【初心者向け】ローカルLLM環境「OpenMythos」の構築手順と実践ガイド(便利機能追加まで)
ローカルで動作するAIコード生成ツール環境「OpenMythos」の構築から、実際の実行手順、そしてより便利に使うための「ファイル自動保存機能」の実装までをまとめました。
OllamaなどのローカルLLMを活用して、機密コードを外部に送信することなく、安全かつ無料でコード生成を行いたい方におすすめです!
🌟 今回作成した環境のアーキテクチャ
まずは全体のシステム構成図です。
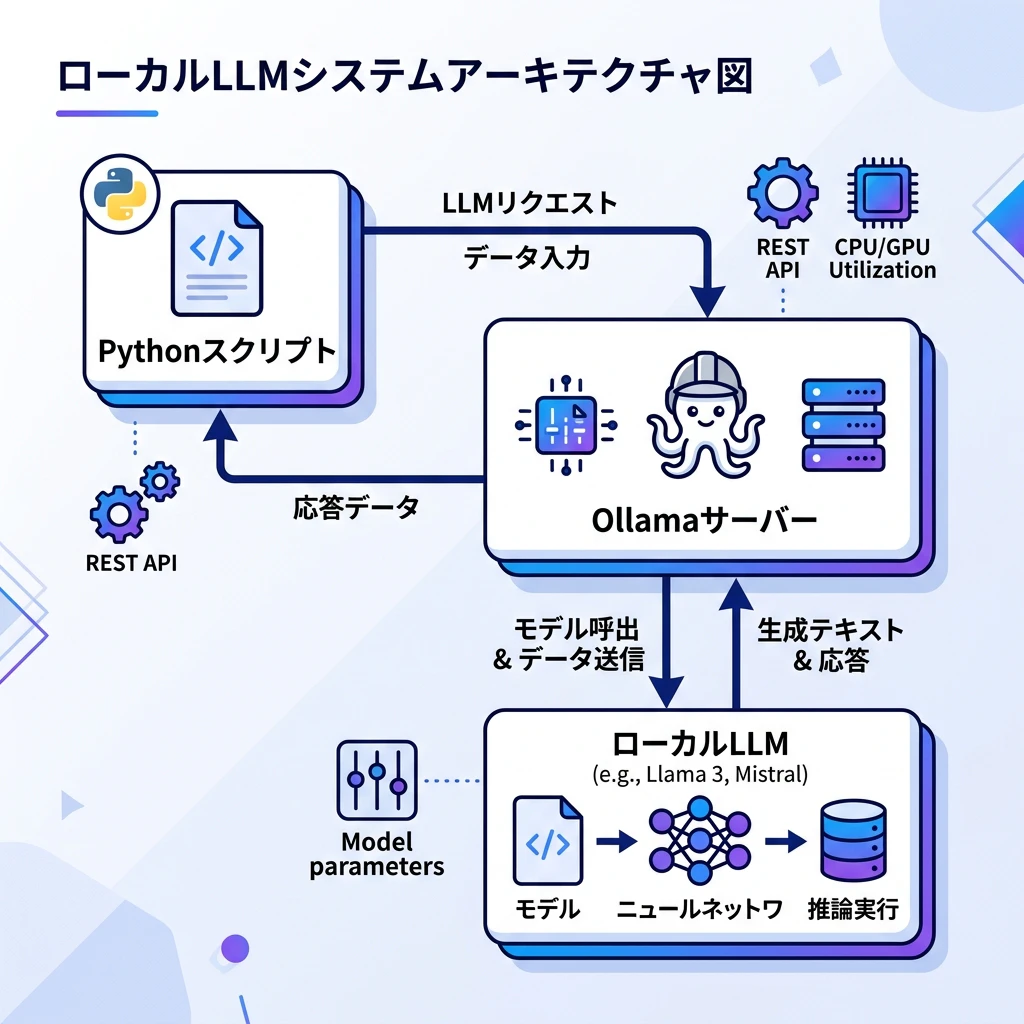
Pythonスクリプトからローカルで稼働するOllama ServerへAPI通信を行い、Ollamaが管理しているLocal LLM(MistralやQwenなど)に推論を実行させます。これにより、完全ローカルで高速なコード生成が可能です。
💡 Ollamaを導入する前と後の決定的な違い

ローカルでLLMを動かす際、以前はHuggingFaceの transformers などを使い、実行するたびにPythonスクリプトで数GBのモデルファイルをメモリ(VRAM)にロードしていました。
この「Ollama導入前」の手法には以下のデメリットがありました。
- 起動が非常に遅い: 実行のたびにモデルロードで数十秒〜数分待たされる。
- 依存関係が複雑: PyTorchやCUDAのバージョン合わせに苦労する。
しかし、今回のように Ollamaをバックエンドサーバーとして常駐(導入後) させる構成にすることで、以下のように劇的に改善しました。
- 起動時間ゼロ: モデルはOllamaサーバー上で常にスタンバイしているため、Pythonスクリプトを実行した瞬間に推論が開始されます。
- 超高速な処理時間: API経由でテキストストリーミングを受け取るだけになり、軽量なQwenモデルならわずか1〜2秒、Mistral(7B)でも5〜10秒程度でコード生成が完了します。
- シンプルなコード: Python側はAPIクライアントとして振る舞うだけなので、コードが非常にシンプルで軽量になります。
🛠️ 1. 環境構築手順
まずはPythonの仮想環境と必要なパッケージのインストールを行います。
前提条件
- Python 3.12 以上
- Ollama がインストールされ、起動していること
仮想環境のセットアップ
# プロジェクトディレクトリの作成と移動
mkdir testMythos
cd testMythos
# 仮想環境の作成と有効化
python -m venv venv
# Windowsの場合
.\venv\Scripts\activate
# Mac/Linuxの場合
source venv/bin/activate
パッケージのインストール
必要なライブラリ(open-mythos, openai など)をインストールします。
pip install --upgrade pip
pip install open-mythos openai
Ollamaモデルの準備
Ollama上で動作するLLMモデルをダウンロードしておきます。今回はコード生成能力の高い Mistral と、超軽量・高速な Qwen のモデルを使用します。
ollama pull mistral
ollama pull qwen2:1.5b
🚀 2. スクリプトの実行と便利機能の追加
用意した対話型のコード生成スクリプトを実行し、実際にAIにコードを書かせてみます。
スクリプトの実行と処理時間の実例
python mistral_code_gen.py
実行すると、以下のようなメニューが表示されます。実際に「Pythonで素数を判定する関数」を生成させたときのログです。
======================================================================
Mistral-7B - コード生成ツール
======================================================================
オプション:
1. コード生成
2. コード説明
...
