1.はじめに
機械学習を勉強し始めたので、なにはともあれ Kaggleの初心者向けチュートリアル、タイタニックにトライしてみました。
最初は、日本語のWeb情報を参考に、自分なりに特徴量を色々いじってみたわけですが、学習データでは良い精度が出ても、テストデータをSubmitすると、思った様に精度は上がらず、なかなか80%の壁を破れず悶々としていました。
そうした中で、英文なので取っ付き難いですが、Kaggle/TaitanicのNotebookにある先人の知恵を拝借して、やっと上位2%に入れたので、特に参考になった点を中心に備忘録として残します。
では、コードに沿って説明して行きます。
1.データの読み込み
まず、データセットを読み込みます。trainとtestを別々に扱うと、2回同じ処理をする必要があるので、合体させdfとします。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# データセットの読み込み
train_data = pd.read_csv('./train.csv')
test_data = pd.read_csv('./test.csv')
# train_dataとtest_dataの連結
test_data['Survived'] = np.nan
df = pd.concat([train_data, test_data], ignore_index=True, sort=False)
# dfの情報
df.info()
# Sexと生存率の関係
sns.barplot(x='Sex', y='Survived', data=df, palette='Set3')
plt.show()
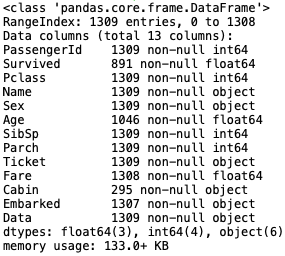
dfは、13項目×1309行です。欠損値は、Age:1309-1046=263個、Fare:1309-1308=1個、Cabin:1309-295=1014個、Embarked:1309-1307=2個です。
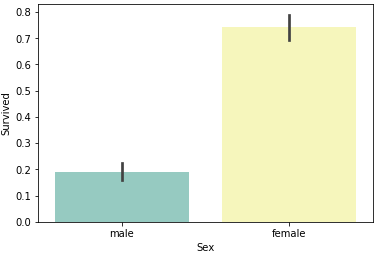
男性と女性の生存率を確認すると、圧倒的に女性の生存率が高いです。
2.Ageの欠損値補完
私は、最初、敬称と年齢の関係があるので、敬称別平均年齢で補完しました。しかし、何故か、この特徴量を使うと逆に精度は落ちてしまうので、特徴量には採用しませんでした。多分、年齢にバラツキがある敬称が悪さをするんだと思います。
Notebookでは、欠損値がない完全なデータ(Pclass, Sex, SibSp, Parch)を使って、ランダムフォレストでAgeの欠損値を推定している人が居ました。
私も最初からこの発想は持っていたんですが、まさかそこまでやらなくても良いだろうと思っていました。しかし、間違いでした。これ効きます。
# ------------ Age ------------
# Age を Pclass, Sex, Parch, SibSp からランダムフォレストで推定
from sklearn.ensemble import RandomForestRegressor
# 推定に使用する項目を指定
age_df = df[['Age', 'Pclass','Sex','Parch','SibSp']]
# ラベル特徴量をワンホットエンコーディング
age_df=pd.get_dummies(age_df)
# 学習データとテストデータに分離し、numpyに変換
known_age = age_df[age_df.Age.notnull()].values
unknown_age = age_df[age_df.Age.isnull()].values
# 学習データをX, yに分離
X = known_age[:, 1:]
y = known_age[:, 0]
# ランダムフォレストで推定モデルを構築
rfr = RandomForestRegressor(random_state=0, n_estimators=100, n_jobs=-1)
rfr.fit(X, y)
# 推定モデルを使って、テストデータのAgeを予測し、補完
predictedAges = rfr.predict(unknown_age[:, 1::])
df.loc[(df.Age.isnull()), 'Age'] = predictedAges
# 年齢別生存曲線と死亡曲線
facet = sns.FacetGrid(df[0:890], hue="Survived",aspect=2)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, df.loc[0:890,'Age'].max()))
