はじめに
はじめまして、(株)日立製作所 Lumada Data Science Lab. の顧です。日立では「小集団活動」という、有志が集まって好きなテーマに取り組む活動があります。今回、私が所属するデータサイエンティストのチームで、**「お刺身認識アプリを作ってみよう!」**という活動をしました。この取り組みを通して学びや気づき、実際のモデルのコード例などを紹介します。
さて、どちらがカンパチでしょう?

正解は・・・

正直、カンパチとブリの違いが分からない…。そんなときに「お刺身認識アプリ」が役立ちます!
活動のきっかけ
私の業務はデータ分析がメインなのですが、システム構築のスキルを身につければ、プロト開発に活かして、お客様に試してもらうことができ、成果の体感・共有が可能になります。そこで、ゼロからシステム構築まで通して取り組む機会を作り、メンバー間でノウハウを共有しようという目的で始めました。
どうやって開発したか
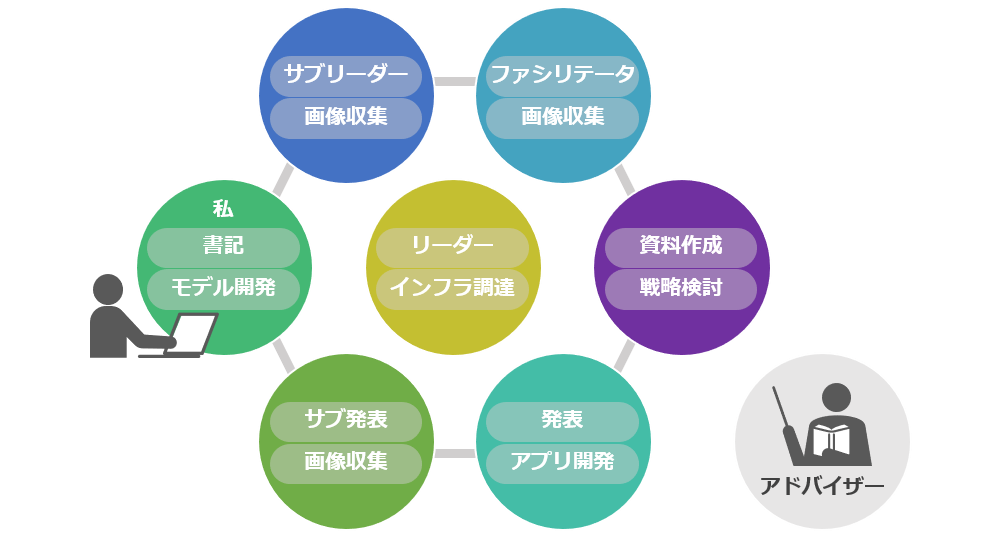
メンバー構成
このようなかんじで役割を分担しました。私はモデル開発をメインに担当しました。
進め方
テーマ決め→データ収集→モデル構築→アプリ開発という流れで進めました。
テーマ決め
AIのすごさを検証するのではなく、お客様に実際に使ってもらえるサービスやシステムを目ざしました。メンバーそれぞれがアイデアを持ち寄り、仮説やニーズなどを議論した結果、最終的に「お刺身認識アプリ」が選ばれました。
-
仮説立案
お刺身の種類を区別することは難しい。特に訪日外国人の方は、回転ずしで何の魚かよく分からずに食べていることが多そうだ。そういった訪日外国人にお刺身の違いを知ってもらい、日本の文化の理解を深めてもらったり、世界中で宣伝してもらったりできれば、飲食業・観光業に貢献できるのではないか。
-
ニーズ調査
- TOKYOオリンピックでインバウンド需要が見込まれる。
- 訪日外国人が日本に最も期待することは「日本食」であるという調査結果あり。
- 一方「日本食」を提供する飲食店側は、背景にある日本文化や食材の魅力を十分に説明できていないという課題を感じている。
※検討したのは、新型コロナ流行前でした…
-
事業モデル化イメージ
回転ずしなどの飲食店のアプリと連携し、お刺身の種類を正しく答えられるか、AIと勝負するアプリを提供する。お客様の正解率がAI判定結果よりも高い場合は、お店で使えるポイントを付与する。お客様に楽しんでもらいながら、日本文化の理解と消費につなげる。
データ収集
方法①:画像検索
インターネットから画像を集めました。これが大変…。

