Crawlersの設定
RDSに接続できるようになったら、クローラーの設定を行う。
自分なりの解釈だが、GlueがETL処理を行うために、書き出し先の構造を取得する処理と考えている。
GlueのDatacatalog→Crawlers→Create crawlerボタンを押下する。(オレンジのやつ)

Step1
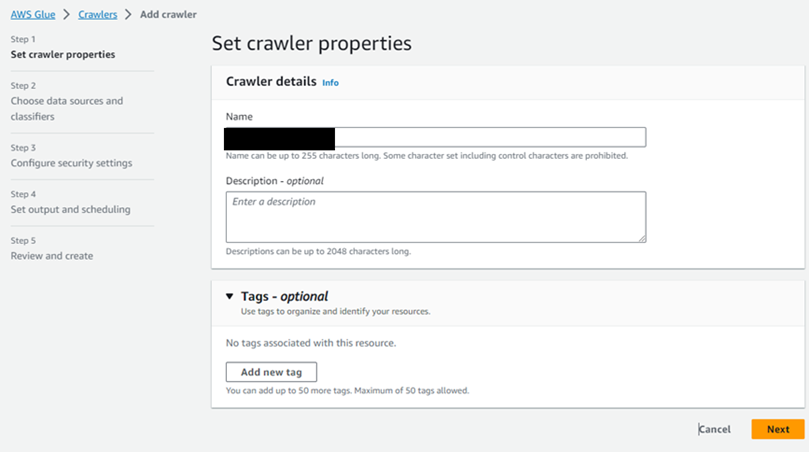
クローラーの名前と説明を書く画面。
好きな内容を入力。
Step2
これは初めて作るので、Not yetを選択。
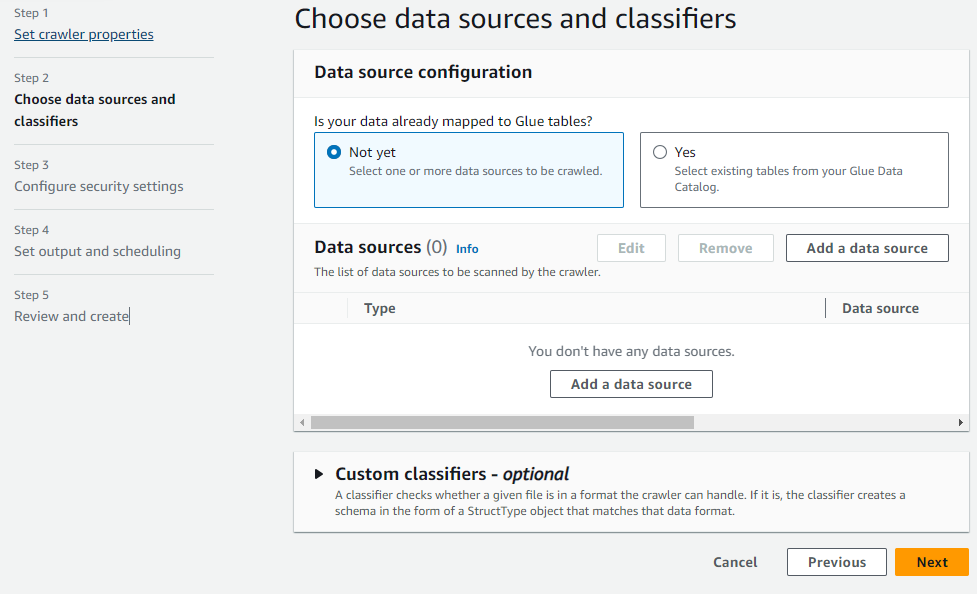
「Add a data source」ボタンを押下。
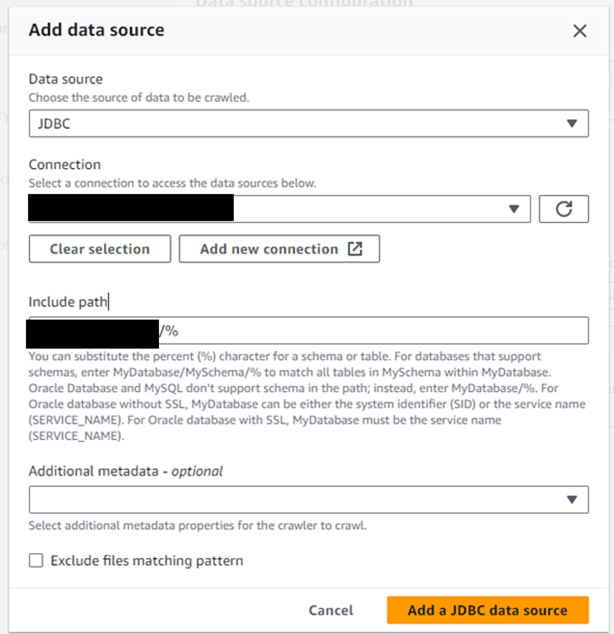
Data source:JDBS
Connection:接続対象のインスタンスを選択