facet.add_legend()
plt.show()
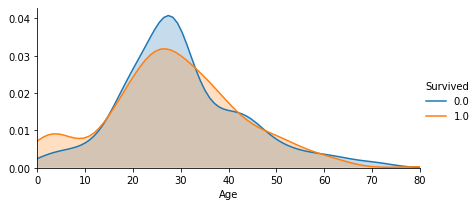
Ageの欠損値補完をした結果、年齢別の生存曲線と死亡曲線を描かせると、生存のピークは10才未満、死亡のピークは20代後半と言ったところでしょうか。
3.Nameから新たな特徴量を作り出す
私も、最初から、**Nameから敬称を取り出して特徴量にしていました。**そして、確かにこれは精度向上に寄与(抜くと精度が下がる)していました。
# ------------ Name --------------
# Nameから敬称(Title)を抽出し、グルーピング
df['Title'] = df['Name'].map(lambda x: x.split(', ')[1].split('. ')[0])
df['Title'].replace(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer', inplace=True)
df['Title'].replace(['Don', 'Sir', 'the Countess', 'Lady', 'Dona'], 'Royalty', inplace=True)
df['Title'].replace(['Mme', 'Ms'], 'Mrs', inplace=True)
df['Title'].replace(['Mlle'], 'Miss', inplace=True)
df['Title'].replace(['Jonkheer'], 'Master', inplace=True)
sns.barplot(x='Title', y='Survived', data=df, palette='Set3')
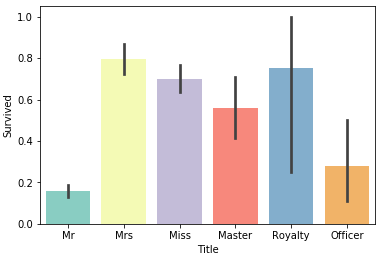
敬称別の生存率を見ると、Mrの生存率が最も低く、Mrsの生存率が最も高いことが分かります。
さて、Notebookでは、これに加えて、Nameから苗字を取り出し、同じ苗字が複数人いるグループに注目する人がいました。
つまり、家族がいた場合、運命を共にする傾向があるのではないかと言う視点です。
# ------------ Surname ------------
# NameからSurname(苗字)を抽出
df['Surname'] = df['Name'].map(lambda name:name.split(',')[0].strip())
# 同じSurname(苗字)の出現頻度をカウント(出現回数が2以上なら家族)
df['FamilyGroup'] = df['Surname'].map(df['Surname'].value_counts())
そして、その家族を、16才以下または女性というグループ(俗に言う、女子供)と、16才を超えかつ男性というグループに分けて生存率を見ると興味深い事実が見えて来ます。
# 家族で16才以下または女性の生存率
Female_Child_Group=df.loc[(df['FamilyGroup']>=2) & ((df['Age']<=16) | (df['Sex']=='female'))]
Female_Child_Group=Female_Child_Group.groupby('Surname')['Survived'].mean()
print(Female_Child_Group.value_counts())

16才以下または女性のグループは、113グループと多くが生存率100%な一方で、32グループに限っては生存率0%です。つまり、多くのグループは全員生存しているのに、一部のグループだけ全滅なのです。
# 家族で16才超えかつ男性の生存率
Male_Adult_Group=df.loc[(df['FamilyGroup']>=2) & (df['Age']>16) & (df['Sex']=='male')]
Male_Adult_List=Male_Adult_Group.groupby('Surname')['Survived'].mean()
print(Male_Adult_List.value_counts())

16才を超えかつ男性のグループは、115グループと多くが生存率0%な一方で、21グループに限っては生存率100%です。つまり、多くのグループは全滅なのに、一部のグループだけ全員生存しているのです。
これらの事実から得られる価値ある情報は、全体の流れとは逆の運命を辿った少数派が居ることです。この少数派の情報を元に、下記の対応を行います。