方法②:実物撮影
スーパーなどで実物を買い求め、画像を撮りました。撮影する方向・光の当て方・お皿の色などを変えて動画を撮影し、コストをかけずにたくさんの画像を集める工夫をしました。ただ、お刺身を食べ過ぎておなかを壊すことも…。
苦労しながらも最終的に、40,000枚を超える刺身写真を集めました。
モデル構築
モデルの学習フロー
データ収集→前処理→データ分割→モデル構築→(再)学習のサイクルを回し、学習し続けるAIを構築しました。
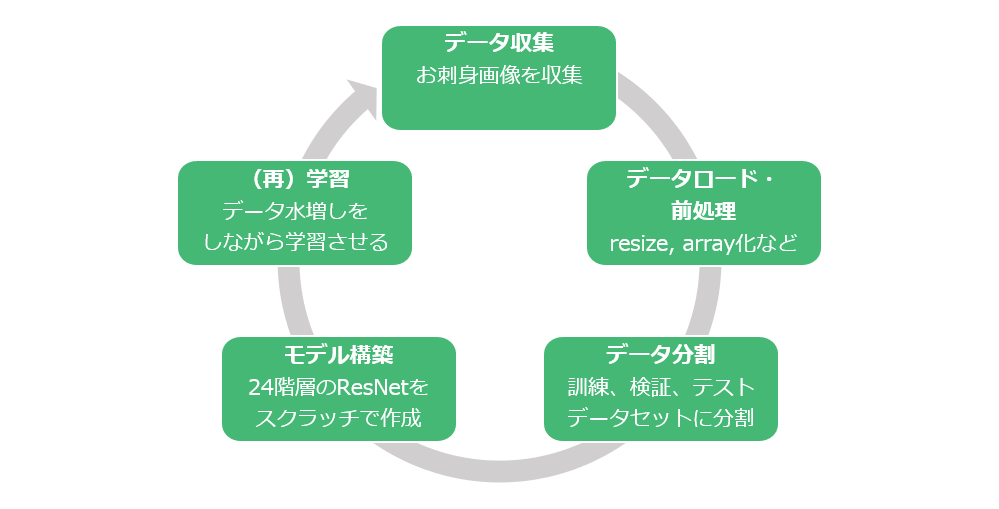
モデル(SushiNetと命名)はカスタマイズの24階層のResidual Network(ResNet)をスクラッチで作成しています。(再)学習では、収集したデータセットは不均衡であるため、クラスごとの重みを設定することで、過小評価されたクラスに注意を向けるようにしています。
実行例(データ拡張)
ここでは、(再)学習でのデータ拡張の実行例をご紹介します。
rows=cols=3
datagen = ImageDataGenerator(rotation_range=90)
show_aug_images(x)
このように、画像をランダムに回転させます。