Include path:MySQLの場合は「接続対象のDB名/%」を入力する
Step3
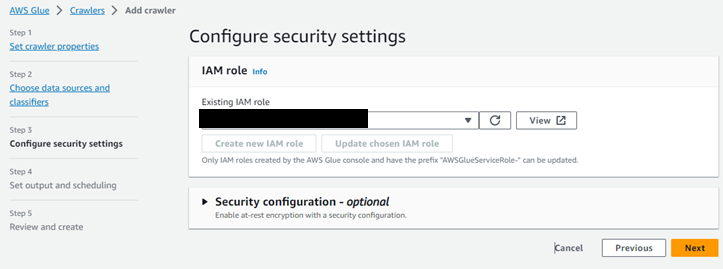
Glue用に作ったIAMロールを選択する。
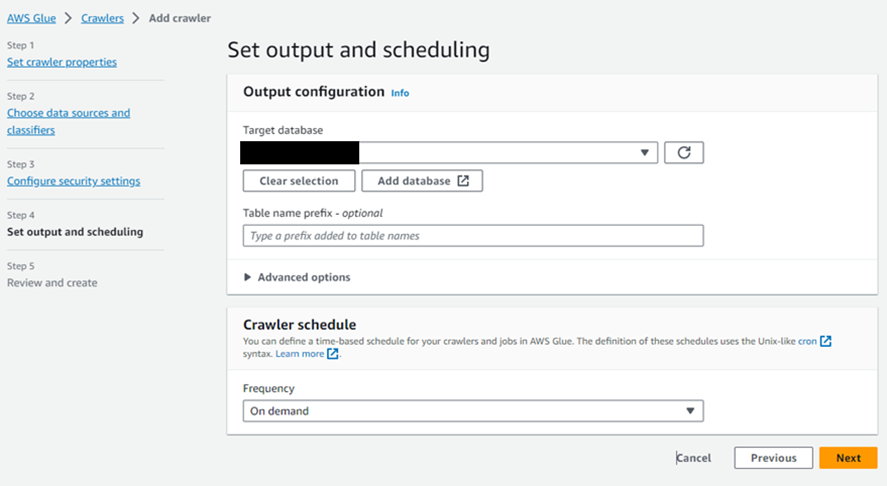
Step4
Target database:接続対象のデータベースを選択する
今回は自動更新しないので、スケジュールはOn demandにする。
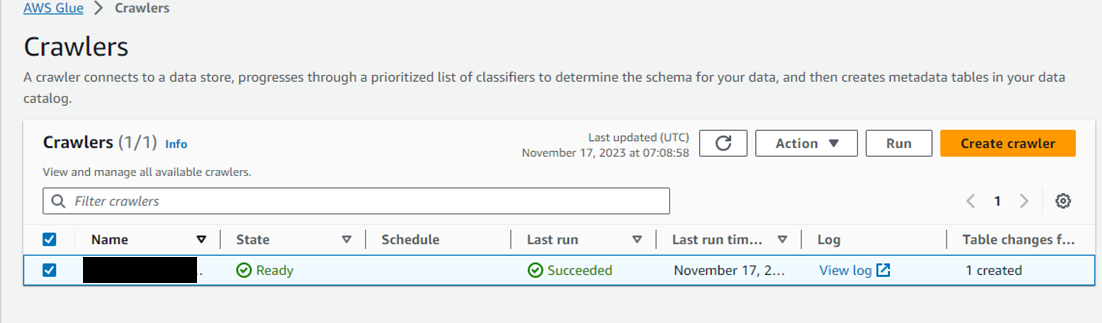
クローラーの実行
対象のクローラーを選択して、Runボタンを押下する。
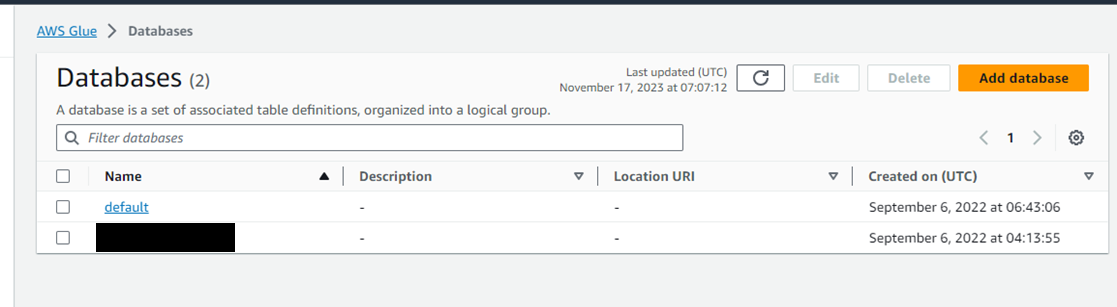
成功すると、Databasesに新たな行ができる。
Nameのリンクを押下すると、データベース内のテーブル一覧を見ることができる。
これでやっとETLの準備完了。
今まで用意したものを使ってジョブを作成する。