はじめに
 |
| AWS AppSync |
Amplify Gen 2 でアプリ開発していると良く使われる AWS AppSync ですが、これまで深く考えずにKiroちゃんの勧められるままに使ってきました。
そんな脇役的なイメージの AppSync ですが、ちょっと気になってきたので調べてみました。
本記事では、AppSync が Amplify Gen 2 の中でどんな役割を果たしているのか、「中継機能」という切り口で整理してみます。
まずは結論から
- AppSync は フロントエンドとデータソースの間に立つ「スマートな中継機能」
- ただリクエストを転送するだけでなく、ルーティング・認証認可・データ変換 を担う
- Amplify Gen 2 は、AppSync を TypeScript だけで構築する自動化レイヤーを有する
想定される読者
- Amplify Gen 2 を触り始めた方(「data って何が動いてるの?」と思った方)
- AppSync の名前は知っているけど、役割がぼんやりしている方
- API Gateway との違いを理解したい方
そもそも GraphQL って何?
AppSync は GraphQL を用いて動作するフルマネージドなAPIです。
このため、AppSync の話に入る前に、GraphQL について整理しておきます。
REST API の「あるある」な悩み
代表的なAPIといえば REST API ですが、REST API は「エンドポイントごとに返すデータが固定」なので、使いづらい場面もあるかと思います。
例えば、以下のような。
-
欲しいデータが足りない(Under-fetching):ユーザー情報と注文一覧が欲しいのに、
/users/123と/users/123/ordersのように2回リクエストが必要 - 余計なデータが多い(Over-fetching):名前だけ欲しいのに、住所やメールなど全部返ってくる
GraphQL のアプローチ
GraphQL は、この問題を「クライアントが欲しいデータを自分で指定する」というアプローチで解決します。
# REST だと2回のリクエストが必要だったものが、1回で済む
query {
getUser(id: "123") {
name # 名前だけ欲しい(住所やメールは不要)
orderlist { # 注文一覧も一緒に取得
orderId
orderingDate
}
}
}
エンドポイントは1つだけ(/graphql)。その代わり、「何が欲しいか」をクエリとして送ります。
REST と GraphQL の比較
| 観点 | REST API | GraphQL |
|---|---|---|
| エンドポイント | リソースごとに複数(/users, /posts) |
1つ(/graphql) |
| データ取得 | サーバーが返す形が固定 | クライアントが欲しい形を指定 |
| 複数リソース | 複数回リクエスト | 1回のクエリで取得可能 |
| リアルタイム性 | WebSocket を別途構築 | Subscription でサポート |
GraphQL は「REST の上位互換」ではなく、得意な場面が違います。
- GraphQL → 自分のアプリ内部(フロントエンドとバックエンドの間)で使うのが主流。クライアントがデータの形を自由に指定できる柔軟さは自社アプリ内では強力ですが、外部公開しづらい
- REST API → 外部アプリケーションと連携するための API に向いている。汎用化することで複数のアプリケーションに対して個別に連携機能を開発する必要がなくなる。「誰でも同じエンドポイントを同じ形式で叩ける」シンプルさが強み
Amplify Gen 2 で AppSync(GraphQL)が採用されているのも、単独のアプリケーションとして開発する側面が強いからでしょうね。
GraphQL の3つの操作
GraphQL には3種類の操作があります。
| 操作 | 役割 | 利用例 |
|---|---|---|
| Query | データの取得(読み取り) | 商品一覧を表示、ユーザー情報を取得 |
| Mutation | データの作成・更新・削除 | 注文を確定、お気に入りに追加 |
| Subscription | リアルタイム通知 | 在庫が変わったら画面に即反映 |
REST API だと「GET = 取得、POST = 作成、PUT = 更新、DELETE = 削除」とHTTPメソッドで使い分けますが、GraphQL は クエリの種類 で使い分けます。
AppSync とは
前置きが長くなりましたが、ここまでを踏まえ AWS AppSync について深堀りしていきます。
AppSync は、AWS が提供する フルマネージドの GraphQL API サービス です。ざっくり言うと、API Gateway の GraphQL 版 のような位置づけです。
