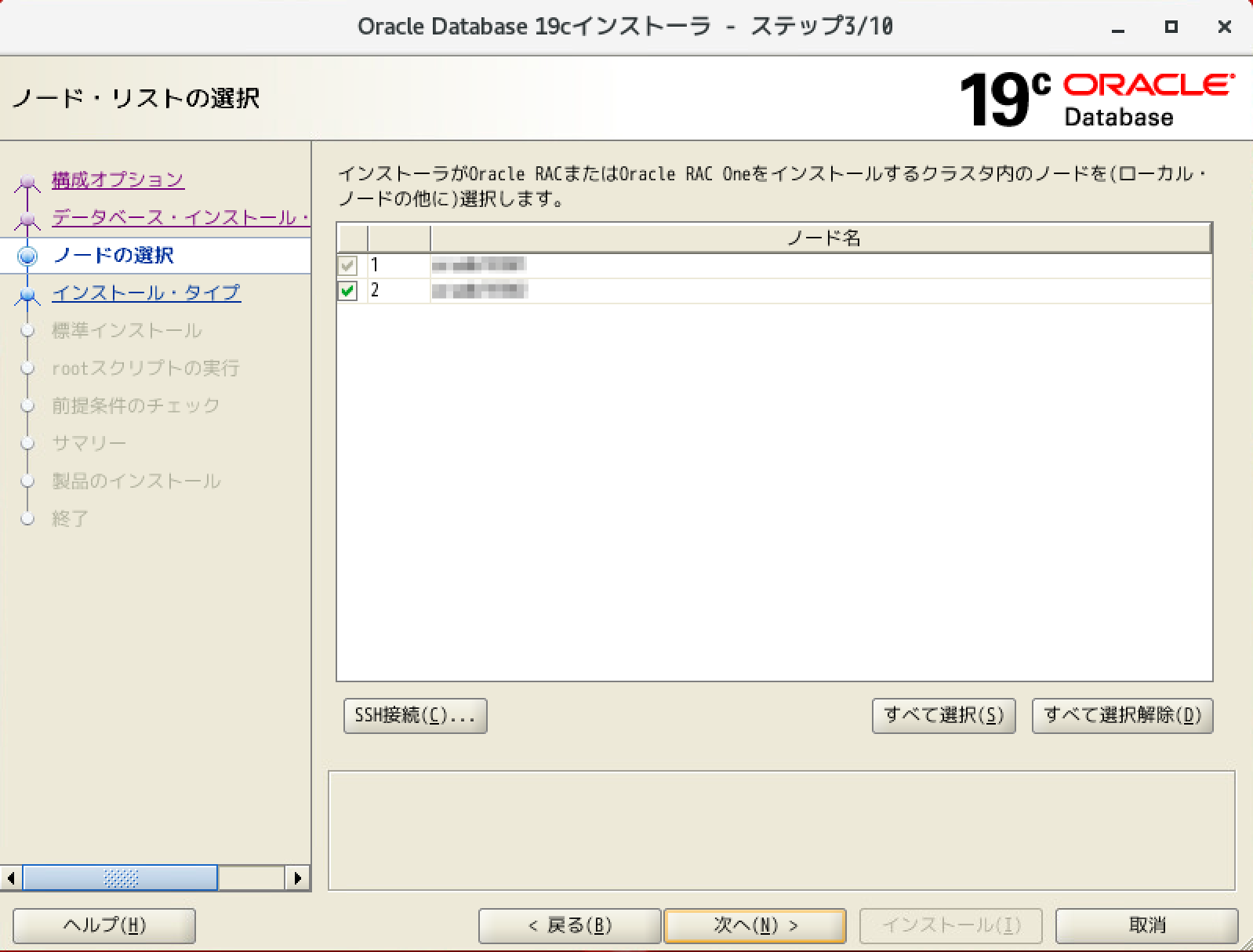
Gridのinstallまでは終了
https://qiita.com/junkers_rene/items/f656b1f980f4a4d0a703
1.Download the Oracle Database installation image files (db_home.zip) and extract the files into a new Oracle home directory.
