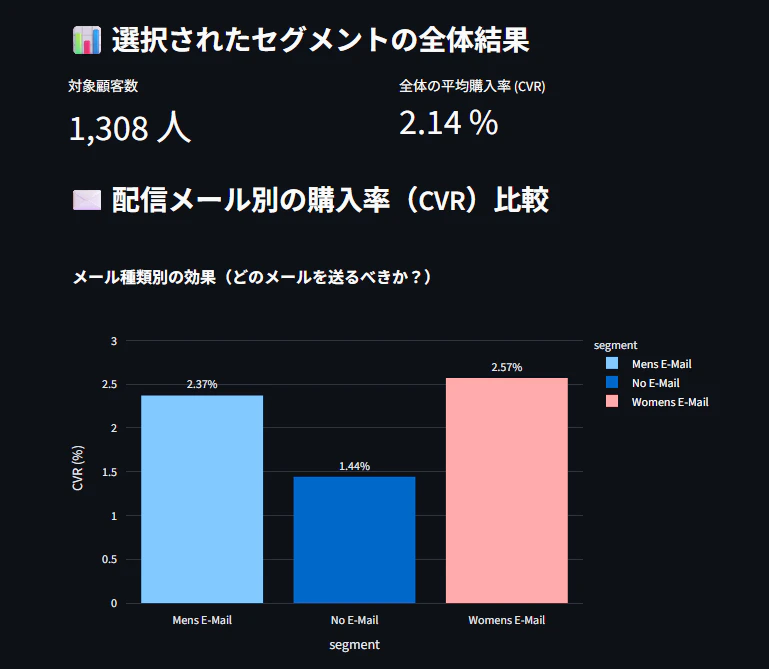
🛑 セグメントC:メールの「真の押し上げ効果」が不透明な層(超高単価層)
-
条件: 過去の購買金額が最も高い(
$1,000 +)層 -
結果と統計的解釈:
ダッシュボード上の単純集計では、メール配信群のCVR(2%台)が未配信群(1.44%)を上回っているように見えます。しかし、CHAIDの決定木において、この層にはsegment(メールの種類)による分岐が現れませんでした。これは、ダッシュボード上の見た目の差が「統計的に有意な差ではない(=偶然の誤差の範囲内であり、確実なメールの効果とは断言できない)」ことを示しています。 -
インサイト:
もともと自然流入での購入確率が高いロイヤルカスタマー層であるため、「誤差の範囲かもしれない売上増」を狙って一斉配信のコストやオプトアウト(配信停止)のリスクをかけるよりも、別のCRM施策を検討すべき層だと言えます。
CHAIDアルゴリズムによる分岐結果の全容は以下の通りです。
(※長いため折りたたんでいます。クリックして展開できます)
CHAIDの分類ツリー出力(生データ)を見る
(■ Kevin Hillstrom データセット:CHAID 分類ツリー
([], {0: 63422.0, 1: 578.0}, (history_segment, p=3.928007839599126e-13, score=60.819382601591485, groups=[['1) $0 - $100', '2) $100 - $200'], ['3) $200 - $350'], ['4) $350 - $500', '6) $750 - $1,000', '5) $500 - $750'], ['7) $1,000 +']]), dof=3))
|-- (['1) $0 - $100', '2) $100 - $200'], {0: 36961.0, 1: 263.0}, (segment, p=2.413508679021971e-06, score=22.234085913667425, groups=[['Mens E-Mail', 'Womens E-Mail'], ['No E-Mail']]), dof=1))
| |-- (['Mens E-Mail', 'Womens E-Mail'], {0: 24565.0, 1: 211.0}, (recency, p=0.007568449062945799, score=7.132846325848508, groups=[[1], [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]]), dof=1))
| | |-- ([1], {0: 2474.0, 1: 33.0}, <Invalid Chaid Split> - the max depth has been reached)
| | +-- ([2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12], {0: 22091.0, 1: 178.0}, <Invalid Chaid Split> - the max depth has been reached)
| +-- (['No E-Mail'], {0: 12396.0, 1: 52.0}, (newbie, p=0.00024705436349124526, score=13.434381949452566, groups=[['新規'], ['既存']]), dof=1))
| |-- (['新規'], {0: 6016.0, 1: 12.0}, <Invalid Chaid Split> - the max depth has been reached)
| +-- (['既存'], {0: 6380.0, 1: 40.0}, <Invalid Chaid Split> - the max depth has been reached)
|-- (['3) $200 - $350'], {0: 12172.0, 1: 117.0}, (segment, p=2.1050029834438394e-06, score=22.49674215008225, groups=[['Mens E-Mail'], ['No E-Mail', 'Womens E-Mail']]), dof=1))
| |-- (['Mens E-Mail'], {0: 4027.0, 1: 63.0}, (newbie, p=0.018696819038675042, score=5.529652433377164, groups=[['新規'], ['既存']]), dof=1))
| | |-- (['新規'], {0: 1403.0, 1: 13.0}, <Invalid Chaid Split> - the max depth has been reached)
| | +-- (['既存'], {0: 2624.0, 1: 50.0}, <Invalid Chaid Split> - the max depth has been reached)
| +-- (['No E-Mail', 'Womens E-Mail'], {0: 8145.0, 1: 54.0}, (recency, p=0.005512450538767705, score=7.703151173990445, groups=[[1, 2, 3], [4, 5, 6, 7, 8, 9, 10, 11, 12]]), dof=1))
| |-- ([1, 2, 3], {0: 3032.0, 1: 30.0}, <Invalid Chaid Split> - the max depth has been reached)
| +-- ([4, 5, 6, 7, 8, 9, 10, 11, 12], {0: 5113.0, 1: 24.0}, <Invalid Chaid Split> - the max depth has been reached)
|-- (['4) $350 - $500', '6) $750 - $1,000', '5) $500 - $750'], {0: 13009.0, 1: 170.0}, (segment, p=7.82413263385576e-05, score=15.600320486603511, groups=[['Mens E-Mail'], ['No E-Mail', 'Womens E-Mail']]), dof=1))
