概要: 全文検索では、表記ゆれを吸収するために正規化することが一般的です。たとえばテキストに全角の「DBMS」があるとき、正規化することで、半角の「DBMS」で検索しても「DBMS」が見つかるようになります。DoqueDBではもっとアグレッシブに、正規化に加えて検索時の異表記展開を行うことで、「ウィルス」で「ビールス」も検索できますよ、というのが今回お話ししたいことです。ここではキーワード検索に関して競合ソフトウェアと比較を行っていきます。
今回の話題は正規化です
前回の記事「DoqueDB:MySQL, PostgreSQLと構文を比較してみる」に引き続き、DoqueDBをご紹介させていただきましょう。前回はMySQLやPostgreSQLと全文検索の構文の違いについて解説しましたが、その中で、システムによって正規化のようすが異なることに簡単に触れました。今回は、その正規化について詳しく眺めていきたいと思います。前回の記事をまだご覧でない方は、そちらも合わせてお読みください。
比較対象はMySQL + MroongaおよびPostgreSQL + PGroongaです。正規化の機能はGroongaが提供しているので、実質的にはGroongaとの比較になります。また、MySQL + InnoDBでも基本的な正規化機能が提供されているので、こちらについても見ていきましょう。具体的な比較対象は以下のものになります。
- MySQL + Mroonga (ストレージモード) + Bigram索引
- MySQL + InnoDB + Bigram索引
- PostgreSQL + PGroonga + Bigram索引
- DoqueDB + Bigram索引
比較に用いたバージョンは前回と同じです。
正規化って何するの?
正規化というのは、簡単にいうと、不揃いな表記を何らかの規則に従って一定の表記に揃えることです。
全文検索では、英数字やカタカナの全角半角、大文字小文字を同一視して検索したいことがあります。データの登録時と検索時の両方で正規化を行うことにより、これを実現できます。手順は以下のとおりです。
① 全文検索のデータ登録時に、テキストを正規化して索引語を作る
② 検索時には、入力を正規化してから検索する
肝心なのは、データは入力したものがそのまま登録され、索引はそれを正規化したものから作られるということです。具体例をお見せしましょう。
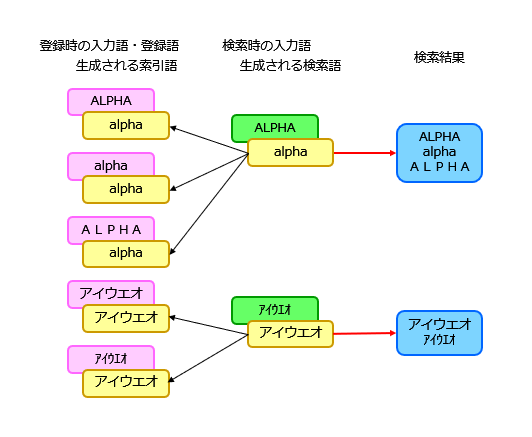
全文検索エンジンやDBMSでは、索引を定義するときに正規化を指定することで、上記の処理が自動的に行われるようになります。
正規化の結果はこうなります
比較対象のソフトウェアで正規化を指定したとき、どんな文字が同一視されるかを見ていきましょう。注意すべき点がいくつかあります。
- ・照合順序による同一視を行いません
- 正規化の効果を確認するため、照合順序による同一視を行っていません。照合順序の指定は前回と同じです。
- ・キーワード検索を用います
- 類似文書検索でなく、キーワード検索を用います。類似文書検索では、指定したキーワードと完全に一致しなくても検索結果に含まれることがあるためです。
- ・Bigram索引を用います
- 正規化を行うと、形態素解析の結果が変化します。ある表記が辞書語になったり、辞書語でなくなったりすることがあるからです。したがって、ここではMeCab索引ではなく、Bigram索引を使って比較します。MeCab索引との差異については、のちほど説明しましょう。
- ・MySQL + Mroongaの結果を示します
- 正規化の指定が同じであれば、MySQL + MroongaでもPostgreSQL + PGroongaでも基本的に同じ結果になります。このため、PostgreSQL + PGroongaの結果は省略しています。
Groongaにはいくつかの正規化器がありますが、ここではNormalizerAutoとNormalizerNFKC150を使用します。これらの違いや、NormalizerNFKC150に指定するオプションについては後述します。DoqueDBについては正規化なしと正規化ありの結果を示します。表の各列の意味は以下のとおりです。
- Groonga / NormalizerAuto
- Groonga / NormalizerNFKC150
- MySQL + InnoDB
- DoqueDB 正規化なし
- DoqueDB 正規化あり (@NORMRSCID:1)
それでは各ソフトウェアの正規化の違いを見てみましょう。
| 正規化種別 | Groonga | MySQL | DoqueDB | ||
|---|---|---|---|---|---|
| Auto | NFKC | InnoDB | なし | あり | |
| 英字大小文字の同一視 (A⇔a, A⇔a) | ○ | ○ | ○ | × | ○ |
| 英字全半角の同一視 (A⇔A) | ○ | ○ | ※3 | × | ○ |
| 数字全半角の同一視 (1⇔1) | ○ | ○ | ○ | × | ○ |
