環境
Ubuntu 18.04.1 LTS(こちらでKerasまで一旦、環境構築)
Ubuntu 20.04.1 LTS(途中でアップデート。最終的にはこちらで下記バージョンが動作しています)
GeForce RTX 2070 SUPER
Nvidia ドライバ 455.38
CUDA Version 10.1.243
python 3.7
cuDNN 7.6.5
Keras 2.3.1
tensorflow 2.1.0 gpu_py37h7a4bb67_0
pytorch 1.6.0
(その後、仮想環境を追加してpytorch 1.4.0)
試していないこと
-最初からUbuntu 20.04.1 LTSでのインストール
-Anaconda上でのCUDAインストール
はじめに
ディープラーニングによる画像認識のため、GPU搭載のBTOパソコンにUbuntuを入れてKeras、Pytorchが動くまでの記録です。何度か、はまった末に、ようやく環境構築できたので備忘録を残します。
1. Ubuntuインストール
詳しく解説されているページがいくつもありましたので、そちらを参考にインストールしました。
Ubuntu 18.04 LTSインストールガイド【スクリーンショットつき解説】
私の場合、作業開始早々、画面が崩れて先に進めなくなりました。
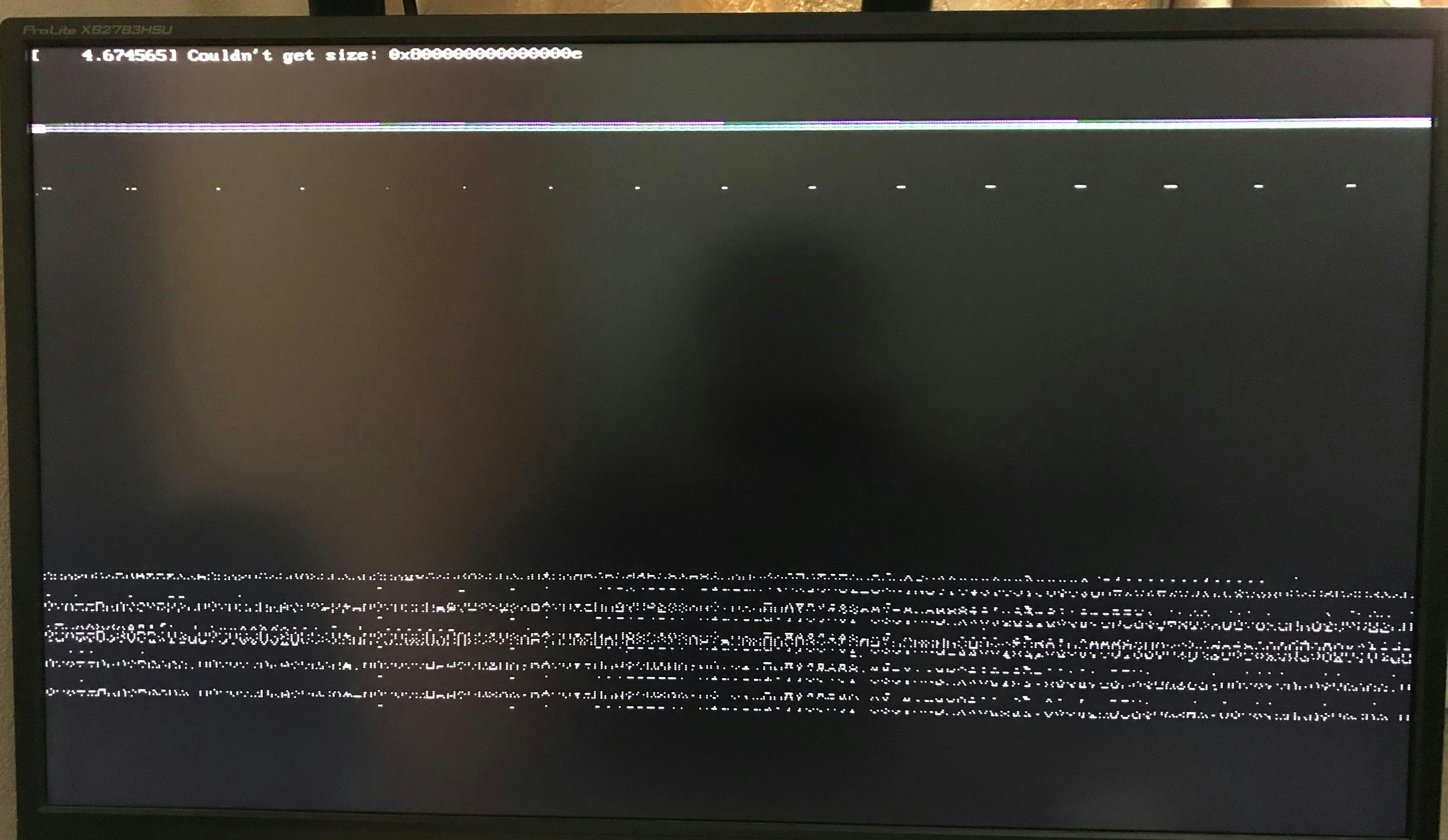
Ubuntuと機器の相性などの不安がよぎりましたが、下記記事を見つけ、ここで紹介されている方法で回避できました。
NVIDIA GeForce 入り PC で Ubuntu インストーラ(GUI版)の表示が壊れてた場合
Install Ubuntu メニュー > eボタンを押す > カーネルパラメータ設定で、linux 行の末尾に nomodeset を追記 > Ctl-x

Ubuntuインストールの途中、次の画面に進むためのボタン(続ける、など)が画面の外(下)に表示され、クリックできないことに何度も遭遇しました。ネットで探したインストール画面のキャプチャ画像を見ながら、TABで送って先に進めました。(最近、VartualBoxへのUbuntuインストールで再び遭遇したため追記しました。2021/10/9追記)
ここからはUbuntuのインストールが終わった直後での話です。
あくまで、私の環境で最終的にうまくいった方法です。
あえてNVIDIAドライバは入れずに、もう少し我慢します。
2. CUDAインストール
画面の解像度が低く作業しにくいですが、その状態でまずは、CUDA tool kit をインストールします。CUDA tool kitをインストールすると、そのCUDAにあうNVIDIAドライバがインストールされていました。
NVIDIAの CUDA Toolkit Archive からインストールするCUDA Toolkit のリンクに入ります。
今回は、CUDA Toolkit 10.1 update2 Archive を選択し、その先の画面で
Operating System、Architecture、Distribution、Version、Installer Type を順に選んでいきます。

Installer Typeではdebを選択しています。runfileはエラーが出て手こずったので、途中からdebしか選ばなくなりました。
上記を選ぶと下記のようなBase Installerが表示されるので、これをコンソールにコピペして1行づつ実行していきます。
$wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin
$sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600
