はじめに
Amplify Gen 2 と Bedrock AgentCore で、AI補完付きのブックマーク管理 Web アプリ Rich Browser Link を作ってみました。コーディングには Kiro を全面活用しています。
仕事においてもプライベートにおいても、最近のちょっとした悩みとしてブックマークがごちゃごちゃしてて、欲しいリンクに辿り着くまでに時間がかかって仕方がない。目的のページを開く前に別のリンクが目に入り当初やろうとしていたことを忘れてしまう。みたいなことがちょいちょい発生していました。
ブラウザのブックマークだと管理にも限界があって、スッキリさせたいなぁと常々思っていたので、それなら URL を放り込むだけで、AI が勝手にタイトル・説明・タグ・メモを埋めてくれる ブックマーク管理を自分で作ってしまおう、というのが今回の動機です。
まずは結論から
- URL を登録するだけで、OGP取得 → AI補完(タグ・メモ・タイトル等)を自動実行
-
2通りの LLM 呼び出しでスピードとリッチな機能の両立
- AI補完: API Route から Bedrock を直呼び。スピード重視・単目的
- AIエージェント: AgentCore Runtimeで稼働。DynamoDBにも自然言語でアクセス
- ソースは GitHub に公開
想定される読者
- ブックマークがごちゃごちゃになって困っている方
- Amplify Gen 2 で個人開発アプリを作ってみたい方
- 1つのアプリの中で「直呼び LLM」と「AIエージェント」をどう使い分けるか知りたい方
なお、今回のアプリは以前作成した Kiro x Amplify Gen 2 テンプレート を土台にしています。
完成イメージ
デスクトップでは、サイドバー(Collection/タグ)・ブックマーク一覧・AIエージェントチャットの3カラム構成です。ブックマーク検索や最終アクセス日時でのソートも可能。
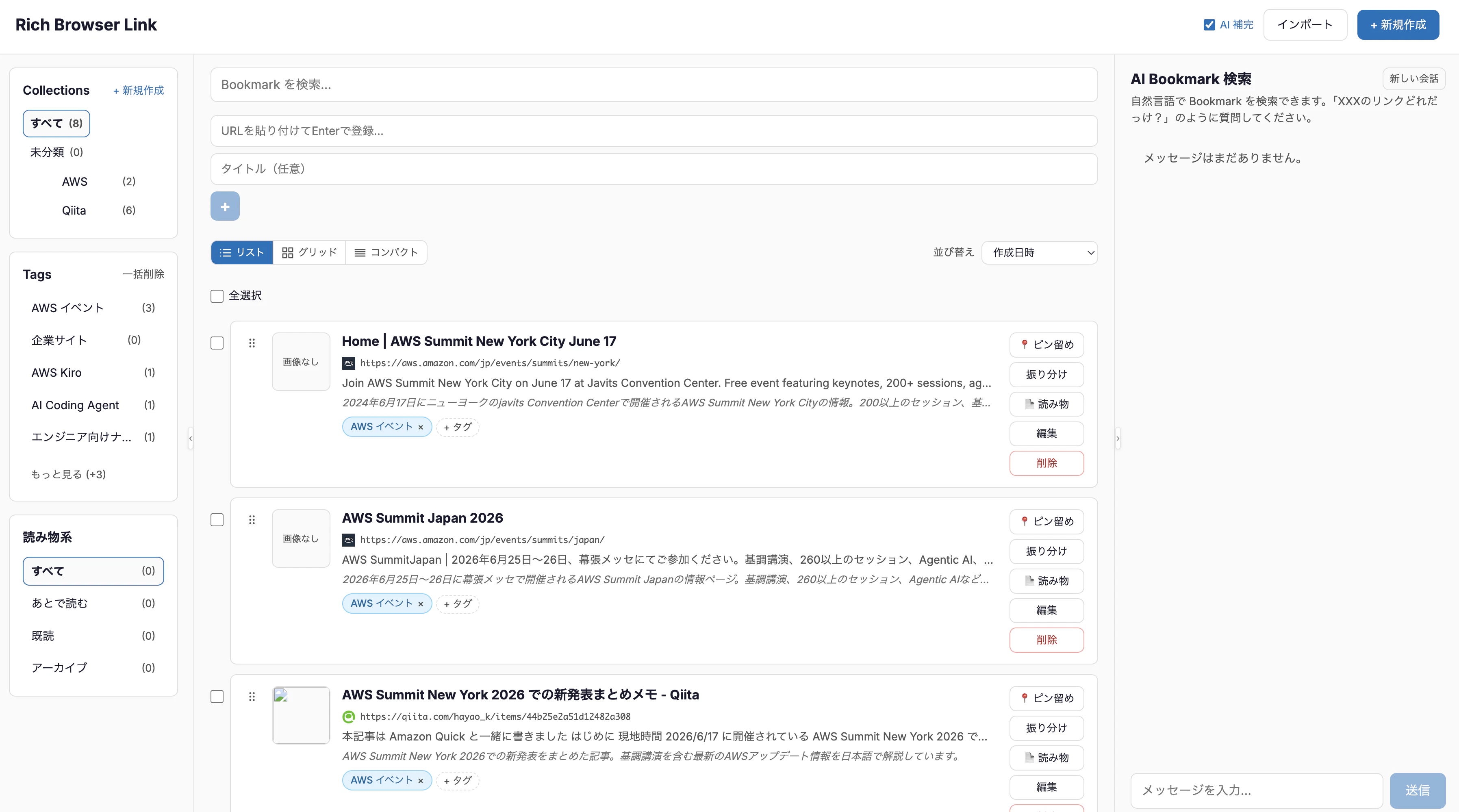
チャット機能では、DynamoDBにアクセスしてブックマークのCRUD操作ができます。

主な機能
| 機能 | 説明 |
|---|---|
| ブックマーク管理 | URL 登録、OGP メタデータ自動取得、読み物系のステータス(未読/既読/アーカイブ)管理、ピン留め |
| AI補完(Enrichment) | LLM による自動タグ付け・メモ生成・タイトル/説明補完 |
| ブックマークインポート | ブラウザのエクスポート HTML を一括取り込み(フォルダ構成の引き継ぎ可) |
| バッチAI補完 | インポート時の大量ブックマークをキュー方式で全件補完 |
| Collection & Tag | 階層 Collection、タグフィルタ、ドラッグ&ドロップ整理、未使用タグ一括削除 |
| AIエージェントチャット | 自然言語でブックマークを検索・作成・編集・削除 |