| 記号全半角の同一視 (!⇔!) | ○ | ○ | ※3 | × | ○ |
| キリル文字大小文字の同一視 (Б⇔б) | × | ○ | ○ | × | ○ |
| カタカナ全半角の同一視 (ア⇔ア) | ○ | ○ | ○ | × | ○ |
| ひらがなカタカナの同一視 (あ⇔ア) | × | ○ | × | × | × |
| かな/かな小字の同一視 (あ⇔ぁ) | × | ○ | × | × | × |
| いゐえゑの同一視 (い⇔ゐ, イ⇔ヰ) | × | × | × | × | ○ |
| 清音濁音半濁音の同一視 (は⇔ば⇔ぱ) | × | ○ | × | × | × |
| 新字旧字の同一視 (剣⇔劍) | × | × | × | × | ○ |
| 濁点付き文字の同一視 (が⇔か゛) ※1 | ○ | ○ | ※3 | × | ○ |
| 長音表記ゆれの同一視 (長音, 全半角 マイナス, 全角ダッシュ, 全角ハイフン) |
× | ※2 | × | × | ○ |
| 中点有無の同一視 ドンキホーテ⇔ドン・キホーテ |
× | × | ※3 | × | × |
| ブ/ヴの同一視 バイオリン⇔ヴァイオリン |
× | ○ | × | × | ○ |
| 外来語表記ゆれの同一視 アーキテクチャー⇔アーキテクチュア アルミニウム⇔アルミニューム インタフェース⇔インターフェイス ウィルス⇔ウイルス⇔ビールス ジーゼル⇔ディーゼル スウェーデン⇔スエーデン スマートフォン⇔スマートホン セロハン⇔セロファン チュートリアル⇔テュートリアル テキスト⇔テクスト |
× | × | × | × | ○ ※4 |
※1:Unicodeの濁点・半濁点は2種類あります。後述します。
※2:長音やハイフンに似た文字の正規化については後述します。
※3:期待通りの検索が行われません。後述します。
※4:正規化と異表記展開を組み合わせて実現しています。
いかがでしょうか? システムや正規化器によって、何が同一視されるかがけっこう違うことがわかりますね。以下ではそれぞれのシステムにおける正規化の指定を詳しく見ていくことにします。上で登録や検索に用いたデータは以下のものです。
登録・検索データ
"ALPHA"
"alpha"
"ALPHA"
"alpha"
"12345"
"12345"
"!#$&@"
"!#$&@"
"АБВГДЕ"
"абвгде"
"あいうえお"
"ぁぃぅぇぉ"
"アイウエオ"
"ァィゥェォ"
"アイウエオ"
"ァィゥェォ"
"わいうえを"
"わゐうゑを"
"ワイウエヲ"
"ワヰウヱヲ"
"はひふへほ"
"ばびぶべぼ"
"ぱぴぷぺぽ"
"劍仂桧"
"剣働檜"
"か゛さ゛た゛は゛は゜"
"がざだばぱ" (結合文字の濁点・半濁点を使っています)
"がざだばぱ"
"カ゛サ゛タ゛ハ゛ハ゜"
"ガザダバパ"
"アート"
"ア-ト"
"ア-ト"
"ア―ト"
"ア‐ト"
"ドン・キホーテ"
"ドンキホーテ"
"バイオリン"
"ヴァイオリン"
"アーキテクチャー"
"アーキテクチュア"
"アルミニウム"
"アルミニューム"
"インタフェース"
"インターフェイス"
"ウィルス"
"ウイルス"
"ビールス"
"ジーゼル"
"ディーゼル"
"スウェーデン"
"スエーデン"
"スマートフォン"
"スマートホン"
"セロハン"
"セロファン"
"チュートリアル"
"テュートリアル"
"テキスト"
"テクスト"
Groongaの正規化
それではGroongaの正規化を詳しく見ていきましょう。GroongaにはNormalizerAuto、NormalizerNFKC、NormalizerTableの3種類の正規化器が用意されています。
NormalizerAuto
NormalizerAutoは基本的な正規化を行う正規化器で、エンコーディング (Shift_JIS, EUC-JP, UTF-8など) によらず使うことができます。NormalizerAutoを使うと、以下の文字が同一視できます。
- 英字の大文字と小文字
- 英数字記号およびカタカナの半角文字と全角文字
- 濁点半濁点付き文字 (か゛⇔が, ハ゜⇔パ)
実は、Unicodeには2種類の濁点・半濁点があります。ひとつはShift_JISやEUC-JPと同じ、単独の文字としての濁点(U+309B, 「゛」)と半濁点(U+309C, 「゜」)で、もうひとつは結合用の濁点(U+3099)と半濁点(U+309A)です。後者はゼロ幅の文字で、直前の文字と重ね合わせるように表示されます。「が」は1文字に見えますが、ひらがなの「か」と結合用の濁点を続けたものです。NormalizerAutoでは、清音にどちらの濁点・半濁点を続けた場合も、1文字の濁音・半濁音と同一視されます。
以下はMySQL + Mroongaで、正規化器NormalizerAutoを使ってBigram索引とMeCab索引のカラムを定義し、データをロードするSQLです。一括登録の入力/tmp/test2.csvは、前述の登録・検索データを2列並べたCSVファイルです。