$wget http://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda-repo-ubuntu1804-10-1-local-10.1.243-418.87.00_1.0-1_amd64.deb
$sudo dpkg -i cuda-repo-ubuntu1804-10-1-local-10.1.243-418.87.00_1.0-1_amd64.deb
$sudo apt-key add /var/cuda-repo-10-1-local-10.1.243-418.87.00/7fa2af80.pub
$sudo apt-get update
$sudo apt-get -y install cuda
CUDAはインストールしただけだとパスが通っていなくてコマンドが実行できません。
下記を参考に自分の入れたCUDAに合わせて.bashrcにパスを追加します。
TensorFlow1.10.1をUbuntu18.04 + CUDA9.2 + cuDNN 7.2.1上で動かす
$ echo 'export PATH=/usr/local/cuda-10.1/bin${PATH:+:${PATH}}' >> ~/.bashrc
$ echo 'export LD_LIBRARY_PATH=/usr/local/cuda-10.1/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}' >> ~/.bashrc
$ source ~/.bashrc
$ sudo ldconfig
状態を確認
$ nvcc -V
$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2019 NVIDIA Corporation
Built on Sun_Jul_28_19:07:16_PDT_2019
Cuda compilation tools, release 10.1, V10.1.243
$ nvidia-smi
nvidia-smi
Mon Nov 30 11:54:32 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 455.38 Driver Version: 455.38 CUDA Version: 11.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce RTX 207... Off | 00000000:09:00.0 On | N/A |
| 38% 28C P8 6W / 215W | 369MiB / 7973MiB | 1% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1150 G /usr/lib/xorg/Xorg 35MiB |
| 0 N/A N/A 1698 G /usr/lib/xorg/Xorg 200MiB |
| 0 N/A N/A 1826 G /usr/bin/gnome-shell 35MiB |
| 0 N/A N/A 2634 G ...AAAAAAAAA= --shared-files 71MiB |
| 0 N/A N/A 7219 G ...AAAAAAAAA= --shared-files 12MiB |
+-----------------------------------------------------------------------------+
nvidia-smiの右上にはCUDA Version: 11.1 と表示されますが、インストールされているCUDAのバージョンとは関係ないようです。
(最初の失敗例)
先にNVIDIAドライバを入れた場合、プリインストールされる望んでいないバージョンのCUDAのアンインストールがうまくいかずエラーが出ました。xwindow関連のいくつかのファイルが、アンインストール対象のファイルを掴んでいるようでした。アンインストールのためには、xwindowではなくCLIで起動して・・・と作業が大変そうだったので、結局Ubuntuを再インストールしました。
