ODCで、日本語の半角・全角文字の置換をどうやろうか、と考えて、やはり.NETライブラリをNuGetで探すのが一番簡単だと考えた。
Kana.NETがライセンスもMITで使いやすそうだったので、これをExternal Logicとして取り込んでみる。
環境情報
OutSystemsExternalLibraries.SDK.1.5.0
ODC Personal Edition
作成したソースコード
そのうち、Forgeにもあげるかもしれないけど今はGitHubで。
https://github.com/jyunji-watanabe/JapaneseCharacters
Kana.NETについて
内容については、ここで改めて書くよりも、githubのプロジェクトページからリンクされていたKana.NET での ひらがな・カタカナ変換をみてもらうのが良さそう。
ライセンスはMIT。
以下の特徴から、Linux OSで動くExternal Logicでも使え、UTF-8をエンコーディングとして使うODCとも相性が良さそうだ。
非日本語環境のWindowsでも使用できます。
Linux や Mac でも使用できます。
Unicode に対応しています。
文字の変換にあたって、日本語環境のプログラマーが想定しそうな作りになっているとのことなので、デフォルト設定で変換する方法を見ることにする。今後必要が出たら、カスタムマッピング(デフォルトとは違う変換方法の定義)について確認する。
対象Framework Versionの記載はnet6.0止まりだが、通常は互換性が期待できると思うのでnet8.0の現在のExternal Logicでもそのまま使ってみることにする。
プロジェクト用意
以前に書いた以下の記事を参考に.NET 8のプロジェクトを用意する。
OutSystems.ExternalLibraries.SDKへの参照追加を忘れずに。
Kana.NET参照追加
NuGet経由で参照追加する。
dotnet add package Kana.NET --version 1.0.6
ソースコード
いろいろ解説を書こうと思ったが、ライブラリにおまかせで変換する場合、非常にシンプルなので完成品だけ載せておく。以下のコードをそのまま使う場合、アイコン画像を指定しているため、Resourcesフォルダに画像ファイルを配置することと、.csprojファイルでの埋め込み指定を忘れずに。あるいは、IconResourceName部分を消しても良い。