| レスポンシブ対応 | デスクトップ3カラム、モバイルはオーバーレイ展開 |
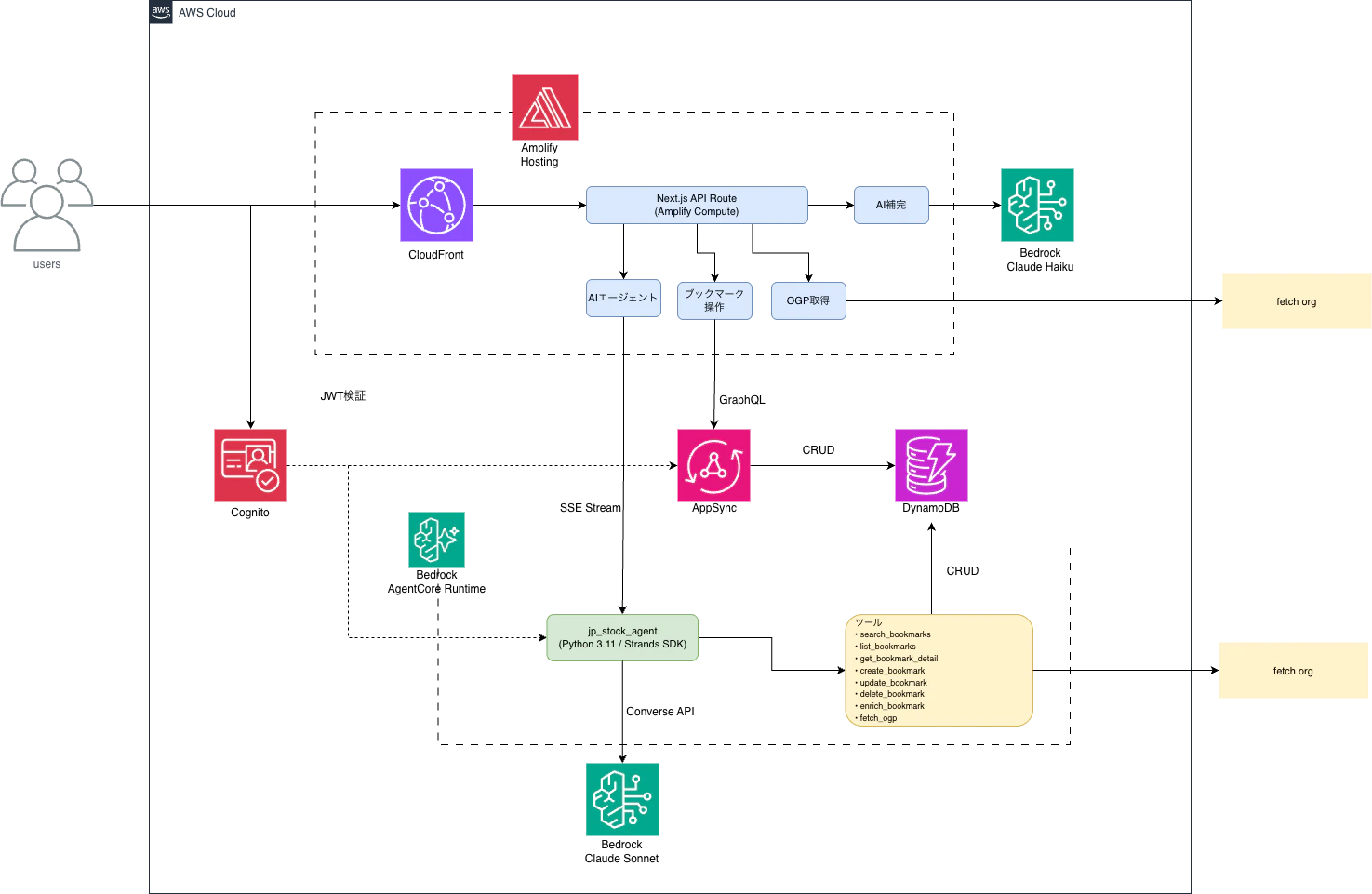
アーキテクチャ
AWSアーキテクチャ図はこんな感じ。
技術スタック
| レイヤー | 技術 |
|---|---|
| フロントエンド | Next.js 15 + TypeScript + React 19 |
| バックエンド | AWS Amplify Gen 2(AppSync + DynamoDB + Cognito) |
| AI補完 | Amazon Bedrock(Claude Haiku) |
| AIエージェント | Python / Strands Agents SDK + Amazon Bedrock(Claude Sonnet) |
| エージェント実行基盤 | Amazon Bedrock AgentCore Runtime |
| ホスティング | Amplify Hosting |
| テスト | Vitest + React Testing Library / fast-check |
| IDE 支援 | Kiro |
Web アプリが主役で、AIエージェントはオプションの拡張という位置づけです。
チャット機能なしでも動作します。
AWS リソース一覧
アーキテクチャ図に登場する AWS リソースと役割は次のとおりです。
| リソース | 役割 |
|---|---|
| Amplify Hosting | Next.js アプリのビルド・デプロイ・ホスティング |
| CloudFront | フロントエンドの配信(Amplify Hosting のCDN) |
| Cognito | ユーザー認証(User Pool)。発行した JWT でデータ分離とエージェントの認可を実施 |
| Next.js API Route(Amplify Compute) | サーバーサイド処理。AI補完・OGP取得及びAIエージェントへの中継を担当 |
| AppSync | GraphQL API。フロントからのブックマーク CRUD を受け付ける |
| DynamoDB | ブックマーク・タグ・Collection を格納するデータストア |
| Bedrock(Claude Haiku) | AI補完用モデル。軽量・高速なモデルでスピード重視 |
| Bedrock(Claude Sonnet) | AIエージェント用モデル。推論・ツール選択をこなす |
| Bedrock AgentCore Runtime | Strands エージェント(Python / Strands SDK)の実行基盤。SSE でフロントへストリーミング |
Bedrock の2つのモデルは用途に合わせて変えています。AI補完には軽量・高速な Claude Haiku、推論しながら複数ツールを連鎖させるエージェントには高性能な Claude Sonnet を割り当てています。
データモデル
