はじめに
Node.js公式の説明ページには以下のようにあります。
Node は(中略)非同期型のイベント駆動の JavaScript 環境です。(中略)各接続ごとにコールバックは発火され、(後略)
知らない人にどう動いているのか説明できるでしょうか。
ちなみに私は「超難しいからまずはイメージをつかんでくれ」と「仕事を他の人に頼む、すると自分は手が空くからその隙に別の仕事をする、頼んでた仕事が上がってきたら処理を再開する、的な感じ」と言ったもの、「(httpコールバックのプログラムについて)どう動いてるのかわからん」とのコメントをいただきました。「だから難しいからいきなり完全に理解しようとするんじゃねよ」と思ったわけですが、そりゃそうですね、「非同期」って言われてもまず「同期」とはなんなのかがわからないですし。
というわけで、今回はステップを踏んで「非同期型のイベント駆動」までを説明していこうと思います。
OS、システムコール、ファイル
どこから話始めるか。説明を聞く人の知識にもよりますが、「プログラミングやったことある」程度の人だとシステム寄りのプログラミングについて知っていることはまず期待できません。つまり、C言語ならprintfのその先がどうなっているかを知らないということです。
というわけでここから話を始めましょう。最低限、プログラミング言語で画面出力、ファイル入出力はしたことがある、標準入出力という言葉は知っているということにします。
普通プログラミング言語にはファイルを扱う機能が用意されています。ではその先はどうなっているのでしょうか。
ファイル管理はOSの仕事です。プログラムがファイルを開いて読んだり書いたりするためにはOSに「お願い」をする必要があります。この「お願い」をちゃんとした言葉で言うとシステムコールと言います。
どのようなシステムコールがあるかはOSにより変わりますがPOSIXに準拠したOSではファイル関連のシステムコールとして以下のものが用意されています。
- open:ファイルを開く。ファイルディスクリプタが返される
- read:ファイルから読み込む
- write:ファイルに書き込む
- close:ファイルを閉じる
openのみ、ファイルディスクリプタという言葉を書きましたが、read、write、closeこれ以外のシステムコールについてもこのファイルディスクリプタを使ってファイルへのアクセスが行われます。
C言語のfopen、fcloseに似てるなと思った方は鋭い。実はC言語のfopenはopenシステムコールを使って作られています。なんで直接open使わないの?ということについては、ファイルを開くシステムコールがopenじゃないOSもあるので移植性を考えてOSの一つ上に作られたのがC言語の標準ライブラリということになります。
POSIX
ところでしれっとPOSIXという言葉を使いましたがこれは何者でしょうか。POSIXは略さないで書くとPotable Operationing System Interfaceの略です。Xどこ行ったということについては、POSIXはUNIXの標準規格であるから、という意味でXが付いています。
ファイルという概念
実はUNIXでは「ファイル」という概念が非常に重要です。いつの間にか話の中心がUNIXになっていますがWindowsでもそこそこ似たことは可能なのでまあそこら辺は気にしないでください。
ともかく、UNIXではいろいろなものが「ファイル」として扱われます。このファイルはファイルディスクリプタで参照できることができ、readで読み込み、writeで書き込みが行えます。それがどういう意味を持つのかについては後からわかってくるのでそろそろ次の話題に移りましょう。
同期と非同期
Node.jsの説明を振り返りましょう、「非同期型の云々」。
非同期ってどういうことでしょうか。「同期に非ず」ということだが同期とは何なのでしょうか。まずは同期から始めましょう。
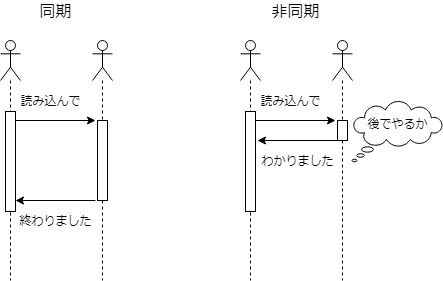
同期処理では「呼び出し側」が処理(プログラミング言語により言い方は変わりますが、いわゆる関数)を呼び出すと処理が終わるまで返ってきません。ファイル読み込みであればファイルの内容が読み取るまで返ってきません。
何を当たり前のことをと思われるかもしれませんが、この常識が通じなくなるのが非同期です。
非同期では処理を呼び出した場合、処理が終わる前に呼び出しから返ってきます。ファイル読み込みでは通常「読み込み結果はここに入れてね」というメモリ領域を渡しますが非同期呼び出しの場合、呼び出し直後に結果を参照しようとしても値が入っている保証はありません(運がいいと入っていることもあります)
ともかくこれが非同期です。図で書くとこんな感じです。UMLのシーケンス図っぽく書いてありますが一部正確なUML表記じゃないところがあるのはご容赦ください。
ポイントとなるのは非同期の「わかりました」と「後でやるか」です。つまり、指示を受けはしたけどそれを今すぐやり始めないということになります(他の仕事があるのかもしれません)
いくつか疑問がわいてくると思います。
- 何が便利なの?
