これはGCP(Google Cloud Platform) Advent Calendar 2022の22日目のエントリーです。
はじめに
こんにちは、GAFA社長です。
私はHPEでクラウドネイティブ系のいろいろ(雑)を生業としているのですが、基本インフラのひとなので、技術検証みたいなことをやるときも、その対象はKubernetesクラスタそのものであったり、OS、ネットワーク、ストレージといったレイヤーであることも多いわけです。
で、いちいち会社の検証機材を調達するのもめんどくさくて病むので、自宅のPCの中に仮想マシンイメージを各種揃えておいて必要に応じて立ち上げて使う、というようなことをやっています。
一方で、Kubernetes上でのもろもろ(雑)ももちろんやっていますので、Kubernetes Nativeなワークロード管理に慣れてしまうと、作ったものがそのままコードとして残せて、動いているワークロードをコードと一致させるところはKubernetesがよろしくやってくれる、というのは、整理整頓が苦手な私には最高なわけです。
というわけで、Kubernetesで仮想マシンも管理できるKubeVirtは弊宅のような逸般の誤家庭にはうってつけのテクノロジーなので、
- 素のKubernetes(kubeadmてきな)+アップストリームのKubeVirt
- Harvester
などの導入を考えていたところ、昨年プレビューリリースされていたAnthos clusters on bare metalのKubeVirtサポート(Anthos VM Runtime)がこの9月にGAになっていたことを知ったので、Google Cloudさんともいろいろ(雑)やっている私としては、仕事のための素振りをかねて試してみることにしました。あわよくばKubeVirtとAnthos clusters on bare metalの両方にキャッチアップしてしまおうという魂胆です。いわゆる 「やってみた」系のアレです。とりとめもなくやってみたことを書くので長いよ。すまんな。
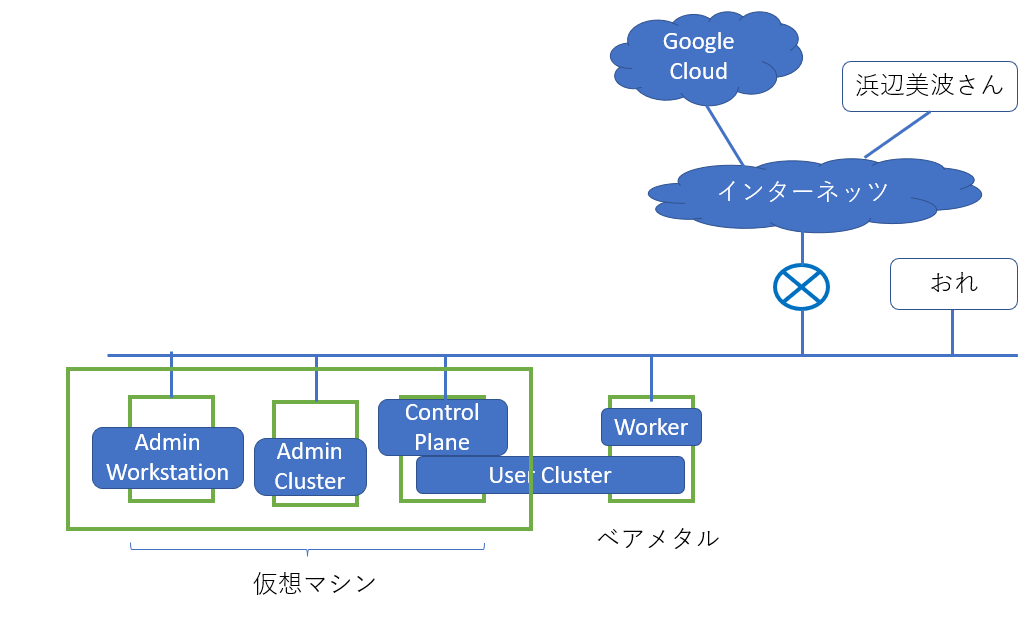
構成を決める
Anthos clusters on bare metalのデプロイ構成を考えるときに、以下の概念は理解しておいたほうがよいでしょう。
- User cluster
- ユーザーのワークロードを動かすためのKubernetesクラスタです。まあ普通のKubernetesです。
- Admin cluster
- User clusterを管理するためのKubernetesクラスタです。
- User clusterはAdmin cluster上の
Clusterリソースとして定義され、Operatorによって維持されます。つまりKubernetesでKubernetesを管理するわけです。
- Admin workstation
- インフラ構築者が
gcloud,bmctl,kubectlといったコマンドを叩くためのLinux環境です。 -
bmctlはAnthos clusters for bare metalをデプロイするためのツールなのですが、これを実行するとkindのコンテナが起動します。つまりAdmin clusterをデプロイするときは、KubernetesをデプロイするためのKubernetesをKubernetesがデプロイする ということになります。どんだけKubernetes好きやねん。
- インフラ構築者が
富豪構成
ベアメタル版 Anthos クラスタは、異なる可用性、分離、リソースのフットプリントのニーズに合わせて複数のデプロイモデルをサポートします。
まずはガチエンタープライズデータセンター向けの構成を考えます。仕事で提案するときはこれがスタート地点。
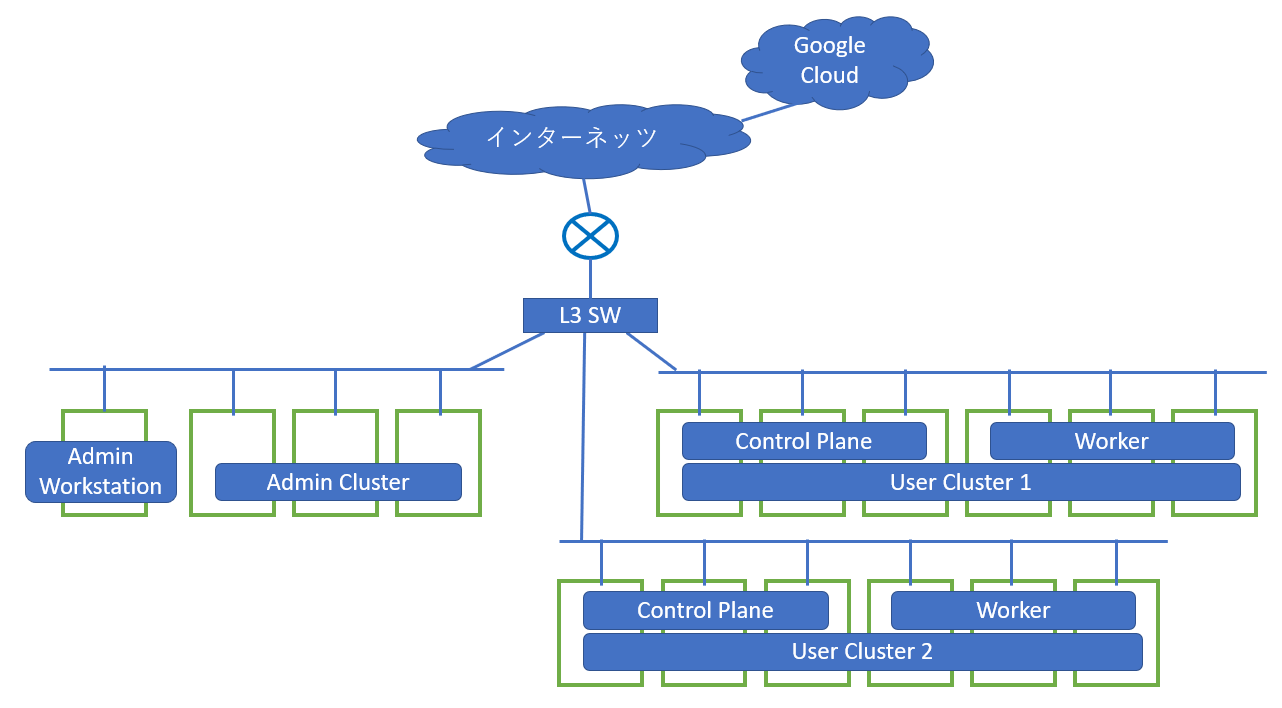
こんな感じですかね。
逸般の誤家庭向け構成
さすがにマルチクラスタは必要ないのですが、Google Cloud ConsoleからAdmin Clusterを経由してのUser Clusterの管理は機能として試したいので、いちおうデプロイメントモデルとしてはマルチクラスタモデルを採用するとして、こうなります。
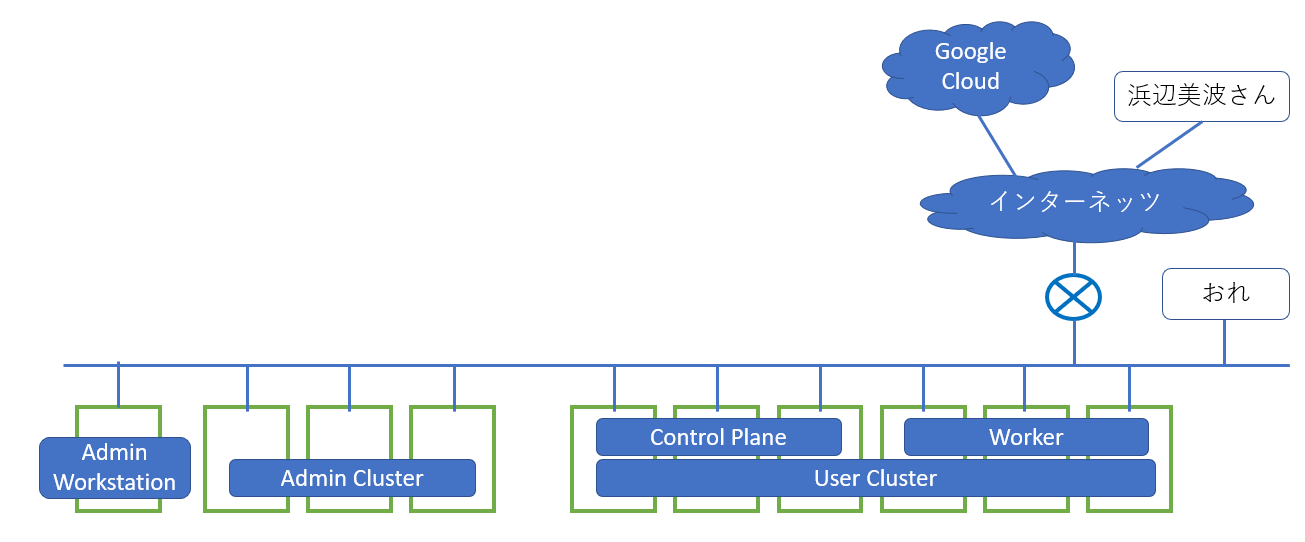
そしてGAFAと言えどベアメタルマシンがゴロゴロ転がってるわけではないので、Admin ClusterとUser Control PlaneのHAは捨てて、かつユーザーワークロード(ここで試したいのは主にVM Pod)が乗らないものは仮想マシンで動かすとして、こんな感じを目指してとりあえず進めようと思います。
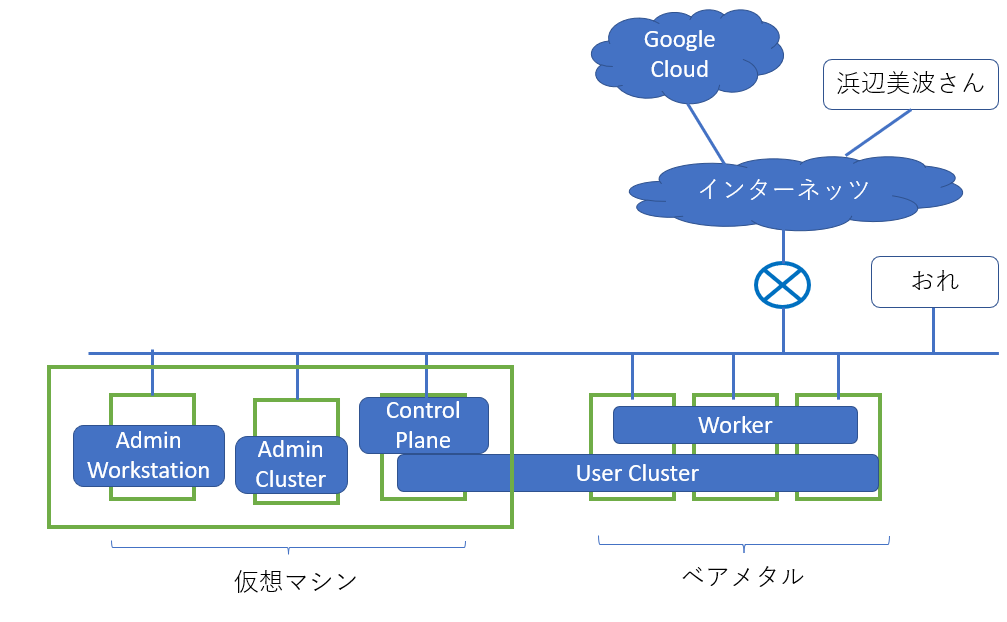
では構築開始
構築手順については 公式嫁 って話なのですが、公式ドキュメントもあちこち飛んで読みにくかったり間違ってたりするので、以下参考までに、私がやった流れを記録しておきます。やさC。
Google Cloudにプロジェクトを作ってAnthosを有効にしておく
ここでは社長@gafa.co.jpとして、Google Cloudに新規プロジェクトを作りました。作ったプロジェクトでAnthosを有効にしておきます。GAFA㈱はAnthosを初めて使うアカウントさんなので、30日間$800のお試しクレジットがもらえます。円安のいまなら11万円。得した気分。ていうかお試しでそんなにもらえるってことは、逆にAnthosけっこう高いってことか・・・?
追記:このお試しクレジットのスコープはGCP上のAnthosなので、オンプレのAnthosクラスタ(GDC-Vという名前になった模様)に対するAPIはカバーされません。
Admin workstationを作る
Admin workstationは別にわざわざ立てなくても、ふだん使ってるLinux環境があればそれでもよいです。WSL2でもいいのかもしれないけどおすすめはしません。私は環境が混ざるのがいやなので、それ用にUbuntuの仮想マシンを立てました。
そこに gcloud と kubectl と docker をセットアップしておきます。dockerは作業ユーザー権限で使えるように、作業ユーザーをdockerグループに入れておきます。
注意点としては、Anthos cluster on bare metalを構成するすべてのノードに対して、Admin workstationの作業ユーザーから 各ノードのrootへのパスワードなしssh もしくは 各ノードの特定ユーザーへのパスワードなしssh + そのユーザのパスワードなしsudo が必要となります。Ansibleみたいなもんですね。インフラおじさん的には前者には抵抗があるので後者で行くことにしました。
