これまで幾つかのパターンでOutSystemsの周辺的な開発に生成AIの助けを借りる方法を試してきた(関連記事項目参照)。
ここでは、そのバリエーションとして、複数のPDFファイルを受け取り、1つに結合して返すClient Actionを作ってみる。
修正履歴
- 2025/04/12 「代替案2」を追加:pdf-libが出力する結果をBASE64エンコードしたString型で返すAPIを使う方法
関連記事(生成AIの助けを借りてODCの開発を支援する)
環境情報
ODC Studio(Version 1.5.15)
VSCode (Version 1.98.2)
GitHub Copilot (VSCodeのExtension。1.277.0)
最初のプロンプト
JavaScriptで以下の関数を作ってください。
入力:バイナリ形式のPDFファイル2つ
出力:入力を結合した1つのPDFファイル
使用するライブラリのライセンスを確認
pdf-libを利用するコードが出力された。
このライブラリは、上記プロジェクトページによると、MITライセンス。ただし、次項でダウンロードしたファイルにはApache License, Version 2.0の記述がいくつか見られた。
おそらく内部で使われていて結合された他のライブラリ由来だろうか。
出力を検討:nodeで動かす前提のコードになってしまっている→プロンプトを修正
npmコマンドでモジュールをインストールするように指示が出た。
まず、pdf-libをインストールしてください。
npm install pdf-lib
OutSystemsのApp内から使うので、nodeは使わない方法にしたい。
プロンプトを以下のように修正。
JavaScriptで以下の関数を作ってください。
入力:バイナリ形式のPDFファイル2つ
出力:入力を結合した1つのPDFファイル
ライブラリは、開発者が手動でダウンロードし、同じアプリケーション内に配置します。
このプロンプトによって、ライブラリを用意する部分は以下のように変わった。「(GitHub)」の部分はpdf-libのプロジェクトページ。
1. PDF-Libのダウンロード
PDF-Libの公式リポジトリ(GitHub)からライブラリをダウンロードします。
ダウンロードしたファイルをプロジェクト内の適切なフォルダ(例: libs/pdf-lib.js)に配置します。
pdf-libのInstallationページによると、UMD Moduleの方を選べば、JavaScriptのパッケージマネージャーを使わない環境でも動作するらしいので、この方法を使うことにする。
You can also download pdf-lib as a UMD module from unpkg or jsDelivr. The UMD builds have been compiled to ES5, so they should work in any modern browser. UMD builds are useful if you aren't using a package manager or module bundler. For example, you can use them directly in the <script> tag of an HTML page.
上記ドキュメントに示されている
https://unpkg.com/pdf-lib/dist/pdf-lib.min.js
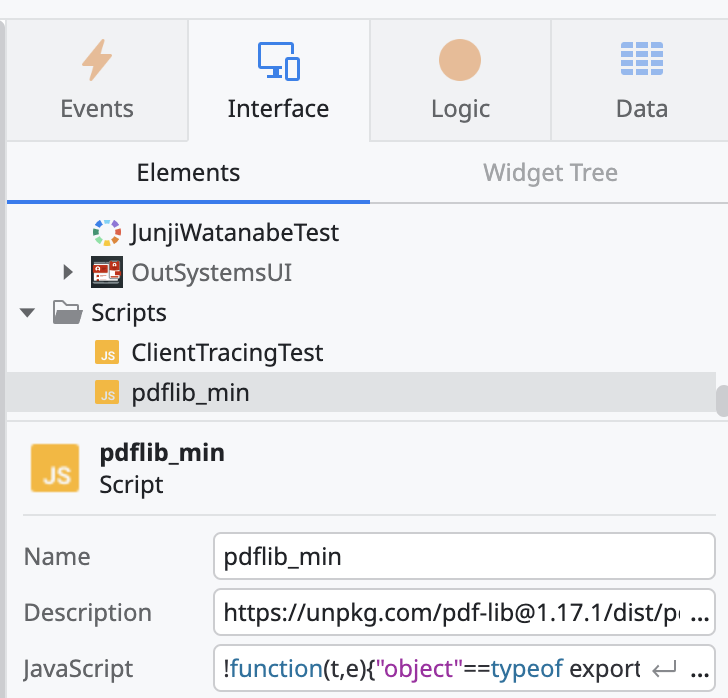
のリンクからファイルをダウンロードし、ODC StudioからScrptsフォルダにインポートする。
手順は、Interfaceタブ > Scriptsフォルダを右クリックし、Import Scriptを選択し、ダウンロードしたライブラリを選択する。
インポートすると、以下のようになる。
出力を検討:JavaScriptのmoduleに非同期関数を定義する形式→OutSystemsなのでmoduleにする必要はない
出力されたコードを確認してみる。
すると、「JavaScriptのmoduleとして作っている(export defaultの記述から)」点がOutSystemsのClient Action内で使用するJavaScriptとしては気になる。
Client Actionに書くJavaScriptコードはmoduleとして書かない。
// Import the PDF-Lib library from the local file
import { PDFDocument } from './libs/pdf-lib.js';
/**
* Merge two binary PDF files into one.