- 結果はいつになったら入ってる保証があるの?
- そもそもなんでこんなことができるの?
一つずつ見ていきましょう。
非同期のメリット
まず大きなメリットして、非同期、というか呼び出してすぐに返ってこれば呼び出し側は別の処理が行えます。
行えるのは「別の」処理です。例えばファイルAを非同期で読み込んでおいてすぐにファイルAの内容を使うことはできません(まだ読み込まれていません)。できるのはファイルBを読み込む(ための非同期呼び出し)、ネットワーク通信(これも非同期でしょう)、はたまたたまっている別のHTTPリクエストかもしれません。ともかく、「ファイルAの内容を使う以外の処理」です。
「別の処理をやり出したら初めの処理が完了するの遅くならない?」と思われましたか?はい、それも正解です。多分、「一つのリクエスト処理」時間はちょっと長くなるでしょう。しかし、「ある時間(例えば一時間)でさばけたリクエストの処理」という視点で見ると同期で処理するよりも多くなるでしょう。このように一定時間でさばけた処理の量という視点をスループットと言います。非同期処理をするとスループットを向上させることができます。
非同期で結果を受け取る方法
さて次の疑問、結果が欲しくなったらどうするのかです。方法は二つあります。ポーリングとコールバックです。
ポーリングは処理が完了しているかちょいちょい確認しに行く方法です。確認タイミングをどうするかなどいろいろ問題点はありますがメリットとしてはコールバック的な機構がサポートされていない場合でも自力でプログラミングすることが可能ということです。
次に本題のコールバック。ようやく出てきましたね、コールバック。英語で書くとcallback、呼び戻しです。何を呼び戻すかと言うと、「頼まれてた仕事終わったよ、はいこれ」と結果を渡してくれるということになります。
HTTPサーバのコールバックの場合は「呼び戻し」じゃないけどまあいいや。ともかく、「非同期処理を呼んだ側」に呼ばれた側が値を渡す方法として用いられるのがコールバックです。
何故非同期できるのか、DMA
最後の疑問、何故非同期処理ができるのか、先に挙げた例で言うと何故ファイル読み込みをやりつつ別のこともできるのか。これを理解するための鍵が**DMA(Direct Memory Access)**です。
普通のパソコンでは(今どきならマイコンでも)CPU以外にディスクコントローラ、ネットワークコントローラなど様々なコントローラが載っておりそれらは独立して動作することができます。CPUは初めにメモリへの読み込み指示、メモリからの書き込み指示を出せば後は別の処理が行えます。これがDMAです。
同期の場合もDMAは使っていますが、指示を出した後プログラム的に終わるまで待っているのだと思います。
なお何故DMAという技術が開発されたかですが、I/O機器はCPUに比べると遅すぎるので待っていると無駄が大きすぎるためです。
ところでほんとに同期?