bmctlとAnthos clusters on bare metalのパッケージを取得
クラスタ構成ノードの用意
Admin clusterとUser clusteを構成する各ノードを用意するわけですが、私はUbuntu派なのでこちらに従います。
Ubuntu22.04はサポートされていないのか?まあいいけど。
また、上記のリンクにはDockerのインストール手順が書いてありますが、 Admin workstation以外のノードにはDockerは入れないほうがいいです。 Anthos cluster on bare metalのデフォルトのコンテナランタイムはcontainerdですので、Dockerを入れてもハマりどころを増やすだけです。
Admin clusterのデプロイ
基本的にはここに書かれている手順通り、
-
bmctl create configでクラスタ構成ファイル(YAML)のひな型を生成 - YAMLを編集して
bmctl create clusterでデプロイ
です。クラスタ構成ファイルは冒頭の鍵ファイル情報以外はKubernetesのマニフェスト形式です。仮に192.168.0.201というシングルノード構成とする場合はこんな感じになります。
gcrKeyPath: bmctl-workspace/.sa-keys/<俺のプロジェクトID>-anthos-baremetal-gcr.json
sshPrivateKeyPath: <SSH秘密鍵のパス>
gkeConnectAgentServiceAccountKeyPath: bmctl-workspace/.sa-keys/<俺のプロジェクトID>-anthos-baremetal-connect.json
gkeConnectRegisterServiceAccountKeyPath: bmctl-workspace/.sa-keys/<俺のプロジェクトID>-anthos-baremetal-register.json
cloudOperationsServiceAccountKeyPath: bmctl-workspace/.sa-keys/<俺のプロジェクトID>-anthos-baremetal-cloud-ops.json
---
apiVersion: v1
kind: Namespace
metadata:
name: cluster-anthosbmlab-admin
---
apiVersion: baremetal.cluster.gke.io/v1
kind: Cluster
metadata:
name: anthosbmlab-admin
namespace: cluster-anthosbmlab-admin
spec:
type: admin
profile: default
anthosBareMetalVersion: 1.13.1
gkeConnect:
projectID: <俺のプロジェクトID>
controlPlane:
nodePoolSpec:
nodes:
- address: 192.168.0.201
clusterNetwork:
pods:
cidrBlocks:
- 10.1.0.0/16
services:
cidrBlocks:
- 10.96.0.0/20
loadBalancer:
mode: bundled
ports:
controlPlaneLBPort: 443
vips:
controlPlaneVIP: 192.168.0.200
clusterOperations:
projectID: <俺のプロジェクトID>
location: us-central1
storage:
lvpNodeMounts:
path: /mnt/localpv-disk
storageClassName: local-disks
lvpShare:
path: /mnt/localpv-share
storageClassName: local-shared
numPVUnderSharedPath: 5
nodeConfig:
podDensity:
maxPodsPerNode: 250
nodeAccess:
loginUser: anthosadmin
bmctl create clusterが成功すると、~/bmctl-workspace/クラスタ名の下にkubeconfigが生成されるので、それを使って
kubectl --kubeconfig bmctl-workspace/anthosbmlab-admin/anthosbmlab-admin-kubeconfig get pod --all-namespaces
とかやってみると
NAMESPACE NAME READY STATUS RESTARTS AGE
anthos-identity-service ais-d6bcd875f-cbgj8 1/1 Running 0 2d3h
capi-kubeadm-bootstrap-system capi-kubeadm-bootstrap-controller-manager-1.13.1-7f9885cb76kz9k 2/2 Running 0 2d3h
capi-system capi-controller-manager-1.13.1-69d77cf6-5rsjv 2/2 Running 0 2d3h
cert-manager cert-manager-584cdd7c89-pk2rq 1/1 Running 0 2d3h
cert-manager cert-manager-cainjector-68cbb4cf8f-ppr98 1/1 Running 0 2d3h
cert-manager cert-manager-webhook-9cbdd65b6-7hjj2 1/1 Running 0 2d3h
gke-connect gke-connect-agent-20220819-00-00-8665599b78-rjrj5 1/1 Running 1 (2d3h ago) 2d3h
gke-managed-metrics-server metrics-server-6447f49db5-j52vs 2/2 Running 0 2d3h
kube-system anet-operator-5cc7b59859-kvqrc 1/1 Running 0 2d3h
kube-system anetd-j6tlk 2/2 Running 0 2d3h
kube-system anthos-cluster-operator-1.13.1-6b5b887495-29j6t 2/2 Running 0 2d3h
kube-system anthos-multinet-controller-75c5c8f4bd-cx5cx 1/1 Running 0 2d3h
...