# デッドリストとサバイブリストの作成
Dead_list=set(Female_Child_Group[Female_Child_Group.apply(lambda x:x==0)].index)
Survived_list=set(Male_Adult_List[Male_Adult_List.apply(lambda x:x==1)].index)
# デッドリストとサバイブリストの表示
print('Dead_list = ', Dead_list)
print('Survived_list = ', Survived_list)
# デッドリストとサバイブリストをSex, Age, Title に反映させる
df.loc[(df['Survived'].isnull()) & (df['Surname'].apply(lambda x:x in Dead_list)),\
['Sex','Age','Title']] = ['male',28.0,'Mr']
df.loc[(df['Survived'].isnull()) & (df['Surname'].apply(lambda x:x in Survived_list)),\
['Sex','Age','Title']] = ['female',5.0,'Mrs']

これは、学習データから、16才以下または女性のグループで全員死んだ苗字を集めたデッドリスト(Dead_list)と、16才を超えかつ男性のグループで全員生存した苗字を集めたサバイブリスト(Survived_list)です。これを、テストデータに反映させます。
具体的には、テストデータの中で、デッドリストに該当した行がある場合は、必ず死亡と判断されるように Sex, Age, Titleを典型的な死亡データに書き換え、サバイブリストに該当した行がある場合は、必ず生存と判断されるように Sex, Age, Titleを典型的な生存データに書き換えます。
ちょっとトリッキーな方法にも思えますが、推定モデルが単純で済むので、逆にスマートな方法だと思います。さすが、先人の知恵です。
4.Fareの欠損値の補完
運賃は、乗船する場所(Emabarked)とクラス(Pclass)と関係があるだろうと言うことで、欠損値の設定(Embarked=S, Pclass=3)からFareのメジアンを取って補完しています。これは特に問題ないでしょう。
# ----------- Fare -------------
# 欠損値を Embarked='S', Pclass=3 の平均値で補完
fare=df.loc[(df['Embarked'] == 'S') & (df['Pclass'] == 3), 'Fare'].median()
df['Fare']=df['Fare'].fillna(fare)
5.SibSpとParchから特徴量を作る
SibSpはタイタニックに同乗している兄弟や配偶者の数、Parchはタイタニックに同乗している親や子供の数。独立で特徴量とするより、合計してFamilyにした方が特徴量としては優れています。生存率でグルーピングしています。これも特に問題ないでしょう。
# ----------- Family -------------
# Family = SibSp + Parch + 1 を特徴量とし、グルーピング
df['Family']=df['SibSp']+df['Parch']+1
df.loc[(df['Family']>=2) & (df['Family']<=4), 'Family_label'] = 2
df.loc[(df['Family']>=5) & (df['Family']<=7) | (df['Family']==1), 'Family_label'] = 1 # == に注意
df.loc[(df['Family']>=8), 'Family_label'] = 0
6.Ticketから意味のある特徴量を取り出す
最初は、何の理屈もなしに、Ticketナンバーの先頭文字で特徴量を作っていました。案の定、この特徴量は、使うと逆に精度が落ちてしまうので、特徴量には採用しませんでした。やっぱり、理屈も無いのに特徴量にするのは得策ではないようです。
Notebookでは、Ticketナンバーが同じ人が何人いるかで特徴量を作っている人がいました。なるほど、それなら理屈が分かります。Ticketナンバーが同じ人は、多分同じ部屋に居て運命を共にし易いし、人数によって生存のしやすさも変わるということでしょう。
以下は、Ticketナンバーが同じ人数別の生存率のグラフです。
# ----------- Ticket ----------------
# 同一Ticketナンバーの人が何人いるかを特徴量として抽出
Ticket_Count = dict(df['Ticket'].value_counts())