同期は処理が終わるまで待っていると書きましたが本当でしょうか。
実は、読み込みは多分大丈夫ですが書き込みは怪しいです。普通書き込みは「システムコールを発行して書き込みデータがOSのメモリ領域にコピーされたら」返ってきます。実際、Linuxのwriteのmanには「注意」のセクションに以下のように書かれています。
write() が成功して返ってきても、データがディスクに記録されたことを 保証するものではない。
確実に書き込むためにはfsyncをする必要があります。1
同期・非同期とブロッキング・ノンブロッキング
同期、非同期と合わせてよく使われる言葉としてブロッキング、ノンブロッキングがあります。この言葉は似ていますが違う概念です。私も調べるまで混同していましたが。
まずブロッキングと同期はほぼ同じと考えていいでしょう。ブロッキングとは「処理が止められる」ということです。
一方、ノンブロッキングは非同期とは限りません。ノンブロッキングは「処理が止められない」です。これだけだと当たり前ですがノンブロッキングは「処理がブロックしそうな場合はエラーを返す(止まらないようにする)」という動作をするようです。つまり、呼び出して戻ってきたらそのうち結果が入る or コールバックされるということはありません。
「処理が止められる」、「ブロックしそうだからエラー返す」ってどういう場合だ?という流れで次のソケットに話を進めます。
ソケット
ネットワーク通信を行うには通常ソケットというものが使われます。元々BSDで作られたものですがLinuxでもWindowsでもほぼ同じAPIでプログラミングでき、いわゆるデファクトスタンダードというAPIになっています。
ソケットはネットワーク通信、TCP/IP以外の通信にも使えますが以下ではTCP/IPを前提として話を進めます。
ソケットでは様々なAPIが定義されていますがとりあえずサーバを作るときに覚えるべきなのは次の4つです。
- socket:ソケットを作成する
- bind:ソケットにアドレスとポート番号を関連付ける
- listen:リクエストの受け付けを開始する
- accept:リクエストを一つ受け取る(クライアントと通信できるソケットが返される)
listenという単語出てきましたね。Node.jsのサンプルプログラム見て「listenって何(。´・ω・)?」と思いませんでしたか?listenはソケット由来の単語なんですね。
さてというわけでクライアントとの接続ができました。通信は?と思われていると思いますが実はこれ前に説明したreadとwriteのシステムコールでできます2。閉じるのはcloseシステムコールを使います。何故そんなことができるのかというとsocketシステムコールは「ファイルディスクリプタ」を返すからです。
これがファイルのところで書いた「UNIXではいろいろなファイルとして扱われる」という意味です。普通のファイルでもソケットでも「読む・書く」という操作は同じなのだから同じようにできるようにしようというわけですね。3
ソケットのブロックと対策
さて伏線張ったブロックについて。ソケットがファイル(毎回「普通のファイル」と書くのもめんどくさいので以降、「ファイル」と書きます)と同じように扱えると書きましたがソケットはファイルに比べるとブロックしやすいです。例えば以下のような場合にブロックします。
- acceptでクライアントからの接続取得しようとしたんだけど、誰も接続してないから待ち(ブロック)
- readでクライアントからのデータ読もうとしたんだけど送られてきてないから待ち(ブロック)
こういう場合にブロックしないようにするにはソケットをノンブロッキング(非同期ではありません!)に設定しておいてエラーが返ってきたら他のことをした後もう一度確認するというプログラムを作成します。
でもそれってめんどくさい。
本筋じゃないので簡単に説明しますがここで出てくるのがselectというシステムコールです。selectには複数のファイルディスクリプタを渡し、どのファイルディスクリプタが読み込み可能かを調べることができます。読み込み可能と判断されたファイルディスクリプタであれば実際にreadしてもブロックすることはありません。
マルチスレッドについて
少し話題を変えましょう。
Node.jsはシングルスレッドだからC10K問題が起きないと言われています。これもマルチスレッドとはなんなのか、何故マルチスレッドだとC10K問題が起きるのかを理解しないと言っている意味がわからないでしょう。
マルチスレッドは何に使われるのか
話をサーバに限定すると、「複数のクライアントを処理するため」です。シングルスレッドでは一度に一つのクライアントしか処理できません。「え?Node.jsは・・・」という人はちょっと待て。順番に説明するから。ともかく先ほど説明したacceptごとに処理スレッドを作ってクライアント処理を行うというのが古典的なマルチスレッドでのサーバ処理になります。4
関数の実行方法、ローカル変数
マルチスレッドを使う場合の問題点を理解するためには遠回りですが関数(C言語とかの関数)がどう実行されているのかを理解する必要があります。また、ローカル変数がどう実現されているかも理解する必要があります。説明できますか?
