1.はじめに
現在(3/4〜*3/31)、Neural Network Console Challengeという企業データを用いてディープラーニングに挑戦するAI開発コンテストが開催されています。
今回のテーマは、Neural Network Console を用いたPIXTAの写真素材の人物画像 10,000枚の分類ということで、応募テーマは「オノマトペ分類」、「画角/焦点距離分類」、「感情分類」、「自由設定」の4つです。
2017年の Neural Network Console の発表をきっかけに、ディープラーニングを始めた私としては、懐かしい古巣に帰った様な気持ちになり、何はともあれ参加してみることにしました。
*学習用データ提供:PIXTA
2.テーマ設定
人物画像といえば、「友人」、「恋人」、「家族」、「学生」、「ウエディング」、「夫婦」など様々なカテゴリーがあります。
様々なカテゴリーの中で、写真に写って人物が、1人なのか、2人なのか、グループ(3人以上)なのかで、写真が伝える意味合いは結構違ってくる様に思います。
ということで、今回私が選ぶテーマは、様々なカテゴリーの画像に写っている人数で分類することにします。
なお、Neural Network Console には、Windows版 と Cloud版の2種類がありますが、今回はデータセット作成までを windows版で、それ以後はCloud版でやっています。
3.アノテーション
ディープラーニングを行う時にかなりの労力を使うのがアノテーション(画像への注釈付与)ですが、今回は人数による分類なので複雑ではなくて、正解ラベルを「0」,「1」,「2」,「3」と4つ作るだけです。
手とか下半身とか顔が全く写っていないものは「0」、一人しか写っていないものは「1」、二人写っているものは「2」、三人以上写っているものは「3」とします。

具体的な作業は、フォルダーを「0」,「1」,「2」,「3」と4つ作り、画像データを見て適切なフォルダーにドラック&ドロップすることを、ひたすら繰り返すだけです。
結果、「0」が169枚、「1」が4,687枚、「2」が2,394枚、「3」が2,754枚、計10,004枚。元データが10,000枚なのに4枚増えているのは、ドラッグ&ドロップ作業の時に、間違えてコピーしたのではないかと思いますが、確認はしていません。
さすがに、10,000枚を処理するには、丸一日掛かりました。お疲れ様でした。
4.データセットの作成
画像をフォルダー分類してしまえば後の処理はとても楽です。+Create Dataset 一発でデータセットの作成が行えます。
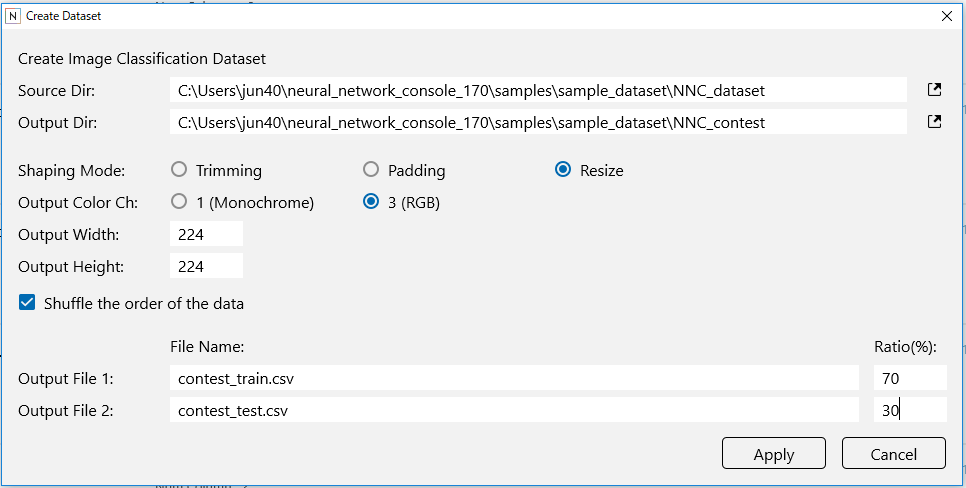
フォルダー分けしたディレクトリーをSource Dir: に、データセットを出力したいディレクトリーをOutput Dir:に入力します。
Resizeを選択すれば、全ての画像を Output Width: と Output Hight: に設定したサイズに変換してくれます。今回は、カラー224×224サイズの画像に統一しています。
Output File1:には学習ファイル名、Output File2:にはテストファイル名、Ratio(%)には、学習データとテストデータの比率を設定します。今回の学習:テスト比率は70:30です。
後は、Applyボタンを押すだけ。自動的に、Neural Network Console が読めるデータセットが完成します。
完成したデータセットは、Neural Network Console の Cloud 版にある Upload Datasetで、アップロードしておきます。
5.ネットワーク設計
人物の検出は通常、SSDかYOLOを使うのが一般的ですが、Neural Network Consoleでこれらを設計するのは難しそうだったので、一般的なCNNでやってみることにしました。
ベースモデルは2014年に発表されたVGG16(懐かしい!)とし、各層のフィルター数を半分にスケールダウンさせ適正な規模にしつつ、Convolution の各層には BatchNormal を挟んでブラッシュアップしたものをネットワークとして使います。