Amplify Gen 2 の amplify/data/resource.ts にデータモデルを定義しています。色々と機能を追加したところ、ちょっと複雑な構成になりました。ブックマークを中心に、タグと Collection を多対多でつないでいます。
| モデル | 説明 |
|---|---|
| Bookmark | URL、OGPメタデータ、AI補完結果、ステータス、ピン留め、所属Collection |
| Tag | ブックマークに付与するラベル |
| BookmarkTag | Bookmark ↔ Tag の多対多中間テーブル |
| Collection | ブックマークをまとめるフォルダ(parentId で階層対応) |
| BookmarkCollection | Bookmark ↔ Collection の多対多中間テーブル |
ポイントは、Bookmark を中心に Tag と Collection をそれぞれ中間テーブル経由の多対多でつないでいる点です。Collection は parentId で自分自身を参照し、階層フォルダを表現しています。ER 図にすると次のようになります。
これは DynamoDB そのものの設計図というより、Amplify Data のモデルの関係図です。DynamoDB には RDB のような外部キー制約はなく、id は各テーブルのパーティションキー、bookmarkId / tagId などはただの属性です(中間テーブルでは GSI を張って参照できるようにしています)。テーブル間の関係はあくまで論理的なもので、整合性は Amplify Data 側が面倒を見ます。
関係の定義で押さえておきたいのが hasMany と belongsTo です。Amplify Gen 2 では、この2つでモデル間のリレーションを宣言的に書きます。
-
hasMany: 1対多の「多」を持つ側。例のa.hasMany("BookmarkTag", "bookmarkId")は「Bookmark は複数の BookmarkTag を持つ」を表し、第2引数bookmarkIdは相手側が親を指すために持つ属性名です -
belongsTo: その逆側。a.belongsTo("Bookmark", "bookmarkId")は「BookmarkTag は1つの Bookmark に属する」を表します
多対多(Bookmark ↔ Tag)は、中間テーブルを1つ自分で定義して、両側から hasMany ↔ belongsTo でつなぐのが Amplify 流です。今回の BookmarkTag がそれにあたります。
const schema = a.schema({
Bookmark: a
.model({
url: a.string().required(),
title: a.string().default(""),
status: a.string().default("inbox"), // "inbox" | "read" | "archived"