関数は別の関数を呼び出します。その関数はさらに別の関数を呼び出します。さて関数が終了したらどこに戻ればいいでしょうか。CPUのレベルまで話を下げると関数を終了する際には「メモリの某所」に書かれている戻りアドレスを次に実行する命令のアドレスとしてセットします。5
「メモリの某所」と書きましたが、実際には関数呼び出しごとに「ここに戻れ」という情報が積まれていきます。「積む」と聞いて連想された方がいるかもしれませんが情報はスタックに積まれます。通常、CPUにはスタックを管理するためのレジスタ(スタックポインタと呼ばれます)と命令が用意されています。それらを利用して呼び出し情報を積んでいきます。
呼び出し情報と書いたのはスタックには戻りアドレス以外に引数6の情報もあるからです。また、先ほど伏線しておいたローカル変数についてもここに領域が確保されます。このような関数を実行するのに必要な情報をスタックフレームと言います。また、関数呼び出し状況を示すスタックを特にコールスタックと言います。この言葉は聞いたことがある人もいるでしょう。
func1→func2→func3と関数呼び出しを行った場合のコールスタックは以下のようになります。呼び出しが終わるとfunc3→func2→func1とスタックが下ろされていきます(スタックポインタが調整される)

マルチスレッドはどう実行されるのか・何が問題なのか
さてここまでが前置き。ここからマルチスレッドの話です。
関数が実行される際にはスタックというメモリ領域にスタックフレームが積まれることがわかりました。このスタック用のメモリはスレッドごとに持つ必要があります。そうしないと別々のスレッドで同じ関数を実行することができません。
一つのスレッドに割り当てるスタック用メモリというのは結構難しい問題です。関数呼び出しが多いとスタックを溢れる危険があります。んー、スタック溢れについて説明してなかったけどまあなんとなくわかるでしょう(笑)
通常は一つのスレッドに多めに1Mとか2Mとか割り当てられます。まあ1Mとしておきましょう。
はい、ここで算数の時間です。1スレッド1Mかかる場合に1万のクライアントが一気に接続してきたらどうなるでしょう。
すぐ下に答え書くのもあれですが、スタック用に10Gのメモリが必要です。まあサーバ用に用意したマシンならそれぐらい積んでるかな、ってそういう問題ではありません。単純にメモリを大量に消費する以外の問題も発生します。
メモリはどうにかなったとしてもCPUのコアはしばらくは1万も用意できるわけはありません。つまり、1万スレッド作っても本当に一度に処理できるのはコアの数に限定されてしまいます。
スレッドプール
「大量にスレッド作るとメモリも食うしコア数以上同時実行できないし意味なくね?」と思ったからなのかなんなのか、これを解決する技術が作られました。スレッドプールと言います。
スレッドプールではまずスレッドをいくつか(通常、コア数分程度)作っておきます。
リクエストが来たら作ったスレッドに処理を割り当てます。次のリクエストが来たら手の空いてる別のスレッドに割り当てます。さらにリクエストが来て、手が空いているスレッドがいなかったらしばらく待たせます。窓口が複数ある店舗のイメージですね。このようにスレッドプールを使うことでメモリもそこまで食わずにコアを有効に使うことが可能になります。
「え?だったらスレッドプールでよくない?」となりますが、説明してない点が一つ。複数スレッドが資源(なんでもいいですがオブジェクトとしておきましょう)を共有しようとすると排他制御の問題が発生します。詳細は略しますが排他制御は往々にして厄介なバグの原因になります。シングルスレッドならそんなことは起こりません。だって他にスレッドいないから。
というわけでようやくこれでNode.jsの動作を説明するための知識を説明し終わりました。それではNode.jsの実装をちょっと見てみましょう。
Node.jsの実装に踏み込む
Node.jsの実装についてはこちらの記事が参考になります。
内部実装から読み解くNode.js Eventloop
Node.jsのコアはlibuvというライブラリを使って非同期I/Oを行っているようです。
どう動いているのか読んでみた
ご存知かと思いますが私の本職はコードリーダーです(?)。というわけで、「へーlibuv使ってイベントループ実行してるんだー」なんてところでは終わりません。ここから先はガチです。
と言っても全部の処理を詳細に見ていくのは読む方も書く方も辛いので、流れを追いかけるのみにします。
読解のエントリーポイントは以下。引数は適当です。readFileじゃないのはreadFileはwriteFileに比べて少しややこしいためです。
fs.writeFile('hello.txt', 'Hello, World', (err) => {});
Javascriptの世界:lib/fs.js
fsモジュールのwriteFileの実装はlib/fs.jsにあります。
はい、ここでストップ。writeの実装には怪しげなものが登場します。
return binding.writeString(fd, buffer, offset, length, req);
bindingの正体を探すと上の方に書いてあります。
const binding = process.binding('fs');
Node.jsのドキュメント見てもprocessオブジェクトにbindingメソッドの説明なんてありません。ここからはもう非公開APIの世界です。というか、ここで取得しているのはfsのC++実装部分です。
C++の世界:src/node_file.cc
そこに至るまでの経緯を省略すると、ともかくwriteStringに対して呼び出されるのはC++のWriteString関数です。
特にこの部分に注目。
int err = uv_fs_write(env->event_loop(),
req_wrap->req(),
fd,
&uvbuf,
1,
pos,
After);
libuv呼び出していますね。いい感じです。ちなみに最後の引数のAfterは書き込み後に呼び出されてコールバック呼び出しを行っています。
libuvの世界:deps/uv
ここから先はかなり難解になってきます。
( ゚д゚)え?