using OutSystems.ExternalLibraries.SDK;
namespace JapaneseCharacters;
[OSInterface(
Name = "JapaneseCharacters",
Description = "Japanese character conversion utilities",
IconResourceName = "JapaneseCharacters.Resources.JapaneseCharacters.icon.png")]
public interface IJapaneseCharacters
{
[OSAction(
Description = "Converts half-width (Hankaku) characters to full-width (Zenkaku) characters",
ReturnName = "ResultText",
ReturnDescription = "A Text with its original half-width characters converted into full-width characters",
ReturnType = OSDataType.Text)]
string HankakuToZenkaku(
[OSParameter(
Description = "A Text to convert",
DataType = OSDataType.Text)]
string SourceText);
[OSAction(
Description = "Converts full-width (Zenkaku) characters to half-width (Hankaku) characters",
ReturnName = "ResultText",
ReturnDescription = "A Text with its original full-width characters converted into half-width characters",
ReturnType = OSDataType.Text)]
string ZenkakuToHankaku(
[OSParameter(
Description = "A Text to convert",
DataType = OSDataType.Text)]
string SourceText);
}
using Umayadia.Kana;
namespace JapaneseCharacters;
public class JapaneseCharacters : IJapaneseCharacters
{
public string HankakuToZenkaku(string SourceText)
{
if (string.IsNullOrEmpty(SourceText))
return SourceText;
return KanaConverter.ToWide(SourceText);
}
public string ZenkakuToHankaku(string SourceText)
{
if (string.IsNullOrEmpty(SourceText))
return SourceText;
return KanaConverter.ToNarrow(SourceText);
}
}
出来上がったインターフェース(Hiragana、KatakanaのActionはKana.NETに含まれている機能をせっかくなので組み込んだもの)。
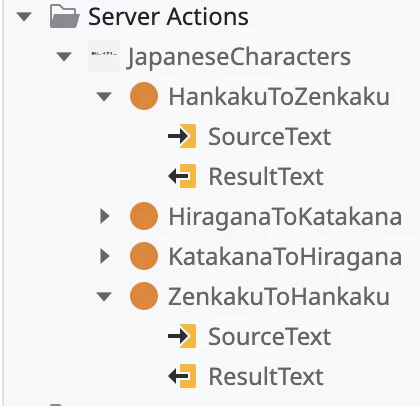
ODCへの取り込み
これも以前別記事で書いているので以下を参照。
Geminiにテスト用入力文字列を作ってもらう
この後BDD Frameworkでテスト用画面を作っていくので、入力、テスト結果として使う文字列をGeminiに作ってもらった。
日本語の全ての半角文字を列挙した文字列(二重引用符で囲む)を作ってください
日本語の処理において「全ての半角文字」とされる文字(半角スペース、半角英数字、半角記号、半角カタカナ)を全て列挙し、二重引用符で囲んだ文字列を以下に示します。
この文字列は、**ASCIIの印字可能文字(スペース含む)**と、JIS X 0201で定義される半角カタカナを結合したものです。
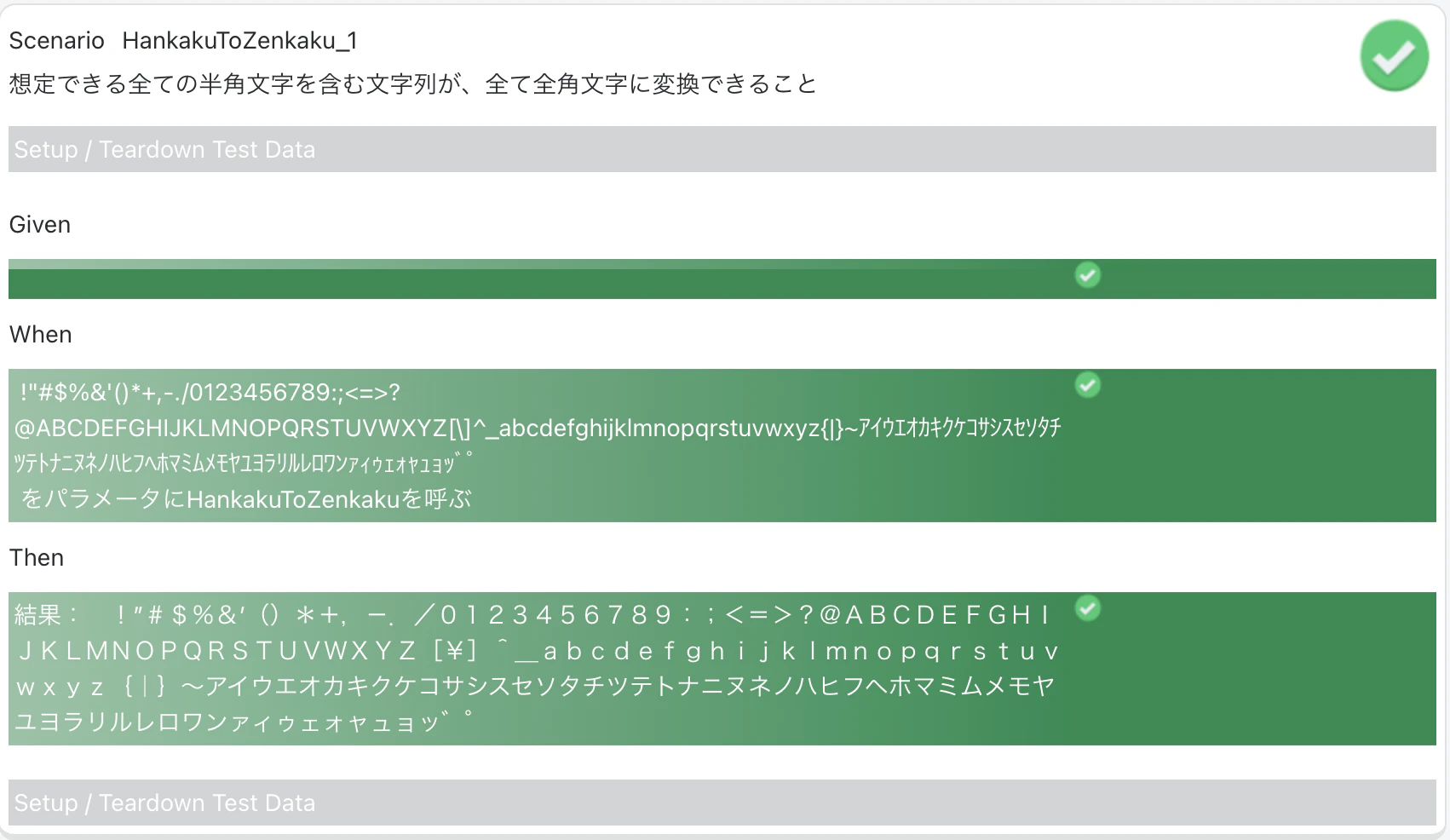
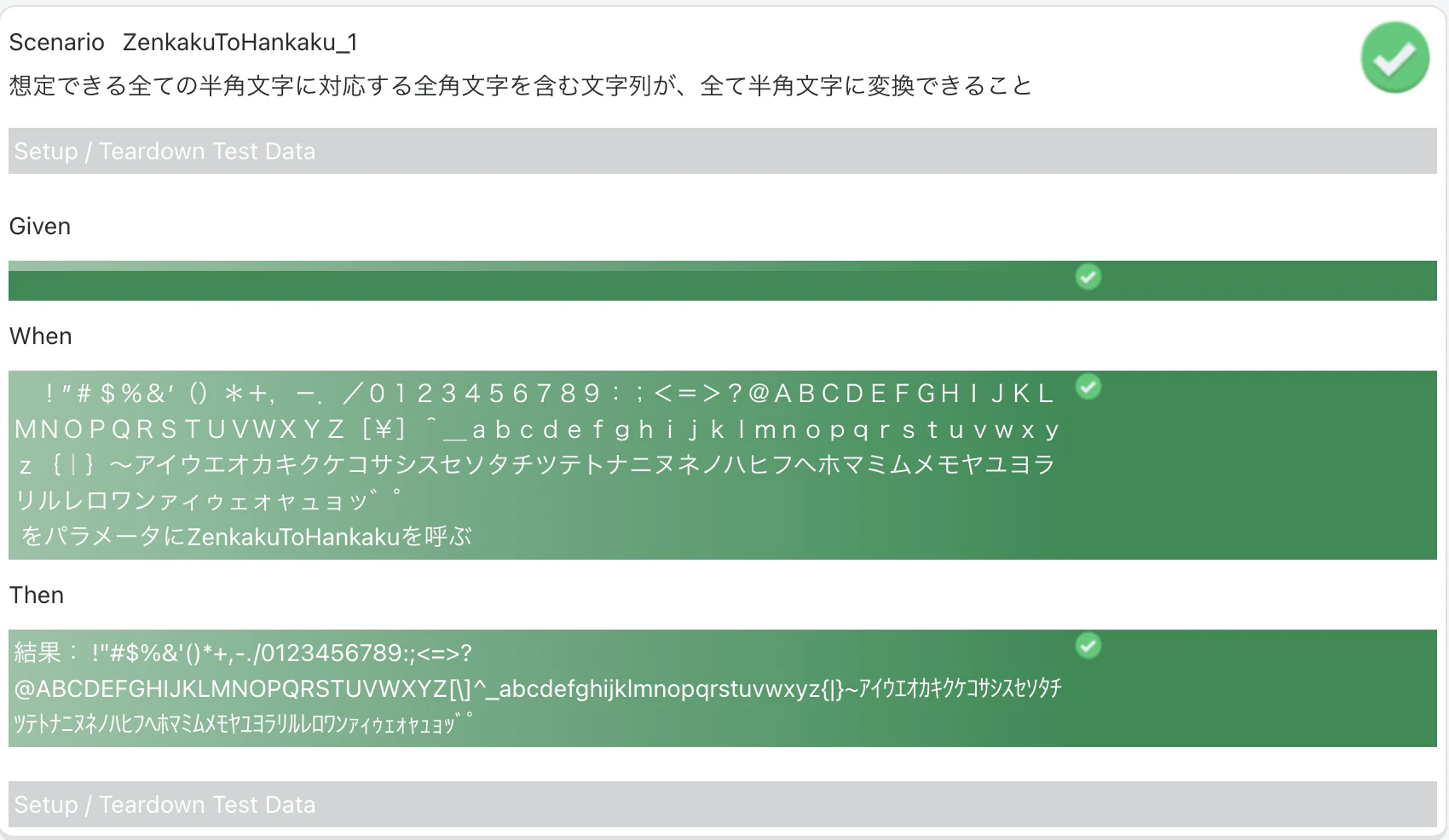