CREATE DATABASE mtestdb;
USE mtestdb;
CREATE TABLE testtable (
bigram_auto VARCHAR(128) NOT NULL,
mecab_auto VARCHAR(128) NOT NULL
) ENGINE = Mroonga DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_ja_0900_as_cs_ks;
LOAD DATA INFILE '/tmp/test2.csv'
INTO TABLE testtable
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n';
CREATE FULLTEXT INDEX bigram_auto_index
ON testtable(bigram_auto)
COMMENT
'tokenizer "TokenBigram",
normalizer "NormalizerAuto"';
CREATE FULLTEXT INDEX mecab_auto_index
ON testtable(mecab_auto)
COMMENT
'tokenizer "TokenMecab",
normalizer "NormalizerAuto"';
上で定義したカラムbigram_autoやmecab_autoを検索するSQLは以下のようになります。キーワード検索を行うために「IN BOOLEAN MODE」を指定しています。今回の登録・検索データでは、Bigram索引でもMeCab索引でも検索結果は同じになります。
SELECT bigram_auto FROM testtable
WHERE MATCH(bigram_auto) AGAINST('ALPHA' IN BOOLEAN MODE);
SELECT bigram_auto FROM testtable
WHERE MATCH(bigram_auto) AGAINST('alpha' IN BOOLEAN MODE);
SELECT bigram_auto FROM testtable
WHERE MATCH(bigram_auto) AGAINST('ALPHA' IN BOOLEAN MODE);
SELECT bigram_auto FROM testtable
WHERE MATCH(bigram_auto) AGAINST('alpha' IN BOOLEAN MODE);
SELECT bigram_auto FROM testtable
WHERE MATCH(bigram_auto) AGAINST('12345' IN BOOLEAN MODE);
...
PostgreSQL + PGroongaで上と同じ索引の定義とデータのロードを行うSQLは以下のようになります。
CREATE DATABASE testdb
WITH ENCODING 'UTF8'
LC_COLLATE = 'ja_JP.UTF8'
LC_CTYPE = 'ja_JP.UTF8'
TEMPLATE = template0;
\connect testdb
CREATE TABLE testtable (
bigram_auto TEXT,
mecab_auto TEXT
);
COPY testtable
(bigram_auto, mecab_auto)
FROM '/tmp/test2.csv'
WITH (FORMAT CSV, DELIMITER ',', QUOTE '"', ESCAPE '"');
CREATE INDEX bigram_auto_index
ON testtable USING pgroonga(bigram_auto)
WITH (tokenizer='TokenBigram',
normalizers='NormalizerAuto');
CREATE INDEX mecab_auto_index
ON testtable USING pgroonga(mecab_auto)
WITH (tokenizer='TokenMecab',
normalizers='NormalizerAuto');
同様に、検索を行うSQLは以下のとおりです。「&@」はキーワード検索を行う演算子です。
SELECT bigram_auto FROM testtable WHERE bigram_auto &@ 'ALPHA';
SELECT bigram_auto FROM testtable WHERE bigram_auto &@ 'alpha';
SELECT bigram_auto FROM testtable WHERE bigram_auto &@ 'ALPHA';
SELECT bigram_auto FROM testtable WHERE bigram_auto &@ 'alpha';
SELECT bigram_auto FROM testtable WHERE bigram_auto &@ '12345';
...