参考サイト
Ubuntu 16.04 をインストールして NVIDIAドライバ (410.48)と CUDA10.0 と cuDNN7.4.1 を入れて Tensorflow-gpu を動かすメモ
Kerasを使って画像分類を試してみる(2)―GPUドライバとライブラリの対応関係確認―
4. Anacondaインストール
下記サイトなどを参考にしました。
UbuntuにAnacondaをインストールしてPythonとJupyter Notebookを動かすまでの手順
[【備忘録】Ubuntu18.04のCUDA10&Python3&PyTorch環境構築]
(https://qiita.com/hey_gt/items/cabf4dce9d8e39a5b4d4)
最近のインストーラーだとデフォルトがPython3.7ではなかったと思います。当初あまりよく考えずに進めたこともあり、Pytorchのインストール時、ライブラリなどのバージョン違いでうまく動きませんでした。結局、Anaconda上でPython3.7の仮想環境を作り、CUDA以外は入れ直すはめになりました。
なお、Anaconda上でのインストールにおいてconda install と pipを混ぜると危険という記事がありましたので、以降のインストールは conda install で行っています。
デフォルトチャネルのconda searchで見つからない場合は、conda-forgeというチャネルを追加したりします。
5. tensorflowインストール
「ここ」で確認されているテスト済みのビルド構成、Linux、GPUからCUDA10.1に対応しているtensorflowのバージョンを調べます。
今回は、tensorflow 2.1.0、cuDNN 7.6 になります。

conda search でインストール可能なtensorflow の一覧を表示します。実際はもっと大量に表示されますが、下記は一部抜粋です。
(my_env)$ conda search tensorflow
Loading channels: done
# Name Version Build Channel
tensorflow 2.0.0 mkl_py36hef7ec59_0 pkgs/main
tensorflow 2.0.0 mkl_py37h66b46cc_0 pkgs/main
tensorflow 2.1.0 eigen_py27h636cc2a_0 pkgs/main
tensorflow 2.1.0 eigen_py36hbb90eaf_0 pkgs/main
tensorflow 2.1.0 eigen_py37h1a52d58_0 pkgs/main
tensorflow 2.1.0 gpu_py27h9cdf9a9_0 pkgs/main
tensorflow 2.1.0 gpu_py36h2e5cdaa_0 pkgs/main
tensorflow 2.1.0 gpu_py37h7a4bb67_0 pkgs/main
tensorflow 2.1.0 mkl_py27h9dbd782_0 pkgs/main
tensorflow 2.1.0 mkl_py36h23468d9_0 pkgs/main
tensorflow 2.1.0 mkl_py37h80a91df_0 pkgs/main
上記からtensorflow2.1.0でgpu かつpy37となっているものをインストールします。
conda install tensorflow=2.1.0=gpu_py37h7a4bb67_0
6. cuDNNインストール
