1.初めに
過去のM-1グランプリの得点を各年で標準化し、その値を比較する。
歴代M-1グランプリ結果からスクレイピングしてデータを取得する。
2.準備
スクレイプのためBeautifulSoupとrequestsを使う
import pandas as pd
from bs4 import BeautifulSoup
import requests
url = "https://www.m-1gp.com/history"
res = requests.get(url)
soup = BeautifulSoup(res.text,'html.parser')
開催年を作成する。(2020年から2000年までの2011から2014年までを除いたもの。)
year_list = []
for year in range(2020,2000,-1):
if year in [2011,2012,2013,2014]:
continue
year_list.append(str(year))
3.実行
dfsに2000〜2020年までの結果が入る。
dfs = pd.DataFrame([])
for i in range(16):
score_list = []
for j in soup.find_all("div", class_='result')[i].find_all("td"):
score_list.append(j.get_text())
scores = [score_list[i:i+2] for i in range(0,len(score_list),2)]
df = pd.DataFrame(scores)
#indexを開催年とする
df.index = [year_list[i]] * len(df)
#得点をint型に
df[1] = df[1].map(lambda x: x.replace('点','')).astype(int)
#標準化
df[2] = (df[1]-df[1].mean()) / df[1].std()
dfs = pd.concat([dfs,df])
dfs
実行結果は以下
1列目は得点、2列目が各年で得点を標準化したものとなっている。
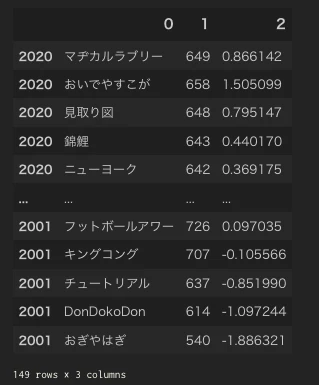
この標準化された得点で降順にソートしてみると
# 降順にソート
dfs_s = dfs.sort_values([2], ascending=False)
pd.set_option('display.max_rows', 200)
dfs_s
実行結果
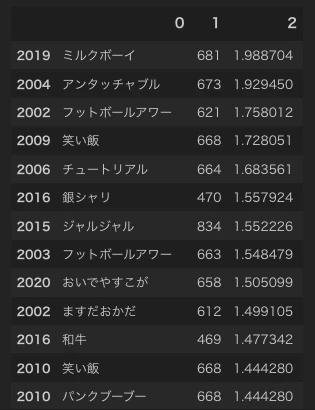
----------------------(省略)----------------------

母集団や採点方法などが違うので一概に比較できないが、ミルクボーイ、次点でアンタッチャブルが抜けていることが分かる。
また、2001年の芸人が上位に来ないのは、審査員が付ける点に差があり得点差が大きく開き、分散、標準偏差が大きくなったことが原因だと思われる。