R3に保存したCSVをRDS(MySQL)へ取り込みたい
別サービスで発生したデータをRDSへ取り込みたい。
S3にCSV形式でファイルを置けることは確認したので、次にCSVをRDSへ取り込む方法を調べてみた。
できるだけ楽に。サーバーレスでノーコード。画面ポチポチで実現したい。
最初に考えた構成
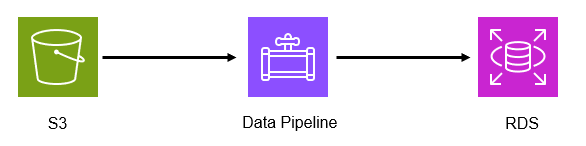
調べたところ、DataPipelineというサービスが費用的にも難易度的にもハードルが低そうだったので候補とした。
とりあえず、簡単なCSVを連携してみよう。

と思ったら、なんかメンテ中だのAPIかCLIならみたなことが書いてある。
ネットをさぐると、現在(2023年11月)DataPipelineはAPIかCLIからのみ使用可能らしい。
出鼻をくじかれた・・・
楽がしたいので、画面ポチポチして構築できるような他のサービスを模索。
AWSのドキュメントを見ていると、移行するならGlueってのがあるよと言った記載を確認。
他にあてがあるわけでもないので、こいつに賭けてみよう。
新構成
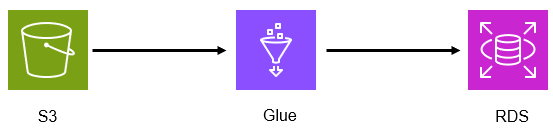
DatapipelineをGlueにかえただけ。
経験無しな上に、理解力が極めて低い私が手探りでサービスを使用してみる。
準備1 S3
これは特に、特別な設定は不要。
パブリックアクセスをさせるつもりはないので、デフォルト設定でバケットを作ればOK。
面倒なので画像も無し。
準備2 Glue用のIAMロール
Glueが、S3やRDSを使用するためのIAMロールが必要らしい。
ドキュメントに従って用意してみる。
AWSドキュメント IAMロール
ユースケースにGlueを選択。
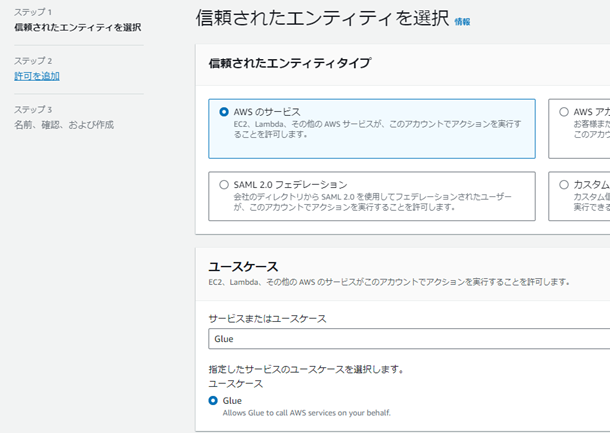
アクセス権限の付与。
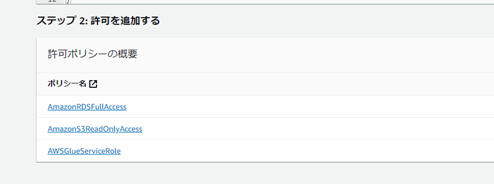
AWSGlueServiceRoleはとりあえず入れておく。
S3はデータ元として読み取りだけできればOK。
RDSは書き込みを行うためにFullAccessを付与した。
ロール名の設定。
注意点、ロール名には「AWSGlueServiceRole」をプレフィックスに付与すること。
これでIAMロールの準備は完了。
次はGlueがS3に接続するための準備をしよう。
準備3 S3との接続準備
GlueからS3へ接続するためには、VPCにエンドポイントを設定する必要がある。
まずはVPC。これはもう普通に作ればOK。
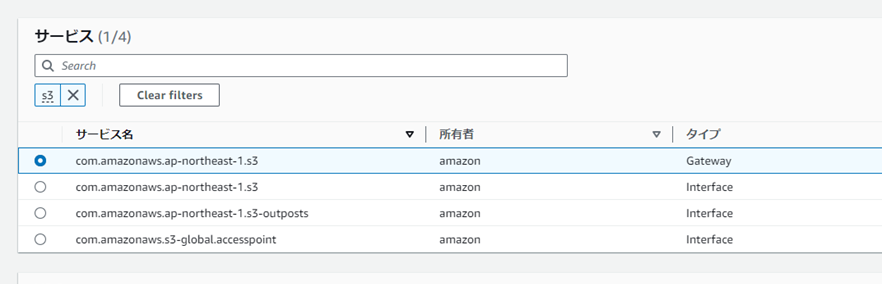
バケットを作成したS3を指定し、タイプは「Gateway」を選択する。
VPCは作成したものを対象にする。
準備4 セキュリティグループ作成
GlueがRDSへ接続するためのセキュリティグループを作成する。
これもドキュメントにポイントが書いてある。
AWSドキュメント セキュリティグループ
以下のインバウンドルールがポイント。
・インバウンドに作っているセキュリティグループ自身をソースに指定する
・タイプ: すべてのTCP
・ポート範囲: 0-66635
準備5 RDS用のインバウンド設定
上で作ったVPCのインバウンドルールに、Glue用のセキュリティグループを指定する。
・タイプ: MYSQL/Aurora
・プロトコル: TCP
・ポート範囲: 3306
準備6 RDS
もうこれは普通にMySQLのインスタンスを作るだけ。
中を見るのにいちいちEC2を作るのも面倒なので、一旦publicな状態で作る。
取込結果は、MySQL Workbenchを使用してみる。
これでS3→Glue→RDSへ接続するための準備が完了。
よっしゃ。Glueの設定に進もう。