概要
プロ野球も今シーズンは残り30試合ほどとなり、現時点でのデータを用いて新人王が誰になるのかをLightGBMにて予測してみようと思いました。(9/10時点でのデータ)
個人的には、球団新人最多本塁打記録を塗り替えた阪神の佐藤輝明選手に獲って欲しいと思っています。(希望的観測)
LightGBMとは
近年編み出された機械学習アルゴリズム。精度が高く、実行時間も短いらしい。
また、欠損値もそのまま扱え、特徴量のスケーリングも必要ない。
詳しくはこちら(公式ドキュメント)
https://lightgbm.readthedocs.io/en/latest/
流れ
2009年から2020年までの新人王有資格者の成績をLightGBMを用いて学習させ、2021年のデータから、新人王は誰になるのかを予測する。
歴代新人王
| 年度 | 2020年 | 2019年 | 2018年 | 2017年 | 2016年 | 2015年 | 2014年 | 2013年 | 2012年 | 2011年 | 2010年 | 2009年 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| セ・リーグ新人王 | 森下 暢仁(広島) | 村上 宗隆(ヤクルト) | 東 克樹(DeNA) | 京田 陽太(中日) | 高山 俊(阪神) | 山崎 康晃(DeNA) | 大瀬良 大地(広島) | 小川 泰弘(ヤクルト) | 野村 祐輔(広島) | 澤村 拓一(巨人) | 長野 久義(巨人) | 松本 哲也(巨人) |
| パ・リーグ新人王 | 平良 海馬(西武) | 高橋 礼(ソフトバンク) | 田中 和基(楽天) | 源田 壮亮(西武) | 高梨 裕稔(日本ハム) | 有原 航平(日本ハム) | 石川 歩(ロッテ) | 則本 昂大(楽天) | 益田 直也(ロッテ) | 牧田 和久(西武) | 榊原 諒(日本ハム) | 攝津 正(ソフトバンク) |
ライブラリのimport
import pandas as pd
import numpy as np
from tqdm.notebook import tqdm
import lightgbm as lgb
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split # データセット分割用
from sklearn.metrics import roc_auc_score # モデル評価用(auc)
データ入手
データは、プロ野球データFREAK様から拝借させていただきました。
以下の関数で2009年~2020年までの野手(Batter)と投手(Pitcher)の新人王有資格者のデータをスクレイプ。
def scrape_B(year_list):
batter_results = {}
for year in tqdm(year_list):
time.sleep(1)
url = "https://baseball-data.com/" + year + "/stats/hitter-all/tpa-7.html"
df = pd.read_html(url)
df = df[0].droplevel(1, axis=1)
