1.はじめに
ゼロから作るDeep Learning2 自然言語処理編を勉強しました。8章に Attention があるのですが、現在主流である BERT の基本になっている Transformer に割かれているのは僅か4ページでした。
実はこれは無理からぬことで、ゼロつく2が発刊されたのは2018年7月で、Transformerが2017年12月、BERTが2018年10月というタイミングだったためです。
今回は、ゼロつく2のAttentionから、現在の自然言語処理の基本とも言える Transformer の論文 Attention Is All You Need へと迫ってみたいと思います。
2.ゼロつく2のAttentionとは?
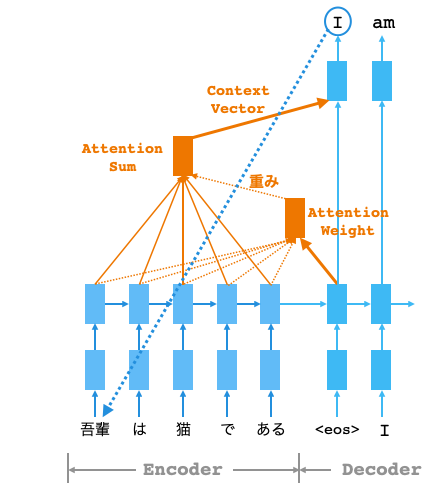
ゼロつく2の8章Attentionでは、Seq2Seqの翻訳モデルの性能を上げるために、Decoderで「I」を翻訳する時にEncoderの「吾輩」に注意を向けるようなAttentionを実装します。
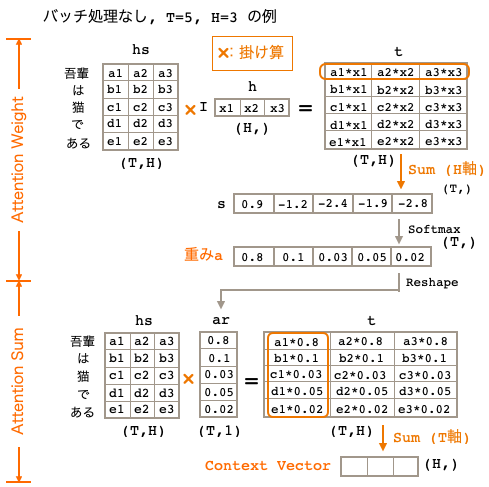
まず、Attention Weightで、Decoderの「I」のベクトルとEncoderの各単語ベクトルの類似度を求めるために内積を計算し、その結果にSoftmaxを掛けて重みaを求めます。但し、分かり易さを優先し、内積は掛け算+H軸SUMで代替計算をしています。
そして、Attention Sumで、重みaからEncoderの各単語ベクトルの重み付き和を計算し、Context Vector を求めます。この Context Vector は「吾輩」の単語ベクトルを色濃く反映したものになっていて、「I」が注意を向けるべきなのは「吾輩」であることを示しています。
3.ゼロつく2からTransformerへ
ゼロつく2の処理は分かり易さを優先し、わざと内積を使わず掛け算+軸SUMで計算しています。では、ちゃんと内積を使って計算するとどうなるかと言うと、
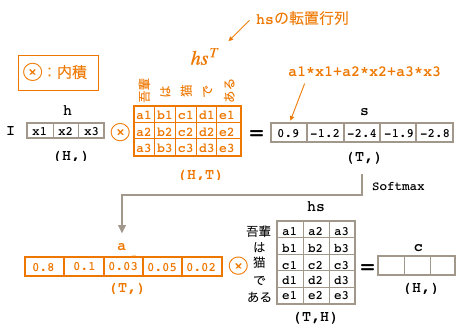
重みの計算、重み付け和の計算とも、内積の形にすると、こんな風にスッキリします。こちらの方が合理的ですよね。
さて、一般的にAttentionでは、計算するターゲットをQuery、類似度の計算に使う単語ベクトルの集まりをKey、重み付け和計算に使うベクトルの集まりをValueと言います。これらを反映して図を見直すと、
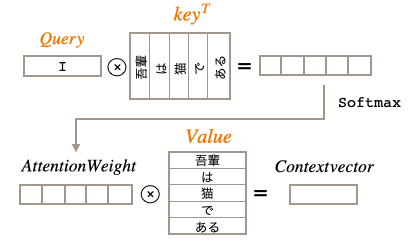
計算するターゲット**「I』はQuery**, 類似度の計算に使う単語ベクトルの集まりhsはKey, 重み付け和計算に使うベクトルの集まりhsはValue となるわけです。ゼロつく2では、keyとValueは同じですが、この2つを独立させることでより表現力が向上します。