[root@host01 ~]# sudo su - oracle
[oracle@host01 ~]$ mkdir -p /u01/app/oracle/product/19.3.0/dbhome_1
[oracle@host01 ~]$ ls -ld /u01/app/oracle/product/19.3.0/dbhome_1
drwxr-xr-x. 2 oracle oinstall 6 4月 29 10:45 /u01/app/oracle/product/19.3.0/dbhome_1
[oracle@host01 ~]$ cd /u01/app/oracle/product/19.3.0/dbhome_1
[oracle@host01 dbhome_1]$ unzip -q /tmp/LINUX.X64_193000_db_home.zip
[oracle@host01 dbhome_1]$
2.From the Oracle home directory, start the Oracle Database software installation:










[root@host01 ~]# /u01/app/oracle/product/19.3.0/dbhome_1/root.sh
Performing root user operation.
The following environment variables are set as:
ORACLE_OWNER= oracle
ORACLE_HOME= /u01/app/oracle/product/19.3.0/dbhome_1
Enter the full pathname of the local bin directory: [/usr/local/bin]:
The contents of "dbhome" have not changed. No need to overwrite.
The contents of "oraenv" have not changed. No need to overwrite.
The contents of "coraenv" have not changed. No need to overwrite.
Entries will be added to the /etc/oratab file as needed by
Database Configuration Assistant when a database is created
Finished running generic part of root script.
Now product-specific root actions will be performed.
[root@host01 ~]#
すんなりサクッと出来上がり。
3.ついでにDBCAでDB作ってみる

1)標準構成選んだ場合


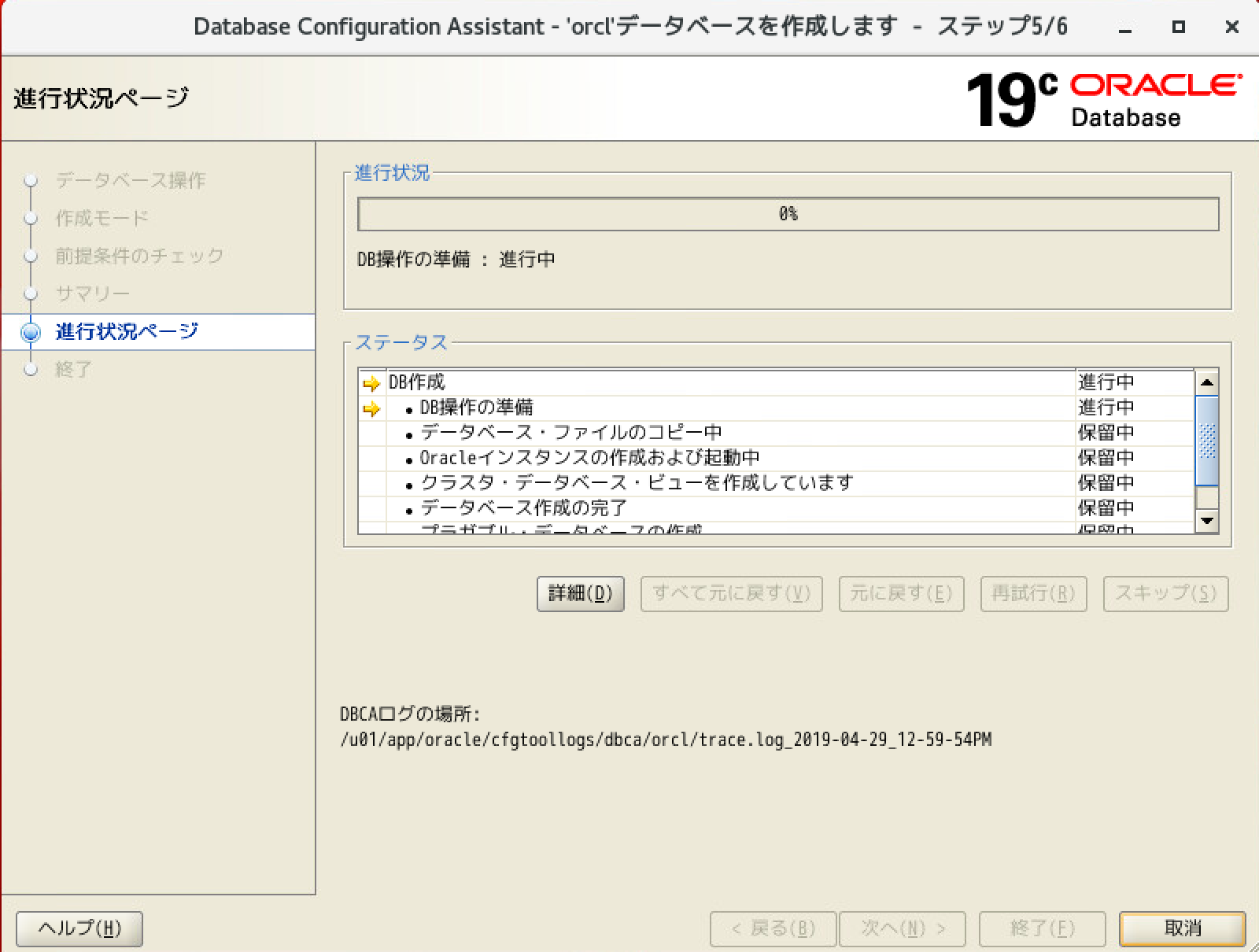

/u01/app/oracle/cfgtoollogs/dbca/orcl/trace.log_2019-04-29_12-59-54PM
[progressPage.flowWorker] [ 2019-04-29 13:53:16.968 JST ] [SQLEngine.setSpool:2132] old Spool = null
[progressPage.flowWorker] [ 2019-04-29 13:53:16.968 JST ] [SQLEngine.setSpool:2133] Setting Spool = /u01/app/oracle/cfgtoollogs/dbca/orcl/plugDatabase1R.log
