はじめに
HTMLのCanvasとTypeScriptでタイピングゲームを開発しました。
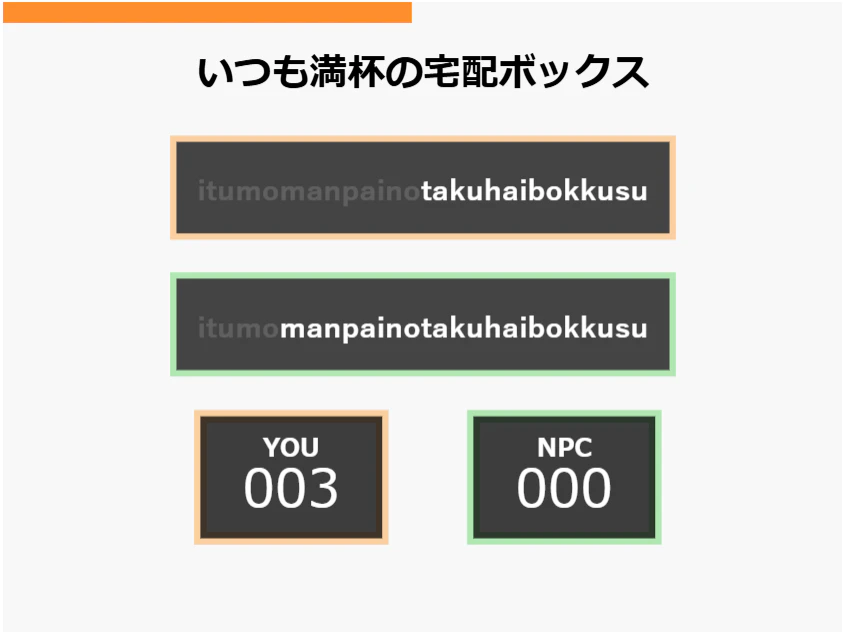
リアルタイムでNPCと入力速度を競うタイピングゲームです。
オレンジ枠がプレイヤーの入力欄、緑がNPCの入力欄です。
NPCの強さは3段階あります。
以下のページで遊べます。※音が鳴ります
本記事では、タイピングゲームの入力アルゴリズムを中心に解説します。
アルゴリズム
タイピングゲームのアルゴリズムは、大まかにまとめると以下の通りです。
- キーボードから入力した文字を1文字受け取る
-
1.で取得した文字と現在の文字を比較する - 一致しているなら、現在の文字を1文字進める
-
1.~3.を繰り返して、全ての文字を入力したら完了とする
簡単な方法
とりあえずパッと思いつくコードは以下のような感じでした。
// 日本語の文章とアルファベットの文章
const word = { display: "こんにちは", input: "konnnitiha" }
let idx = 0;
while (...) {
// 入力文字を受け取る
const ch = inputKey();
// 入力文字と現在の文字が一致するか
if (ch == word.input[idx]) {
// 次の文字へ進める
idx += 1;
if (idx >= word.input.length) {
// 入力完了
...
}
} else {
// 入力ミス
...
}
...
