Linux Advent Calendar 2019 四日目の記事です。Linux perfの使い方は知ってるけど割と不便に感じることがあるのを解消したいという人を対象読者にしています。
なお、perfに元々興味があるけどmanを見てもどう使うのかイマイチわからない、という人は 僕が最初に読んだ記事 … はいつのまにか消えていたので、Brenden Gregg先生のサイト (今見ると、この記事の内容も大体カバーされていますね) に行くか、日本語で読みたい人は詳解システム・パフォーマンスを読んでも概要はわかりそうです。
1. libc6-dbgを入れる
デバッグ対象のプログラムをデバッグシンボル付きでコンパイルしておかないと困るのはまあ当然ですが、そうしていてもlibcなどで未解決のシンボルが登場してしまい、関数名がわからないことがあります。
0.23% ruby libc-2.27.so [.] 0x00000000000950dd
知っていると割と当然に感じますが、 sudo apt install libc6-dbg などでlibc6-dbgというパッケージを入れるとlibcのシンボルも解決できるようになります。
1.11% ruby libc-2.27.so [.] _int_malloc
これがあるのとないのとでは分かりやすさが全然違うので、perfを使う時は常に入れておくようにすると便利です。
2. --call-graph は fp 以外で使う
上記の問題を解決すると perf record + perf report では何が呼ばれているかおおむね分かることが多いのですが、call graphを出すために perf record -g をすると [unknown] というのが出てきてしまうことがあります。(以降の計測結果はRack::Utils::HeaderHashを使ったRuby VMのベンチをRubyのmasterで走らせたものです)
Samples: 38K of event 'cycles:ppp', Event count (approx.): 271180000
Children Self Command Shared Object Symbol
- 15.64% 0.00% ruby [unknown] [.] 0000000000000000
- 0
2.20% gc_mark_ptr
1.73% gc_mark_children
1.33% vm_call_cfunc
1.29% gc_aging
1.26% rgengc_check_relation.part.95
1.04% vm_exec_core
0.84% 0x20000
0.72% gc_sweep_step
+ 13.76% 13.43% ruby ruby [.] rb_st_lookup
+ 11.82% 11.73% ruby ruby [.] vm_exec_core
- 10.98% 0.00% ruby [unknown] [.] 0x0000555555bcf598
- 0x555555bcf598
1.57% rb_memhash
1.30% rb_str_downcase
0.62% ar_update
0.56% rb_hash_aref
0.53% rb_hash_default_value
+ 6.58% 6.42% ruby ruby [.] rgengc_check_relation.part.95
- 5.14% 0.00% ruby [unknown] [.] 0x00000000000015c0
- 0x15c0
2.09% vm_call_cfunc
1.02% vm_exec_core
いやあ、shared objectが [unknown] になってしまうと訳がわかりませんね。
/proc/$pid/map を見ても 0x0000555555bcf598 は [heap] のところにいたりとか、gdbでx/iしても単に 0000... な時の命令が出てるだけとか、そもそも 0000000000000000 が呼び出されるて何やねんとか。
[unknown] 問題に対するBrenden Gregg氏のコメントでは、例えばJavaだと-XX:+PreserveFramePointerをつけ、jvm-profiling-tools/perf-mapagentも利用する必要があるとしていて、アプリごとにどうにかしていく必要がある感じがしています。