pinned: a.boolean().default(false),
collectionId: a.id(),
// ...他のフィールドは省略
// hasMany:「Bookmark は複数の BookmarkTag を持つ」(1対多)。
// 第2引数 "bookmarkId" は、相手側(BookmarkTag)が親を指すために持つ属性名
tags: a.hasMany("BookmarkTag", "bookmarkId"),
collections: a.hasMany("BookmarkCollection", "bookmarkId"),
})
.authorization((allow) => [allow.owner()]),
// 多対多(Bookmark ↔ Tag)は、中間テーブルを1つ挟んで両側から belongsTo でつなぐ
BookmarkTag: a
.model({
bookmarkId: a.id().required(),
tagId: a.id().required(),
// belongsTo:「BookmarkTag は1つの Bookmark / Tag に属する」(多対1)
bookmark: a.belongsTo("Bookmark", "bookmarkId"),
tag: a.belongsTo("Tag", "tagId"),
})
.authorization((allow) => [allow.owner()])
// GSI: bookmarkId / tagId それぞれから関連を引けるようにする
.secondaryIndexes((index) => [index("bookmarkId"), index("tagId")]),
// Tag / Collection / BookmarkCollection も同様に定義(ここでは省略)
});
export const data = defineData({
schema,
authorizationModes: { defaultAuthorizationMode: "userPool" },
});
こう書くだけで、AppSync のリゾルバ・DynamoDB のテーブル・GSI がまとめて生成されます。フロントからは bookmark.tags() のように書くだけで関連データをたどれます。
裏側ではリゾルバが中間テーブルの GSI を Query → Tag を取得と複数の DynamoDB 呼び出しを順に投げているイメージです。その配線を自前で書かずに済むのが Amplify Data の便利なところです。
【こだわりポイント】 LLM の呼び分け
今回いちばん考えたのが、同じ Amazon Bedrock を使うのに、用途によって呼び方を完全に分けたところです。
- AI補完(Enrichment) :「決まった補完を、とにかく速く返す」専用ルート