}
比較的シンプルなコードですが、これには致命的な弱点があります。
それは表示された通りの入力しか受け付けない点です。
例えばローマ字入力において「こ」はkoとcoの2通りの入力方法があります。
しかし、上記のコードではkoしか入力として受け付けられません。
このままでは柔軟性がないので、別の方法を考える必要があります。
木構造を使った入力方法
次に考えたのは、平仮名毎に入力方法を木構造で表す方法です。
例えば「し」はsi、shi、ciの3つの入力方法があります。
その3つの入力方法を以下のような木構造で表します。
し
┣━ s
┃ ┣━ i
┃ ┗━ h
┃ ┗━ i
┗━ c
┗━ i
ここからどのように入力を受け付けるかを順を追って説明します。
初期状態ではルートノードにいます。
し ← 現在地
┣━ s
┃ ┣━ i
┃ ┗━ h
┃ ┗━ i
┗━ c
┗━ i
まず、子ノードのアルファベットを見てどの文字が入力可能か調べます。
現在のルートノードではs、cの2つが入力可能な文字です。
この状態でsを入力した場合、現在地をsの子ノードに移動させます。
し
┣━ s ← 現在地
┃ ┣━ i
┃ ┗━ h
┃ ┗━ i
┗━ c
┗━ i
この現在地から見ると入力可能な文字はi、hの2つです。
この状態でiを入力した場合はiの子ノードに移動します。
iの子ノードはノードを持っていないので、ここで「し」の入力が完了したと判定します。
し
┣━ s
┃ ┣━ i ← 現在地(入力完了)
┃ ┗━ h
┃ ┗━ i
┗━ c
┗━ i
このように木構造を使うと、複数の入力に対応することができます。
Nodeクラス
上記の木構造をコードにします。
charはそのノードが持つ文字です。ルートノードの場合は空文字です。
childrenは子ノードです。子ノードを持たなければundefinedです。
その他にノード追加する関数、ノードを探索する関数、予測文字列を返す関数があります。
node.ts
export class Node {
char: string;
children?: Node[];
constructor(char: string, children?: Node[]) {
this.char = char;
this.children = children;
}
/**
* ノードを追加する
* @param child ノード
*/
push(child: Node) {
if (this.children === undefined) {
this.children = [];
}
this.children.push(child);
}
/**
* 指定した値を持つノードを返す
* @param char
* @returns 指定した値を持つノード。なければundefined
*/
find(char: string): Node | undefined {
return this.children?.find((child: Node) => child.char === char);
}
/**
* 予測文字列を返す
* @returns 予測文字列
*/
getPrediction(): string {
const children = this.children;
return this.char + (children === undefined ? '' : children[0].getPrediction());
}
}
上記で説明したような木構造を生成するのが下記のcreateNode関数です。
引数に入力方法の文字列の配列を受け取ります。
たとえば「し」の場合は["si", "shi", "ci"]です。
/**
* 入力文字列からノードを作成する
* @param inputs 入力文字列
* @returns ノード
*/
export const createNode = (inputs: string[]): Node => {
const root = new Node('', []);
for (const input of inputs) {
let node = root;
// 1つずつノードを進めていき、見つからなければ新しいノードを追加する
Array.from(input).forEach((char) => {
const child = node.find(char);
if (child === undefined) {
// 新しいノードを追加して進める
const newChild = new Node(char);
node.push(newChild);
node = newChild;
} else {
// ノードを追加せずに進める
node = child;
}
});
}
return root;
};
平仮名「し」の木構造が生成される過程を順番に説明します。
まず空のルートノードにsiを追加すると以下のような構造になります。
ルートノード直下にsと、その子であるiが追加されています。
┗━ s
┗━ i
次にこの状態からshiを追加すると以下の構造になります。
sは既に存在するので追加されていません。
またsの下にhと、その子のiが追加されています。
┗━ s
┣━ i
┗━ h
┗━ i
最後にciを追加すると以下の構造になります。
ルートノード直下にcと、その子のiノードが追加されています。
┣━ s
┃ ┣━ i
┃ ┗━ h
┃ ┗━ i
┗━ c
┗━ i
NodeSearcherクラス
上記のNodeクラスには現在地を進めたり、進行履歴を保持する機能はありません。
そういった機能は新たに追加するNodeSearcherクラスで実装します。
node-seracher.ts
export class NodeSearcher {
current: Node;
isEnd: boolean;
history: string[];
constructor(root: Node) {
this.current = root;
this.isEnd = false;
this.history = [];
}
contains(char: string): boolean {
return this.current.find(char) !== undefined;