Anaconda 上でconda install します。基本的にバージョン管理はAnacondaがインストール済のものにあわせうまくやってくれますが、おまかせが不安な場合はconda search で候補をリストアップし、Version、Buildを指定してインストールします。これは後述のKerasなどでも同様です。
(my_env)$ conda search cudnn
Loading channels: done
# Name Version Build Channel
cudnn 7.6.0 cuda10.0_0 pkgs/main
cudnn 7.6.0 cuda10.1_0 pkgs/main
cudnn 7.6.0 cuda9.0_0 pkgs/main
cudnn 7.6.0 cuda9.2_0 pkgs/main
cudnn 7.6.4 cuda10.0_0 pkgs/main
cudnn 7.6.4 cuda10.1_0 pkgs/main
cudnn 7.6.4 cuda9.0_0 pkgs/main
cudnn 7.6.4 cuda9.2_0 pkgs/main
cudnn 7.6.5 cuda10.0_0 pkgs/main
cudnn 7.6.5 cuda10.1_0 pkgs/main
cudnn 7.6.5 cuda10.2_0 pkgs/main
cudnn 7.6.5 cuda9.0_0 pkgs/main
cudnn 7.6.5 cuda9.2_0 pkgs/main
cudnn7.6.5のcuda10.1に対応したバージョンを入れます。
my_env)$ conda install cudnn=7.6.5=cuda10.1_0
7. Kerasインストール
conda install keras
バージョンはAnaconda任せです。
8. Pytorchインストール###
PytorchとKerasを同時に使うことはないのですが、たまたま他の方から頂いたサンプルコードがPytorchだったので、こちらの環境も整えました。
INSTALLING PREVIOUS VERSIONS OF PYTORCH から
conda、Linux and Windows、今回であれば #CUDA 10.1 の所にあるコマンドを実行します。
conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.1 -c pytorch
cudatoolkit=10.1 はインストール済みなので実際は
conda install pytorch==1.6.0 torchvision==0.7.0 -c pytorch
としました。
9.動作確認###
keras
jupyter notebook上で下記を実行
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)

GPU使用状況
watch -d -n 1 nvidia-smi
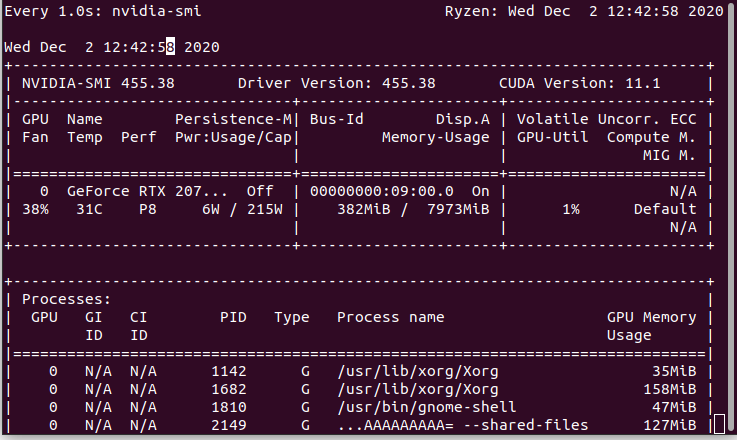
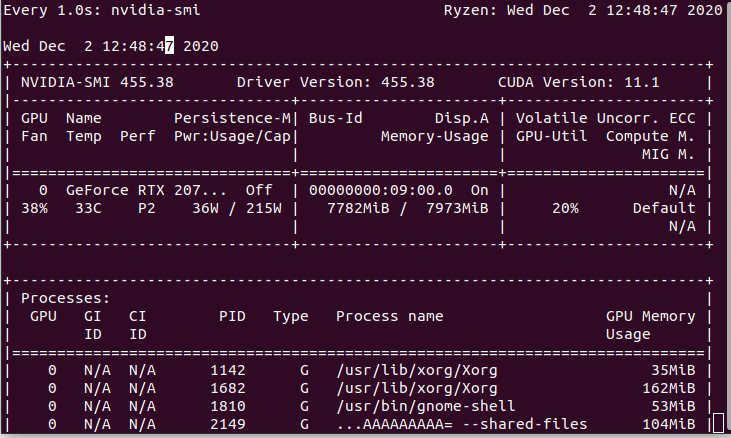
真ん中の数字が382から7782MiBに上昇
Pytorch
シンプルに確認
その後1
~~物体検出のコンペのようなもの(?)~~経産省主催のAI Questに参加していて、選んだテーマが物体検出でした。物体検出の事前知識が皆無のため、事前にベースラインを作っておきたいと思い「PyTorchによる発展ディープラーニング」 にある物体検出(SSD)のコードを試してみました。モデル学習後、検出時にエラーが出て、GitHubのIssue情報から解決策を探した結果、Pytorchを1.5以前に下げることにしました。
(AI Questの中では、結局、事務局から提供されたyolo3サンプルコードをベースに、前処理中心で提出したためSSDは使いませんでした。)