フルバージョンのモデル実⾏例は、この記事の最後に記載しています。ご興味ある⽅はぜひお試しください︕
アプリ開発
システム構成とリポジトリー
システムの各コンポーネントとリポジトリーの対応関係を示します。
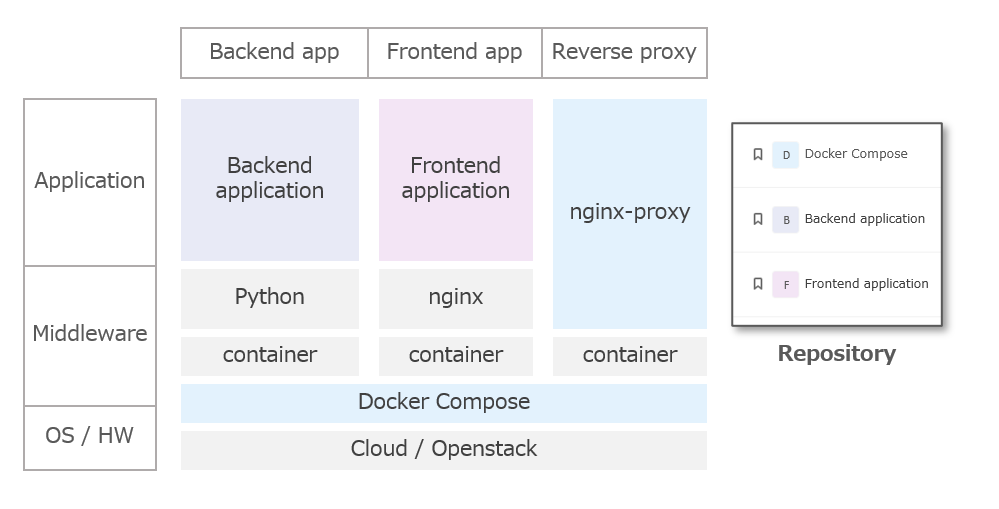
処理方式①
スマホのブラウザーでお刺身認識アプリのURLを開く(=ランディング)と、フロントエンドアプリ(=HTML+JavaScript+CSS)がダウンロードされ、ブラウザー上でアプリが起動します。
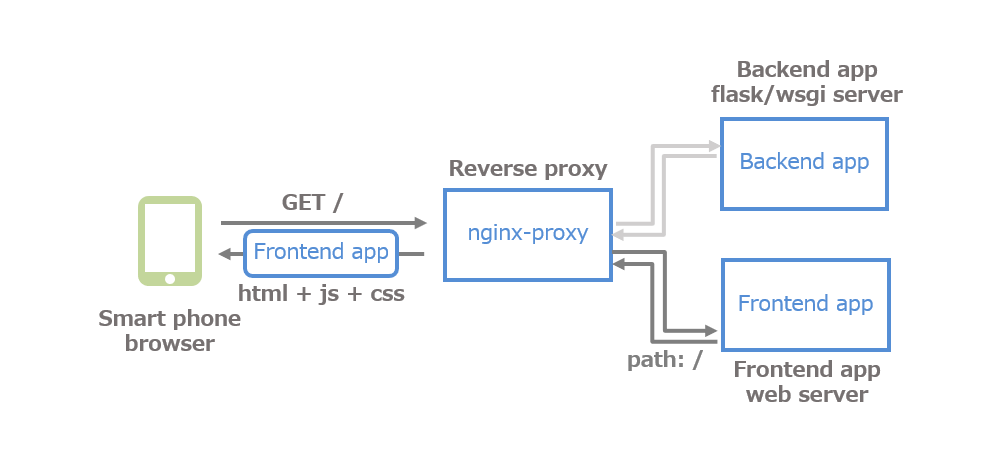
処理方式②
お刺身認識アプリを起動し、カメラで刺身を撮影してアップロードすると、フロントエンドアプリがブラウザー経由で端末のカメラデバイスを制御、画像を取得してサーバーへ送信します。
サーバーが画像を受け取り、バックエンドアプリが刺身を認識・判定し、判定した結果をブラウザー経由でフロントエンドアプリへ送信します。フロントエンドアプリが受け取った判定結果をスマホのブラウザーに表示します。
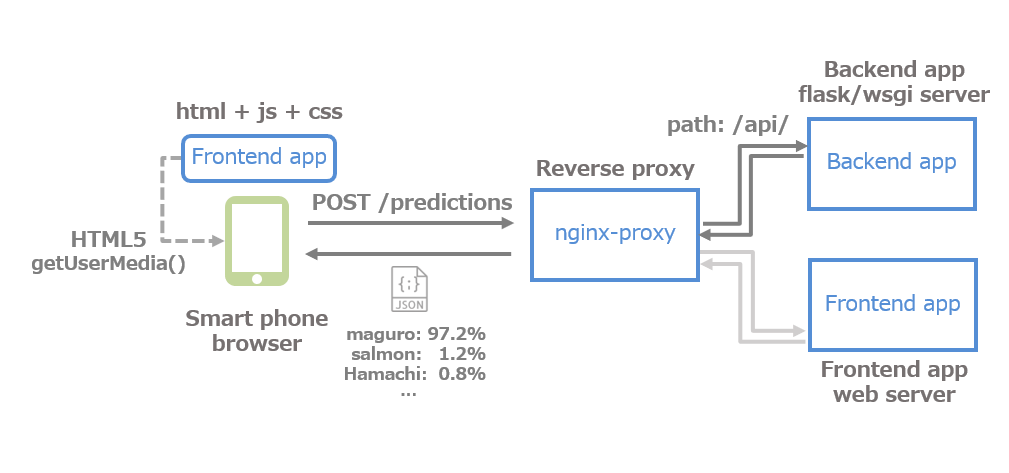
苦労ポイント
-
HTML5仕様は変化が早い
スマホのブラウザーからカメラデバイスへアクセスするために、HTML5のgetUserMedia() APIを利用しました。このAPIは「Candidate Recomendation」というステータスであり、まだ正式な仕様ではないため、仕様が変更されるおそれがあります。実際、セキュリティが強化によってHTTPスキームの通信では使用不可となり、HTTPsにする必要がある、ということが開発を進める中で判明してちょっと焦りました。
-
TensorFlow(1系)はスレッドセーフではない
これはWebアプリケーションの中からTensorflowを使う場合に、非常に重要なポイントです。あるHTTPリクエストAを処理するスレッドAの中でTensorflowが作成した計算グラフは、別のHTTPリクエストBを処理するスレッドBの中で作成した計算グラフと干渉し合ってしまいます。これを回避するためには、計算グラフをシングルトンにする必要があります。
※Tensorflow2系では(それなりに)解消されており、つまづきづらいようなAPI設計がなされています。たぶん。
-
各コンポーネントで画像処理をどう分担するか
カメラ撮影した画像をモデルへ入力するまでに、幾つかの画像処理を施す必要があります。これをフロントエンドアプリ(=ブラウザー上のJavaScript)とバックエンドアプリ(=Python)でどう分担するか、綿密に設計する必要があります。この設計が甘いと、結合テスト以降にバグが頻発して手戻りが…。実際に、圧縮解凍処理の設計誤りによって、JavaScript側はRGBA形式で送信しているのに対して、Python側はRGB形式を期待しているため、異常が発生してしまいました。
まとめ
人間 vs AI 結果は…?
出来上がったアプリの様子はこちら。