[progressPage.flowWorker] [ 2019-04-29 13:53:16.968 JST ] [SQLEngine.setSpool:2134] Is spool appendable? --> true
[progressPage.flowWorker] [ 2019-04-29 13:53:16.968 JST ] [RestorationFactory.getRestorer:62] Performing pdb restore
[progressPage.flowWorker] [ 2019-04-29 13:53:16.968 JST ] [PluggableDatabaseSQLGenerator.getDefinitionText:140] convertClause= file_name_convert=NONE
[progressPage.flowWorker] [ 2019-04-29 13:57:06.735 JST ] [PlugDatabaseStep.executeImpl:300] Done with Create PDB
/u01/app/oracle/diag/rdbms/orcl/orcl1/trace/alert_orcl1.log
2019-04-29T14:07:03.755413+09:00
Resize operation completed for file# 3, old size 542720K, new size 563200K
2019-04-29T14:11:58.887589+09:00
Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl1/trace/orcl1_rms0_19039.trc (incident=12209) (PDBNAME=CDB$ROOT):
ORA-00240: control file enqueue held for more than 120 seconds
Incident details in: /u01/app/oracle/diag/rdbms/orcl/orcl1/incident/incdir_12209/orcl1_rms0_19039_i12209.trc
2019-04-29T14:13:29.756137+09:00
CKPT (ospid: 19052) waits for event 'enq: CF - contention' for 73 secs.
2019-04-29T14:13:29.756203+09:00
CKPT (ospid: 19052) is hung in an acceptable location (inwait 0x201.00).
2019-04-29T14:13:31.050891+09:00
minact-scn: got error during useg scan e:12751 usn:15
2019-04-29T14:14:11.482999+09:00
minact-scn: useg scan erroring out with error e:12751
2019-04-29T14:14:39.784477+09:00
CKPT (ospid: 19052) waits for event 'enq: CF - contention' for 143 secs.
2019-04-29T14:14:39.784564+09:00
CKPT (ospid: 19052) is hung in an acceptable location (inwait 0x201.00).