df['TicketGroup'] = df['Ticket'].map(Ticket_Count)
sns.barplot(x='TicketGroup', y='Survived', data=df, palette='Set3')
plt.show()
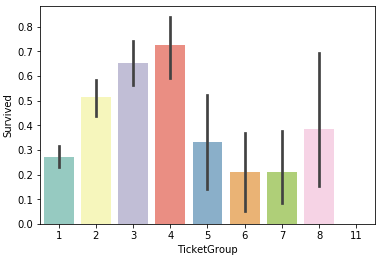
人数が2〜4人の生存率が高く、5〜8人と1人の生存率が中位、11人の生存率はゼロです。従って、3つにグルーピングします。
# 生存率で3つにグルーピング
df.loc[(df['TicketGroup']>=2) & (df['TicketGroup']<=4), 'Ticket_label'] = 2
df.loc[(df['TicketGroup']>=5) & (df['TicketGroup']<=8) | (df['TicketGroup']==1), 'Ticket_label'] = 1
df.loc[(df['TicketGroup']>=11), 'Ticket_label'] = 0
sns.barplot(x='Ticket_label', y='Survived', data=df, palette='Set3')
plt.show()
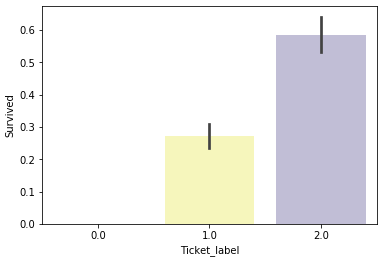
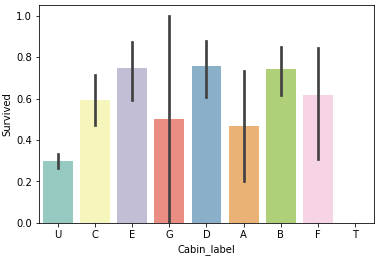
7.Cabin
欠損値が多いですが、欠損値 U の生存率が明らかに低いので、欠損値補完は特にしません。これも特に問題ないでしょう。
# ------------- Cabin ----------------
# Cabinの先頭文字を特徴量とする(欠損値は U )
df['Cabin'] = df['Cabin'].fillna('Unknown')
df['Cabin_label']=df['Cabin'].str.get(0)
sns.barplot(x='Cabin_label', y='Survived', data=df, palette='Set3')
plt.show()
8.Embarked
欠損値は一番乗船者が多かったSで補完。これも問題ないでしょう。
# ---------- Embarked ---------------
# 欠損値をSで補完
df['Embarked'] = df['Embarked'].fillna('S')
9.前処理
ランダムフォレストで推定モデルを作るための前処理です。ラベル特徴量をワンホットエンコーディングすることでラベルの特徴量を分解することが出来ます。
例えば、Embarkedの内容は、C, Q, S の3つのラベルから成っています。これにワンホットエンコーディングを掛けると、自動的に、Embarked_C, Embarked_Q, Embarked_S の3つの項目が作られ、3つの項目の内どれか一つだけ1で残りは0という表現に変わります。
こうすることで、Embarked_C,Embarked_S は特徴量として採用するが、Embarked_Q は過学習になるので採用しないという様な、細やかな過学習防止策が取れるわけです。
これは、Notebookで初めて知ったことで、ワンホットエンコーディングによる特徴量の分解は、様々な特徴量を見つけ出した後に、必要なものだけを選択する際の強力な武器になると思いました。
# ------------- 前処理 ---------------
# 推定に使用する項目を指定
df = df[['Survived','Pclass','Sex','Age','Fare','Embarked','Title','Family_label','Cabin_label','Ticket_label']]
# ラベル特徴量をワンホットエンコーディング
df = pd.get_dummies(df)
# データセットを trainとtestに分割
train = df[df['Survived'].notnull()]
test = df[df['Survived'].isnull()].drop('Survived',axis=1)
# データフレームをnumpyに変換
X = train.values[:,1:]
y = train.values[:,0]
test_x = test.values
10.ランダムフォレストによる推定モデルの構築
私は、最初、作った特徴量を手動で足したり、引いたりして精度がどうなるかを見ながらベストな組み合わせを選択してました。
ところが、Notbookでは、SelectKbestを使って特徴量の取捨選択を自動で行う人がいました。これは効率的!