NormalizerNFKC
NormalizerNFKCは、Unicode正規化の正規化形式KCに基づいて正規化を行う正規化器で、エンコーディングがUTF-8のときに指定できます。対応するUnicodeのバージョンによって、いくつかの変種がありますが、ここでは最新のNormalizerNFKC150を使います。NormalizerNFKC150には正規化仕様を変更するオプションが多数用意されていますが、初期状態では、NormalizerAutoの仕様に加えて以下の文字が同一視されます。
- キリル文字の大文字と小文字 (Б⇔б)
正規化オプションにはトークナイズの動作に影響するものがあるため、トークナイズ後に置き換えを行う手段が用意されています。それはトークンフィルターです。詳しくいうと、正規化は次の順序で実行されます。
① 正規化
② トークナイズ
③ トークンフィルター
オプションによる正規化は、NormalizerNFKC150に指定すると①で実行され、TokenFilterNFKC150に指定すると③で実行されます。どちらに指定するかは、以下のルールに従うとよいでしょう。
①正規化に指定する
- 文字数が変化するもの (Bigram索引のブ/ヴ同一視など)
- トークナイズを改善するもの (MeCab索引の長音正規化など)
③トークンフィルターに指定する
- トークナイズに悪影響のあるもの (MeCab索引のひらがなカタカナ同一視など)
以上を考慮しながら、ここでは以下のオプションを指定することにしましょう。
| 位置 | オプション | 意味 |
|---|---|---|
| ① | unify_katakana_v_sounds | ブ/ヴの同一視 (バイオリン⇔ヴァイオリン) |
| ① | unify_prolonged_sound_mark | 長音正規化 |
| ③ | unify_kana | ひらがなカタカナの同一視 (あ⇔ア) |
| ③ | unify_kana_case | かな/かな小字の同一視 (あ⇔ぁ) |
| ③ | unify_kana_voiced_sound_mark | 清音濁音半濁音の同一視 (は⇔ば⇔ぱ) |
NormalizerNFKC150には長音やハイフンに似た文字を正規化するオプションがいくつか用意されていますが、それらを長音に寄せるオプションはunify_prolonged_sound_markだけです。これは半角カナ長音(U+FF70), 全角ダッシュ(U+2014), 水平バー(U+2015), 罫線素片の横棒(U+2500, U+2501)を全角カナ長音(U+30FC)に正規化します。日本語文にありがちな「長音があるべきところに全角マイナスがある」ケースには対応していないようです。
以下はMySQL + Mroongaで、正規化器NormalizerNFKC150を使ってBigram索引とMeCab索引のカラムを定義し、データをロードするSQLです。
CREATE DATABASE mtestdb;
USE mtestdb;
CREATE TABLE testtable (
bigram_nfkc VARCHAR(128) NOT NULL,
mecab_nfkc VARCHAR(128) NOT NULL
) ENGINE = Mroonga DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_ja_0900_as_cs_ks;
LOAD DATA INFILE '/tmp/test2.csv'
INTO TABLE testtable
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n';
CREATE FULLTEXT INDEX bigram_nfkc_index
ON testtable(bigram_nfkc)
COMMENT
'tokenizer "TokenBigram",
normalizer "NormalizerNFKC150(
\'unify_katakana_v_sounds\', true,
\'unify_prolonged_sound_mark\', true)",
token_filters "TokenFilterNFKC150(
\'unify_kana\', true,
\'unify_kana_case\', true,
\'unify_kana_voiced_sound_mark\', true)"';
CREATE FULLTEXT INDEX mecab_nfkc_index
ON testtable(mecab_nfkc)
COMMENT
'tokenizer "TokenMecab",
normalizer "NormalizerNFKC150(
\'unify_katakana_v_sounds\', true,
\'unify_prolonged_sound_mark\', true)",
token_filters "TokenFilterNFKC150(
\'unify_kana\', true,
\'unify_kana_case\', true,
\'unify_kana_voiced_sound_mark\', true)"';
上で定義したカラムbigram_nfkcやmecab_nfkcを検索するSQLは以下のようになります。
SELECT bigram_nfkc FROM testtable
WHERE MATCH(bigram_nfkc) AGAINST('ALPHA' IN BOOLEAN MODE);
SELECT bigram_nfkc FROM testtable
WHERE MATCH(bigram_nfkc) AGAINST('alpha' IN BOOLEAN MODE);
SELECT bigram_nfkc FROM testtable
WHERE MATCH(bigram_nfkc) AGAINST('ALPHA' IN BOOLEAN MODE);
SELECT bigram_nfkc FROM testtable
WHERE MATCH(bigram_nfkc) AGAINST('alpha' IN BOOLEAN MODE);
SELECT bigram_nfkc FROM testtable
WHERE MATCH(bigram_nfkc) AGAINST('12345' IN BOOLEAN MODE);
...