通常 GraphQL を使う際は Apollo Server に代表されるAPIサーバーを自分で運用する必要がありますが、AppSync を使うことでお手軽に GraphQL を用いたアプリケーションを構築することができます。
AppSync の役割:3つの中継機能
AppSync は、クライアント(Web/Mobile)とデータソース群の 間 に位置し、単なるリクエスト転送ではなく「スマートな中継」を行います。
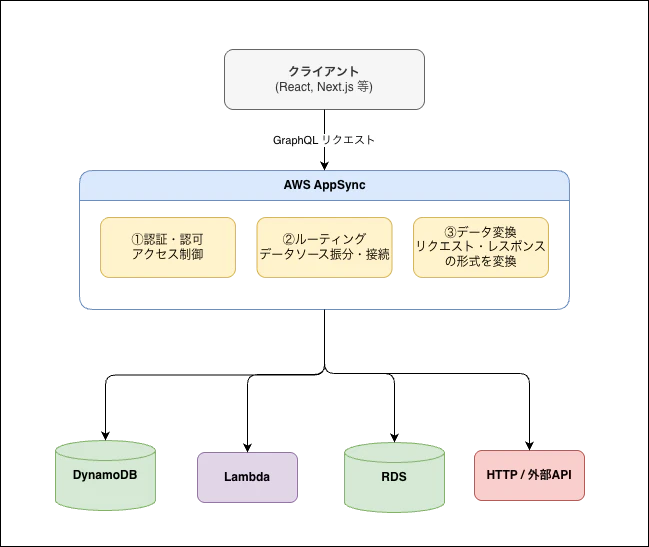
1. 認証・認可ゲートウェイ
リクエストがデータソースに到達する 前に 認証・認可チェックを行います。
例えば、フロントエンドとしてECサイトを構築することを考えてみます。
- 認証(あなたは誰?):ログインしていないユーザーが注文履歴を見ようとしたら、そもそもリクエストを弾く
- 認可(何ができる?):ログイン済みでも、他人の注文履歴は見られないようにする
# 商品一覧 → 誰でも見られる(認証不要)
query {
listProducts {
name
price
imageUrl
}
}
# 注文履歴 → ログイン必須 & 本人のデータだけ返ってくる
query {
listOrders {
productName
price
status
shippingAddress
}
}
# ↑ owner ルールが設定されていると、AppSync が Cognito トークンから
# ユーザーIDを取り出し「このユーザーが owner のレコードだけ返す」
# というフィルタを裏側で自動適用してくれる
AppSync は Cognito 等のトークンに含まれるユーザーIDと、データの所有者(owner)を照合して「この人は本人だからOK」と判断します。本人でなければデータは返されません。
さらに、フィールドレベル で細かく制御することも可能です。たとえば「注文のステータスは管理者も見られるけど、配送先住所は本人だけ」といった設定もできます。
対応している認証方式は以下の通りです。
| 認証方式 | ユースケース |
|---|---|
| Cognito User Pool | 一般的なユーザーログイン(メール/パスワード、ソーシャルログイン) |
| API Key | 公開データの読み取り、開発・テスト用途 |
| IAM | サーバー間通信、管理者用の内部 API |
| OIDC | 外部の ID プロバイダー(Auth0 等)との連携 |
| Lambda Authorizer | 独自の認証ロジック(カスタムトークン検証など) |
Amplify Gen 2 では認可ルールの設定も簡単に行えますが、実際にリクエスト時にトークンを検証してアクセスを許可/拒否しているのは AppSync です。
2. リクエストルーティング(交通整理)
認証・認可を通過したリクエストは、次に適切なデータソースへ振り分けられます。AppSync は GraphQL スキーマの各フィールドに対して「リゾルバ」をマッピングしており、フィールドごとに 適切なデータソースへ振り分けてくれます。
ECサイトのマイページのように、1つの画面にデータの保存先がそれぞれ異なる「ユーザー名」「注文情報」「おすすめ商品」を表示したいような場合に活躍します。
- ユーザー情報 → DynamoDB の Users テーブル
- 注文情報 → DynamoDB の Orders テーブル
- おすすめ商品 → Lambda で動くレコメンドエンジン(外部 API やML モデルを使う)
このとき、以下のクエリを1回送るだけで、AppSync が裏側で3つの異なるデータソースに問い合わせてくれます。
query {
getUser(id: "123") { # → DynamoDB「Users テーブル」に問い合わせ
name
email
orders { # → DynamoDB「Orders テーブル」に問い合わせ
items {
productName
price
}
}
recommendations { # → Lambda 関数(レコメンドエンジン)に問い合わせ
title
score
}
}
}
「どのフィールドがどのデータソースに行くか」は、AppSync の リゾルバ設定 で定義されています。

REST API だと /users/123、/orders?userId=123、/recommendations?userId=123 と3回リクエストが必要なところを、AppSync は 1回のリクエストで複数のデータソースからデータを集約 して返してくれるため、無駄のないデータ連携機能を構築できます。
3. データ変換ミドルウェア