/u01/app/oracle/diag/rdbms/orcl/orcl1/trace/orcl1_rms0_19039.trc
*** 2019-04-29T14:11:58.922984+09:00
ORA-00240: control file enqueue held for more than 120 seconds
* pnp work: # new threads that need to be created = 0
*** 2019-04-29T14:19:09.046111+09:00 (CDB$ROOT(1))
* pnp work: no new public threads are needed
*** 2019-04-29T14:19:10.028245+09:00 (CDB$ROOT(1))
* pnp work: online undo count(*) = 2
2019-04-29 14:19:10.028 :
* pnp work: sent pnp go msg to 1
/u01/app/oracle/diag/rdbms/orcl/orcl1/incident/incdir_12209/orcl1_rms0_19039_i12209.trc
拡張時と同じプロセスが起動できなくてハング、メモリだけの問題じゃない?
2)拡張構成選んだ場合







 長い、、、ステップ多い
長い、、、ステップ多い
 そしてこんなところでエラー・・・???
そしてこんなところでエラー・・・???
 続行したら
続行したら
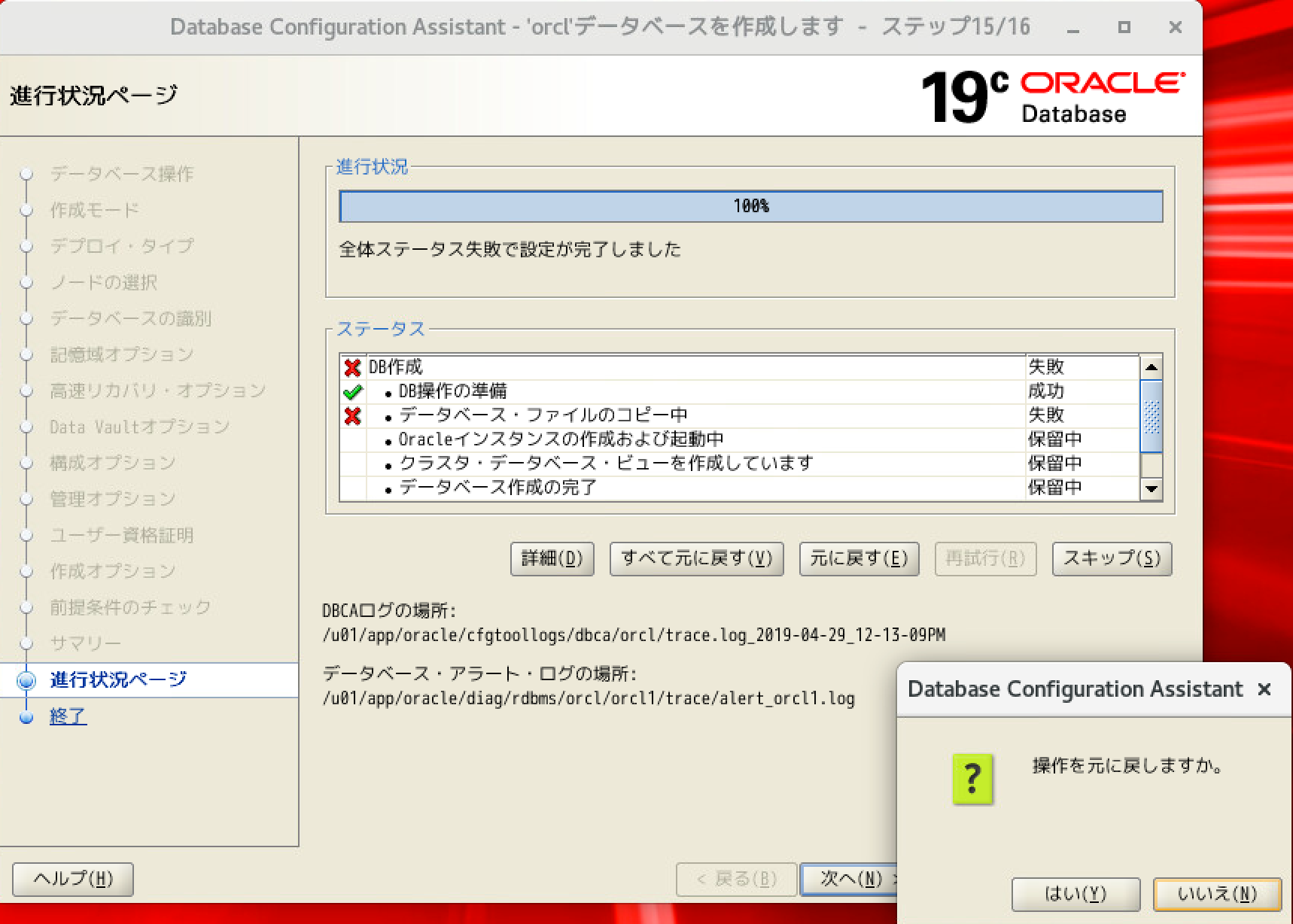 おちる。。。
おちる。。。
/u01/app/oracle/cfgtoollogs/dbca/orcl/trace.log_2019-04-29_12-13-09PM
[Thread-1632] [ 2019-04-29 12:39:02.656 JST ] [BasicStep.handleNonIgnorableError:542] ORA-00444: background process "RMS0" failed while starting
ORA-00610: Internal error code
:msg
WARNING: 4 29, 2019 12:39:02 午後 oracle.assistants.common.base.util.AssistantAdvisor logMessage
警告: [ 2019-04-29 12:39:02.656 JST ] [WARNING] ORA-00444: background process "RMS0" failed while starting
ORA-00610: Internal error code