みたいにいろいろわちゃわちゃ動いてるのが見えるので、やっとるやっとる、と眺めましょう。
Admin clusterをフリートに登録する
追記:これをやるとそのクラスタは課金対象になります。
オンプレにデプロイしたAnthosクラスタをGoogle Cloudのフリートに登録すると、Google Cloudによるマルチクラスタ管理機能を利用することができます。詳しくはこちら。
Admin clusterではユーザーワークロードを動かすわけではないのでフリートに登録する必要はなさそうな気もしますが、Admin clusterをフリートに登録すると、Google Cloud Consoleからの操作でUser clusterをデプロイできるというプレビュー機能が実装されたようですので、それを試すために登録してみることにしました。
登録手順はこちら。
フリートによる管理機能については後述します。
User clusterのデプロイ
Admin clusterが起動したら、次はUser clusterを作ります。
まずは
- Control Plane : 1ノード(仮想マシン)
- Worker : 1ノード(ベアメタル)
という最小構成で作ってみます。
Workerノードは逸般的な誤家庭用機器であるこいつを使います。 ファンレスなので猫の毛にまみれても安心。

せっかくなのでプレビュー機能である、Google Cloud Consoleからのクラスタ作成を試してみます。
ほうほう
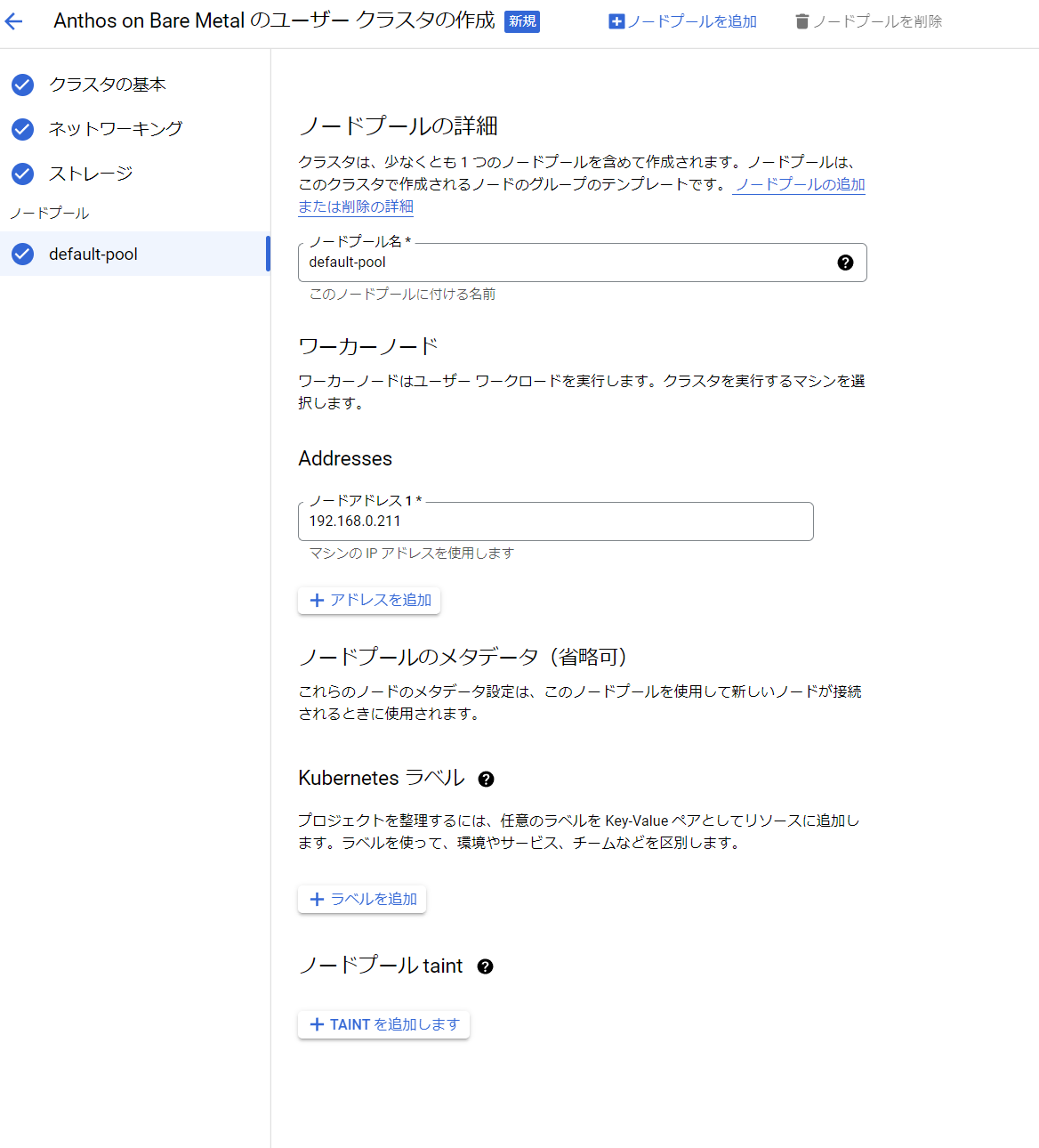
・・・結論から言うと失敗しました。
理由としては、先述のようにUser Clusterのノードに接続する際にsudo権限のあるユーザーを指定したかったのですが、Google Cloud Consoleからのデプロイではユーザー指定に対応しておらず、rootのsshが許可されていることが前提となっていました。プレビュー機能なのでまあ制約があるのは仕方がありません。
まあ実際の運用を考えると、GUIでぽちぽちやってわけがわからなくなるよりも、ちゃんとYAMLを書いてapplyというほうが正しいでしょう。GUI、あんなの飾りです。偉い人にはそれがわからんのですよ。
というわけでAdmin clusterを作ったときと同様、bmctlで作っていきます。
基本Admin clusterと同じです。違うのはingressVIPの指定が必要なのと、workerノードをNodePoolとして定義する必要があることぐらいですかね。この時点では1台しかないのでこんな感じです。
---
# Node pools for worker nodes
apiVersion: baremetal.cluster.gke.io/v1
kind: NodePool
metadata:
name: node-pool-1
namespace: cluster-anthosbmlab-usr1
spec:
clusterName: anthosbmlab-usr1
nodes:
- address: 192.168.0.211
bmctl create clusterが成功するとUser cluster用のkubeconfigが生成されるので、
anthosadmin@ubuntuvm:~$ kubectl --kubeconfig bmctl-workspace/anthosbmlab-usr1/anthosbmlab-usr1-kubeconfig get nodes
NAME STATUS ROLES AGE VERSION