Neural Network Console のネットワーク設計はとても楽チンです。特に、今回の様な単純なCNNなら、C (Convolution), B (BatchNormalization), R (ReLU)の3つをセットにしてコピペし、時々間にM (MaxPooling)を挟んで線を繋ぐだけ。Webながら、操作は軽快に動きますので、3分あればOKです。
しかも、I (input)の入力シェイプ、C (Convolution)のフィルター数、A (Affine)の出力数あたりを決めてあげれば、他のパラメータは自動的に設定されるので、ミスも起こり難いです。
6.学習環境
最初は、ちゃんと動くのか確認するために、先程説明したネットワークの1/4くらいのモデルでやってみたのですが、CPUだけではとても重く、1epochあたり10分くらいかかりました。このままでは、本格モデルでやると 1epochあたり40分と、とても実用になりそうもありません。
そうした中、ありがたいことに、今回のコンテストでは参加者は申請すると10,000円分のGPU利用枠が貰えるということで、早速メールで NNC-Challenge事務局 (nnc-challenge@ledge.co.jp)へ NNC IDと氏名を記載して申請し、自分の使っている Cloud にGPU利用枠を付与して貰いました。
ちなみに、SONYさんのGPUの利用料金は、
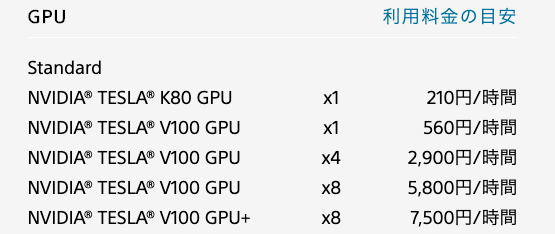
うおーっ!これで、K80が丸2日間無料で使えるぞ!
7.学習結果
それでは、早速GPUを使って学習させてみます。
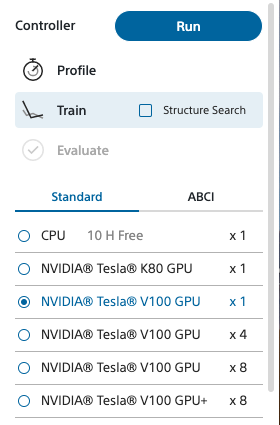
GPUで動かすには、自分が使いたいGPUのラジオボタンを選択するだけです。後は、何も変更がいりません。
本当は、K80がリーズナブルなのですが、メモリ不足でエラーが出てしまったので、V100で実行しました。
それでは、学習完了後のTRAINING タブを見てみましょう。