* @param {Uint8Array} pdf1 - The binary data of the first PDF.
* @param {Uint8Array} pdf2 - The binary data of the second PDF.
* @returns {Promise<Uint8Array>} - The binary data of the merged PDF.
*/
async function mergePDFs(pdf1, pdf2) {
// Load the first PDF
const pdfDoc1 = await PDFDocument.load(pdf1);
// Load the second PDF
const pdfDoc2 = await PDFDocument.load(pdf2);
// Create a new PDF document
const mergedPdf = await PDFDocument.create();
// Copy pages from the first PDF
const pages1 = await mergedPdf.copyPages(pdfDoc1, pdfDoc1.getPageIndices());
pages1.forEach((page) => mergedPdf.addPage(page));
// Copy pages from the second PDF
const pages2 = await mergedPdf.copyPages(pdfDoc2, pdfDoc2.getPageIndices());
pages2.forEach((page) => mergedPdf.addPage(page));
// Serialize the merged PDF to Uint8Array
const mergedPdfBytes = await mergedPdf.save();
return mergedPdfBytes;
}
export default mergePDFs;
そこで、プロンプトを再び変更し、この点を改善したコードにしてもらう。
JavaScriptで以下の関数を作ってください。
入力:バイナリ形式のPDFファイル2つ
出力:入力を結合した1つのPDFファイル
条件:
- ライブラリは、開発者が手動でダウンロードし、同じアプリケーション内に配置します
- 関数はmoduleに配置しないでください
出力を検討:requireを使う文が出力された→ライブラリはscriptタグを使ってロードする
新しいプロンプトを入力すると、以下の出力(先頭だけ抜粋)。
// 必要なライブラリを読み込みます(pdf-libを手動でダウンロードして配置してください)
const fs = require('fs');
const { PDFDocument } = require('pdf-lib');
...
require()も普通は使わないと思うが、この部分は無視すればいい。
あるいは、プロンプトで、ダウンロードしたライブラリはscriptタグで読み込む、という記載を追加する。「requireを使わないでください」という注意書きは、含めないと無理やり使われてしまったので、仕方なく追加している。
以下はプロンプト例。
JavaScriptで以下の関数を作ってください。
入力:バイナリ形式のPDFファイル2つ
出力:入力を結合した1つのPDFファイル
条件:
- ライブラリは、開発者が手動でダウンロードし、同じアプリケーション内に配置します
- ライブラリの読み込みにはscriptタグを使ってください(requireを使わないでください)
- 関数は非同期処理にしないでください
- 関数はmoduleに配置しないでください
出力されたコードをClient Actionに組み込む
色々プロンプトを変えてきた結果、使えそうなコードになったのでODCの組み込んでいく。
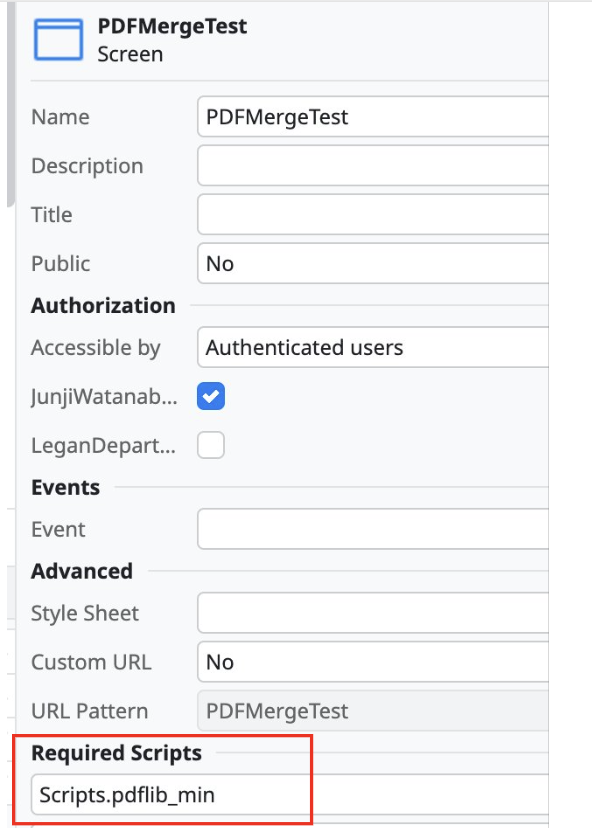
Screenでpdf-libをロードする
テスト用ScreenのRequired Scriptsプロパティで、Scriptsフォルダにインポートしておいたライブラリを指定。これで、実行時にライブラリがロードされ、利用可能になる。
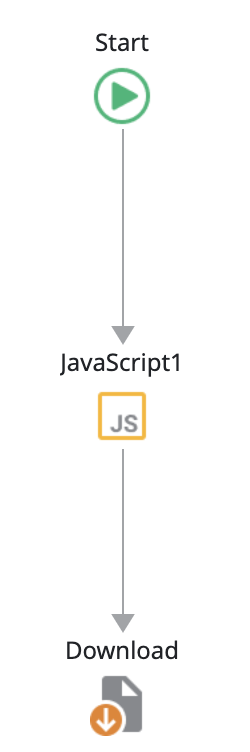
Client Actionを作成
Client ActionにJavaScript要素とDownload要素(JavaScript要素のOutput ParameterのBinary Dataをダウンロードさせる)を配置。
JavaScript要素に出力されたコードを貼り付け
JavaScript要素のParameter(全てBinary Data型)。

async function mergePDFs(pdf1Binary, pdf2Binary) {
try {
// PDFLibのPDFドキュメントを読み込む
const pdfDoc = await PDFLib.PDFDocument.create();
const pdf1 = await PDFLib.PDFDocument.load(pdf1Binary);
const pdf2 = await PDFLib.PDFDocument.load(pdf2Binary);
// PDF1の全ページを追加