anthosbmctl1 Ready control-plane,master 2d6h v1.24.5-gke.400
anthosbmusr1 Ready worker 2d6h v1.24.5-gke.400
こんな風に普通にKubernetesとして見えてきます。
ちなみに私はいちいちkubeconfigファイル指定するのがめんどくさいので、~/.kube/configにAdmin clusterとUser clusterのkubeconfigファイルの内容をまとめて、kubectl config use-contextで切り替えられるようにしました。
とりあえずここまでできましたよ。
User clusteをフリートに追加する
追記:これをやるとそのクラスタは課金対象になります。
追加手順はAdmin clusterのときと全く同じなので省略。
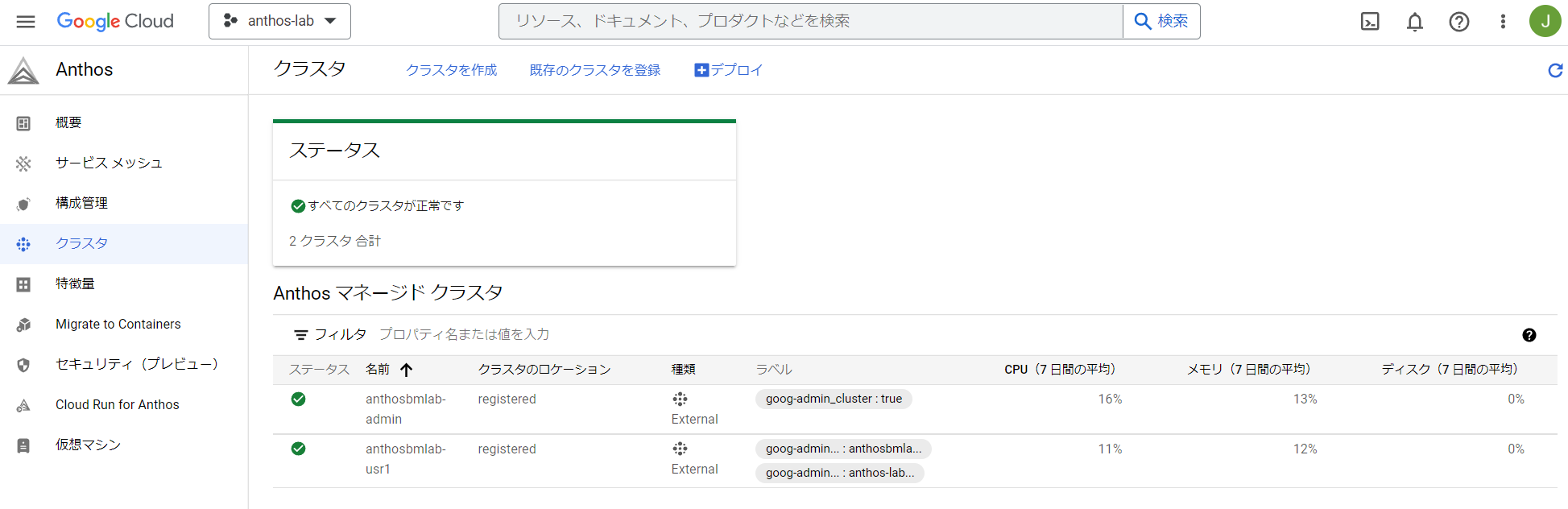
クラスタをフリートに登録すると、Google Cloud ConsoleのAnthosの画面ではこんなふうに見えます。
そして、Kubernetes Engineの画面でも見えるようになります。
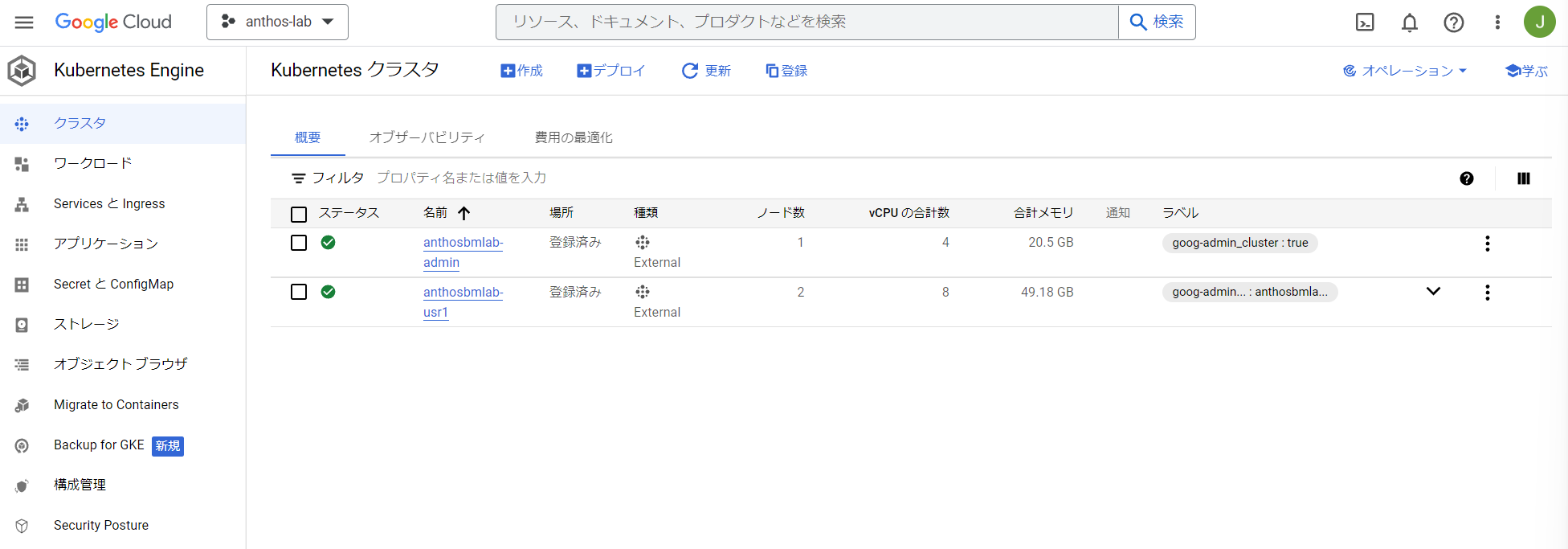
クラスタの種類がExternalとなっていて、GKEと異なるのは、ノード数にControl Planeも含まれるということです。
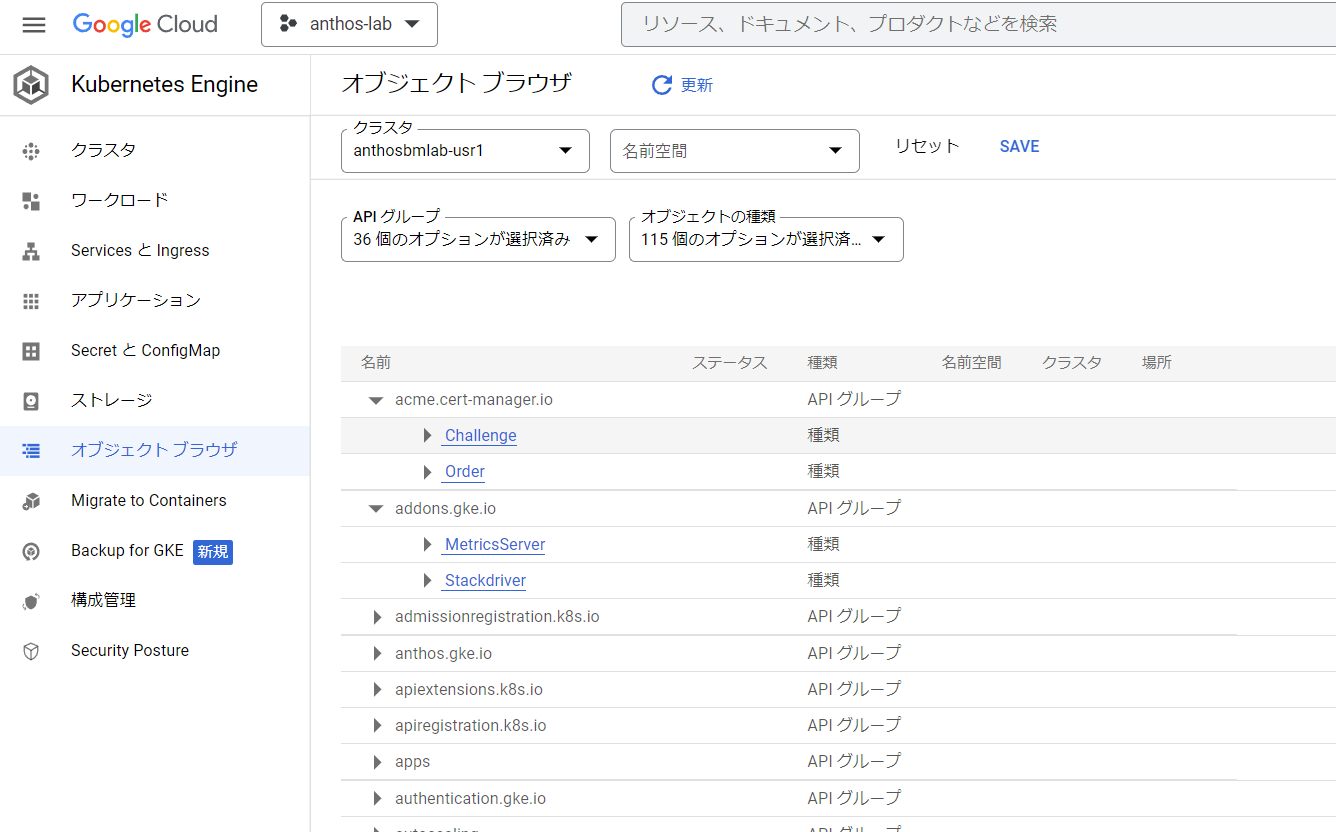
クラスタの中のオブジェクトなんかももちろん見えます。ほぼGKEじゃん。 おうちGKE。
Anthos VM Runtimeを有効にする
いよいよAnthos VM Runtimeを使ってみます。Anthos VM RuntimeはKubeVirtをベースにしていますが、いろいろな機能拡張が行われているようです。
Anthos clusters on bare metalのUser clusterにはVMRuntimeというカスタムリソースが定義されています。デフォルトではenabled: falseになっていますので、これをenabled: trueに変更します。
kubectl edit vmruntime
apiVersion: vm.cluster.gke.io/v1
kind: VMRuntime
metadata:
name: vmruntime
spec:
enabled: true
# useEmulation defaults to "false" if not set.
useEmulation: true
# vmImageFormat defaults to "qcow2" if not set.
vmImageFormat: qcow2
とりあえずやっつけVMを作ってみる
試しにVMを作ってみます。簡単です。
kubectl virt create vm testvm \
> --image ubuntu20.04 \
> --configure-initial-password test:password
と叩くとVMの作成が始まります。
Downloading the image from https://cloud-images.ubuntu.com/releases/focal/release/ubuntu-20.04-server-cloudimg-amd64.img, please wait
...........................................................................