バージョンダウンは別の仮想環境で作りたかったのでこちらを参考に仮想環境をコピーします。ここでmy_env はこれまでに構築済みの仮想環境名(pytorch1.6.0バージョン)、PyT14 は複製して作成する新しい仮想環境名です。
(base)$ conda create -n PyT14 --clone my_env
前述した「ここ」からCUDA10.1 に対応したpytorchで1.5以前のものを探すと、v1.4.0一択でした。pytorch1.6.0を削除して、pytorch1.4.0を入れます。
(base)$ conda activate PyT14
(PyT14)$ conda uninstall pytorch
(PyT14)$ conda install pytorch==1.4.0 torchvision==0.5.0 -c pytorch
CUDAはインストール済なので、conda installから cudatoolkit=10.1 の部分は削ってあります。
その後2
tensorflow2.3、keras2.2 の環境を再現する必要があり、別の仮想環境を作りました。conda installにtensorflow2.3がなく、Dockerなども試しましたが挫折し、既存の仮想環境をコピーし、pip install で tensorflow2.3を入れました。
これまで conda install と pip install の混在を避けてきましたが、やむを得ず混在させてしまいました。listを出しただけだと conda と pip のどちらでインストールしたものか区別がつかなくなりました。
(手順)
1.新たな仮想環境を既存仮想環境をコピーして作成。以下は全て新たな仮想環境上での操作です。
2.一旦、仮想環境をきれいにしました。
conda install した tensorflow、tensorboard、keras とつくものを全て削除
conda list でpip install したものは Channel が pypi になっていますので、それ以外の該当するもの(conda uninstall ・・・)
3.pip install した tensorflow、tensorboard、keras とつくものを全て削除(pip uninstall ・・・)
4.pipで tensorflow2.3 をインストール
5.pipで keras2.2.4 をインストール
keras2.2.4は、conda install にもありますが、conda installだと余計なもの(cpu版のtensorflowなど)が一緒に入ってうまくいきませんでした。tensorflow、tensorboard、kerasを全て消さなくてもうまくいくかもしれませんが、学習時に別のエラーがでてはまったので、一旦、きれいにした方がいいようです。
---- 不用意なインストールの結果、仮想環境が壊れてしまい、作り直すことになったため、改めて詳細手順を追加しました。今後は仮想環境のバックアップも、しっかり残すようにしたいと思います。
# PL11は新しい仮想環境名
(base)$ conda create -n PL11 --clone my_env PyT14
(base)$ conda activate PL11
(PL11)$ conda uninstall tensorflow
# これ以外にもtensorflow、ensorboard、kerasで始まるものを全てuninstallします。
(PL11)$ pip uninstall tensorflow
# これ以外にもtensorflow、ensorboard、kerasで始まるものを全てuninstallします。
(PL11)$ pip install tensorflow-gpu==2.3.0
(PL11)$ pip install Keras==2.2.4