const pdf1Pages = await pdfDoc.copyPages(pdf1, pdf1.getPageIndices());
pdf1Pages.forEach((page) => pdfDoc.addPage(page));
// PDF2の全ページを追加
const pdf2Pages = await pdfDoc.copyPages(pdf2, pdf2.getPageIndices());
pdf2Pages.forEach((page) => pdfDoc.addPage(page));
// 結合したPDFをバイナリ形式で出力
const mergedPdfBytes = await pdfDoc.save();
return mergedPdfBytes;
} catch (error) {
console.error("PDFの結合中にエラーが発生しました:", error);
throw error;
}
}
$parameters.MergedPdf = mergePDFs($parameters.Pdf1, $parameters.Pdf2);
動作確認→pdf-libから返る型がODCのBinary Data型と互換性がないようだ
上記のまま実行すると、ブラウザの開発者ツール > Consoleタブ上で以下のエラーが出ることが確認できた。
PDFの結合中にエラーが発生しました: TypeError: this._content.substr is not a function
何かの変数が想定外の型になっていそうだというあたりがつくので、開発者ツールのデバッガでブレークポイントを設定して実行を止め、「await pdfDoc.save()」が返す値の型を確認してみたところ、「Uint8Array」だった。
OutSystemsのClient側でのBinary DataはBASE64エンコードした文字列なので、「Uint8ArrayをBASE64エンコードした文字列に変換する」処理が必要。
こういう処理は、生成AIがうまく書いてくれることが多い気がする。プロンプトはなぜか英語で書いてしまっていたが、以下の通り。
Can Uint8Array be converted into BASE64 string?
関数定義を出力してくれたのでこれをそのまま使うことにする。
function uint8ArrayToBase64(uint8Array) {
// Convert Uint8Array to a binary string
const binaryString = Array.from(uint8Array)
.map(byte => String.fromCharCode(byte))
.join('');
// Encode the binary string to Base64
return btoa(binaryString);
}
async/await対策
生成AIに聞いたところ、pdf-libはasyncの機能しかないらしい(裏は取っていない)。
- asyncの関数は、asyncの関数からしか呼べない
- OutSystemsのClient Action内のJavaScriptで非同期処理するにはasync/awaitではなく、OutSystems提供の\$resolve/\$rejectを使う必要がある(使わないと、Client Actionはpdf-libの終了を待たずに終わってしまい、結合結果を取れない)
ので少し工夫が必要。
対策としては、「対象処理の実行を、asyncをつけた即時実行関数式で呼び、その最後で\$resolve()を呼ぶ」ことで解決した。
以上を受けて、JavaScriptのコードは以下。
// PDF結合関数
async function mergePDFs(pdf1Binary, pdf2Binary) {
try {
// PDFLibのPDFドキュメントを読み込む
const pdfDoc = await PDFLib.PDFDocument.create();
const pdf1 = await PDFLib.PDFDocument.load(pdf1Binary);
const pdf2 = await PDFLib.PDFDocument.load(pdf2Binary);
// PDF1の全ページを追加
const pdf1Pages = await pdfDoc.copyPages(pdf1, pdf1.getPageIndices());
pdf1Pages.forEach((page) => pdfDoc.addPage(page));
// PDF2の全ページを追加
const pdf2Pages = await pdfDoc.copyPages(pdf2, pdf2.getPageIndices());
pdf2Pages.forEach((page) => pdfDoc.addPage(page));
// 結合したPDFをバイナリ形式で出力
const mergedPdfBytes = await pdfDoc.save();
return uint8ArrayToBase64(mergedPdfBytes);
} catch (error) {
console.error("PDFの結合中にエラーが発生しました:", error);
throw error;
}
}
function uint8ArrayToBase64(uint8Array) {
