qwen tts でボイスクローン試してみた!(Mac の MPS でローカル動作)
「参照音声を投げて、日本語テキストを読ませる」を Mac だけでサクッと試したかったので、Qwen3-TTS の voice clone を FastAPI で包んでみました。
結論から言うと、
- Mac(Apple Silicon)でもMPSで動く
- Web UI(フォーム)から投げてWAVをダウンロードできる
- 型は
float32が良い - 今回作ったもの一式
つくったもの
ローカルで動く FastAPI サーバです。
-
GET /:簡易 Web UI- 参照音声(ボイス元データ)をアップロード
- 読ませたいテキスト(日本語優先)を入力
- 送信すると
tts.wavがダウンロードされる
-
POST /api/tts:HTTP API(multipart/form-data)
リポジトリは uv で依存管理しています。
環境
- macOS(Apple Silicon)
- Python 3.12
uv- モデル:
Qwen/Qwen3-TTS-12Hz-0.6B-Base(Hugging Face)
セットアップ
uv venv --python 3.12
source .venv/bin/activate
uv sync
初回実行時に Hugging Face からモデルが落ちてきます。
起動(ローカル / LAN 公開)
まずはローカルで。
uv run uvicorn tts_api.app:app --host 127.0.0.1 --port 8000
LAN 内の別端末から叩きたいなら 0.0.0.0 バインド。
HF_HOME="$PWD/.cache/huggingface" uv run uvicorn tts_api.app:app --host 0.0.0.0 --port 8010
macOS のファイアウォール許可が出たら通します。
Web UI で試す
ブラウザで http://127.0.0.1:8000/ を開きます。
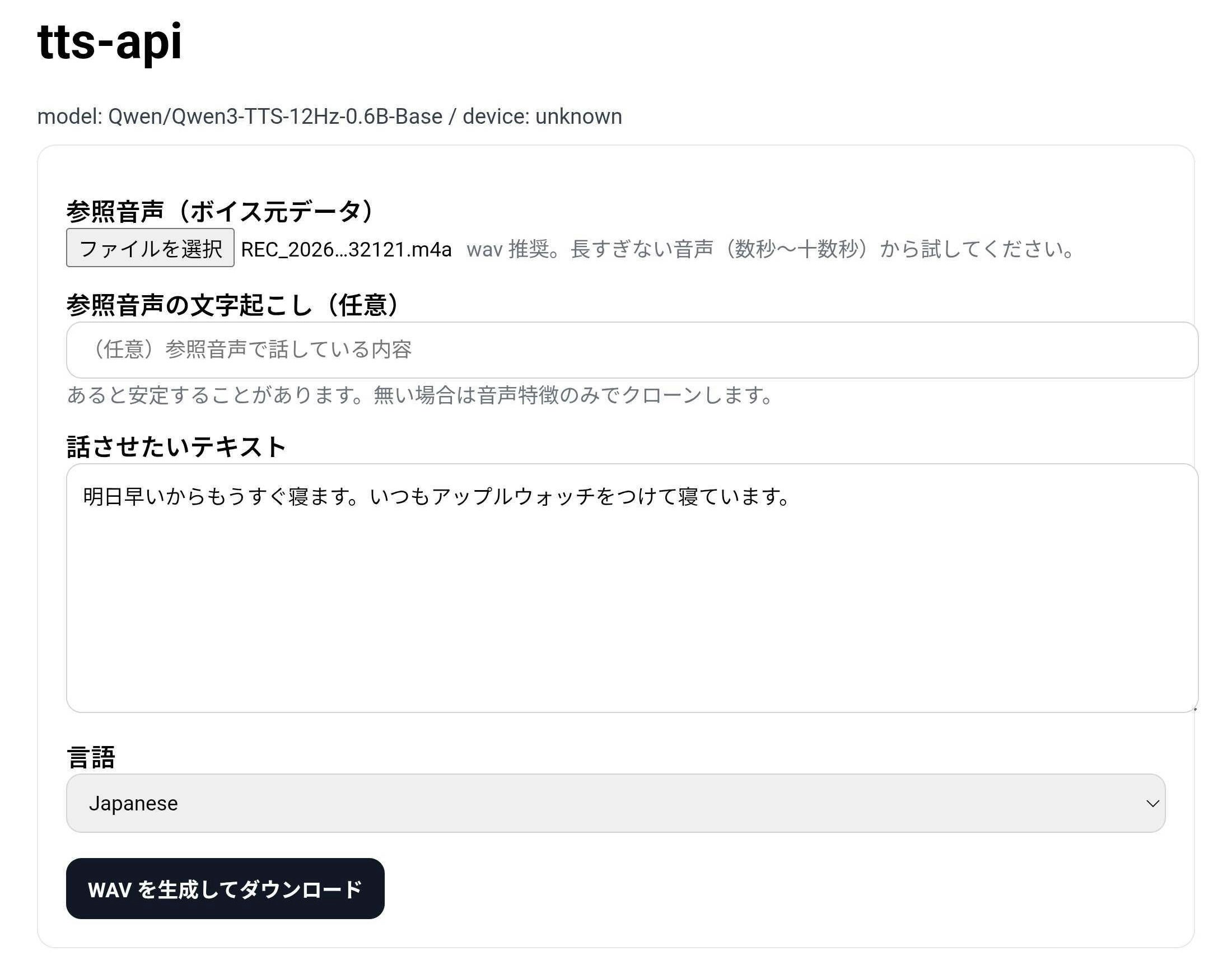
コツはこれ:
- 参照音声は最初短め(3〜15秒)が安定(23秒でもいけた。)
- ノイズや残響が少ない音声だと声の寄り方が良い
-
ref_text(参照音声の文字起こし)を入れると安定することがある(なくても問題ないはず)
curl で叩く(API)
curl -F "ref_audio=@voice.wav" \
-F "text=こんにちは。今日は声クローンの実験です。" \
-F "language=Japanese" \
http://127.0.0.1:8000/api/tts -o out.wav
ハマりどころ(Internal Server Error 編)
500 が返ってきたとき、ログを掘るとこんな落ち方をしていました。
RuntimeError: probability tensor contains either inf, nan or element < 0
要は「サンプリングの確率が壊れて torch.multinomial が死んだ」パターンです。
MPS と dtype(特に fp16)絡みで、たまにこういう “確率が NaN になる” 系が起きます。
そこで対策を入れました:
- 既定 dtype を
float32(安定優先)に - 上のエラーを検知したら
do_sample=False(greedy)でリトライ - それでもダメで「MPS + fp16」の時はfp32 でモデルをリロードして再試行(多分そっちがデフォ。)
ついでに: SoX 警告
ログに /bin/sh: sox: command not found が出ることがあります。
必須ではないケースもありますが、音声処理で使われることがあるので気になるなら入れておくと安心です。
brew install sox
まとめ
Qwen3-TTS の voice clone、Mac(MPS)でもちゃんと遊べました。
- UI から投げて WAV が落ちる、という “試せる形” にしておくと検証が速い
- MPS は速いけど、数値的不安定さはあるので dtype と生成設定は逃げ道を用意
- 参照音声は短く・クリアに。まずはそこから
次は、参照音声の前処理(長さ/サンプルレート/正規化)を API 側で固めて、入力ゆらぎで崩れにくくしたいところ。