- AIエージェント(Chat) :「自然言語で何でも頼める」万能ルート
| 観点 | AI補完(Enrichment) | AIエージェント(Chat) |
|---|---|---|
| LLM呼び出し | API Route から Bedrock を直呼び | Strands Agent 経由 |
| 実行基盤 | Next.js API Route(Amplify Hosting) | Bedrock AgentCore Runtime |
| 目的 | タグ/メモ/タイトル/説明の自動補完 | 検索・操作なんでも |
| DynamoDBへの書き込み | フロント(Amplify Data)経由 | エージェントが直接 CRUD |
| 重視点 | スピード・堅牢性 | 万能性・柔軟性 |
以降で、それぞれの中身を見ていきます。
AI補完... Bedrock を直呼びしてスピード重視
ブックマーク登録時の AI 補完は、エージェントを挟まず Next.js API Route(/api/ai-enrich)から Bedrock の InvokeModel を直接叩く構成にしています。
やりたいことが「タグ・メモ・タイトル・説明を生成して返す」と固定されているので、推論ループを回す必要はありません。むしろ登録のたびに走る処理なので、速さと堅牢さを最優先しました。
設計で意識したのは次の点です。
-
登録は止めない: Bedrock がタイムアウト・失敗しても、エラーではなく
HTTP 200 + 空フィールドを返す。AI補完はあくまで「おまけ」で、本体のブックマーク登録を妨げない - 速度の上限を切る: API は10秒以内に応答、Bedrock 側のタイムアウトは8秒
- 空欄だけ埋める: OGP で既にタイトルや説明が取れている項目は上書きしない
- 固定スキーマで返す: タグ最大5個、メモ最大300字、タイトル最大200字、説明最大500字
処理は「ブックマーク作成 → OGP取得 → AI補完」をバックグラウンドで順に流すので、ユーザーは補完を待たずに次の URL をどんどん登録できます。
// /api/ai-enrich のイメージ(要点のみ)
export async function POST(req: Request) {
const { url, ogp } = await req.json();
if (!url) {
return Response.json({ error: "url is required" }, { status: 400 });
}
try {
// Bedrock を直接呼び出し、JSON で補完結果を受け取る
const result = await invokeBedrock({ url, ogp, timeoutMs: 8000 });
return Response.json(result); // suggestedTags / suggestedMemo / ...