何個の特徴量に絞り込むかは、**select = SelectKBest(k = 20)**という形で指定します。
# ----------- 推定モデル構築 ---------------
from sklearn.feature_selection import SelectKBest
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import cross_validate
# 採用する特徴量を25個から20個に絞り込む
select = SelectKBest(k = 20)
clf = RandomForestClassifier(random_state = 10,
warm_start = True, # 既にフィットしたモデルに学習を追加
n_estimators = 26,
max_depth = 6,
max_features = 'sqrt')
pipeline = make_pipeline(select, clf)
pipeline.fit(X, y)
# フィット結果の表示
cv_result = cross_validate(pipeline, X, y, cv= 10)
print('mean_score = ', np.mean(cv_result['test_score']))
print('mean_std = ', np.std(cv_result['test_score']))

20個の特徴量に絞り込んだ結果の平均スコアは0.8417441となりました。
さて、上記のコードで構築したモデルではどの特徴量を採用したのか確認してみましょう。
# -------- 採用した特徴量 ---------------
# 採用の可否状況
mask= select.get_support()
# 項目のリスト
list_col = list(df.columns[1:])
# 項目別の採用可否の一覧表
for i, j in enumerate(list_col):
print('No'+str(i+1), j,'=', mask[i])
# シェイプの確認
X_selected = select.transform(X)
print('X.shape={}, X_selected.shape={}'.format(X.shape, X_selected.shape))
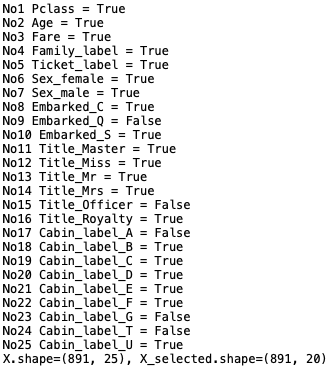
25個用意した特徴量の内、Embarked_Q, Title_officer, Cabin_label_A, Cabin_label_G, Cabin_label_T が不採用、後は採用と成って、確かに特徴量は20個に絞り込まれていました。
11.Submit_dataの作成
# ----- Submit dataの作成 -------
PassengerId=test_data['PassengerId']
predictions = pipeline.predict(test_x)
submission = pd.DataFrame({"PassengerId": PassengerId, "Survived": predictions.astype(np.int32)})
submission.to_csv("my_submission.csv", index=False)

結果は、2019年11月21日時点で、精度0.83732で、259位となりました。
参加メンバーは、15,889名なので、**Top1.6%**あたりです。
12.まとめ
今回、Kaggle/titanicのNotebookから得た、ノウハウをまとめておきます。
1)欠損値補完には、欠損値がない完全なデータから推定モデルを作って補完する方法がある(Age)。
2)一見ランダムに見える特徴量も必ず合理的な理屈から新たな特徴量が見い出せるはずだ(Ticket)。
3)一度新たな特徴量を見つけ出しても、さらに特徴量が見い出せる場合がある(Name)。
4)新たな特徴量を探る視点として、頻度がある(Surname, Ticket)
5)ラベル特徴量は分解して取捨選択するのが効果的な過学習防止策になる(Embarked, Title, Cabin)。
6)SelectKBsetを使用すると効率的な特徴量の取捨選択が出来る。
13.コード
最後に、コードをまとめておきます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# データセットの読み込み
train_data = pd.read_csv('./train.csv')
test_data = pd.read_csv('./test.csv')
# train_dataとtest_dataの連結
test_data['Survived'] = np.nan
df = pd.concat([train_data, test_data], ignore_index=True, sort=False)
# dfの情報
df.info()
# Sexと生存率の関係
sns.barplot(x='Sex', y='Survived', data=df, palette='Set3')
plt.show()
# ------------ Age ------------
# Age を Pclass, Sex, Parch, SibSp からランダムフォレストで推定
from sklearn.ensemble import RandomForestRegressor
# 推定に使用する項目を指定
age_df = df[['Age', 'Pclass','Sex','Parch','SibSp']]
# ラベル特徴量をワンホットエンコーディング
age_df=pd.get_dummies(age_df)
# 学習データとテストデータに分離し、numpyに変換
known_age = age_df[age_df.Age.notnull()].values