(つд⊂)ゴシゴシ
threadpool.c
(;゚д゚)
スレッドプール使ってるじゃねえか!
あ…ありのまま 今 起こった事を話すぜ!
「おれは シングルスレッドで非同期する仕組みを見ていたと思ったら
いつのまにか同期処理をスレッドプールで多重化する仕組みを見ていた」
な… 何を言ってるのか わからねーと思うが
おれも何をされたのかわからなかった…
頭がどうにかなりそうだった…
催眠術だとか超スピードだとか
そんなチャチなもんじゃあ 断じてねえ
もっと恐ろしいものの片鱗を味わったぜ…
というわけで、libuvは非同期を実現するための方法としてスレッドプールを使っているようです。
このことはちゃんとlibuvのDesign Overviewに書かれています。
Unlike network I/O, there are no platform-specific file I/O primitives libuv could rely on, so the current approach is to run blocking file I/O operations in a thread pool.
ネットワーク通信は本当に(?)非同期でやっているようです。
実装読解まとめ
というわけで理論ばかりだとあれなので実際にNode.jsがどう非同期を実現しているか見てきました。まさかの展開になりましたが(読みながら非同期I/Oしてなそうなんだけど、と悩んでた)
ここで一つ誤解があるといけないので補足しておきます。
Node.jsのファイルI/Oは非同期を実現するためにスレッドを使っていましたがそれはNode.jsの謳う「シングルスレッドで非同期」を崩すものではありません。内部実装はあくまで内部実装。Node.jsを使う側(普通のNode.jsプログラマ)はマルチスレッドに関する排他制御に悩まされることなく非同期プログラムを作成できるということになります。
おわりに
では最後に全体のまとめ。この記事ではいろいろなことを説明してきました。ちょっと書き出してみましょう。
- システムコール
- 広い意味でのファイル
- 同期と非同期
- ブロッキングとノンブロッキング
- ソケット
- スタックフレーム
- マルチスレッド、特にメモリ消費について
- スレッドプール
うーん、多いですね。Node.jsはどのような特徴があってそれは他と比べてどのような利点があるのかを説明するにはこれだけの要素技術が必要なのですね。
書籍案内
上記のようなことは何を読んだら身につくのか、ということで数冊書籍を紹介します。
ふつうのLinuxプログラミング 第2版
素晴らしい書籍を書くことに定評のある青木峰郎さんによるLinuxプログラミング本です。システムコールに関する基本的な内容が説明されています。逆に非同期だとかマルチスレッドには話が及んでいません。これはそもそも「次のステップとしてそこら辺が理解できるようになる本」なので本自体に罪はありません。
詳解 Linuxカーネル 第3版
OSの中身がどうなっているかを説明した本。「広い意味でのファイル」とかスレッドの切り替えコストみたいな概念を学ぶのに大変参考なりました(私が読んだのは第2版ですが)
低レベルプログラミング
システムコールやOSの中身と言うよりは、よりCPUに近いレベルの話が書かれている本です。スタックフレームとか。最終章にマルチスレッドの話題も載っています。