" !\"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\\]^_`abcdefghijklmnopqrstuvwxyz{|}~アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワンァィゥェォャュョッ゙゚"
以下の点を修正してテストに使う。
- 二重引用符は二重にする
- エスケープ文字としてのバックスラッシュは除去
- $\text{U+2018}$は、半角形式がないからなのか変換後が想定外の文字になったので除去
上記の文字セットの全角版も作ってもらう。
上記の文字列内の全ての半角文字を対応する全角文字に置き換えたものを作ってください
先の回答で列挙した半角文字を、全て対応する全角文字に置き換えた文字列(二重引用符で囲んだもの)を作成します。
この文字列は、全角スペース、全角英数字、全角記号($\text{Unicode}$の$\text{Fullwidth Forms}$ブロック)、および全角カタカナ(濁点・半濁点含む)で構成されています。
" !”#$%&’()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_‘abcdefghijklmnopqrstuvwxyz{|}~アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモヤユヨラリルレロワンァィゥェォャュョッ゛゜"
以下の点を修正してテストに使う。
- バックスラッシュ文字は「¥」になるようなので置き換え
- $\text{U+2018}$に対応する文字は削除
BDD Frameworkでテスト作成
BDD Frameworkのテストケースはそのまま、作成したActionで何ができるかの解説・0時にもなるので作成しておく。
BDD Frameworkの基本的な使い方は以下の記事を参照。
以下、基本的なテストケースをBDD Frameworkで作ったので参考までに。
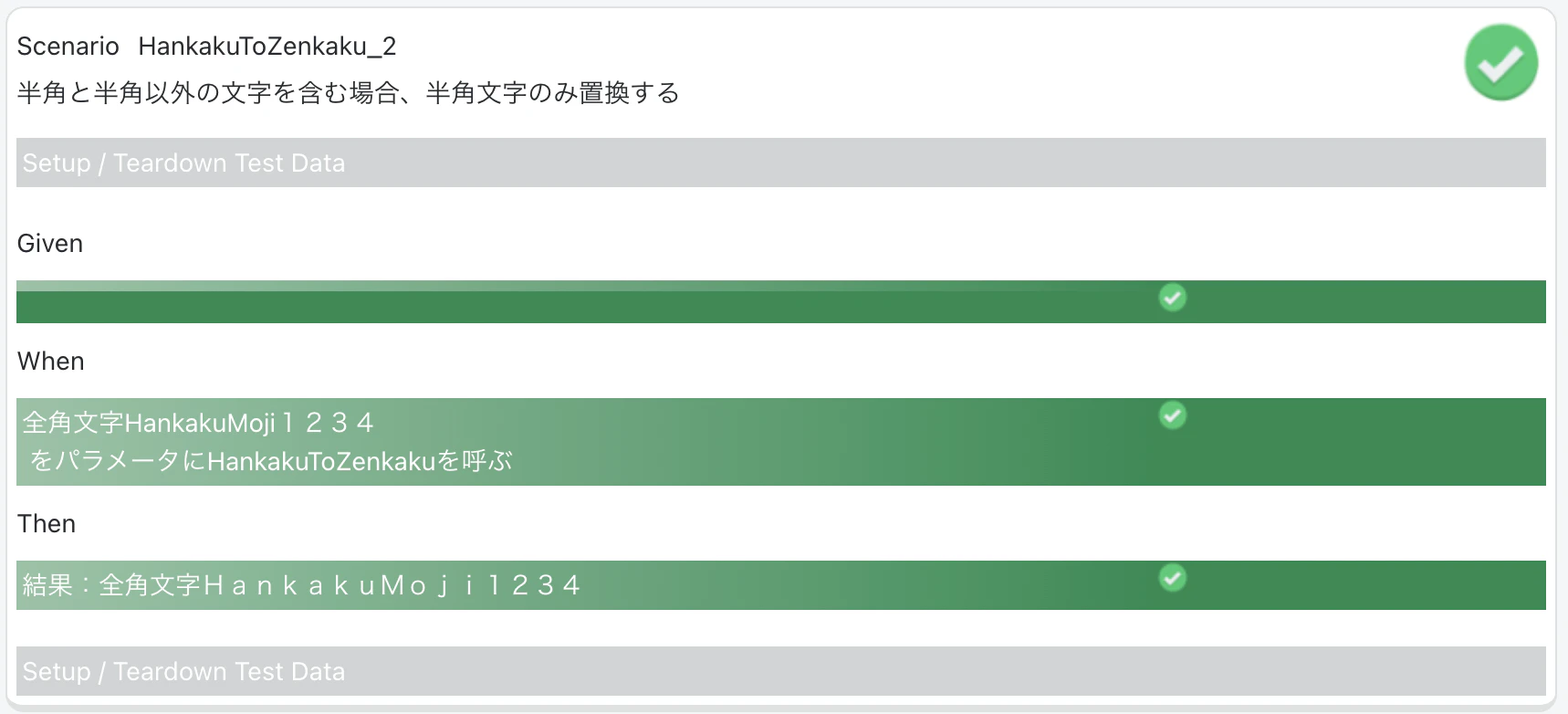
HankakuToZenkaku
文字種網羅
変換非対象文字を含む場合、対象文字のみ置換する
ZenkakuToHankaku
文字種網羅
変換非対象文字を含む場合、対象文字のみ置換する