はたして、AIは人間にどのくらい近づけたのでしょうか⁉
| お刺身の種類 | 人間の正解率 | AIの正解率 | 勝敗 |
|---|---|---|---|
| マグロ | 95% | 75% | 人間の勝ち |
| ハマチ | 44% | 78% | AIの勝ち |
| サンマ | 50% | 100% | AIの勝ち |
| カンパチ | 40% | 40% | どっちも苦手? |
なかなかよい結果が出たのではないかと思います。(そもそも人間の正解率もあまり高くないけど…)
が、まだまだ現物と収集したデータとのギャップが大きく、改善の余地があります。動物の外見ような分かりやすい特徴も少ないし、鮮度でも見た目が変わってしまうことも判定を難しくする要因です。インターネットから得たデータをどうクリーニングするか、が今後の課題です。
活動の成果
- システム開発の全体像をカバーするという目標はおおむね達成
- メンバー間でお互いの知識共有・向上につながった
- アプリ開発部分(クラウド連携など)も学びがあった
- データ収集はとにかく大変……お客様やSEの苦労が少し分かった
最後のお客様やSEの苦労が分かった、というのが実はいちばん大切かもしれません。来年のオリンピックまでに、このアプリが実用化できたらうれしいですね。
参考:モデルの実行例(フルバージョン)
ライブラリーインポート
from tensorflow.keras.layers import Dropout, BatchNormalization, Flatten, Activation, Input, Dense,Add,Reshape
from tensorflow.keras.layers import ZeroPadding2D,Conv2D,ELU,MaxPooling2D,AveragePooling2D,GlobalAveragePooling2D
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import Model
from tensorflow.keras.callbacks import ModelCheckpoint, EarlyStopping, Callback, ReduceLROnPlateau, LearningRateScheduler,CSVLogger
from tensorflow.keras.losses import binary_crossentropy, categorical_crossentropy, mean_squared_error
from tensorflow.keras.optimizers import Adam, RMSprop, SGD
from tensorflow.keras.utils import Sequence, to_categorical
from tensorflow.keras import losses, models, optimizers
from tensorflow.keras import backend as K
import tensorflow as tf
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import warnings
import os
from datetime import datetime
warnings.simplefilter('ignore')
warnings.filterwarnings('ignore')
%matplotlib inline
データ拡張
データ拡張の準備
# データロード
img_path="xxx.jpg"
im = Image.open(img_path)
im = im.resize((224,224),Image.BILINEAR)
x = np.expand_dims(im,axis=0)
# データ拡張の可視化関数
def show_aug_images(x):
g = datagen.flow(x,
batch_size=1)
plt.figure(figsize=(8,8))
for i in range(rows*cols):
aug_img=g.next()
plt.subplot(rows,cols,i+1)
plt.axis('off')
plt.imshow(aug_img[0].astype('uint8'))
データ拡張①:画像をランダムに回転させる
rows=cols=3
datagen = ImageDataGenerator(rotation_range=90)
show_aug_images(x)