じゃあ、と思ってGCCの-fno-omit-frame-pointerをいれてみても、0000000000000000は消えても、他のところでよくわからないアドレスが残ったりしました。
この問題は、私の環境では --call-graph に渡すオプションを、デフォルトの fp (frame pointer) ではなく dwarf や lbr にすることで解決しました。
--call-graph dwarf
このオプションでは、frame pointerがないような状況でもlibunwindがdwarfを使ってfpをunwindしてくれるため、上記の問題を解決してくれることがあるのに加え、本来インライン化されてフレームが存在しないような関数の情報も見ることができます。
Samples: 35K of event 'cycles:ppp', Event count (approx.): 246764000
Children Self Command Shared Object Symbol
- 85.75% 10.77% ruby ruby [.] vm_exec_core
- 74.98% vm_exec_core
- 63.48% vm_sendish (inlined)
- 40.67% vm_call_method
- 40.32% vm_call_cfunc
- 40.11% vm_call_cfunc_with_frame (inlined)
+ 31.27% enum_collect
+ 8.14% rb_hash_aset
- 20.99% vm_call_cfunc
- 20.56% vm_call_cfunc_with_frame (inlined)
+ 18.54% rb_str_downcase
0.56% rb_str_freeze
1.19% vm_search_super_method
+ 4.28% vm_opt_aset (inlined)
+ 3.89% vm_getinstancevariable (inlined)
+ 3.27% vm_opt_aref (inlined)
- 10.22% _start
__libc_start_main
main
ruby_run_node
rb_ec_exec_node
rb_vm_exec
+ vm_exec_core
- 85.29% 0.43% ruby ruby [.] rb_vm_exec
84.87% rb_vm_exec
+ vm_exec_core
+ 85.20% 0.00% ruby ruby [.] _start
+ 85.20% 0.00% ruby libc-2.27.so [.] __libc_start_main
+ 85.20% 0.00% ruby ruby [.] main
VM本体の処理である vm_exec_core にかかる時間85.75%のうち、enum_collect で実装されたメソッド本体に31.27%、rb_str_downcase は 18.54%、Hashに値をセットする vm_opt_aset には 4.28%、インスタンス変数の取得 vm_getinstancevariable は3.87% かかっていた、ということがわかります。このうちいくつかはinlinedであり、本来VM本体の vm_exec_core 単体として出てきてしまうはずのものであるにも関わらず、です。これを見たらVMのどのあたりを最適化すべきか、というのがなんとなくわかりますね。
上記の -g のグラフと計測しているものは同じなのですが、正しく集計できるようになったからか、それぞれの関数が占める割合も全然違うものになっています。
一方、次に述べるlbrに比べると、Dwarf2 unwinding also does not always work and is extremely slow (upto 20% overhead) という欠点があるようです。
--call-graph lbr