リゾルバの中で、リクエストやレスポンスを 加工 できます。フロントエンドとデータソースの間で「翻訳」してくれるイメージです。
データソースから商品情報を取得する場面を考えてみます。
リクエスト変換:フロントエンドが送る形 → DynamoDB が理解する形
フロントエンドが送るもの:
getProduct(id: "prod-001")
リゾルバが DynamoDB に送るもの:
GetItem { TableName: "Products", Key: { id: { S: "prod-001" } } }
フロントエンドは DynamoDB のテーブル名や Key の形式を知る必要がありません。リゾルバが「翻訳」してくれます。
レスポンス変換:データソースの形 → フロントエンドが期待する形
DynamoDB が返すもの:
{ id: { S: "prod-001" }, price_jpy: { N: "1980" }, is_active: { BOOL: true } }
リゾルバがフロントエンドに返すもの:
{ id: "prod-001", price: 1980, isActive: true }
フィールド名の変換(price_jpy → price)や、DynamoDB 固有の型表記の除去を、リゾルバが吸収してくれます。
この「翻訳」の仕組みがあるおかげで、フロントエンドはデータソースの内部構造を知らなくて済みます。また、データソース側の構造を変更しても、リゾルバで吸収すればフロントエンド側の修正が不要になります。
AppSync のその他の機能
| 機能 | 説明 |
|---|---|
| パイプラインリゾルバ | 複数の処理ステップをチェーンして1つのリゾルバで実行できる |
| リアルタイム同期 | Subscription で、データ変更を即座にクライアントへ通知 |
| オフライン対応 | クライアント側でデータをローカル保存し、復帰時に同期 |
| サーバーサイドキャッシュ | インメモリキャッシュでレイテンシを削減 |
| 自動スケーリング | トラフィックに応じて自動でスケール |
API Gateway との違い
類似サービスである API Gateway との違いについて、「3つの中継機能」の観点で比較してみました。
| 役割 | AppSync | API Gateway |
|---|---|---|
| 認証・認可 | Cognito / IAM / OIDC 等をネイティブサポート。フィールドレベルの認可も可能 | Lambda Authorizer や IAM で実現。フィールドレベルの制御は自前で実装 |
| ルーティング | スキーマベース。フィールドごとに異なるデータソースへ振り分け | URL パスベース。エンドポイントごとに Lambda 等を紐付け |
| データ変換 | リゾルバで DynamoDB 等に直接アクセス&変換。Lambda 不要 | 基本的に Lambda 経由。マッピングテンプレートで簡易変換は可能 |
一番の違いは ルーティングの考え方 です。
- API Gateway:「
/users/123に GET が来たから、この Lambda を呼ぼう」 - AppSync:「
getUserのnameとordersが要求されたから、それぞれのリゾルバを実行しよう」
AppSync の方が「フロントエンドが何を求めているか」をより細かく理解した上でルーティングしてくれます。
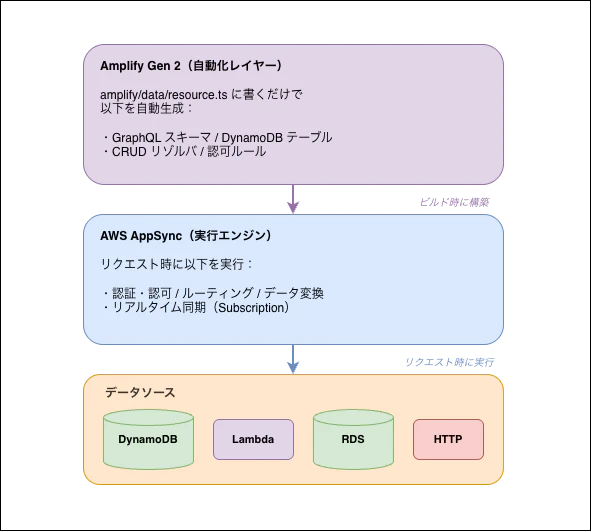
Amplify Gen 2 の役割
ここからは、Amplify Gen 2 が AppSync の機能をどう「簡単に使えるようにしているか」を見ていきます。Amplify Gen 2 では、TypeScript のスキーマ定義 にて複数の機能を自動生成してくれます。
| 何を書くか | 何が自動生成されるか |
|---|---|
| TypeScriptのスキーマ定義 | DynamoDB テーブル + AppSync API 一式 |
| GraphQLスキーマの自動生成 | GraphQL スキーマ(型・クエリ・ミューテーション) |
| 認可ルールの設定 | フィールド単位の認可ルール |
| リゾルバの振り分け先 | CRUD リゾルバ(get / list / create / update / delete) |
詳細は以降のセクションで説明します。
TypeScriptのスキーマ定義
Amplify Gen 2 の自動化レイヤーのベースとなるTypeScriptのスキーマ定義についてです。amplify/data/resource.ts にスキーマを定義するだけで、裏側で AppSync API が自動構築されます。