ひらがなカタカナを同一視するオプションunify_kanaを指定していますが、MeCab索引では「あいうえお」「アイウエオ」など、トークナイズの結果が異なるものについては同一視されないことに注意してください。MeCabによるトークナイズの結果は、以下のようにして確認できます。
$ echo 'あいうえお' | mecab -d /usr/lib64/mysql/mecab/dic/ipadic_utf-8
あい 動詞,自立,*,*,五段・カ行イ音便,連用タ接続,あく,アイ,アイ
う 助動詞,*,*,*,不変化型,基本形,う,ウ,ウ
え フィラー,*,*,*,*,*,え,エ,エ
お 感動詞,*,*,*,*,*,お,オ,オ
EOS
$ echo 'アイウエオ' | mecab -d /usr/lib64/mysql/mecab/dic/ipadic_utf-8
アイウエオ 名詞,固有名詞,組織,*,*,*,*
EOS
PostgreSQL + PGroongaで上と同じ索引の定義とデータのロードを行うSQLは以下のようになります。
CREATE DATABASE testdb
WITH ENCODING 'UTF8'
LC_COLLATE = 'ja_JP.UTF8'
LC_CTYPE = 'ja_JP.UTF8'
TEMPLATE = template0;
\connect testdb
CREATE TABLE testtable (
bigram_nfkc TEXT,
mecab_nfkc TEXT
);
COPY testtable
(bigram_nfkc, mecab_nfkc)
FROM '/tmp/test2.csv'
WITH (FORMAT CSV, DELIMITER ',', QUOTE '"', ESCAPE '"');
CREATE INDEX bigram_nfkc_index
ON testtable USING pgroonga(bigram_nfkc)
WITH (tokenizer='TokenBigram',
normalizers='NormalizerNFKC150(
"unify_katakana_v_sounds", true,
"unify_prolonged_sound_mark", true)',
token_filters='TokenFilterNFKC150(
"unify_kana", true,
"unify_kana_case", true,
"unify_kana_voiced_sound_mark", true)');
CREATE INDEX mecab_nfkc_index
ON testtable USING pgroonga(mecab_nfkc)
WITH (tokenizer='TokenMecab',
normalizers='NormalizerNFKC150(
"unify_katakana_v_sounds", true,
"unify_prolonged_sound_mark", true)',
token_filters='TokenFilterNFKC150(
"unify_kana", true,
"unify_kana_case", true,
"unify_kana_voiced_sound_mark", true)');
同様に、検索を行うSQLは以下のとおりです。
SELECT bigram_nfkc FROM testtable WHERE bigram_nfkc &@ 'ALPHA';
SELECT bigram_nfkc FROM testtable WHERE bigram_nfkc &@ 'alpha';
SELECT bigram_nfkc FROM testtable WHERE bigram_nfkc &@ 'ALPHA';
SELECT bigram_nfkc FROM testtable WHERE bigram_nfkc &@ 'alpha';
SELECT bigram_nfkc FROM testtable WHERE bigram_nfkc &@ '12345';
...
NormalizerTable (余談)
ちょっと脇道にそれますが、GroongaのNormalizerTableに触れておきます。これはテーブルを使った正規化で、PostgreSQL + PGroongaの環境で使うことができます。
細かい説明は省略して、サンプルをご覧いただきましょう。正規化用のテーブルを定義し、正規化前後の文字列を登録します。全文索引の定義時にこのテーブルをNormalizerTableとして指定することにより、登録した文字列による正規化が行われるようになります。以下では「はい」「そうです」「ちがいます」をすべて同一視します。
CREATE DATABASE nttestdb;
\connect nttestdb;
CREATE TABLE normtable (
target TEXT,
normalized TEXT
);
CREATE EXTENSION IF NOT EXISTS pgroonga;
CREATE INDEX normtable_index ON normtable
USING pgroonga (target pgroonga_text_term_search_ops_v2,
normalized);
INSERT INTO normtable VALUES ('はい', 'そうです');