[progressPage.flowWorker] [ 2019-04-29 12:41:05.301 JST ] [RmanRestoreDatafilesStep.executeImpl:89] update db alert log File
INFO: 4 29, 2019 12:41:05 午後 oracle.assistants.dbca.driver.StepDBCAJob$1 update
情報: Percentage Progress got for job:データベース・ファイルのコピー中 progress:7.0
SEVERE: 4 29, 2019 12:41:05 午後 oracle.assistants.common.base.util.AssistantAdvisor logMessage
重大: [ 2019-04-29 12:41:05.442 JST ] [FATAL] ORA-01034: ORACLE not available
[progressPage.flowWorker] [ 2019-04-29 12:41:53.162 JST ] [SQLEngine.done:2362] Done called
[progressPage.flowWorker] [ 2019-04-29 12:41:53.163 JST ] [SQLEngine.spoolOff:2208] Setting spool off = /u01/app/oracle/cfgtoollogs/dbca/orcl/CloneRmanRestore.log
[progressPage.flowWorker] [ 2019-04-29 12:41:53.164 JST ] [Host.updateDBAlertLogFile:12307] Could not retrieve the diag location.ORA-01034: ORACLE not available
/u01/app/oracle/diag/rdbms/orcl/orcl1/trace/alert_orcl1.log
Starting background process RMS0
2019-04-29T12:35:45.563383+09:00
* Load Monitor used for high load check
* New Low - High Load Threshold Range = [1920 - 2560]
2019-04-29T12:38:31.488439+09:00
Warning: VKTM detected a forward time drift.
Time drifts can result in unexpected behavior such as time-outs.