}
/**
* 現在地ノードを先へ進める
* @param char 入力文字
*/
step(char: string) {
const child = this.current.find(char);
if (child !== undefined) {
this.current = child;
this.isEnd = child.children === undefined;
this.history.push(char);
}
}
/**
* 入力履歴+予測文字列を返す
* @returns
*/
getCompletion(): string {
const history = this.history.join('');
const children = this.current.children;
const completion = children === undefined ? '' : children[0].getPrediction();
return history + completion;
}
}
step関数はノードの現在地を進める関数です。
子ノードのいずれかが入力された文字を保持しているなら、現在地をその子ノードへ進めます。
その場合、入力された文字をhistoryに追加します。
そのノードが子ノードを保持していない場合は終端に到達したので、isEndフラグをtrueにします。
getPrediction関数は「これまでの入力履歴 + ノードの現在地から予測される残りの文字列」を返す関数です。
例えば「し」の場合で、入力履歴が空なら先頭のノードを順にたどりsiという文字列を返します。
これ以外にも、入力パターンとして正しければ受け入れることが可能です。
その場合はgetCompletion関数が返す文字列は変わります。
例えば先程の「し」例で、入力履歴が['s'、'h']の場合、現在地を基にshiという文字列を返すようになります。
このようにNodeSearcherクラスを使って、表示された以外の正しい入力パターンを受け入れ可能にします。
実際の画面では入力に応じて表示される文字列が変化します。
入力パターンの列挙
連想配列を使って、全ての入力パターンを列挙します。
まずは、1文字の場合の入力パターンを以下の様に連想配列を使って全て列挙します。
この連想配列には平仮名以外にも、英数字と記号が含まれています。
const singlePatterns: Record<string, string[]> = {
あ: ['a'],
い: ['i', 'yi'],
う: ['u', 'wu'],
え: ['e'],
お: ['o'],
か: ['ka', 'ca'],
き: ['ki'],
く: ['ku', 'cu'],
け: ['ke'],
こ: ['ko', 'co'],
...
}
次に「きゅ」や「しゃ」等の2文字の場合のパターンを考えます。これらの文字は大きく分けて2通りの入力方法があります。
「しゃ」を例として考えます。
- ひとまとまりとして入力する方法
sya、sha - 前の文字と後ろの文字を別々に入力する方法
silya、sixya、shilya、shixya、cilya、cixya
このように1文字の場合よりも入力のパターンが多いため、全てのパターンを予め列挙するのはかなり大変です。そこで以下の様な方法を行います。
連想配列には、ひとまとまりとして入力する方法だけを列挙しておきます。
const tmpMultiPatterns: Record<string, string[]> = {
いぇ: ['ye'],
きゃ: ['kya'],
きぃ: ['kyi'],
きゅ: ['kyu'],
きぇ: ['kye'],
きょ: ['kyo'],
しゃ: ['sya', 'sha'],
...
}
前後別々に入力するパターンは、上記で定義したsinglePatternsを使って動的に生成します。1文字目と2文字目の入力方法の積を返す関数は以下の様になります。
export const createMultiPattern = (input: string): string[] => {
if (input.length != 2) {
return [];
}
// 1文字目と2文字目の入力方法の積を返す
const patterns1 = singlePatterns[input.charAt(0)];
const patterns2 = singlePatterns[input.charAt(1)];
return patterns1.flatMap((str1) => patterns2.map((str2) => str1 + str2));
};
例えば、この関数に「しゃ」を渡すと以下の様に入力パターンを生成します。
{「し」の入力パターン} × {「ゃ」の入力パターン}
↓
['si', 'shi', 'ci'] × ['lya', 'xya']
↓
['silya', 'sixya', 'shilya', 'shixya', 'cilya', 'cixya']
この関数で生成した入力パターンをtmpMultiPatternsの値に追加します。
最後にsinglePatternsとtmpMultiPatternsを結合させることで、タイピングに必要な入力パターンを全て列挙した連想配列が完成します。
特殊な入力方法
上記のアルゴリズムでほとんどの文字の入力に対応できます。しかし、まだ対応できてない平仮名が2つあります。
それは「ん」と「っ」です。それぞれの特徴を以下に挙げます。
「ん」の特徴
- 単体で入力するパターンは
nn、xn - 以下の条件を満たす場合、
n1回で入力可能- 「ん」の次に文字が来る
- その文字があ行、な行、や行、ん以外
※ 例えば「たんご」はtangoと入力可能です。
「っ」の特徴
- 単体で入力するパターンは
ltu、xtu、ltsu、xtsu - 以下の条件を満たす場合、次に来る平仮名の子音1回で入力可能
- 「っ」の次に平仮名が来る
- その平仮名があ行、な行、ん以外
※ 例えば「きって」はkitteと入力可能です。
NodeクラスやNodeSearcherクラスは次に来る文字を参照しないため、上記の特殊な入力方法に対応することができません。