lbrはHaswellのLast Branch Recordを使ってcall chainを保存するオプションです。この機能が有効になると、on-chipなLBRレジスタを使ってcallgraphを保存しようとするため、frame pointerに依存しなくとも軽量にcallgraphを保存することができるようです。
これを使うと、同じものを計測した時以下のような出力になります。
Samples: 68K of event 'cycles:ppp', Event count (approx.): 476567000
Children Self Command Shared Object Symbol
- 95.02% 10.94% ruby ruby [.] vm_exec_core
- 86.37% vm_exec_core
- 40.20% vm_call_cfunc
+ 33.48% rb_str_downcase
1.73% call_cfunc_m1
+ 0.69% rb_str_freeze
0.51% CALLER_SETUP_ARG
0.51% call_cfunc_0
- 18.34% vm_call_method
- 16.66% vm_call_cfunc
+ 8.18% rb_hash_aset
+ 7.04% rb_class_s_new
1.07% call_cfunc_2
1.68% vm_call_method_each_type
+ 6.66% rb_hash_aset
+ 4.95% rb_hash_aref
4.54% rb_st_lookup
+ 4.16% rb_hash_new_with_size
+ 2.06% vm_setivar.isra.358
2.02% vm_search_super_method
0.55% vm_call_iseq_setup_normal_0start_2params_3locals
0.97% rb_memhash
0.97% rb_st_lookup
0.67% vm_call_cfunc
+ 0.60% int_dotimes
+ 63.10% 3.86% ruby ruby [.] vm_call_cfunc
+ 39.69% 5.04% ruby ruby [.] gc_mark_children
+ 38.83% 1.62% ruby ruby [.] newobj_slowpath_wb_protected
+ 35.43% 1.67% ruby ruby [.] rb_str_downcase
こちらでも、私の環境では [unknown] なshared objectは出ませんでした。fpのunwindをしないのでinline化された関数の情報は見れませんが、逆に実際フレームにになっている呼び出しを見ることができます。まあこちらでも正しく割合が計測できるようになった風なので概要は正しくわかりますし、dwarfオプションに比べ計測が軽量なため結果もより正確なはずなのも利点でしょう。
一方、LBRはスタックの深さが8, 16, あるいは32フレームまでしか計測を行なってくれないという欠点があるようです。スタックが深い用途や、次に述べるFlameGraphには向かないとされています。
3. FlameGraphの出し方
perf reportの普通のcall graphの出力もシンプルでいいですが、brendangregg/FlameGraphを使うと結果をflame graphとして可視化することができます。
使い方はREADMEの通りですが、PATHを通しておくと以下のように使えます。
sudo perf script | stackcollapse-perf.pl | flamegraph.pl > flamegraph.svg
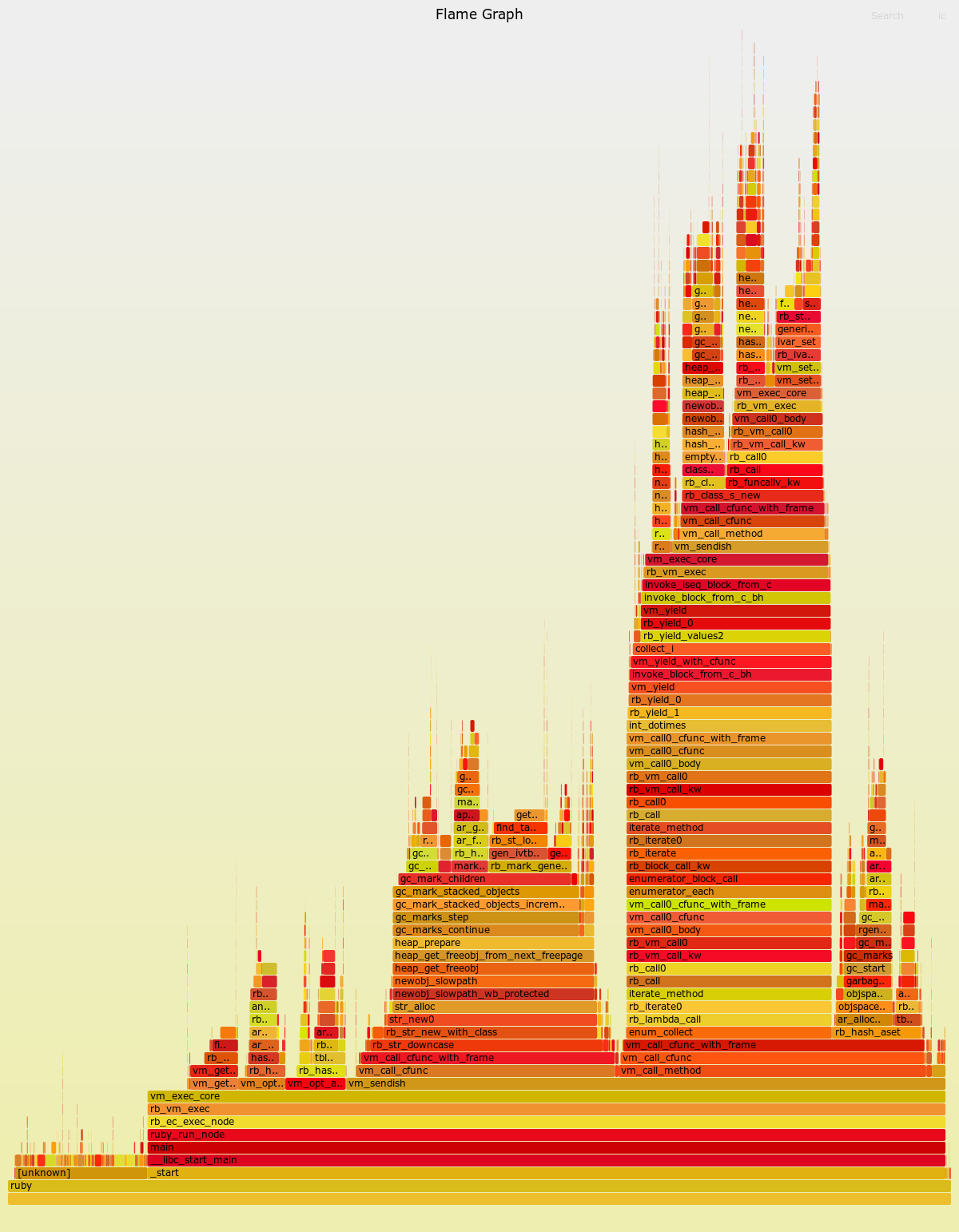
ブラウザで開くと、小さいフレームもホバーすると何なのかわかるので便利です。以下に perf record --call-graph dwarf で計測したflame graphの例を貼っておきますので、RubyのVMがどのようなフローで処理をしているか興味のある方はどうぞ。(SVG版)
余談: ソースだけでannotateしたい場合
デバッグシンボルをつけてperfでannotateをするとasmと一緒に元になったCのソースを見ることができますが、これができるならCのソースだけ見たい、と思ったことはありませんか?