Saved the image to /home/anthosadmin/google-virtctl/ubuntu-20.04-server-cloudimg-amd64.img
PVC default/testvm-boot-dv not found
DataVolume default/testvm-boot-dv created
Waiting for PVC testvm-boot-dv upload pod to be ready...
Pod now ready
...
出来上がったらVMを確認してみます。
anthosadmin@ubuntuvm:~$ kubectl get gvm
NAME STATUS AGE IP
testvm Running 4m40s 10.2.2.25
anthosadmin@ubuntuvm:~$
anthosadmin@ubuntuvm:~$ kubectl virt console testvm
Successfully connected to testvm console. The escape sequence is ^]
testvm login: test
Password:
Welcome to Ubuntu 20.04.5 LTS (GNU/Linux 5.4.0-135-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Tue Dec 6 11:46:24 UTC 2022
System load: 0.01 Processes: 138
Usage of /: 7.4% of 19.20GB Users logged in: 0
Memory usage: 5% IPv4 address for enp1s0: 10.0.2.2
Swap usage: 0%
0 updates can be applied immediately.
The programs included with the Ubuntu system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by
applicable law.
To run a command as administrator (user "root"), use "sudo <command>".
See "man sudo_root" for details.
test@testvm:~$ df
Filesystem 1K-blocks Used Available Use% Mounted on
udev 1995768 0 1995768 0% /dev
tmpfs 402608 1056 401552 1% /run
/dev/vda1 20134592 1530704 18587504 8% /
tmpfs 2013040 0 2013040 0% /dev/shm
tmpfs 5120 0 5120 0% /run/lock
tmpfs 2013040 0 2013040 0% /sys/fs/cgroup
/dev/loop1 94080 94080 0 100% /snap/lxd/23991
/dev/loop0 64768 64768 0 100% /snap/core20/1695
/dev/loop2 50816 50816 0 100% /snap/snapd/17883
/dev/vda15 106858 5313 101545 5% /boot/efi
/dev/sdb 996780 45216 882752 5% /mnt/kubevm-agent-installation
/dev/sda 1024 1024 0 100% /run/secrets/google/serviceaccount
tmpfs 402608 0 402608 0% /run/user/1000
test@testvm:~$
test@testvm:~$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc fq_codel state UP group default qlen 1000
link/ether f8:8f:ca:00:00:01 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.2/24 brd 10.0.2.255 scope global dynamic enp1s0
valid_lft 86310961sec preferred_lft 86310961sec
inet6 fe80::fa8f:caff:fe00:1/64 scope link
valid_lft forever preferred_lft forever
test@testvm:~$
コンソールから抜けるときは Ctrl + ]です。
作成されたVMのマニフェストは~/google-virtctl/testvm.yamlに保存されています。
apiVersion: vm.cluster.gke.io/v1
kind: VirtualMachine
metadata:
annotations:
vm.cluster.gke.io/configure-initial-password: test:password
creationTimestamp: null
labels:
kubevirt/vm: testvm
name: testvm
namespace: default
spec:
compute:
cpu:
vcpus: 2
memory:
capacity: 4Gi
disks:
- boot: true
driver: virtio
virtualMachineDiskName: testvm-boot-dv
interfaces:
- default: true
name: eth0
networkName: pod-network
osType: Linux
status: {}
もちろんあらかじめyamlをきっちり書いて、kubectl applyでもOKです。
Workerノードを追加する
そうこうしているあいだに なんか生えてきたよ。かわいいね。 プリインストールされているWindows11は何の躊躇もなく消し去って、こいつらを2台目・3台目のWorkerノードとして追加します。

Anthos clusters on bare metalでは、WorkerノードはNodePoolとして管理されます。GKEと同じですね。
NodePoolにノードを追加するには、各ノードのOS設定を済ませたら、クラスタ作成時にbmctlに渡したクラスタ構成ファイルのNodePoolを定義している部分に新たなノードのIPアドレスを書き加えます。
---
# Node pools for worker nodes
apiVersion: baremetal.cluster.gke.io/v1
kind: NodePool
metadata:
name: node-pool-1
namespace: cluster-anthosbmlab-usr1
spec:
clusterName: anthosbmlab-usr1
nodes:
- address: 192.168.0.211
- address: 192.168.0.212
- address: 192.168.0.213
その後
bmctl update cluster -c anthosbmlab-usr1 --kubeconfig /home/anthosadmin/bmctl-workspace/anthosbmlab-admin/anthosbmlab-admin-kubeconfig
として変更を適用するだけです。
ここでは Admin clusterのkubeconfig を指定します。なぜなら、User clusterの構成はAdmin cluster上のリソースとして管理されているからです。つまり、上記のbmctl update clusterは、Admin clusterに対してkubectl applyを実行しているのと同等です(実際kubectl applyでもできます)。User clusterにもろもろコンポーネントをインストールしたりするのは、Admin clusterで動いている小人たちa.k.a.Operatorのお仕事です。
ここでAdmin clusterに対して
kubectl -n cluster-anthosbmlab-usr1 get nodepool
と叩くとこのような結果が返ってきます。
NAME READY RECONCILING STALLED UNDERMAINTENANCE UNKNOWN
anthosbmlab-usr1 1 0 0 0 0
node-pool-1 1 2 0 0 0
RECONCILINGが2となっているのは、いま追加した2つのノードが準備中(Operatorが馬車馬のように働いている)ということです。
しばらく待つと
NAME READY RECONCILING STALLED UNDERMAINTENANCE UNKNOWN
anthosbmlab-usr1 1 0 0 0 0
node-pool-1 3 0 0 0 0
こうなって、その後User Cluster側で
kubectl get node
すると
NAME STATUS ROLES AGE VERSION
anthosbmctl1 Ready control-plane,master 2d14h v1.24.5-gke.400
anthosbmusr1 Ready worker 2d14h v1.24.5-gke.400
anthosbmusr2 Ready worker 22m v1.24.5-gke.400
anthosbmusr3 Ready worker 21m v1.24.5-gke.400
めでたくworkerが増えました。かわいいね。
いろいろ遊んでみる
その前にちょっと課金が怖くなってきた
このかわいいクラスタも、Google Cloud Consoleから見ると結構立派なクラスタに見えてしまいます。

32vCPU。Admin clusterと合わせて36vCPU。Hyper Threadingをオンにしてるからなんですけど。AnthosはvCPU課金なのでちょっとこわい。というわけでPricing Calculatorで計算してみます。
こうか?