そこで、特殊な入力方法にも対応できるAcceptorクラスを作ります。
Acceptorクラス
acceptor.ts
export enum Result {
Accept,
Reject,
}
export class Acceptor {
idx: number = 0;
count: number = 0;
history: string = '';
completion: string = '';
end: boolean = false;
charas: Chara[];
searcher: NodeSearcher;
specialRuleHandlers: Record<string, SpecialRuleHandler>;
constructor(charas: Chara[]) {
this.charas = charas;
this.searcher = new NodeSearcher(this.charas[0].node);
this.specialRuleHandlers = { ん: new NNRuleHandler(), っ: new SmallTsuRuleHandler() };
this.updateCompletion();
}
/**
* 入力文字を受け入れる
* @param char 入力文字
* @return 入力結果
*/
accept(char: string): Result {
const chara = this.charas[this.idx];
const handler = this.specialRuleHandlers[chara.value];
if (handler === undefined) {
return this.step(char);
} else {
return handler.accept(this, char);
}
}
/**
* 入力文字を1文字進める
* @param char 入力文字
* @return 入力結果
*/
step(char: string): Result {
if (!this.searcher.contains(char)) {
return Result.Reject;
}
this.searcher.step(char);
this.count += 1;
this.history += char;
if (this.searcher.isEnd) {
if (this.charas[this.idx + 1] === undefined) {
// 全ての文字を入力した
this.end = true;
} else {
// 次の文字に進む
this.next();
}
} else {
this.updateCompletion();
}
return Result.Accept;
}
/**
* 次の文字に進む
*/
next() {
this.idx += 1;
this.count = 0;
this.searcher = new NodeSearcher(this.charas[this.idx].node);
this.updateCompletion();
}
/**
* 入力文字全体の予測を更新する
*/
updateCompletion() {
...
}
}
/**
* 文字を表すクラス
*/
export class Chara {
value: string;
node: Node;
constructor(value: string, node: Node) {
this.value = value;
this.node = node;
}
/**
* 子音を返す
* @returns 子音の配列 (あ行の平仮名または平仮名以外の場合は空配列)
*/
getConsonants(): string[] {
if (/[あ-おーa-z0-9!?,.[\]]/.test(this.value) || this.node.children === undefined) {
return [];
}
return this.node.children.map((child) => child.char);
}
}
accept関数で入力文字を受け取り、入力結果をResult列挙体で返します。
大抵の文字の場合はstep関数を呼び出して、内部で保持しているNodeSearcherを更新します。
もし、現在入力している文字が「ん」や「っ」の場合は、それぞれに対応したSpecialRuleHandler.aceept関数を呼び出します。
SpecialRuleHandlerインターフェース
special-rule-handler.ts
export interface SpecialRuleHandler {
/**
* 入力文字を受け入れる
* @param acceptor 入力を受け入れるオブジェクト
* @param char 入力文字
* @return 入力結果
*/
accept(acceptor: Acceptor, char: string): Result;
/**
* 予測文字列を返す
* @param chara 文字
* @param nextChara charaに次に来る文字
*/
getCompletion(chara: Chara, nextChara: Chara | undefined): string;
/**
* 現在の予測文字列を返す
* @param searcher 現在入力中の文字のNodeSearcher
* @param nextChara 次に来る文字
*/
getCurrentCompletion(searcher: NodeSearcher, nextChara: Chara | undefined): string;
}
特殊な入力方法に対応するインターフェースです。「ん」や「っ」の判定ロジックはこのインターフェースを継承したクラスに実装します。
全ての判定ロジックをAcceptorクラス内に直接実装すると、クラスが肥大化するので別モジュールとして切り出しました。
Acceptorクラスはこのインターフェースを継承したクラスのインスタンスを保持して、必要に応じて呼び出すようにしています。
「ん」の特殊な入力方法に対応する