Please see the VKTM trace file for more details:
/u01/app/oracle/diag/rdbms/orcl/orcl1/trace/orcl1_vktm_6009.trc
2019-04-29T12:38:42.628870+09:00
Using default pga_aggregate_limit of 2048 MB
2019-04-29T12:38:54.441806+09:00
Errors in file /u01/app/oracle/diag/rdbms/orcl/orcl1/trace/orcl1_rms0_6059.trc:
ORA-00610: Internal error code
2019-04-29T12:38:56.319708+09:00
USER (ospid: ): terminating the instance due to ORA error
2019-04-29T12:38:58.193622+09:00
Instance terminated by USER, pid = 5881
/u01/app/oracle/diag/rdbms/orcl/orcl1/trace/orcl1_rms0_6059.trc
New process timed out
error 610 detected in background process
*** 2019-04-29T12:38:54.441615+09:00 (CDB$ROOT(1))
ORA-00610: Internal error code
/u01/app/oracle/diag/rdbms/orcl/orcl1/trace/orcl1_vktm_6009.trc
kstmmainvktm: succeeded in setting elevated priority
highres_enabled
VKTM running at (1)millisec precision with DBRM quantum (100)ms
[Start] HighResTick = 79947573758
kstmrmtickcnt = 0 : ksudbrmseccnt[0] = 1556508943
*** 2019-04-29T12:36:45.835622+09:00 (CDB$ROOT(1))
kstmchkdrift (kstmhighrestimecntkeeper:highres): Time jumped forward by (25774116)usec at (80001363092) whereas (1000000) is allowed
*** 2019-04-29T12:38:32.272060+09:00 (CDB$ROOT(1))
kstmchkdrift (kstmhighrestimecntkeeper:highres): Time jumped forward by (114961000)usec at (80116324092) whereas (1000000) is allowed
[root@host01 ~]# free
total used free shared buff/cache available
Mem: 8158988 3949564 138836 3033472 4070588 660344
Swap: 8257532 3387144 4870388
top - 13:18:24 up 22:55, 8 users, load average: 3.25, 3.10, 4.94
Tasks: 690 total, 2 running, 569 sleeping, 0 stopped, 0 zombie
%Cpu(s): 59.7 us, 6.4 sy, 0.0 ni, 3.5 id, 29.7 wa, 0.0 hi, 0.7 si, 0.0 st
KiB Mem : 8158988 total, 128272 free, 4400300 used, 3630416 buff/cache
KiB Swap: 8257532 total, 4897780 free, 3359752 used. 437064 avail Mem
[root@host01 ~]#