※ Attentionの解説には、KeyとValueをまとめてMemoryと言い、Keyで指定されたValueを引き出す辞書のようなものだと説明しているケースもありますが、これは1つの例えです(実際にdictが使われているわけではありません)。
もう1つ、一般的にAttentionには、入力が何処から来るかによって区分があります。
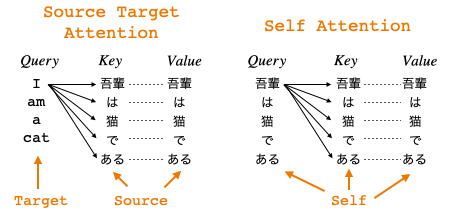
QureryとKey・Valueが別の場所から来る場合を Sorce Taget Attention と言い、Quety,Key,Valueの3つが全て同じ場所 (Self) から来る場合を Self Attentionと言います。ゼロつくのAttentionはSorce Taget Attentionということになります。
さて、書き方を少し変え、Self Attention の形式にして項を1つ追加します。
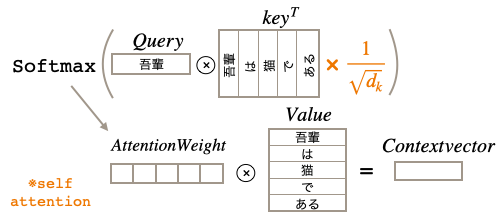
追加したのはルートdkで割る項です。なぜルートdkで割るかと言うと、内積計算で大き過ぎる値があるとSoftmaxを掛けたとき、それ以外の値が0になり勾配消失してしまうため、それを防止するためです。dkは単語分散表現の次元数で論文では512です。
さて、Transformer は逐次処理が必要なRNNは一切使わず並列処理が可能なAttentionのみで構成されています。従って、Queryを1つづつ計算する必要はなく、全てのQueryに対して一気に計算が出来るので下記の様に表せます。
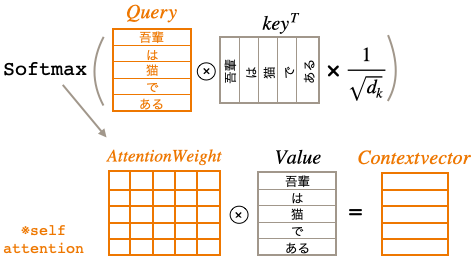
Attention Is All You Need の論文では、これを Scaled dot-product Attention と呼んでいて、下記の式で表現されています。これが Transformer の肝です。
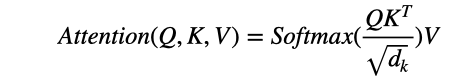
4.Attention Is All You Need
さて、2017年12月に発表された論文 Attention Is All You Need をザックリ理解するために、論文に出て来る図の説明をします。
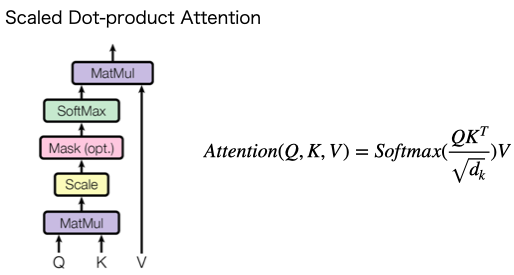
まず、Scaled Dot-product Attention の図です。Matmul は内積、Scale はルートdkで割ることを表しています。**Mask(opt)**は、入力する単語数がシーケンス長より短いときにpad処理した箇所にをマスクを掛けるという意味です。Attention(Q,K,V)の式と符号することが分かると思います。