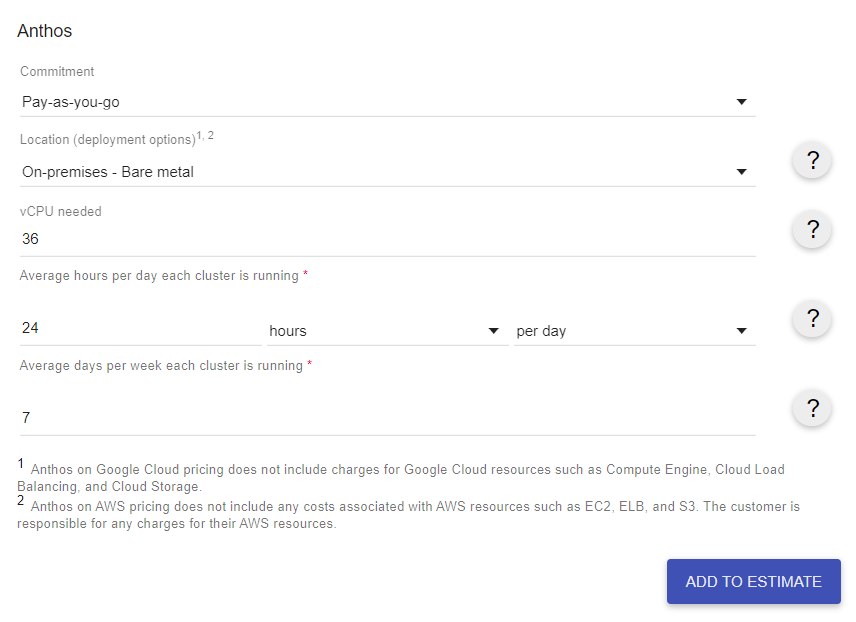
さて
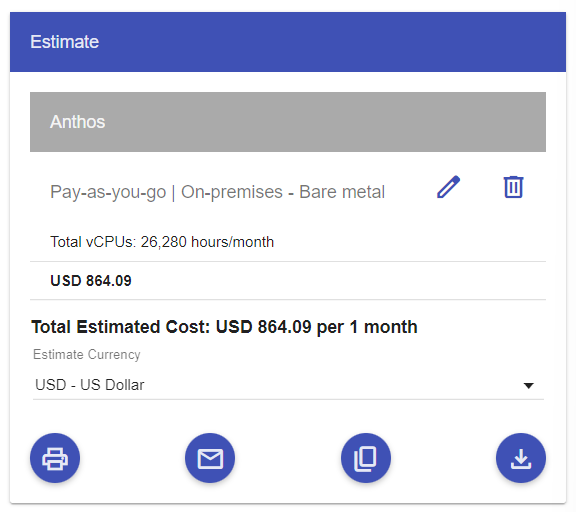
うぎゃー800USD超える。お試し枠に収まらんw
追記:そもそもお試し枠の対象ではありませんでしたw
とはいえGKEで同じぐらいのサイズのクラスタ作ろうとすると
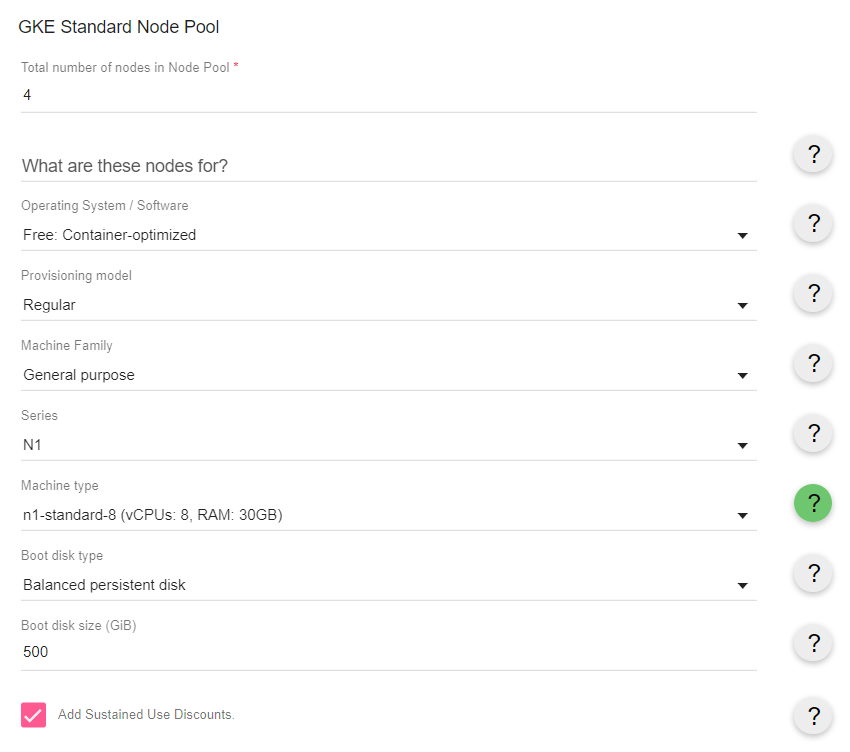
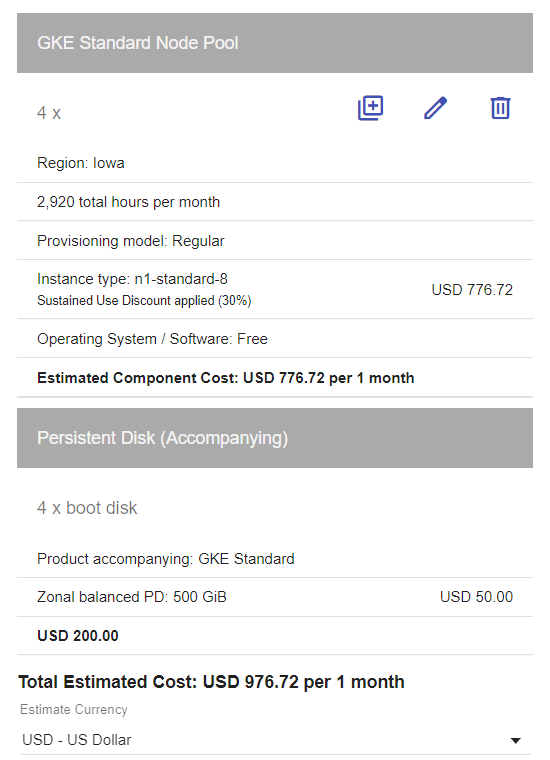
やっぱもっと高い。ストレージがでかくなるともっと差がつくし、まあAnthosもリーズナブルではあるのかも。エンタープライズ向けとしては。
追記:フリート登録を解除すれば課金は止まります。その場合もクラスタは動き続けます。
ストレージをどうするか
Anthos clusters on bare metalで最初から用意されているStorage Classは以下の3つです。
anthosadmin@ubuntuvm:~$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
anthos-system kubernetes.io/no-provisioner Delete WaitForFirstConsumer false 4d13h
local-disks kubernetes.io/no-provisioner Delete WaitForFirstConsumer false 4d13h
local-shared kubernetes.io/no-provisioner Delete WaitForFirstConsumer false 4d13h
要するに各ノードのファイルシステムを使うだけです。
ステートレスなコンテナを動かすだけならよいのですが、今回試したいワークロードはどちらかというと仮想マシンであり、 仮想マシンとは宿命的にステートフルです。なんならステートそのものです。
というわけで仮想マシンディスク用に別途ストレージを用意したくなります。
Synology CSI Driver
逸般の誤家庭でしたら、4TBのHDDを4本積んだSynologyのNASの1台や2台、そこらへんに転がっているはずです。 弊宅もそうです。で、SynologyはCSI Driverを提供しているので、これをシュッと入れればDynamic provisionができるStorageClassが手に入ります。家でKubernetes検証してて手っ取り早くStorageClass使いたいときはこれ使ってます。スナップショットもできるよ。便利。
で今回も入れて普通に使えたのですが、これだとiSCSIのRWO(ReadWriteOnce)なんですよね。KubeVirt/Anthos VM Runtimeのライブマイグレーション機能やHA機能を利用するには、RWX(ReadWriteMany)なストレージが必要になります。Synology NASのNFSを使うという手もあるのですが、わしはNFSに村を焼かれたのじゃ。
Rookと書いてるっくと読む
というわけでUser clusterにRookを入れて、CephFSをRWXで使おうと思います。
ただRook-ceph使おうとすると、Cephクラスタの冗長性は確保したくなるのが人のSAGA。というかこの実験の最大のお楽しみは Workerノード1台即死させても果たして仮想マシンは動き続けるのか? なので、ストレージが死んでは元も子もないわけです。この時点でWorkerノードは3台構成なので、Cephのmonやmgrの冗長性は問題ないのですが、
| ノード | ブートディスク | 未使用ディスク |
|---|---|---|
| anthosbmusr1 (EL300) | sda (236G) | sdb (472G) |
| anthosbmusr2 (SER5) | nvme0n1 (465G) | なし |
| anthosbmusr2 (SER5) | nvme0n1 (465G) | なし |
という状態なので、OSD用のディスクが足りません。ブートディスクはLVMにしてるので、LV切り出して使うということも(satさんのおかげで)可能ではあるのですが、やっぱ物理ディスク分けたいじゃないですか。どうしようかな。
などと考えていたら こんなのが生えてきたよ。
増設増設ぅ♪

この筐体よくできてんな。
本題ではないので(もはや本題とは)Rookのセットアップ手順は割愛します。RTFM。
というわけで
| ノード | ブートディスク | Rook-Ceph OSD |
|---|---|---|
| anthosbmusr1 (EL300) | sda (236G) | sdb (472G) |
| anthosbmusr2 (SER5) | nvme0n1 (465G) | sda (954G) |
| anthosbmusr2 (SER5) | nvme0n1 (465G) | sda (954G) |
という構成でめでたくCephクラスタができあがり、
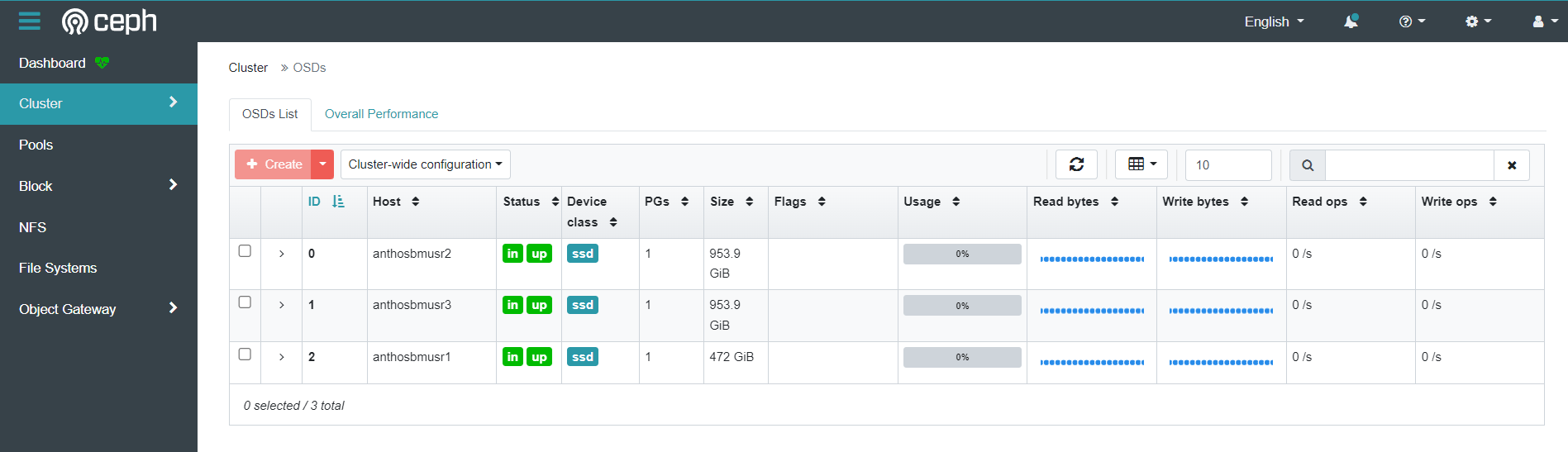
CephFSもできました。
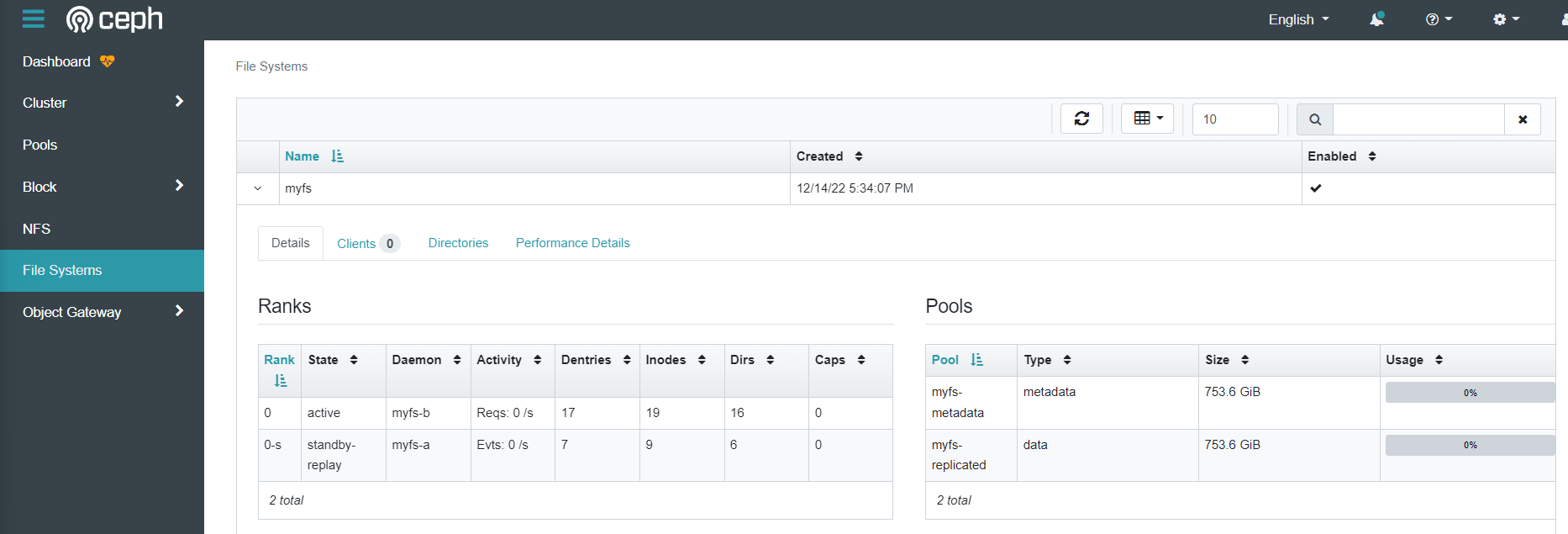
StorageClassも用意したので、RWXなボリュームがプロビジョニングできるようになったわけです。
仮想マシンのHA/ライブマイグレーションを試したい
HAポリシーの確認
デフォルトで、VMHighAvailabilityPolicyはRescheduleになっています。
anthosadmin@ubuntuvm:~$ kubectl get VMHighAvailabilityPolicy --namespace vm-system
NAME AGE RECOVERY STRATEGY NODE HEARTBEAT INTERVAL NODE MONITOR GRACE PERIOD
default 91s Reschedule 15s 1m30s
つまり、通常のコンテナのPodと同様、ノード障害が発生したりVM Podが異常終了した場合は、生きているノードでVMを再スケジュールするということです。
eviction policyの設定
これはまだPreviewですが、ノードをメンテナンスモードにした際にそのノードで稼働しているVMを他のノードにライブマイグレートするように設定できます。
kubectl edit vmruntime
で
spec:
evictionPolicy:
evictionStrategy: LiveMigrate
maxMigrationAttemptsPerVM: 3
migrationTargetInitializationTimeout: 30s
と設定しておきます。
というわけでちゃんとHA/ライブマイグレーション対応なVMを作る
前述のkubectl virt create vmコマンドではイメージを指定しただけであとはお任せだったわけですが、ストレージやネットワークをちゃんと指定して作る場合の手順はこちらになります。
StorageClassを作成する
rook-cephfsというSCを作ってあるのでそれを使います。
anthosadmin@ubuntuvm:~$ kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
anthos-system kubernetes.io/no-provisioner Delete WaitForFirstConsumer false 47h
local-disks kubernetes.io/no-provisioner Delete WaitForFirstConsumer false 47h
local-shared kubernetes.io/no-provisioner Delete WaitForFirstConsumer false 47h
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 10h
rook-cephfs rook-ceph.cephfs.csi.ceph.com Delete Immediate true 10h
StorageProfileの設定
StorageClassからボリュームを取ってくる際のAccess Mode (RWO/RWXなど) は普通はPersistentVolumeClaim(pvc)オブジェクトで指定するのですが、KubeVirtの場合はPVCはVirtualMachineDiskというCRDから間接的に作られます。で、VirtualMachineDiskというオブジェクトにもAccessModeというSpecはありません。ではどこで指定するかというと、StorageProfile というCRDで指定します。StorageProfileは各StorageClassに対応するものをKubeVirtが生成していて、