[root@host02 ~]# free
total used free shared buff/cache available
Mem: 8158988 3508940 365824 834544 4284224 3258208
Swap: 8257532 0 8257532
top - 13:18:42 up 1 day, 21:34, 5 users, load average: 0.67, 0.68, 0.75
Tasks: 435 total, 1 running, 320 sleeping, 0 stopped, 0 zombie
%Cpu(s): 16.5 us, 10.9 sy, 0.0 ni, 55.5 id, 16.8 wa, 0.0 hi, 0.3 si, 0.0 st
KiB Mem : 8158988 total, 292976 free, 3562080 used, 4303932 buff/cache
KiB Swap: 8257532 total, 8257532 free, 0 used. 3205304 avail Mem
[root@host02 ~]#
メモリ足りなくて、時間かかって落ちた?標準ならいける???
フリーがあるのに、使わずにswapを使っているのは、解放に時間がかかっているから?
トレースからは、バグっぽいものを記載を見たけど、18で回収済み。。。とりあえず、メモリ割り当て変えてOS再起動してリトライ
スパップは解放されてない
top - 18:48:42 up 1 day, 4:25, 7 users, load average: 1.44, 2.24, 1.84
Tasks: 678 total, 1 running, 559 sleeping, 0 stopped, 0 zombie
%Cpu(s): 7.8 us, 9.4 sy, 0.0 ni, 82.5 id, 0.2 wa, 0.0 hi, 0.2 si, 0.0 st
KiB Mem : 8158988 total, 377396 free, 4124852 used, 3656740 buff/cache
KiB Swap: 8257532 total, 5168492 free, 3089040 used. 1400904 avail Mem
MGMTDBが起動しているから、それの分か?どんだけ使うんだ
再起動直後
[root@host01 ~]# ps -ef | grep pmon
grid 9483 1 0 19:05 ? 00:00:00 asm_pmon_+ASM1
grid 11093 1 0 19:06 ? 00:00:00 mdb_pmon_-MGMTDB
oracle 11500 1 0 19:06 ? 00:00:00 ora_pmon_orcl1 << 上がってる
[root@host01 ~]# free
total used free shared buff/cache available
Mem: 12287764 3792728 1842512 4415580 6652524 3573052
Swap: 8257532 0 8257532
2019-04-29T19:07:49.872507+09:00
CJQ0 started with pid=81, OS id=18213
Completed: ALTER DATABASE OPEN /* db agent *//* {1:13432:2} */
2019-04-29T19:07:53.952733+09:00
ALTER SYSTEM SET _ipddb_enable=TRUE SCOPE=MEMORY SID='orcl1';
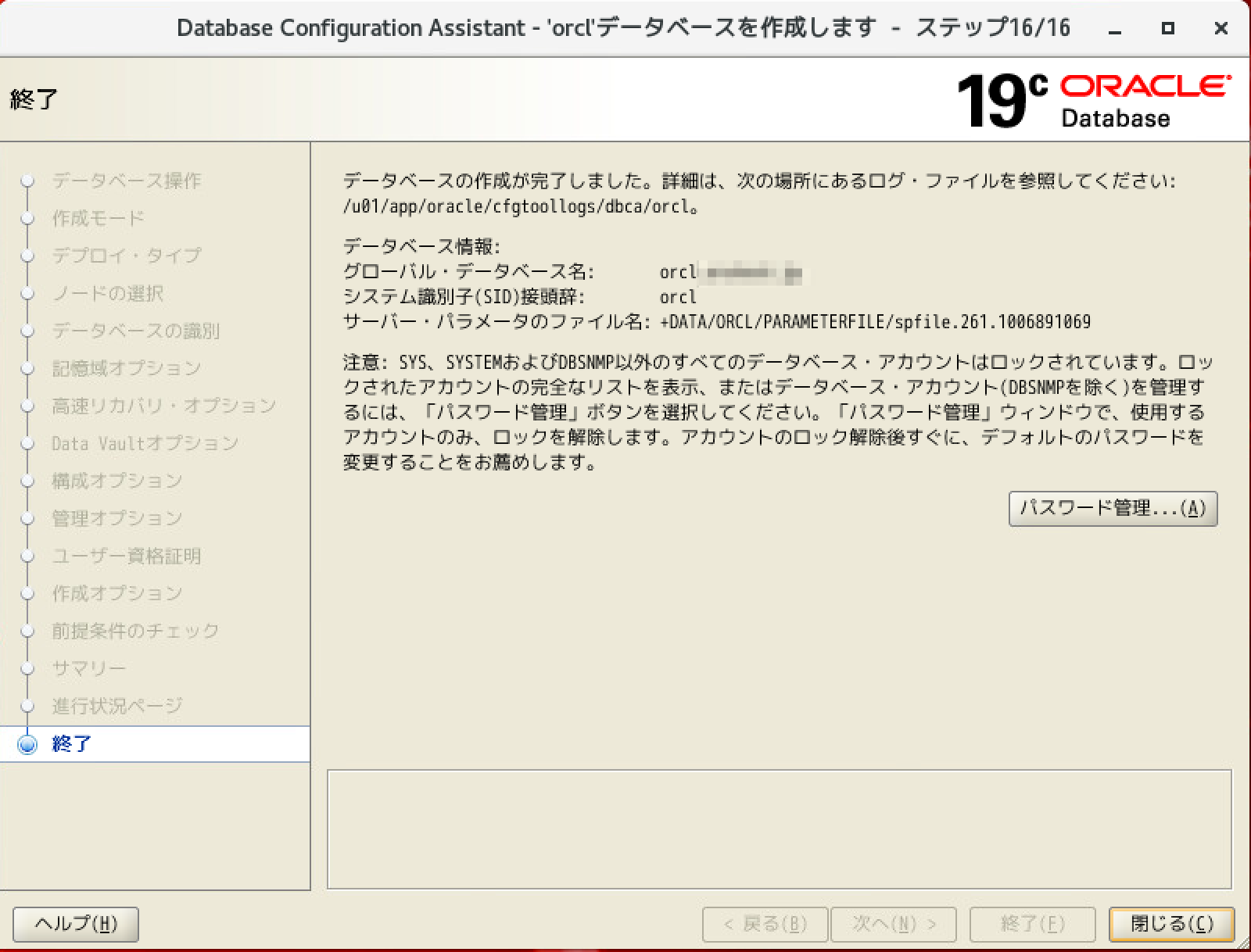 OS再起動して、メモリ増やしたら完了した。困った時は再起動だね
OS再起動して、メモリ増やしたら完了した。困った時は再起動だね
dbcaでDB作成直後
[root@host01 ~]# free
total used free shared buff/cache available
Mem: 12287764 4154124 837608 5661532 7296032 1945312
Swap: 8257532 12044 8245488