| |-- (['Mens E-Mail'], {0: 4258.0, 1: 80.0}, <Invalid Chaid Split> - the node only contains single category respondents)
| +-- (['No E-Mail', 'Womens E-Mail'], {0: 8751.0, 1: 90.0}, (recency, p=0.004488895217712591, score=8.074642913465201, groups=[[1, 2, 3, 4, 5], [6, 7, 8, 9, 10, 11, 12]]), dof=1))
| |-- ([1, 2, 3, 4, 5], {0: 5644.0, 1: 71.0}, <Invalid Chaid Split> - the max depth has been reached)
| +-- ([6, 7, 8, 9, 10, 11, 12], {0: 3107.0, 1: 19.0}, <Invalid Chaid Split> - the max depth has been reached)
+-- (['7) $1,000 +'], {0: 1280.0, 1: 28.0}, (zip_code, p=0.04857361285517265, score=3.890028031561463, groups=[['Rural', 'Surburban'], ['Urban']]), dof=1))
|-- (['Rural', 'Surburban'], {0: 770.0, 1: 22.0}, <Invalid Chaid Split> - p-value greater than alpha merge)
+-- (['Urban'], {0: 510.0, 1: 6.0}, (channel, p=0.04043225565969357, score=4.199652844744455, groups=[['Multichannel'], ['Phone', 'Web']]), dof=1))
|-- (['Multichannel'], {0: 211.0, 1: 0}, <Invalid Chaid Split> - the minimum parent node size threshold has been reached)
+-- (['Phone', 'Web'], {0: 299.0, 1: 6.0}, <Invalid Chaid Split> - the minimum parent node size threshold has been reached)
)
6. ビジネスへの提言(Next Action)
上記の分析結果とダッシュボードのシミュレーションから、次回のEメールマーケティング・キャンペーンに向けて以下の具体的なアクションプランを提案します。
1. 「セグメントA」へのMens E-Mail集中配信による売上創出
これまで「低単価だから」と配信優先度を下げていた地方在住の顧客に対し、意図的にMens E-Mailの配信テストを実施します。自然購入(0.37%)からのリフト幅が大きいため、最も高い配信ROIが期待できます。
2. 「セグメントB」におけるWomens E-Mailの配信停止
中単価層に対するWomens E-Mailは効果がない(No E-Mailと同等)ため、この層へのWomensコンテンツの配信を停止します。これにより、無駄な配信コストの削減と、顧客の「メルマガ離れ(オプトアウト)」を防ぐことができます。
3. 「セグメントC(超優良顧客)」への一斉配信の停止とCRM戦略の転換
過去の購買金額が$1,000を超える超優良顧客層に対しては、通常の販促メール(Mens/Womens)の配信を停止、または極力控えることを推奨します。
データ上、この層は自然流入でも購入確率が高く、一斉配信メールによる「統計的に確実な売上の押し上げ効果」は確認できませんでした。すでにブランドへのロイヤルティが高い顧客に対し、明確な効果がないままセールスメールを連発することは、最悪の場合「メルマガのオプトアウト(配信解除)」や「ブランドへの嫌悪感」という致命的なリスクを招きます。
この層には通常キャンペーンのメールは打たず、代わりに「VIP顧客限定の特別なご案内」や「バースデー特典」など、LTV(顧客生涯価値)をさらに高めるための1to1のCRM施策へとリソースを振り向けるべきです。
4. ダッシュボードを活用した現場主導のターゲティング運用
今回開発したシミュレーションダッシュボードをマーケティング担当者に展開し、キャンペーンのたびに「今回の商材ならどの属性に当てるべきか」を現場自身で探索・決定できる運用フローを構築します。
💡 結論
このように、CHAIDによる統計的な分類とダッシュボードを組み合わせることで、「誰に送るか」だけでなく、「誰に送らないべきか」というROI最適化の意思決定が可能になります。
7. シミュレーション・ダッシュボード
分析結果を静的なレポートとして終わらせず、現場の担当者が直感的にセグメントの条件を調整できるよう、Streamlitを用いてインタラクティブなダッシュボードを作成しました。
以下のリンクから、実際に顧客の属性(過去の購買金額、地域、新規/既存など)を条件で絞り込み、「どのセグメントに、どのメールを配信すれば購入率(CVR)が最も高くなるのか」のシミュレーションを体験いただけます。
👉 マーケティングセグメント探索ダッシュボード(Streamlit)を開く
※無料サーバーを利用しているため、初回アクセス時に起動まで1〜2分ほど(Zzzzという画面)お待ちいただく場合がございます。
8. おわりに&今後の展望
今回はCHAIDを用いたセグメンテーションを行いましたが、これはあくまで「相関」に基づく分析です。Eメールを送った「から」買ったのか、元々買う予定だった人がメールを見た「だけ」なのかを切り分けるには至っていません。
今後は、因果推論(傾向スコアやUplift Modelingなど)の手法を取り入れ、より精緻なマーケティングROIの算出に挑戦していきたいと考えています。
最後までお読みいただき、ありがとうございました。
コードの詳細やダッシュボードの裏側については、ぜひこちらのGitHubリポジトリもご覧ください。