unknown_age = age_df[age_df.Age.isnull()].values
# 学習データをX, yに分離
X = known_age[:, 1:]
y = known_age[:, 0]
# ランダムフォレストで推定モデルを構築
rfr = RandomForestRegressor(random_state=0, n_estimators=100, n_jobs=-1)
rfr.fit(X, y)
# 推定モデルを使って、テストデータのAgeを予測し、補完
predictedAges = rfr.predict(unknown_age[:, 1::])
df.loc[(df.Age.isnull()), 'Age'] = predictedAges
# 年齢別生存曲線と死亡曲線
facet = sns.FacetGrid(df[0:890], hue="Survived",aspect=2)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, df.loc[0:890,'Age'].max()))
facet.add_legend()
plt.show()
# ------------ Name --------------
# Nameから敬称(Title)を抽出し、グルーピング
df['Title'] = df['Name'].map(lambda x: x.split(', ')[1].split('. ')[0])
df['Title'].replace(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer', inplace=True)
df['Title'].replace(['Don', 'Sir', 'the Countess', 'Lady', 'Dona'], 'Royalty', inplace=True)
df['Title'].replace(['Mme', 'Ms'], 'Mrs', inplace=True)
df['Title'].replace(['Mlle'], 'Miss', inplace=True)
df['Title'].replace(['Jonkheer'], 'Master', inplace=True)
sns.barplot(x='Title', y='Survived', data=df, palette='Set3')
# ------------ Surname ------------
# NameからSurname(苗字)を抽出
df['Surname'] = df['Name'].map(lambda name:name.split(',')[0].strip())
# 同じSurname(苗字)の出現頻度をカウント(出現回数が2以上なら家族)
df['FamilyGroup'] = df['Surname'].map(df['Surname'].value_counts())
# 家族で16才以下または女性の生存率
Female_Child_Group=df.loc[(df['FamilyGroup']>=2) & ((df['Age']<=16) | (df['Sex']=='female'))]
Female_Child_Group=Female_Child_Group.groupby('Surname')['Survived'].mean()
print(Female_Child_Group.value_counts())
# 家族で16才超えかつ男性の生存率
Male_Adult_Group=df.loc[(df['FamilyGroup']>=2) & (df['Age']>16) & (df['Sex']=='male')]
Male_Adult_List=Male_Adult_Group.groupby('Surname')['Survived'].mean()
print(Male_Adult_List.value_counts())
# デッドリストとサバイブリストの作成
Dead_list=set(Female_Child_Group[Female_Child_Group.apply(lambda x:x==0)].index)
Survived_list=set(Male_Adult_List[Male_Adult_List.apply(lambda x:x==1)].index)
# デッドリストとサバイブリストの表示
print('Dead_list = ', Dead_list)
print('Survived_list = ', Survived_list)
# デッドリストとサバイブリストをSex, Age, Title に反映させる
df.loc[(df['Survived'].isnull()) & (df['Surname'].apply(lambda x:x in Dead_list)),\
['Sex','Age','Title']] = ['male',28.0,'Mr']
df.loc[(df['Survived'].isnull()) & (df['Surname'].apply(lambda x:x in Survived_list)),\
['Sex','Age','Title']] = ['female',5.0,'Mrs']
# ----------- Fare -------------
# 欠損値を Embarked='S', Pclass=3 の平均値で補完
fare=df.loc[(df['Embarked'] == 'S') & (df['Pclass'] == 3), 'Fare'].median()
df['Fare']=df['Fare'].fillna(fare)
# ----------- Family -------------
# Family = SibSp + Parch + 1 を特徴量とし、グルーピング
df['Family']=df['SibSp']+df['Parch']+1
df.loc[(df['Family']>=2) & (df['Family']<=4), 'Family_label'] = 2