なんと200epochが1時間半で完了しました(27秒/epoch ! )。爆速です。これがもし、CPUだったら33時間くらい掛かってしまいます。ディープラーニングを本格的にやろうと思ったら、GPUは必須ですね。
ロス推移グラフを見ると、100 epochくらいで Validation Error の減少は打ち止めとなります。それ以後は Training Error が減少するにも関わらず Validation Error は上昇傾向となり、いわゆる過学習に陥っています。
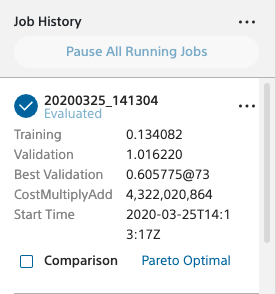
一番Validation Error が小さかった(Best Validation) のは0.605775 (73epoch時)でした。
続いて、EVALUATION タブ を見てみます。
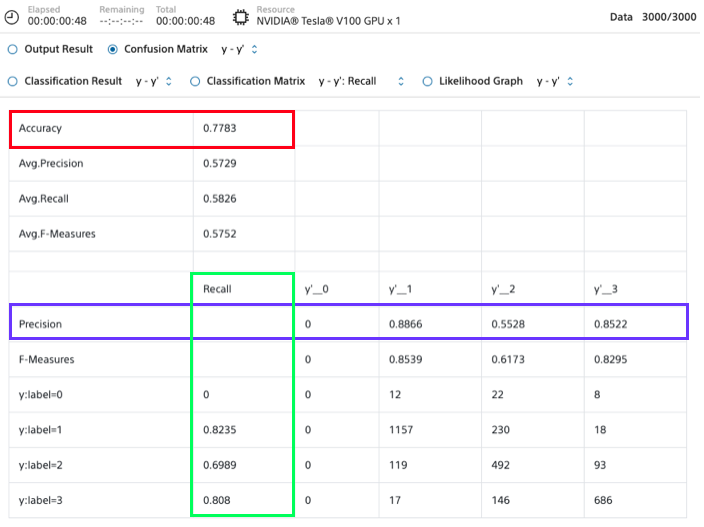
Accuracy(精度)は 77.83% ともう一歩です。Precison(予測したものが当たっているか)を見ると、y'_2が55.28%と低く、y’_0はなんと0%。Recall(当たりを予測できているか)を見ると、y:label=2が69.89%と低く、y:label=0はなんと0%。
つまり、「0」は全く「0」として認識されておらず、「2」は「1」や「3」に間違えられることが割とあるという結果でした。
8.推論結果の考察
EVALUATION タブの Classification Result を見ると、正解ラベルがどういうラベルに間違えたかが分かりますので、前述の正解ラベル「0」と「2」を何に間違えたかをチェックしてみます。
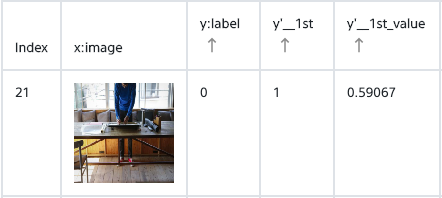
y:labelは正解ラベル、y'_1stはネットワークが判断したラベル、y'_1st_value はネットワークの判断確率を表しています。この場合、正解ラベルは「0」なのに、ネットワークは「1」に59.067%の自信で間違えたということです。
なるほど。顔が写っていないので、私は正解ラベルを「0」としたわけですが、ネットワークは「1」と判断したわけですね。

これも同様です。上部からの写真で全員顔が写っていないので、私は「0」としたわけですが。。。どうも、ネットワークの判断を是とした方が良いのかもしれませんね(笑)。
今度は、「2」を間違えた例です。

うーん。前の二人にピントが合っていて、後ろは少しボケていたので私は「2」としたのですが、「3」といえば確かに「3」ですね。

2人並んで水槽を見ていたので、「2」としましたが、2人がちょっと重なりすぎていましたね。

ただ、この写真の様に、明らかに「2」なのに「3」に間違える例もあります。これは全体的に言えることですが、背景が込み入っている場合、なぜか人数をプラス1してしまう傾向がある様に思います。込み入った背景を人物と間違えているかもしれません。

これは、どう見ても「1」ですが、ネットワークはなぜか「2」と判断します。他にも同様な例があり、どうも背景のロゴが影響している様な気がします。
9.まとめ
今回のチャレンジで、単純なCNNでも、画像の人数分類が割とできることが分かりました。多分、調整を加えれば、精度80%以上は行くと思います。
通常は、推論結果の考察を元に、アノテーションやネットワークの見直しを行い、さらにシステムのパフォーマンスを向上させるのことを繰り返すのが常道ですが、今回は時間の関係でここまでとします。
久しぶりにNeural Network Console の Cloud版を使ってみましたが、推論後の評価結果が様々な角度で提供されること、ワンタッチでGPUが利用できること、などの部分で以前より大幅に進化しており、実用性が大いにある様に感じました。特に、画像分類タスクにおいておすすめです。