INSERT INTO normtable VALUES ('ちがいます', 'そうです');
CREATE TABLE sample (
id INTEGER,
content TEXT
);
CREATE INDEX sample_index ON sample
USING pgroonga (content)
WITH (normalizers='
NormalizerNFKC150("unify_kana", true),
NormalizerTable(
"normalized", "${table:normtable_index}.normalized",
"target", "target")');
INSERT INTO sample VALUES (1, 'はい');
INSERT INTO sample VALUES (2, 'ソウデス');
INSERT INTO sample VALUES (3, 'ちがいます');
NormalizerTableは、ほかの正規化器と同時に指定することもできます。ここではNormalizerNFKC150を併用して、ひらがなとカタカナを同一視しています。DBMS内での使用に限られますが、NormalizerTableは自由度の高い正規化を実現するために役立つでしょう。
「ハイ」「チガイマス」を検索した結果は以下のとおりです。面白いですね。
postgres=# SELECT * FROM sample WHERE content &@ 'ハイ';
id | content
----+------------
1 | はい
2 | ソウデス
3 | ちがいます
(3 行)
postgres=# SELECT * FROM sample WHERE content &@ 'チガイマス';
id | content
----+------------
1 | はい
2 | ソウデス
3 | ちがいます
(3 行)
postgres=#
MySQL + InnoDBの正規化
MySQL + InnoDBの全文索引定義では正規化を記述できませんが、基本的な正規化は行われているようです。試してみたところ、以下の文字が同一視されました。
- 英字やキリル文字の大文字と小文字
- 英数字およびカタカナの半角文字と全角文字
濁点半濁点付きの文字は同一視されません。また、いくつか不可解な点があります。理由は調べていません。
- 「ABCDE」で「ABCDE」「ABCDE」が見つかりますが、「ABCDE」では「ABCDE」しか見つかりません。
- 「!#$&@」「!#$&@」はどちらも見つかりません。
- 「か゛さ゛た゛は゛は゜」で「か゛さ゛た゛は゛は゜」が見つかりません。
- 「ドン・キホーテ」では「ドン・キホーテ」「ドンキホーテ」が見つかりますが、「ドンキホーテ」では「ドンキホーテ」しか見つかりません。
以下はN-gram索引とMeCab索引のカラムを定義し、データをロードするSQLです。
CREATE DATABASE itestdb;
USE itestdb;
CREATE TABLE testtable (
FTS_DOC_ID BIGINT UNSIGNED
AUTO_INCREMENT NOT NULL PRIMARY KEY,
inno_ngram VARCHAR(128),
inno_mecab VARCHAR(128)
) ENGINE = InnoDB DEFAULT CHARSET=utf8mb4
COLLATE=utf8mb4_ja_0900_as_cs_ks;
LOAD DATA INFILE '/tmp/test2.csv'
INTO TABLE testtable
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
(inno_ngram, inno_mecab);
CREATE FULLTEXT INDEX inno_ngram_index
ON testtable(inno_ngram) WITH PARSER ngram;
CREATE FULLTEXT INDEX inno_mecab_index
ON testtable(inno_mecab) WITH PARSER mecab;
N-gram索引を付けたカラムを検索するSQLは以下のようになります。
SELECT inno_ngram FROM testtable
WHERE MATCH(inno_ngram) AGAINST('ALPHA' IN BOOLEAN MODE);
SELECT inno_ngram FROM testtable
WHERE MATCH(inno_ngram) AGAINST('alpha' IN BOOLEAN MODE);
SELECT inno_ngram FROM testtable
WHERE MATCH(inno_ngram) AGAINST('ALPHA' IN BOOLEAN MODE);
SELECT inno_ngram FROM testtable
WHERE MATCH(inno_ngram) AGAINST('alpha' IN BOOLEAN MODE);
SELECT inno_ngram FROM testtable
WHERE MATCH(inno_ngram) AGAINST('12345' IN BOOLEAN MODE);
...