NNRuleHandlerクラス
export class NNRuleHandler implements SpecialRuleHandler {
acceptable: boolean = false;
accept(acceptor: Acceptor, char: string): Result {
if (this.acceptable) {
// charと次に来る文字の先頭のいずれかが一致していたら次の文字へ進む
const children = acceptor.charas[acceptor.idx + 1].node.children?.map((child) => child.char);
if (children?.find((c) => c == char)) {
this.acceptable = false;
acceptor.next();
}
}
const result = acceptor.step(char);
if (result == Result.Accept) {
// acceptableフラグが立つのは以下の条件を全て満たす場合
// 1. 現在「n」が1回だけ入力されている
// 2. 次に入力する文字が存在する
// 3. 次に入力する文字があ行、な行、や行、「ん」以外
const history = acceptor.searcher.history;
const validateHistory = history.length == 1 && history[0] == 'n';
const idx = acceptor.idx;
const validateNextChar = this.validate(acceptor.charas[idx], acceptor.charas[idx + 1]);
this.acceptable = validateHistory && validateNextChar;
}
return result;
}
...
/**
* 指定した文字が1回のnで入力できるかの判定処理
* @param chara 現在の文字
* @param nextChara charaの次に来る文字
* @returns
*/
validate(chara: Chara, nextChara: Chara | undefined): boolean {
if (chara.value == 'ん' && nextChara !== undefined) {
return !/[あ-おな-のやゆよん]/.test(nextChara.value);
}
return false;
}
}
現在入力している文字が「ん」の場合、NNRuleHandler.accept関数が呼び出されます。
入力結果が成功(Result.Accept)の場合、acceptableフラグの判定処理を行います。以下の条件を全て満たす場合にフラグがtrueになります。
- 現在、「n」が1回だけ入力されている
- 次に入力する文字が存在する
- 次に入力する文字があ行、な行、や行、「ん」以外
acceptableフラグがtrueの状態で次に来る文字の先頭を入力すると、「ん」の入力を完了させ次に来る文字の入力を開始させます。
入力例1: 「たんご」に対してtanと入力した場合
「ん」に対して「n」が1回入力されており、次に来る文字が「ご」なのでacceptableフラグがtrueになります。
よって、次に来る「ご」の子音であるgが入力可能になります。もう一回nを入力して「ん」をnnとして入力することもできます。
入力例2: 「しんや」に対してsinと入力した場合
「ん」に対して「n」が1回入力されていますが、次に来る文字が「や」なのでacceptableフラグはfalseです。
そのため、必ずもう一回nを入力して「ん」をnnとして入力する必要があります。
「っ」の特殊な入力方法に対応する
SmallTsuHandlerクラス
export class SmallTsuRuleHandler implements SpecialRuleHandler {
accept(acceptor: Acceptor, char: string): Result {
if (acceptor.step(char) == Result.Accept) {
return Result.Accept;
}
// 次に来る文字を判定する
const nextChara = acceptor.charas[acceptor.idx + 1];
if (nextChara === undefined || /[あ-おな-のんーa-z0-9!?,.[\]]/.test(nextChara.value)) {
return Result.Reject;
}
const historyLength = acceptor.searcher.history.length;
const consonants = nextChara.getConsonants();
// 「っ」を次の文字の子音で入力可能か判定する
if (historyLength <= 1 && consonants.find((c) => c == char)) {
acceptor.history += char;
acceptor.next();
if (historyLength == 1) {
acceptor.step(char);
}
const chara = acceptor.charas[acceptor.idx];
const consonants = chara.getConsonants();
if (consonants.length > 1) {
// 次の文字のノードを変更する
const idx = consonants.findIndex((consonant) => consonant == char);
const children = chara.node.children?.splice(idx, 1);
chara.node.children = children;
}
acceptor.updateCompletion();
return Result.Accept;
}
return Result.Reject;
}
...