batter_results[year] = df
batter_results[year].index = [year] * len(batter_results[year])
return batter_results
def scrape_P(year_list):
pitcher_results = {}
for year in tqdm(year_list):
time.sleep(1)
url = "https://baseball-data.com/" + year + "/stats/pitcher-all/ip3-7.html"
df = pd.read_html(url)
df = df[0].droplevel(1, axis=1)
pitcher_results[year] = df
pitcher_results[year].index = [year] * len(pitcher_results[year])
return pitcher_results
09年から20年までのリストを作成。
year_list = []
for y in range(9, 21, 1):
year = str(y).zfill(2)
year_list.append(year)
スクレイプ関数を実行した後、野手データ、投手データをデータフレーム型に直し、2つを結合する。(2つのcolumnsが違うため欠損値NaNが出てきてしまうが、とりあえずやってみる。)
batter_09_20 = scrape_B(year_list)
pitcher_09_20 = scrape_P(year_list)
batter_09_20 = pd.concat([batter_09_20[key] for key in batter_09_20], sort=False)
pitcher_09_20 = pd.concat([pitcher_09_20[key] for key in pitcher_09_20], sort=False)
# 野手と投手を結合
results_09_20 = pd.concat([batter_09_20, pitcher_09_20])
前処理等
この時、以下のように試合が'-'となっている行があるが、これは1試合も出ていないということなので、これらの行を省く。
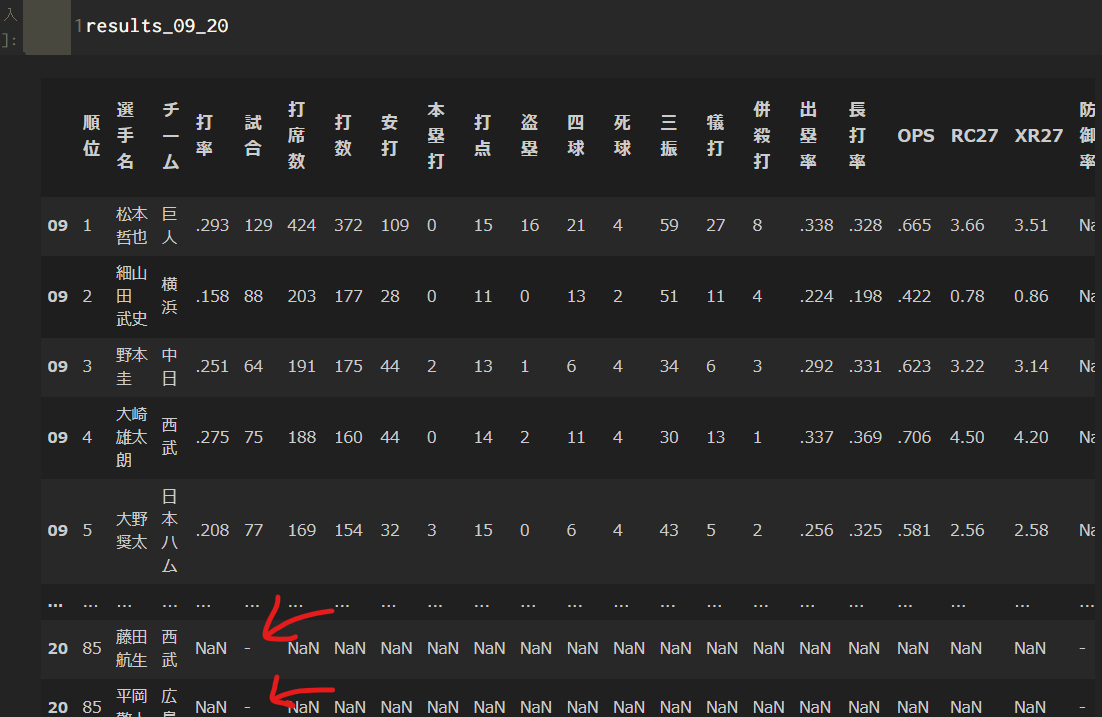
results_09_20 = results_09_20[results_09_20['試合'] != '-']
新たにKINGという列を加え、新人王を獲っているなら1、そうでないなら0とする。コレが目的変数になる。
results_09_20['KING'] = 0
としてKING列を0で初期化して、あとはこれをcsvファイルにして外部操作で歴代新人王での値を1とした。(他にいい方法があるはず)
予測に使わない列「順位」「選手名」「チーム」を削除する。
# preprocessing(前処理)
results_09_20_p = results_09_20.drop(['順位', '選手名', 'チーム'], axis=1)
results_09_20_p
to_numeric関数を用いて、各列を数値型に変換する。