DoqueDBの正規化
さて、それではDoqueDBの正規化を見ていくことにしましょう。
DoqueDBでは、正規化を指定しないといかなる同一視も行われません。正規化を行うためには正規化リソースを指定する必要があります。現在は「@NORMRSCID:1」の1種類のみ提供されています。このリソースでは以下の文字が同一視されます。濁点半濁点付き文字については、Groongaと同じく結合用濁点・半濁点も同一視の対象となります。
- 英字やキリル文字の大文字と小文字
- 英数字記号およびカタカナの半角文字と全角文字
- ワ行の文字 (い⇔ゐ, え⇔ゑ)
- 新字と旧字 (剣⇔劍)
- 濁点半濁点付き文字 (か゛⇔が, ハ゜⇔パ)
- 長音に似た文字 (長音, 全半角マイナス, 全角ダッシュ, 全角ハイフン)
- ブとヴ (バイオリン⇔ヴァイオリン)
- 外来語表記ゆれ (アーキテクチャー⇔アーキテクチュア等)
新字と旧字、外来語表記ゆれの同一視など、DoqueDBに特有の正規化があることがわかりますね。これらは、DoqueDBの前身となるシステムがこれまで日本語の全文検索機能を提供してきた中で、ユーザーからの要望として取り込まれてきたものです。実用的な全文検索を行うには、これらの正規化が必要だと我々は考えている、ということでもあります。
以下は正規化なしと正規化ありのカラムを定義し、データをロードするSQLです。
CREATE DATABASE testdb;
CREATE TABLE testtable (
orig NVARCHAR(128),
norm NVARCHAR(128)
);
INSERT INTO testtable
INPUT FROM PATH '/tmp/test2.csv'
HINT 'Code="utf-8" InputField=(1,2)';
CREATE FULLTEXT INDEX orig_index ON testtable(orig)
HINT 'INVERTED=(INDEXING=DUAL,
TOKENIZER=DUAL:JAP:ALL:2 @UNARSCID:1)';
CREATE FULLTEXT INDEX norm_index ON testtable(norm)
HINT 'INVERTED=(INDEXING=DUAL,
NORMALIZED=(STEMMING=FALSE, DELETESPACE=FALSE),
TOKENIZER=DUAL:JAP:ALL:2 @NORMRSCID:1 @UNARSCID:1)';
正規化ありのカラムを検索するSQLは以下のようになります。
SELECT norm FROM testtable WHERE norm CONTAINS('ALPHA');
SELECT norm FROM testtable WHERE norm CONTAINS('alpha');
SELECT norm FROM testtable WHERE norm CONTAINS('ALPHA');
SELECT norm FROM testtable WHERE norm CONTAINS('alpha');
SELECT norm FROM testtable WHERE norm CONTAINS('12345');
...
正規化と異表記展開を組み合わせる
外来語の表記ゆれは複数文字にわたり、また文字数も変化します。それらをすべて同一の表記に正規化すると、検索時のノイズをいたずらに増やすことになりかねません。たとえば「ウイルス」と「ビールス」を同一視するために「ウイ」を「ビー」に正規化したとしましょう。すると「ウイグル」と「ビーグル」を区別する手段がなくなります。これはうれしくないですね。
DoqueDBでは、正規化と異表記展開を組み合わせることによって、この問題を解決しています。具体的な処理の流れを見てみましょう。
データの正規化 (登録時)
データの登録時には、入力データを正規化してから索引が作られます。たとえば「ウィルス」「ウイルス」「ビールス」は以下のように加工されます。
| 入力データ | → 正規化 | → 索引語 |
|---|---|---|
| ウィルス | ウイルス | ウイルス |
| ウイルス | ウイルス | ウイルス |
| ビールス | ビールス | ビールス |
データの正規化と異表記展開 (検索時)
検索時には、入力データを正規化し、その結果を異表記展開して得られたすべての検索語について検索を行います。「ウィルス」「ウイルス」「ビールス」に対しては、以下のような処理が行われます。ついでに「ウィスキー」と「ビール」も検索してみましょう。
| 入力データ | → 正規化 | → 異表記展開 | → 検索語 |
|---|---|---|---|
| ウィルス | ウイルス | ウイルス, ビールス | ウイルス, ビールス |
| ウイルス | ウイルス | ウイルス, ビールス | ウイルス, ビールス |
| ビールス | ビールス | ビールス, ウイルス | ビールス, ウイルス |
| ウィスキー | ウイスキ | ウイスキ | ウイスキ |
| ビール | ビール | ビール | ビール |
このように、「ビールス」を検索すると「ビールス」「ウイルス」が検索語となり、結果として「ウィルス」「ウイルス」「ビールス」が見つかることがわかります。加えて、「ビール」が「ウイル」に異表記展開されないこともわかりました。
検索時に異表記展開を行うのは、正規化によるノイズを増やさないことのほかに、処理コストを考慮した結果でもあります。正規化は時間のかかる処理であるため、大量のデータを扱う登録時の処理はシンプルにしておき、より広い表記ゆれに対応する処理は検索時に行ったほうがよい、ということです。
DoqueDBが正規化に関してこのようにアグレッシブな姿勢をとっているのは、そもそもDoqueDBの前身が全文検索エンジンとして開発された経緯によるものです。データベースの検索機能としては、少しばかり飛躍したものと言ってよいでしょう。
どんなふうに正規化・異表記展開されるの?