import { a, defineData, type ClientSchema } from '@aws-amplify/backend';
const schema = a.schema({
// "Product" モデルを定義 → DynamoDB テーブル + CRUD リゾルバが自動生成される
Product: a.model({
name: a.string(), // フィールド定義(GraphQL の型も自動生成)
price: a.integer(),
inStock: a.boolean()
})
.authorization(allow => [allow.owner()]) // 認可ルール:本人のみアクセス可
});
// フロントエンドで使う型を自動エクスポート(型安全なクライアント用)
export type Schema = ClientSchema<typeof schema>;
export const data = defineData({
schema,
authorizationModes: {
defaultAuthorizationMode: 'userPool', // デフォルトの認証方式:Cognito User Pool
}
});
たったこれだけで、AppSync GraphQL API + DynamoDB テーブル + CRUD リゾルバ + Subscription + 認可ルール + 型定義が全部生成されます。
GraphQLスキーマの自動生成
通常のAppSync では GraphQL を動かすために自分で .graphql ファイルに必要な GraphQLスキーマ を書く必要がありますが、Amplify Gen 2 ではビルド時の命名規約で、a.model() のモデル名から自動的に GraphQL のクエリ名が生成されます。
TypeScript で書くもの → 自動生成される GraphQL
─────────────────────────────────────────────────────────
Product: a.model({...}) → getProduct(id: ID!): Product
→ listProducts(...): ProductConnection
→ createProduct(input: ...): Product
→ updateProduct(input: ...): Product
→ deleteProduct(input: ...): Product
フロントエンドで client.models.Product.get({ id: "prod-001" }) と呼ぶと、裏では getProduct(id: "prod-001") という GraphQL クエリが AppSync に送られています。
認可ルールの設定
AppSync での認可ルールについても、Amplify Gen 2 ではスキーマ定義内で宣言的に書けます。
const schema = a.schema({
// 商品情報 → 誰でも読める、作成・更新・削除は管理者だけ
Product: a.model({
name: a.string(),
price: a.integer(),
}).authorization(allow => [
allow.guest().to(['read']), // 未ログインでも閲覧OK
allow.group('admin'), // 管理者は全操作OK
]),
// 注文情報 → 本人だけアクセス可能
Order: a.model({
productName: a.string(),
price: a.integer(),
status: a.string(),
}).authorization(allow => [
allow.owner(), // 本人のデータだけ見える
]),
});
.authorization(allow => [...]) と書くだけで、AppSync 側に認可ルールが自動設定されます。実際にリクエスト時にトークンを検証してアクセスを許可/拒否するのは AppSync の仕事です。
リゾルバの振り分け先
どのフィールドがどのデータソースに行くかの交通整理的な役割であるリゾルバについても、Amplify Gen 2 では、スキーマの書き方がそのままリゾルバの振り分け設定になります。
const schema = a.schema({
User: a.model({ // ← model() → DynamoDB + リゾルバが自動生成
name: a.string(),
email: a.string(),
}),
Order: a.model({ // ← これも DynamoDB に自動マッピング
productName: a.string(),
price: a.integer(),
}),