// Convert Uint8Array to a binary string
const binaryString = Array.from(uint8Array)
.map(byte => String.fromCharCode(byte))
.join('');
// Encode the binary string to Base64
return btoa(binaryString);
}
(async () => {
$parameters.MergedPdf = await mergePDFs($parameters.Pdf1, $parameters.Pdf2);
$resolve();
})();
代替案
Screenに別のClient Actionを作り、JavaScriptの最後でこのClient Actionを呼び出す(Input Parameterとして結合後のファイルバイナリを渡す)という方法も機能した。
代替案2(2025/04/12追記):save()でなくsaveAsBase64()を使う
Xでこの記事へのコメントをもらい、APIドキュメントを見に行った。すると、saveAsBase64()というまさに「BASE64エンコードされたバイナリデータ(String型)」を返してくれそうなメソッドを発見。
今回は生成AIのテストなので、プロンプトを変えながら試してみる。
まずは、素直に、pdf-libがこの用途のためのAPIを持っていないか聞いてみた。
mergePDFs関数の戻り値をBASE64エンコードしたstring型にしていますが、pdf-libは結合結果をこの型で返すAPIを持っていませんか?
結果は以下の通り。そんなAPIはないと言われた。
pdf-lib自体には、結合したPDFを直接Base64エンコードされた文字列として返すAPIはありません。ただし、pdf-libが提供するPDFDocument.save()メソッドは、結合したPDFをUint8Array形式で返します。このUint8ArrayをBase64エンコードするのは、現在のコードのように手動で行う必要があります。
生成AIの知識が古いのかもしれない。仕方がないので、API名とドキュメントの抜粋を貼って使えないか聞いてみた。
pdf-libのドキュメントを見ていたら、saveAsBase64というメソッドがあるようですが、これは使えませんか?
Serialize this document to a base64 encoded string or data URI making up a PDF file. For example:
save()をsaveAsBase64()に置き換えるだけでなく、不要になったuint8ArrayToBase64()を消したコードを返してくれた。元々知っていたのか、それともプロンプトの内容を踏まえてくれたのか、裏で検索に行ったのかは不明だが、とにかくいい感じに直してくれた。動作確認したら問題なく動作した。
// PDF結合関数
async function mergePDFs(pdf1Binary, pdf2Binary) {
try {
// PDFLibのPDFドキュメントを読み込む
const pdfDoc = await PDFLib.PDFDocument.create();
const pdf1 = await PDFLib.PDFDocument.load(pdf1Binary);
const pdf2 = await PDFLib.PDFDocument.load(pdf2Binary);
// PDF1の全ページを追加
const pdf1Pages = await pdfDoc.copyPages(pdf1, pdf1.getPageIndices());
pdf1Pages.forEach((page) => pdfDoc.addPage(page));
// PDF2の全ページを追加
const pdf2Pages = await pdfDoc.copyPages(pdf2, pdf2.getPageIndices());
pdf2Pages.forEach((page) => pdfDoc.addPage(page));
// 結合したPDFをBase64エンコードされた文字列として出力
return await pdfDoc.saveAsBase64();
} catch (error) {
console.error("PDFの結合中にエラーが発生しました:", error);
throw error;
}
}
(async () => {
$parameters.MergedPdf = await mergePDFs($parameters.Pdf1, $parameters.Pdf2);
$resolve();
})();
感想
生成AI利用の練習として可能な限り生成AIで出力するように頑張ってみたが、少し大変だった。
向いていそうなところでだけ生成AIを積極的に使う方が生産性が上がるかもしれない。
生成AIが有効な使い方として、
- やりたいことに適したライブラリを教えてくれる
- よく知らないライブラリの使い方がわかるコードを出してくれる
- 仕様が明確であんまり難しくない処理は素早く正確に出力してくれる
非同期処理のような複雑な実装や、メジャーでない環境(OutSystemsはそう)での実装となると、おかしな出力が出てくる。そういう場合は、開発スキルと知識が重要になってしまいそう。