columns = results_09_20_p.columns.tolist()
for column in columns:
results_09_20_p[column] = pd.to_numeric(results_09_20_p[column], errors = 'coerce')
ここまでで、筆者環境で 1675 rows × 36 columns のresults_09_20_pが出来た。
データの分割
説明変数と目的変数に分ける。
# 説明変数
X = results_09_20_p.drop(['KING'], axis=1).values
# 目的変数
y = results_09_20_p['KING'].values
train_test_split関数を使ってデータを分割する。
ここでは訓練データ7割、テストデータ3割となるようにした。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
LightGBMで学習
いよいよ学習。パラメータは以下のように簡単にした。
(ここはOptunaを用いてパラメータを調節する手もあるが省略。)
# LightGBM parameters
params = {
'objective': 'binary', # 目的 : 二値分類
'metric': 'auc', #AUCの最大化を目指す
}
# モデルの学習
model = lgb.LGBMClassifier(**params)
model.fit(X_train, y_train)
モデルの評価
予測値と予測確率
y_pred = model.predict(X_test)
y_pred_prob = model.predict_proba(X_test)
正答率計算
# 正答率
acc = accuracy_score(y_test, y_pred)
acc
0.9860834990059643
AUC計算
# AUC
auc = roc_auc_score(y_test,y_pred_prob[:,1])
auc
0.989558232931727
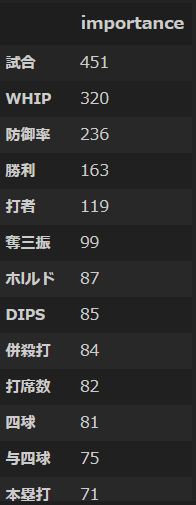
各特徴量の重要度をプロット
各特徴量は以下のようになる。
model.feature_importances_
array([ 34, 451, 82, 51, 47, 71, 10, 47, 81, 0, 2, 8, 84,
12, 33, 62, 8, 10, 236, 163, 19, 40, 87, 44, 119, 34,
54, 12, 75, 47, 99, 48, 50, 320, 85])
これをグラフで可視化してみる。
importance = model.feature_importances_.tolist()
# columnsから'KING'を削除
del columns[-1]
# Dataframe化
imp = pd.DataFrame(model.feature_importances_, index=columns, columns={'importance'})
# 降順にソート
imp_s = imp.sort_values('importance', ascending=False)