df.loc[(df['Family']>=5) & (df['Family']<=7) | (df['Family']==1), 'Family_label'] = 1 # == に注意
df.loc[(df['Family']>=8), 'Family_label'] = 0
# ----------- Ticket ----------------
# 同一Ticketナンバーの人が何人いるかを特徴量として抽出
Ticket_Count = dict(df['Ticket'].value_counts())
df['TicketGroup'] = df['Ticket'].map(Ticket_Count)
sns.barplot(x='TicketGroup', y='Survived', data=df, palette='Set3')
plt.show()
# 生存率で3つにグルーピング
df.loc[(df['TicketGroup']>=2) & (df['TicketGroup']<=4), 'Ticket_label'] = 2
df.loc[(df['TicketGroup']>=5) & (df['TicketGroup']<=8) | (df['TicketGroup']==1), 'Ticket_label'] = 1
df.loc[(df['TicketGroup']>=11), 'Ticket_label'] = 0
sns.barplot(x='Ticket_label', y='Survived', data=df, palette='Set3')
plt.show()
# ------------- Cabin ----------------
# Cabinの先頭文字を特徴量とする(欠損値は U )
df['Cabin'] = df['Cabin'].fillna('Unknown')
df['Cabin_label']=df['Cabin'].str.get(0)
sns.barplot(x='Cabin_label', y='Survived', data=df, palette='Set3')
plt.show()
# ---------- Embarked ---------------
# 欠損値をSで補完
df['Embarked'] = df['Embarked'].fillna('S')
# ------------- 前処理 ---------------
# 推定に使用する項目を指定
df = df[['Survived','Pclass','Sex','Age','Fare','Embarked','Title','Family_label','Cabin_label','Ticket_label']]
# ラベル特徴量をワンホットエンコーディング
df = pd.get_dummies(df)
# データセットを trainとtestに分割
train = df[df['Survived'].notnull()]
test = df[df['Survived'].isnull()].drop('Survived',axis=1)
# データフレームをnumpyに変換
X = train.values[:,1:]
y = train.values[:,0]
test_x = test.values
# ----------- 推定モデル構築 ---------------
from sklearn.feature_selection import SelectKBest
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import cross_validate
# 採用する特徴量を25個から20個に絞り込む
select = SelectKBest(k = 20)
clf = RandomForestClassifier(random_state = 10,
warm_start = True, # 既にフィットしたモデルに学習を追加
n_estimators = 26,
max_depth = 6,
max_features = 'sqrt')
pipeline = make_pipeline(select, clf)
pipeline.fit(X, y)
# フィット結果の表示
cv_result = cross_validate(pipeline, X, y, cv= 10)
print('mean_score = ', np.mean(cv_result['test_score']))
print('mean_std = ', np.std(cv_result['test_score']))
# -------- 採用した特徴量 ---------------
# 採用の可否状況
mask= select.get_support()
# 項目のリスト
list_col = list(df.columns[1:])
# 項目別の採用可否の一覧表
for i, j in enumerate(list_col):
print('No'+str(i+1), j,'=', mask[i])
# シェイプの確認
X_selected = select.transform(X)
print('X.shape={}, X_selected.shape={}'.format(X.shape, X_selected.shape))
# ----- Submit dataの作成 -------
PassengerId=test_data['PassengerId']
predictions = pipeline.predict(test_x)
submission = pd.DataFrame({"PassengerId": PassengerId, "Survived": predictions.astype(np.int32)})
submission.to_csv("my_submission.csv", index=False)