選択してください (1-6): 1
生成したい内容を日本語で入力してください: Pythonで素数を判定する関数
言語を選んでください (python/javascript/cpp/qt/other): python
生成中...
生成結果 (2.45s):
----------------------------------------------------------------------
def is_prime(n):
if n <= 1:
return False
if n <= 3:
return True
if n % 2 == 0 or n % 3 == 0:
return False
i = 5
while i * i <= n:
if n % i == 0 or n % (i + 2) == 0:
return False
i += 6
return True
----------------------------------------------------------------------
Ollamaがスタンバイしているおかげで、モデルのロード時間なしにたった 2.45秒 で高品質なコードが生成されました。
【便利カスタマイズ】スマートファイル保存機能の実装
デフォルトのスクリプトでは、上のログのように生成されたコードが「コンソールにべた書き」で表示されるだけでした。そのため、出力されたコードを使いたい場合はターミナルから手動でドラッグ&コピーし、エディタに貼り付ける必要がありました。
そこで今回はデフォルトの動作から大きく変更を加え、対話的にファイル出力先を指定し、存在しないディレクトリを含めて自動生成して保存する機能を追加しました。
変更点1: save_to_file ヘルパー関数の追加
import os
def save_to_file(content, default_filename="output.txt"):
"""生成結果をファイルに保存するヘルパー関数(ディレクトリの自動作成付き)"""
output_dir = "output"
# デフォルトディレクトリの作成
if not os.path.exists(output_dir):
os.makedirs(output_dir)
filepath = input(f"保存先のファイルパス(デフォルト: {output_dir}/{default_filename})を入力: ").strip()
# 未入力の場合はデフォルトの保存先
if not filepath:
filepath = os.path.join(output_dir, default_filename)
# ファイル名のみの場合はデフォルトフォルダへ
elif not os.path.isabs(filepath) and "/" not in filepath and "\\" not in filepath:
filepath = os.path.join(output_dir, filepath)
# 保存先フォルダの自動作成
parent_dir = os.path.dirname(filepath)
if parent_dir and not os.path.exists(parent_dir):
os.makedirs(parent_dir)
# ファイル書き込み
with open(filepath, "w", encoding="utf-8") as f:
f.write(content)
print(f"✓ {filepath} に保存しました!")
変更点2: インタラクティブモード呼び出し側の改修
単純に print(code) していた処理の直後に、保存の意思確認と保存処理を組み込みました。
# 変更前の処理
print(code)
# 変更後の処理(追記)
save_choice = input("この生成されたコードをファイルに保存しますか? (y/N): ").strip().lower()
if save_choice == 'y':
ext = "py"
if language.lower() == "javascript": ext = "js"
elif language.lower() in ["cpp", "qt", "c++"]: ext = "cpp"
save_to_file(code, f"generated_code.{ext}")
この改修により、対話プロンプトで Enter キーを押すだけで、自動的に output ディレクトリが作成され、綺麗にファイル出力されるようになりました。さらに、存在しない階層(例: my_project/src/main.py)を指定しても、自動的にフォルダを作って保存してくれます。
⚠️ 3. 課題や懸念点
ローカルLLM環境を運用する上で、いくつか気をつけるべき課題があります。
リソースの消費(メモリとVRAM)
今回使用した qwen2:1.5b のような軽量モデルは1GB未満のメモリで動作しますが、mistral (7B) クラスのモデルになると約4GBのメモリ(VRAM)を消費します。ローカルマシンのスペックによっては、他の重い作業(IDEの起動やブラウザのタブ多数開き)との並行処理が少し厳しくなる可能性があります。
推論速度と精度のトレードオフ
軽量モデルは非常に高速(毎秒数十トークン)にレスポンスを返しますが、複雑なロジックの実装や、日本語の細かいニュアンスの解釈には苦戦する場合があります。
用途に合わせて「簡単な補完にはQwen」「しっかりした設計や説明生成にはMistral」といったモデルの使い分けを行う工夫が必要です。
日本語プロンプトの理解力
Ollamaの標準モデルに対して日本語でプロンプトを入力する場合、英語で入力した時と比べて精度が若干落ちることがあります。もし日本語での精度を高めたい場合は、Llama-3などをベースにした**日本語特化のオープンモデル(ELYZAなど)**を追加で ollama pull して組み込むと、さらに体験が向上します。
🎉 おわりに
「OpenMythos」と「Ollama」を組み合わせることで、お金をかけずにセキュアなコード生成環境を手軽に構築できました!
さらに、出力結果を自動保存するようなちょっとした工夫を加えるだけで、日々の開発の大きな助けになるパーソナルなAIツールへと進化します。
皆さんもぜひ、ローカルLLM環境を構築して自分だけのAIアシスタントを育ててみてください!