imp_s
以下のようなデータフレームが得られる。
これのindexを縦軸、importanceを横軸とし横棒グラフにする。
plt.figure(figsize=(10,10))
plt.barh(imp_s.index.tolist(),imp_s['importance'].tolist())
plt.show()
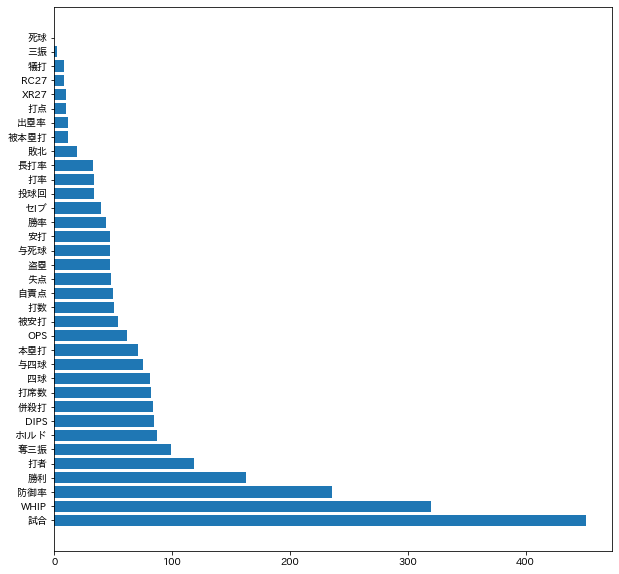
重要度としては、出場試合数が最も高く、次点でWHIP,防御率,勝利数,対戦打者数,奪三振などの投手用の特徴量が続いている。
2021年新人王の予測
本題の新人王予想に入る。
まず2021年のデータを取ってくる。
batter_21 = pd.read_html('https://baseball-data.com//stats/hitter-all/tpa-7.html')
batter_21 = batter_21[0].droplevel(1, axis=1)
pitcher_21 = pd.read_html('https://baseball-data.com//stats/pitcher-all/ip3-7.html')
pitcher_21 = pitcher_21[0].droplevel(1, axis=1)
# 打者データと投手データ結合
results_21 = pd.concat([batter_21, pitcher_21])
続いて前処理
# 試合が - の行は省く
results_21 = results_21[results_21['試合'] != '-']
# 使わない列を落とす
results_21_p = results_21.drop(['順位', '選手名', 'チーム'], axis=1)
for column in columns: #columnsは'打率'から'DIPS'まで35個
results_21_p[column] = pd.to_numeric(results_21_p[column], errors = 'coerce')
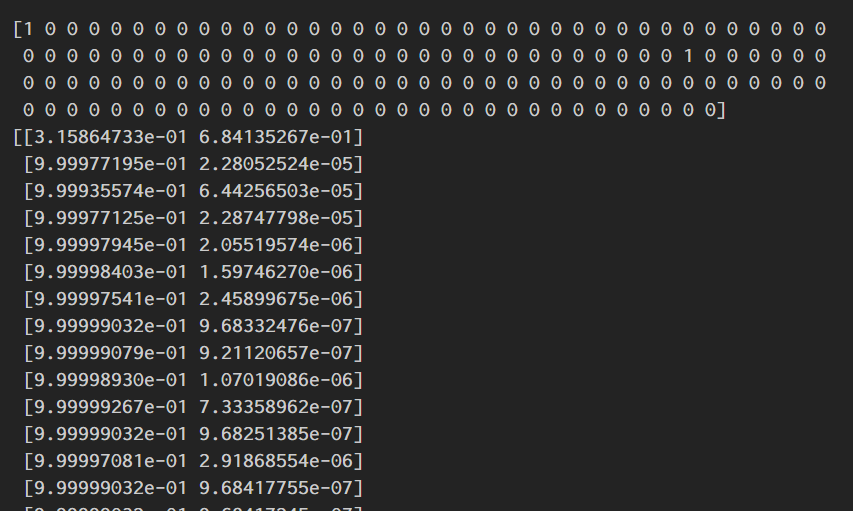
最後に予測値predと予測確率pred_probを表示
pred = model.predict(results_21_p)
pred_prob = model.predict_proba(results_21_p)
print(pred)
print(pred_prob)
predは、1だったら予測確率50%以上で新人王になるということである。
pred_probは[0と予想する確率,1と予測する確率]を表している。
パッと見たところ、0番目の選手が68.4%という確率で新人王になると予測されている。
何番目の選手が新人王と予測されたかを見てみる
[i for i, x in enumerate(pred.tolist()) if x == 1]
[0, 67]
0番目と67番目の選手を見てみると前者は佐藤輝明選手(阪神)、後者は宮城大弥投手(オリックス)であった。
results_21[0:1]
佐藤選手の成績
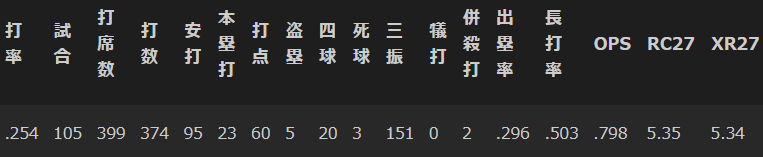