どうやらperf annotateは裏側でobjdumpを使っているだけらしく、Cのソースだけ見る、というのは私の知る限り現時点ではサポートされてないようです。
Linux perf同様にイベントをサンプリングして同じような計測ができるツールにOProfileというのがあり、LinuxでCのソースだけを見てプロファイリングをしたい場合はこちらが使えるようです。(さらに余談: macOSだとXCode InstrumentsのTime Profilerが使えそうです)
sudo apt install oprofile でインストール、 sudo operf --pid <pid> で起動して SIGINT で終了、 opannotate -s とすると計測結果とCのコードがバーッと出てきます。この記事を読んでいる人は Migrating from OProfile to perf, and beyond を逆引きすると便利かもしれません。
これ自体は便利そうなのですが、CRubyのJITコンパイラが生成するshared objectの部分ではopannotateが全く動かず、デバッグも面倒なのので私はとりあえずperf annotateで我慢することにしました。Linux perfの方が取れるイベントの種類が多いようなので、いつかperfでもどうにか同じことができるようになるといいですね。 (追記: できるようにしました https://github.com/k0kubun/perf-profile)
メモ: sudoなしで実行する時の準備
perfはsudoなしでも実行できるが、以下のようなwarningが出る。
WARNING: Kernel address maps (/proc/{kallsyms,modules}) are restricted,
check /proc/sys/kernel/kptr_restrict and /proc/sys/kernel/perf_event_paranoid.
Samples in kernel functions may not be resolved if a suitable vmlinux
file is not found in the buildid cache or in the vmlinux path.
Samples in kernel modules won't be resolved at all.
If some relocation was applied (e.g. kexec) symbols may be misresolved
even with a suitable vmlinux or kallsyms file.
Couldn't record kernel reference relocation symbol
Symbol resolution may be skewed if relocation was used (e.g. kexec).
Check /proc/kallsyms permission or run as root.
rootで以下のコマンドを実行すると直すことができる。
echo 0 > /proc/sys/kernel/perf_event_paranoid
echo 0 > /proc/sys/kernel/kptr_restrict
メモ: Cannot load tips.txt file, please install perf!
tips.txt を /usr/share/doc/perf-tip/tips.txt に置けばいいらしい
参考: https://askubuntu.com/questions/1171494/how-to-get-perf-fully-working-with-all-features
メモ: Firefox Profiler
perf script -F +pid > test.perf でperf.dataを変換した後これを https://profiler.firefox.com にアップロードすると、リッチなUIでperfの出力を眺めることができる。
参考: https://profiler.firefox.com/docs/#/./guide-perf-profiling