kubectl get storageprofile
と叩くと
NAME AGE
anthos-system 4d17h
local-disks 4d17h
local-shared 4d17h
rook-ceph-block 4d17h
rook-cephfs 4d17h
と出てくるので、vmdiskとして使用するStorageClassについて
kubectl edit storageprofile rook-cephfs
で以下specを追加します。
spec:
claimPropertySets:
- accessModes:
- ReadWriteMany
仮想ネットワークを作成する
VMに外部からアクセスできるように、ホストのNICにmacvtapデバイスを乗せて仮想マシンに外部IPアドレスを振るようにします。
INTERFACE_NAME: ネットワークを接続する Anthos clusters on bare metal ノードのインターフェース名。すべてのノードに同じインターフェース名を設定する必要があります。
えっ
EL300とSER5はハードウェア構成が当然違うので、使っているNICも
| ノード | NIC |
|---|---|
| anthosbmusr1 (EL300) | enp3s0 |
| anthosbmusr2 (SER5) | enp1s0 |
| anthosbmusr2 (SER5) | enp1s0 |
と異なります。ここはnetplanでNIC名変えちゃいます。うりゃ。
network:
ethernets:
enp3s0:
match:
macaddress: xx:xx:xx:xx:xx:xx
set-name: lan0
みたいな。
んで
apiVersion: networking.gke.io/v1
kind: Network
metadata: # ドキュメントでこの行抜けてました
name: manual-network
spec:
type: L2
nodeInterfaceMatcher:
interfaceName: lan0
gateway4: 192.168.0.1
dnsConfig:
nameservers:
- 1.1.1.1
というネットワークを作ります。
IPアドレスはDHCPからもらってもよいので最初はそれを試したのですが、IPアドレスはDHCPから振られたものが設定されるものの、DNSサーバーのアドレスがなぜか反映されませんでした。これは弊宅のルーター(DHCPサーバー)の問題かもしれないのですが、IPアドレスは個別に設定することにします。
VM ブートディスクを作成する
こんな感じでUbuntu20.04のブートディスクを作ります。
apiVersion: vm.cluster.gke.io/v1
kind: VirtualMachineDisk
metadata:
name: my-ubuntu20vm-disk
spec:
size: 20Gi
storageClassName: rook-cephfs
source:
http:
url: http://192.168.0.155/ubuntu-20.04-server-cloudimg-amd64.img
今回はあらかじめダウンロードしておいたイメージファイルをローカルのnginxでホストしたので、すぐに作成されました。
VMを作成する
こうか
apiVersion: vm.cluster.gke.io/v1
kind: VirtualMachine
metadata:
name: my-ubuntu20vm
spec:
osType: Linux
compute:
cpu:
vcpus: 2
memory:
capacity: 4Gi
interfaces:
- name: eth0
networkName: manual-network # 作ったnetwork
default: true
ipAddresses:
- 192.168.0.10/24 # 仮想マシンのIPアドレス。ここCIDR形式でないとだめなので注意(ドキュメントは間違い)
disks:
- boot: true
virtualMachineDiskName: my-ubuntu20vm-disk # 作ったディスク
でapplyしたらwatch kubectl get gvmとでもしてコーヒーでも飲みましょう。
anthosadmin@ubuntuvm:~$ kubectl get gvm
NAME STATUS AGE IP
my-ubuntu20vm Running 9h 192.168.0.10/24
できた。
KubeVirtでは仮想マシンは実際にはKubernetes上のいろいろなリソースで構成されています。
pod
anthosadmin@ubuntuvm:~$ kubectl get pod
NAME READY STATUS RESTARTS AGE
virt-launcher-my-ubuntu20vm-tvlrx 3/3 Running 0 7h57m
pvc
anthosadmin@ubuntuvm:~$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
my-ubuntu20vm-disk Bound pvc-2e7cf436-d02d-4519-9aca-ec939e675f85 22Gi RWO rook-cephfs 9h
datavolume
anthosadmin@ubuntuvm:~$ kubectl get datavolumes
NAME PHASE PROGRESS RESTARTS AGE
my-ubuntu20vm-disk Succeeded 100.0% 9h
などなど。
上がってきたVMには kubectl virt ssh VM名 というコマンドでSSH接続できるのですが、このコマンドを叩くたびに一時的な鍵ペアが生成されて、authorized_keysに公開鍵がインジェクトされているようです。
anthosadmin@my-ubuntu20vm:~$ cat .ssh/authorized_keys
# Added by Google
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAAAgQDHicEgm0absFmBm1AYe7mB71u0feQ0UZpuNXORh5VrRAr2+oR1bjNPTufH0rYL82SQCFH5tJ6fZ4Fiad2QbfnIQhAMd+JbYCFjzEpwwfrEQsXQQF9HarTopAntp/fo44/R+AGMMlcSE7ezUdrxEVuFs46htCXSO0J8MPrLBfErUw== google-ssh {"userName":"anthosadmin@ubuntuvm","expireOn":"2022-12-15T06:24:28Z"}
authorized_keysに作業端末の公開鍵を追記してあげれば、ふつうに直接SSH接続できるようになります。
ライブマイグレーションを試すよ
仮想マシンインスタンスがどのノードで動いているかはkubectl get virtualmachininstance で見れます。CRDがたくさんあってややこしいですね。
anthosadmin@ubuntuvm:~/a4vm-lab$ kubectl get virtualmachineinstance
NAME AGE PHASE IP NODENAME READY
my-ubuntu20vm 3h51m Running 192.168.0.10 anthosbmusr1 True
ライブマイグレーションを発動させる方法としては、以下の2通りあります。
- User clusterで
kubectl virt migrate <VM名> - Admin clusterから、User clusterの該当ノードをメンテナンスモードにする
やってみたのですが、私の環境ではいまのところうまく動いてくれていません。
KubeVirtでライブマイグレーションを行うのにはいろいろと前提条件があり、ハマりつつわかったことは
- VirtualMachineDiskがClaimするStorageClassはRWXをサポートしたものでなくてはならない(今回はRook-CephFSを使っているのでクリア)
- VolumeSnapshotClassを作っておかなければならない(作ったのでクリア)