results_21[67:68]
宮城投手の成績
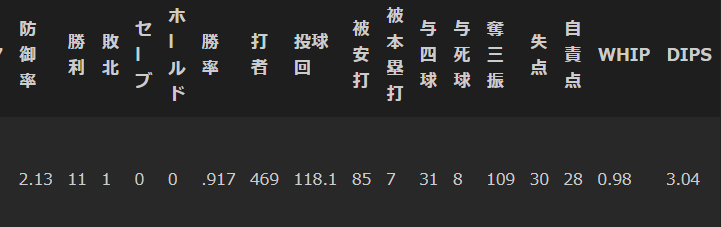
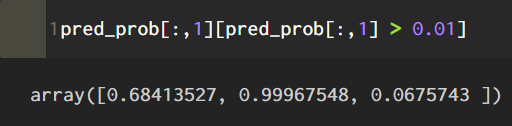
さらにpred_prob(新人王と予測する確率)を見ると、佐藤選手68.4%,栗林投手6.8%,宮城投手に至っては99.97%という数値を叩き出した。
(確率が1%以上になる所を取り出したもの。左から佐藤、宮城、栗林選手)
宮城投手の新人王は確定か
現時点でほぼ100%と言える確率を叩き出した宮城投手は、大崩れしない限りは新人王を手にすると思われる。
一方でセ・リーグだが、佐藤選手に引けを取らないDeNAの牧選手の新人王予測確率が1%未満というのに驚いた。
もしかしたらどこかでミスを犯しているのかもしれない。。。それともホームラン数の差によるものなのだろうか。
また、広島の栗林投手は防御率0.47、 23Sと素晴らしい成績を残しているが、予測確率が6.8%と低いのも気になった。
目的変数が1に比べ0が圧倒的に多いので、もしかしたらアンダーサンプリングを実施すれば、、みたいな話かもしれない。
次に向けて
シーズン終了時にフルシーズンのデータが揃った段階でまた予測したいと思う。
また、パラメータチューニングやアンダーサンプリングなども検討する。
野手と投手を混ぜて考えたが、別々でやるのもいいかもしれない。
セ・リーグ、パ・リーグで分けるということもやってみてもいいかも。
再度検証(10/15時点)
流石に佐藤輝明選手のn打席連続無安打などで成績が下がってきたので再び検証する。牧選手や栗林選手も素晴らしい活躍を見せているので。
また今回は、パラメータチューニングを取り入れてみようと思う。
train,test,validデータに分割
train_test_split関数を用いてまずtrain,testに分割。そしてtrainデータをtrain,validデータに分割する。
validデータはlightGBMに用いるパラメータを調節するために使う。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30)
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, test_size=0.30)
パラメータチューニング
Optunaを用いてパラメータを最適化する。
## OPUTUNA
import optuna.integration.lightgbm as lgb_o
lgb_train = lgb_o.Dataset(X_train, y_train)
lgb_valid = lgb_o.Dataset(X_valid, y_valid)
params = {
'objective': 'binary',
'random_state' : 100
}
lgb_clf_o = lgb_o.train(params, lgb_train,
valid_sets=(lgb_train, lgb_valid),
verbose_eval=100,
early_stopping_rounds=10)
チューニングされたパラメータがどの様になっているかを見てみる。