データ拡張②:画像のチャンネルをランダムにシフトさせる
rows=cols=3
datagen = ImageDataGenerator(brightness_range=[0.1,3])
show_aug_images(x)

データ拡張③:画像を垂直方向に入力をランダムに反転させる
rows=cols=3
datagen = ImageDataGenerator(width_shift_range=0.4,fill_mode='reflect')
show_aug_images(x)

データ拡張④:画像をランダムにズームさせる
rows=cols=3
datagen = ImageDataGenerator(zoom_range=0.4)
show_aug_images(x)

モデル構築(SushiNet)
residual構造を活用して、複数のresidual bolockを積み重ね、ELU(Exponential Linear Unit)を使う24階層のResNetモデルを構築しました。
def cbe_block(X,F,kernel_size,strides,padding):
X = Conv2D(filters=F,kernel_size=kernel_size,strides=strides,padding=padding)(X)
X = BatchNormalization()(X)
X = ELU()(X)
return X
def cb_block(X,F,kernel_size,strides,padding):
X = Conv2D(filters=F,kernel_size=kernel_size,strides=strides,padding=padding)(X)
X = BatchNormalization()(X)
return X
def residual_id(X, f, filters):
F1, F2, F3 = filters
X_s = X
X = cbe_block(X=X,F=F1,kernel_size=(1,1),strides=(1,1),padding='valid')
X = cbe_block(X=X,F=F2,kernel_size=(f,f),strides=(1,1),padding='same')
X = cb_block(X=X,F=F3,kernel_size=(1,1),strides=(1,1),padding='valid')
X = Add()([X, X_s])
X = ELU()(X)
return X
def residual_conv(X, f, filters, s=2):
F1, F2, F3 = filters
X_s = X
X = cbe_block(X=X,F=F1,kernel_size=(1,1),strides=(s,s),padding='valid')
X = cbe_block(X=X,F=F2,kernel_size=(f,f),strides=(1,1),padding='same')
X = cb_block(X=X,F=F3,kernel_size=(1,1),strides=(1,1),padding='valid')
X_s = Conv2D(filters=F3, kernel_size=(1,1), strides=(s,s), padding='valid')(X_s)
X_s = BatchNormalization()(X_s)
X = Add()([X, X_s])
X = ELU()(X)
return X
def SushiNet(input_shape = (224, 224, 3), classes = 10):
X_input = Input(input_shape)
X = ZeroPadding2D((3, 3))(X_input)
X = Conv2D(64, (7, 7), strides = (2, 2))(X)
X = BatchNormalization()(X)
X = ELU()(X)
X = MaxPooling2D((3, 3), strides=(2, 2))(X)
X = residual_conv(X, f = 5, filters = [64, 64, 256],s = 1)
for i in range(2):
X = residual_id(X, 3, [64, 64, 256])
X = Dropout(0.3)(X)
X = residual_conv(X, f = 5, filters= [128, 128, 512], s = 2)
for i in range(3):
X = residual_id(X, 3, [128, 128, 512])
X = Dropout(0.3)(X)
X = GlobalAveragePooling2D()(X)
X = Dropout(0.3)(X)
X = Dense(64)(X)
X = Dense(classes, activation='softmax')(X)
model = Model(inputs = X_input, outputs = X)
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
return model
model = SushiNet(input_shape = (224, 224, 3), classes = 10)
トレーニング
**Tips:**class_weight: 不均衡なクラスを訓練するときは、事前にクラスごとの重みを設定することで、損失関数をスケーリングできます。
datagen = image.ImageDataGenerator(
width_shift_range = 0.1,
height_shift_range=0.1,
rotation_range=10,
channel_shift_range=150,
zoom_range=0.5,
horizontal_flip=True,
vertical_flip=True,
fill_mode='reflect',
brightness_range=[0.5,3.5])
datagen.fit(X_train)
model.fit_generator(datagen.flow(X_train, y_train,
batch_size=batch_size),
epochs=epochs,
validation_data=(X_valid, y_valid),
steps_per_epoch = X_train.shape[0]/batch_size,
shuffle = True,
class_weight = class_weight)