- 仮想マシンネットワークはpod networkはダメ(L2 macvtapネットワークなのでたぶん大丈夫。かもしれない。あやしいかもしれない)
- CPUアーキテクチャが同じノード間でないとダメ
- KubeVirtがホストの
/proc/cpuinfoのflags相当の情報を拾ってきてことごとくnodeのlabelとして設定していて、これが厳密に一致するノード間でないとMigrationは許さないようです。 - 今回はノード1がIntel Corei5, ノード2,3がAMD Ryzen5なので、ノード2⇔ノード3間でしかライブマイグレーションは動作しません。
- そのためCPUアーキテクチャ別にノードにラベルを振って、VMのSpecに
nodeSelectorを設定してノード2もしくは3にVMがデプロイされるようにしました。のでクリア。
- KubeVirtがホストの
ここまでやってもなお、virt-launcher (migration発動時に移行先ノードでインスタンスを起動するためのもろもろを実行するPod)で
"Connecting to libvirt daemon failed: virError(Code=38, Domain=7, Message='Failed to connect socket to '/var/run/libvirt/virtqemud-sock': No such file or directory')"
というエラーが出てmigrationが完了しません。しかもこのとき
anthosadmin@ubuntuvm:~$ kubectl get virtualmachineinstancemigrations.kubevirt.io
NAME PHASE VMI
kubevirt-evacuation-7pzvq Failed my-ubuntu20vm
というオブジェクトがFailedのまま残ってしまうので、ライブマイグレーションを諦めることもせず、ノードがメンテナンスモードに入りません。しかもmaxMigrationAttemptsPerVM: 3 ってしてるのに、上記オブジェクトを消すと無限に再生成して永遠に諦めない。なんだこれ。
virt-launcherで出ているエラーはqemudが息してないの系ですが、CephFSがあやしいようなネットワークがあやしいような、どこかで設定が漏れているのかもしれません。なんせKubeVirtはCRDがたくさんあって依存関係が複雑なので、トラシューはたいへん。
Anthos VM RuntimeてきにはLive MigrationはPreviewなので、動けばラッキーぐらいの感じではあるのですが、Google Cloudさんにログ送って調べていただいてます。(仕事に家庭を持ち込んでないかおれ)
ライブマイグレーションはいったん諦めてHAを試すよ
これは単純に、VMが動いているノードを落とす(sudo shutdown 0 とか、LANケーブル抜くとか、電源ケーブルぶち抜くとか)と、
こうなって
Every 2.0s: kubectl get pod ubuntuvm: Tue Dec 20 07:12:35 2022
NAME READY STATUS RESTARTS AGE
virt-launcher-my-ubuntu20vm-jgjp2 3/3 Running 0 43h
──────────────────────────
Every 2.0s: kubectl get vmi ubuntuvm: Tue Dec 20 07:12:35 2022
NAME AGE PHASE IP NODENAME READY
my-ubuntu20vm 43h Running 192.168.0.10 anthosbmusr3 False
──────────────────────────
Every 2.0s: kubectl get node ubuntuvm: Tue Dec 20 07:12:34 2022
NAME STATUS ROLES AGE VERSION
anthosbmctl1 Ready control-plane,master 7d11h v1.24.5-gke.400
anthosbmusr1 Ready worker 7d11h v1.24.5-gke.400
anthosbmusr2 Ready worker 7d11h v1.24.5-gke.400
anthosbmusr3 NotReady worker 7d11h v1.24.5-gke.400
こうなって
Every 2.0s: kubectl get pod ubuntuvm: Tue Dec 20 07:14:07 2022
NAME READY STATUS RESTARTS AGE
virt-launcher-my-ubuntu20vm-cvn4j 0/3 Init:0/2 0 45s
──────────────────────────
Every 2.0s: kubectl get vmi ubuntuvm: Tue Dec 20 07:14:07 2022
NAME AGE PHASE IP NODENAME READY
my-ubuntu20vm 45s Scheduling False
──────────────────────────
Every 2.0s: kubectl get node ubuntuvm: Tue Dec 20 07:14:09 2022
NAME STATUS ROLES AGE VERSION
anthosbmctl1 Ready control-plane,master 7d11h v1.24.5-gke.400
anthosbmusr1 Ready worker 7d11h v1.24.5-gke.400
anthosbmusr2 Ready worker 7d11h v1.24.5-gke.400
anthosbmusr3 NotReady worker 7d11h v1.24.5-gke.400
こうなります。
Every 2.0s: kubectl get pod ubuntuvm: Tue Dec 20 07:15:09 2022
NAME READY STATUS RESTARTS AGE
virt-launcher-my-ubuntu20vm-cvn4j 3/3 Running 0 107s
──────────────────────────
Every 2.0s: kubectl get vmi ubuntuvm: Tue Dec 20 07:15:09 2022
NAME AGE PHASE IP NODENAME READY
my-ubuntu20vm 107s Running 192.168.0.10 anthosbmusr2 True
──────────────────────────
Every 2.0s: kubectl get node ubuntuvm: Tue Dec 20 07:15:11 2022
NAME STATUS ROLES AGE VERSION
anthosbmctl1 Ready control-plane,master 7d11h v1.24.5-gke.400
anthosbmusr1 Ready worker 7d11h v1.24.5-gke.400
anthosbmusr2 Ready worker 7d11h v1.24.5-gke.400
anthosbmusr3 NotReady worker 7d11h v1.24.5-gke.400
ダウンタイムは2~3分ぐらいでした。
あ、私慣れてないのであんま見てなかったですけど、Google Cloud Loggingで仮想マシンのログも普通に見れますよ。
きりがないのでまとめる
- おうちKubernetesは良いぞ
- おうちKubeVirtは良いぞ
- とはいえCRDがモリモリあって複雑なので、ある程度慣れが必要だぞ
- LiveMigrationは難易度高そうだぞ
- おうちAnthosは良いぞ
- 普通のPC並べれば普通に動くぞ
- でもお値段的に個人ユースには厳しいぞ
今後試したいこと(試用クレジットを使い果たす前に・・・)
- 自宅AnthosクラスタとGKEまたがったGitOps (Anthos Config Management)
- 自宅AnthosクラスタとGKEまたがったサービスメッシュ (Anthos Service Mesh)
じゃっ、メリークリスマス
えっ、浜辺美波さんとはなんだったのか? あなたは浜辺美波さんも知らないのですか。ぐぐってください。分からないことがあったら人に聞く前に自分で調べる癖をつけましょう。
明日はちゃんとしたうっちーさんのちゃんとした記事です!お楽しみに!