入力がどのように正規化されるかについては、SQLからNORMALIZE関数を使って確認することができます。sqliで接続先データベースを省略するとDefaultDBに接続します。FROMを指定しないSELECTが用意されていないため、組み込み表SYSTEM_SESSIONをダミーの取得先として指定しています。「NORM:1」は全文索引定義時の「@NORMRSCID:1」と同じです。
$ rlwrap sqli -remote localhost 54321 -user root -password doqadmin
SQL>select normalize('アーキテクチャー' using 'NORM:1') from system_session;
{normalize('アーキテクチャー' using 'NORM:1')}
{アキテクチヤ}
SQL>select normalize('アーキテクチュア' using 'NORM:1') from system_session;
{normalize('アーキテクチュア' using 'NORM:1')}
{アキテクチユア}
SQL>
異表記展開の結果は、残念ながらSQLからは確認できません。辞書リソースのソースデータを見るか、あるいはテストプログラムを動かして確認することになります。具体的な手順をちょっとお見せしましょう。ソースコード一式はGitHubリポジトリから取得してください。
新字旧字の正規化データ(NormKmap.txt)、外来語表記の正規化および異表記展開ソースデータ(src_norm.txt, src_exp.txt)は、辞書リソースの中にあります。
$ cd una/1.0/resource/src-data/norm
$ head -5 NormKmap.txt
穐→秋
頴→穎
蛎→蠣
苅→刈
舘→館
$ head -5 src_norm.txt
########## ア段ー○ア段 ##########
アー ア # [19]
カー カ # [20]
ガー ガ # [21]
$ head -6 src_exp.txt
########## 基本データ(派生タイプ)に由来 ##########
##### [4-8] アッサ行○アサ行 #####
アセンブラ # [7]
アッセンブラ
$
正規化器のテストプログラムを使うと正規化や異表記展開の結果を確認できますが、ビルド作業が必要です。BUILDING_PROCEDURE_ja.mdに従って「UNAライブラリ (日本語形態素解析器)」のmake buildallまでを実施しておいてください。その後、以下のようにテストプログラムを実行します。
$ cd una/1.0/test/c.O114-64
$ make test-setup
$ export LD_LIBRARY_PATH=`pwd`:$LD_LIBRARY_PATH
$ echo 'アーキテクチャー' | ./nlpnorm
アキテクチヤ
$ echo 'アーキテクチャー' | ./nlpnorm -e
アキテクチヤ,アキテクチユア
$ echo 'アーキテクチュア' | ./nlpnorm
アキテクチユア
$ echo 'アーキテクチュア' | ./nlpnorm -e
アキテクチユア,アキテクチヤ
$
全文検索以外での正規化の利用
全文索引を定義したカラムでなくても、登録時と検索時にそれぞれNORMALIZE関数を呼ぶことにより、通常の条件検索やLIKE検索で正規化を用いた検索を実行できます。残念ながら、異表記展開は利用できません。
通常どおり、カラムを定義します。
CREATE DATABASE db;
CREATE TABLE t (
orig NVARCHAR(128),
norm NVARCHAR(128)
);
データの登録時に、NORMALIZE関数の返り値を渡します。検索時には、WHERE句の条件にNORMALIZE関数の返り値を指定します。
$ rlwrap sqli -remote localhost 54321 -user root -password doqadmin -database db
SQL>INSERT INTO t VALUES('ウィルス', normalize('ウィルス' USING 'NORM:1'));
{<identity>,<current_timestamp>,ROWID}
{(null),(null),0}
SQL>SELECT * FROM t WHERE norm = normalize('ウィルス' USING 'NORM:1');
{orig,norm}
{ウィルス,ウイルス}
SQL>
外部アプリからの正規化・異表記展開の利用
DoqueDB組込みの形態素解析器・正規化器はC++のDLLとして提供されており、DoqueDBの外からでも使うことができます。DoqueDBと正規化リソースを共用することで、DoqueDBと同じ正規化や異表記展開を外部アプリからでも利用できるということです。
現在はまだ十分なドキュメントが用意されていないため、実際に利用するのは簡単ではないと思いますが、先ほどのテストプログラムのソースをご覧いただければ、おおよその使い方はご理解いただけると思います。機会がありましたら、いずれQiitaで解説記事を書かせていただくこともあるでしょう。
おわりに
今回の記事では、Groonga、InnoDB、DoqueDBの正規化機能について詳しく説明させていただきました。トークナイズの細かい仕様など、まだまだ説明が不十分な点もあるかと思いますが、解説としてはこれで一区切りとさせていただきます。DoqueDBの正規化に使える辞書リソースを修正したり新規作成したりする方法についても、今回は説明を割愛いたしましたが、いずれQiitaの記事を通じてご説明させていただきたいと考えております。
毎度のお願いになりますが、他システムの説明に誤りなどありましたら、コメントにてご指摘いただければ幸いです。
DoqueDBのWebサイトとGitHubのURLは以下のとおりです。皆様のご訪問を (揉み手をしながら、期待しつつ) お待ちしております。それでは、またお会いしましょう!
DoqueDB Webサイト
https://www.doquedb.ricoh.co.jp
GitHubリポジトリ
https://github.com/DoqueDB/doquedb