}
現在入力している文字が「っ」の場合、SmallTsuRuleHandler.accept関数が呼び出されます。
まずAcceptor.step関数を呼び出しResult.Acceptが返ってきたら「っ」を単体で入力していると判定します。Result.Rejectが返ってきた場合は、特殊な入力方法が可能かを判定します。
「っ」の次に来る文字があ行、な行、ん以外の平仮名であるかを調べ、条件を満たすならその平仮名の子音を取得します。入力したキーがその子音のいずれかと一致するならば、「っ」の特殊な入力方法と判定して次の文字へ進めます。
この時、入力可能な子音が複数ある場合は次に来る文字のノードを書き換えて、入力した子音が表示されるようにします。詳細は下記の入力例3で説明します。
入力例1: 「きって」に対してkitと入力した場合
「て」の子音がtなので「っ」の特殊な入力方法と判定して「て」の入力を開始します。
入力例2: 「いっぬ」に対してinと入力した場合
「ぬ」がな行の平仮名なので特殊な入力方法ができません。よってnは入力ミスとなります。ltuやxtu等の単体入力をする必要があります。
入力例3: 「にっか」に対してnicと入力した場合
「か」の子音がkまたはcなので、「っ」の特殊な入力方法と判定して「か」の入力を開始します。しかし、画面上に表示されている予測文字列がnikkaなので、この文字列をniccaに変更する必要があります。
そこで「か」のノードの構成を書き換えてcのみ入力可能にします。これにより画面上にniccaと表示されるようになります。
また、子音が複数ある文字の場合はノード構成を書き換えることでnickaやnikcaといった途中で子音を変える入力方法を無効にします。

AcceptorFactoryクラス
Acceptorクラスはインスタンスを生成する処理が少し複雑なので、専用のファクトリークラスを作ります。
acceptor-factory.ts
export class AcceptorFactory {
patterns: Record<string, string[]>;
constructor(patterns: Record<string, string[]>) {
this.patterns = patterns;
}
/**
* 平仮名のテキストを基にAcceptorを生成する
* @param text 平仮名のテキスト
* @returns Acceptor
*/
create(text: string): Acceptor {
const splitText = this.split(text);
const charas: Chara[] = [];
splitText.forEach((char) => {
const node = createNode(this.patterns[char]);
charas.push(new Chara(char, node));
});
return new Acceptor(charas);
}
/**
* 平仮名のテキストを入力パターンごとに分割する
* @param text 平仮名のテキスト
* @returns 分割したテキスト
*/
split(text: string): string[] {
const ary = [];
let buf = '';
for (let i = 0; i < text.length - 1; i++) {
buf = buf + text.charAt(i);
if (!(buf + text.charAt(i + 1) in this.patterns)) {
ary.push(buf);
buf = '';
}
}
ary.push(buf + text.charAt(text.length - 1));
return ary;
}
}
コンストラクタには全ての入力パターンを列挙した連想配列を渡します。
create関数でAcceptorのインスタンスを生成します。引数に入力するテキストの文字列を渡します。
例えばにゅうりょくという文字列を渡すと、以下の手順でAcceptorのインスタンスを生成します。
-
split関数でテキストを入力する文字毎に分割['にゅ', 'う', 'りょ', 'く'] - 分割した文字毎に
Nodeのインスタンスを生成 - 1.の文字と2.の
NodeからCharaクラスの配列を生成 - 3.の配列を
Acceptorのコンストラクタに渡してインスタンスを生成
まとめ
文字によって複数の入力方法があったり、後ろの文字によって特殊な入力が可能だったりと様々な条件があるため適切な設計を考えるのに苦労しました。
今回の開発でローマ字入力の複雑さを改めて実感しました。
参考文献
👆余談ですが、個人的に一番面白いタイピングゲームです。