} catch (e) {
// 失敗しても登録は止めない。空フィールドで 200 を返す
return Response.json({
suggestedTags: [],
suggestedMemo: "",
suggestedTitle: "",
suggestedDescription: "",
});
}
}
AIエージェント... Strands + AgentCore でなんでもできる万能型
一方、チャット欄から使う AIエージェントは、補完とは正反対の「万能型」として作りました。Strands Agents SDK でエージェントを定義し、Amazon Bedrock AgentCore Runtime 上で動かしています。
こちらは「未読のうち AWS 関連のものを教えて」「この URL を保存してタグも付けて」「もう要らないから消して」といった、事前に形を決められないリクエストに応えるのが役割です。だから推論ループを回せるエージェントにして、必要なツールを自分で選んで連鎖させてもらいます。
この操作を実現するため次のツール群を準備しました。
10個のツールで DynamoDB を直接操作する
エージェントには10個のツールを持たせています。検索・閲覧系に加えて、DynamoDB に対する CRUD までツール化しているのがポイントです。
| 分類 | ツール | 役割 |
|---|---|---|
| 検索・閲覧 | search_bookmarks |
キーワード横断検索(タイトル/URL/説明/メモ) |
| 検索・閲覧 | list_bookmarks |
ステータス・タグ・Collection でフィルタ一覧 |
| 検索・閲覧 | get_bookmark_detail |
1件の全メタデータ取得 |
| 検索・閲覧 | list_tags |
タグの一覧 |
| 検索・閲覧 | list_collections |
Collection の一覧 |
| 検索・閲覧 | fetch_ogp |
URL の OGP 情報取得 |
| CRUD | create_bookmark |
ブックマーク新規作成 |
| CRUD | update_bookmark |
フィールド更新、タグ・Collection の追加/削除 |
| CRUD | delete_bookmark |
関連レコードごと削除 |
| CRUD | enrich_bookmark |
既存ブックマークに AI補完を実行 |
各ツールは boto3 で DynamoDB を直接読み書きします。ここで重要なのが、すべてのクエリに owner(Cognito の sub クレーム)でのフィルタを必ず入れることです。フロントの Amplify Data 側は allow.owner() が守ってくれますが、エージェントは別経路で DynamoDB に触るので、データ分離を自前で徹底する必要があります。
from strands import Agent
SYSTEM_PROMPT = """\
あなたはユーザーのブックマークコレクションを管理・検索するアシスタントです。
日本語で回答してください。
(中略: 各ツールの使い分けと、作成時のフローを指示)
"""
def create_agent(owner_id: str = "") -> Agent:
return Agent(
system_prompt=SYSTEM_PROMPT + f"\n現在のユーザーの owner_id は `{owner_id}` です。",
tools=[
fetch_ogp, search_bookmarks, list_bookmarks,
get_bookmark_detail, list_tags, list_collections,
create_bookmark, update_bookmark, delete_bookmark, enrich_bookmark,
],
)
「保存して」の一言でツールを連鎖させる
たとえば「この URL を保存して」と頼むと、エージェントはシステムプロンプトの指示に従って次のように複数ツールを自動でつなぎます。
-
create_bookmarkでレコードを作成 -
fetch_ogpで OGP 情報を取得 -
update_bookmarkで取得したタイトル・説明・画像を反映 -
enrich_bookmarkで AI 補完(タグ・メモ等)を実行
AI補完が「決まった処理を速く1回返す」のに対し、エージェントは「ゴールを伝えると、手順を考えて複数の操作を実行する」。同じ Bedrock でも役割がはっきり違うのが見えると思います。
エージェント機能はあくまでオプションです。AgentCore を立てなくても、ブックマーク管理と AI補完だけで十分実用になります。「まず Amplify でアプリを動かす → 余力があればエージェントを足す」という段階的な拡張ができる構成にしています。
まとめ
今回はAmplify Gen 2 と Bedrock AgentCore で、AI補完付きのブックマーク管理アプリを作ってみました。
階層付きのフォルダ分け(Collection)やタグ付け、読み物系の登録など、思いつく限りの管理機能を追加しつつ、2種類のAI活用方法でより快適に利用できるアプリを目指してみました。
なんでもエージェントにするのではなく、決まった処理は直呼びで速く・自由な操作はエージェントで柔軟にと割り切ると、設計がすっきりすると感じました。Amplify で個人開発を始めたい方の参考になればうれしいです。
ソースは GitHub に公開しています。
Kiroを使えばカスタマイズも簡単にできると思います。
関連記事
土台にした Kiro x Amplify Gen 2 テンプレートの記事はこちらです。