lgb_clf_o.params
{'objective': 'binary',
'random_state': 100,
'feature_pre_filter': False,
'lambda_l1': 1.1161403758595666e-08,
'lambda_l2': 8.829643669237959e-06,
'num_leaves': 31,
'feature_fraction': 0.44800000000000006,
'bagging_fraction': 0.7277588960898274,
'bagging_freq': 7,
'min_child_samples': 25,
'num_iterations': 1000,
'early_stopping_round': 10}
このパラメータを使ってモデルを作るのだが、最後2つの'num_iterations'と'early_stopping_round'を消してから使う。(謎にバグが起き、実行できなかったため。)つまり以下のようにパラメータを設定する。
# iterationとearly省く
params = {
'objective': 'binary',
'random_state': 100,
'feature_pre_filter': False,
'lambda_l1': 1.1161403758595666e-08,
'lambda_l2': 8.829643669237959e-06,
'num_leaves': 31,
'feature_fraction': 0.44800000000000006,
'bagging_fraction': 0.7277588960898274,
'bagging_freq': 7,
'min_child_samples': 25,
}
このパラメータで新たに学習する。
lgb_clf = lgb.LGBMClassifier(**params)
lgb_clf.fit(X_train, y_train)
新人王予測(10/15時点)
2021年新人王の予測と同じコードを実行して、以下のようになる。
今回、0番目,3番目,70番目が新人王と予測されており(予測確率が50%以上)、それぞれ牧、佐藤、宮城選手であった。
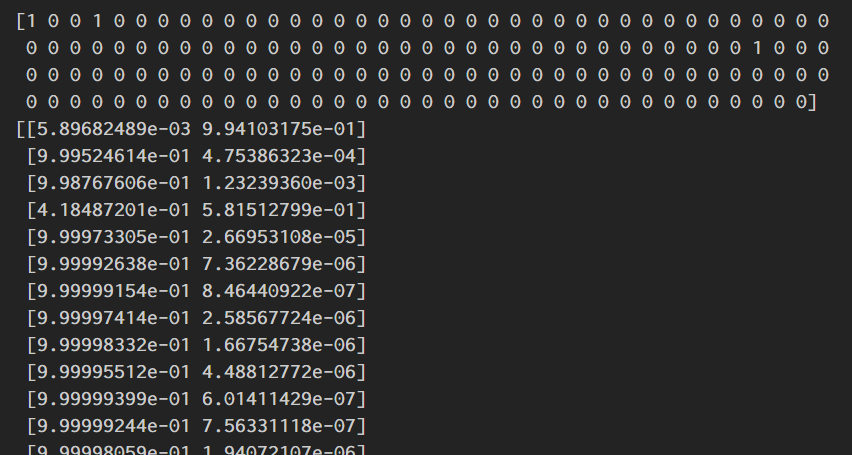
ここで予測確率が1%以上になるところを取り出してみる。
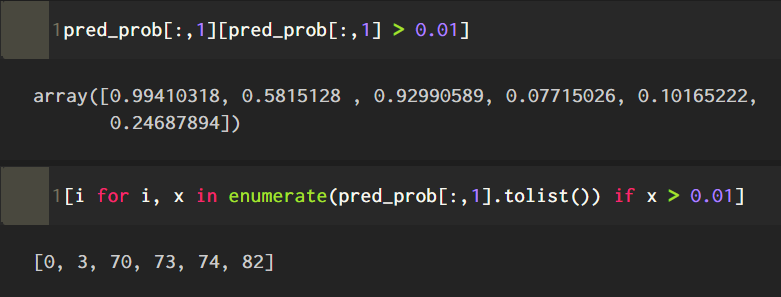
これは、
牧選手 99.4%
佐藤選手 58.1%
宮城選手 92.9%
伊藤将司選手 7.7%
奥川選手 10.1%
栗林選手 24.6%
という予測確率である。
選手は以下のコードで確認できる
results_21.iloc[[0,3,70, 73, 74, 82]]
それぞれの成績も貼っておく。
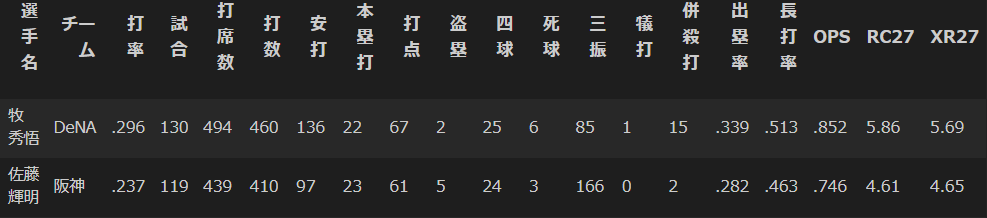
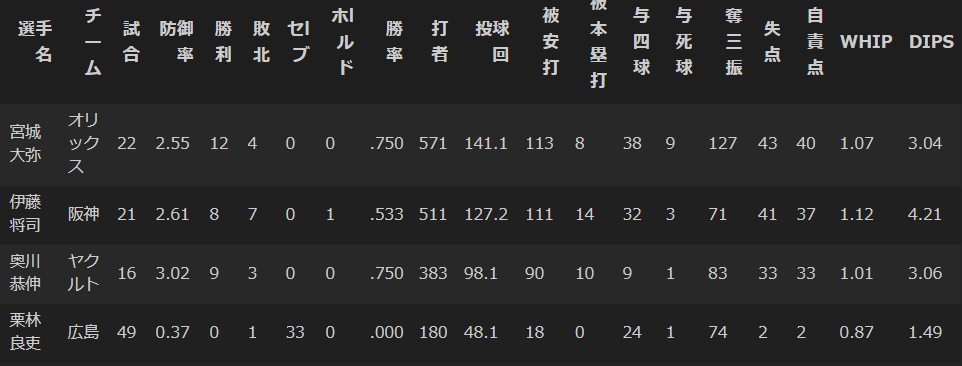
以上、
牧選手、そして宮城選手がほぼ新人王当確ということがわかりました。。。。
にしてもかなりレベルの高い争いです。。![]()