// Lambda を使うカスタムクエリ
recommendations: a.query()
.returns(a.ref('Recommendation').array())
.handler(a.handler.function('recommendEngine')) // ← Lambda に振り分け
});
-
a.model()→ DynamoDB + CRUD リゾルバが自動生成(Amplify の自動化) -
a.handler.function()→ Lambda に振り分け(明示的に指定) -
a.handler.custom()→ AppSync のリゾルバを直接書く
スキーマの書き方 = ルーティング設定 となり、振り分け設定を明確に管理できます。
裏側で何が起きているか
以上のようにスキーマ定義を設定することで、フロントエンドから Mutation のリクエストが入ると、裏側では図のように AppSync が働いてくれています。
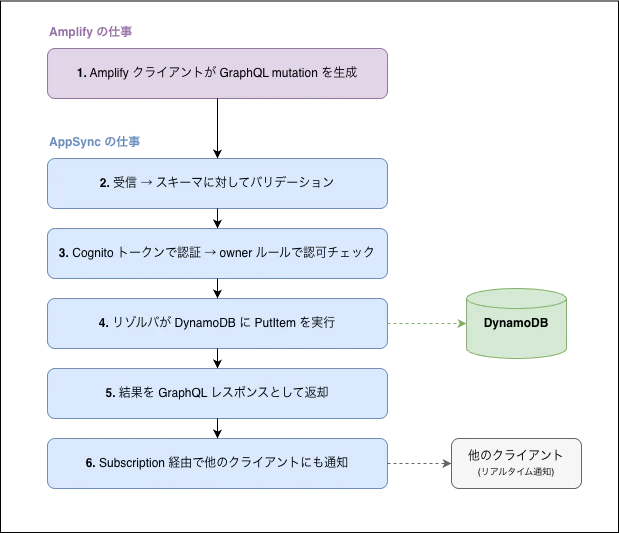
[Amplify の仕事]
1. Amplify クライアントが GraphQL mutation を生成
[AppSync の仕事]
2. AppSync が受信 → スキーマに対してバリデーション
3. Cognito トークンで認証 → owner ルールで認可チェック
4. リゾルバが DynamoDB に PutItem を実行
5. 結果を GraphQL レスポンスとして返却
6. Subscription 経由で他のクライアントにも通知
「意識しなくても動く」のが Amplify Gen 2 と AppSync 連携の良さですが、この流れを知っているとエラーが起きたときに「Amplify 側の問題か、AppSync 側の問題か」を切り分けやすくなります。
AppSync の限界 — 30秒の壁
便利な AppSync ですが、知っておくべき制約があります。
AppSync のリゾルバには タイムアウト30秒 という上限があります。リゾルバが30秒以内にレスポンスを返せないと、エラーになります。
これは API Gateway REST API(29秒)もほぼ同じで、AWS のリクエスト/レスポンス型サービスに共通する制約です。
30秒を超える処理はどうする?
たとえば以下のような処理は、30秒に収まらない可能性があります。
- 大量データの一括処理(CSV インポートなど)
- 外部 API の呼び出しが連鎖する処理
- 動画のエンコードや画像の大量変換
- AI/ML モデルの推論(大きなモデルの場合)
こういった場合は、非同期パターン が推奨されます。
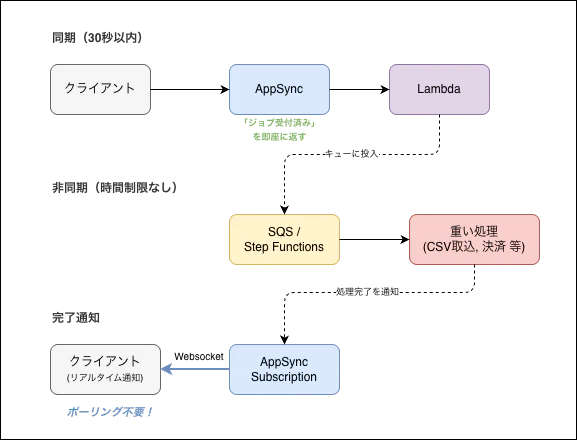
[同期(30秒以内)]
クライアント → AppSync → Lambda → 「ジョブを受け付けました」を即座に返す
↓
[非同期(時間制限なし)]
SQS / Step Functions → 重い処理を実行
↓
[完了通知]
AppSync Subscription で結果をクライアントに通知
ポイントは「受け付け」と「実行」を分離すること。AppSync のレスポンスは「ジョブID」だけ返して、実際の処理は SQS や Step Functions に任せます。処理が終わったら Subscription でクライアントに通知する、という流れです。
非同期処理では AppSync の Subscription(リアルタイム通知)が非常に有効です。非同期処理の完了を WebSocket でクライアントに即座に伝えられるので、ポーリング(定期的に問い合わせ)する必要がありません。
もちろん API Gateway でも WebSocket API を使えばリアルタイム通知は実現できますが、自分で構築する部分がかなり多くなるため、リアルタイム通知が必要なユースケースでは AppSync の良さが光ります。
まとめ
本記事では、AppSync が Amplify Gen 2 の裏側でどんな役割を果たしているかを「中継機能」という切り口で整理しました。
AppSync の3つの中継機能:
- 認証・認可 — リクエストを通すか判断する門番
- ルーティング — フィールドごとに適切なデータソースへ振り分け
- データ変換 — フロントエンドとデータソースの間で「翻訳」
Amplify Gen 2 の役割:
- TypeScript のスキーマ定義(
amplify/data/resource.ts)から、AppSync の設定を自動生成する自動化レイヤー
今後 Amplify Gen 2 で凝ったアプリを作ろうとすると、処理時間の観点などで AppSync の動作も意識する必要が出てきそうなので、今理解を深められたことは良かったなと思います。