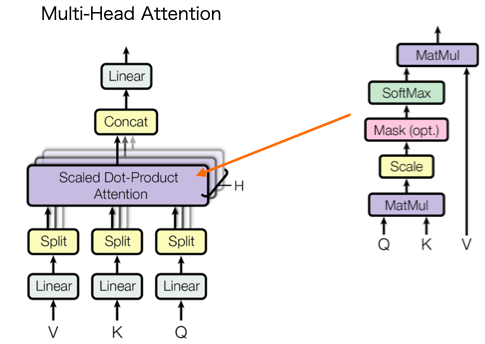
先程のScaled Dot-product Attention を含んだ、Multi-Head Attention です。前段の1つの出力が3つの**Linear(全結合層)**を経てQ,K,Vとして入力されます。言い換えれば、Q,K,Vは前段の出力にそれぞれ重みWq,Wk,Wvを掛けたもので、これらの重みは学習によって獲得されます。
1組のQuery,Key,Valueをヘッド(Head)といいます。大きなヘッドを1つ持つより、小さいヘッドを複数個持ち、それぞれで潜在表現を計算し最後にConcatする方がパフォーマンスが上がります。そのためにMulti-Headにしているわけです。論文では、前段の出力が512次元で、それを64次元のヘッドで8つに分割しています。
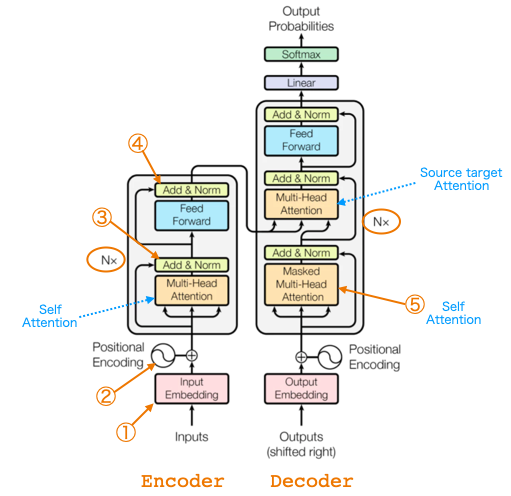
全体構成は、Encoder-Decoderの翻訳モデルです。狙いは、逐次計算のRNNはやめて並列計算ができるAttentionのみで構成し処理を高速化すること。Nxは同じ構成がN回繰り返されるという意味で、論文ではN=6です。
① Input Embedding
Inputsは(バッチ数, 単語ID列数)。事前訓練済みの単語分散表現を使ってベクトルに変換したものを出力(バッチ数, 単語ID列数, 次元数)します。論文の次元数は512です。
② Positional Encoding
重み和を計算すると単語の順番情報が失われる(「私は彼女を好き」と「彼女は私を好き」の区別がつかない) ので、分散表現に単語の位置情報(sin関数とcos関数のパターン)を加算し、相対的な単語位置を学習し易くしています。つまり、同じ単語でも違う場所にあれば異なるベクトルになります。論文に載っている位置情報を表す式は、以下の様です。
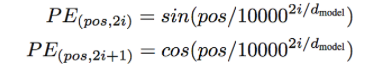
③ Add & Norm
Skipコネクションで、LayerNormalizationによる正規化, Dropoutによる正則化を行います。LayerNormalizationはバッチ単位ではなくバッチ内の各データ単位(センテンス)で正規化を行います。
④ Feed Foward
Attention層からの出力を2層の全結合層で特徴量を変換します。
⑤ Masked Multi-Head Attention
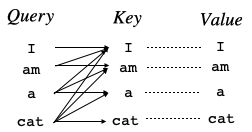
「I」のAtentionを計算するとき、「am」,「a」,「cat」を対象に入れると予測すべき単語をカンニングすることになるので、Keyにある先の単語を見えなくするためにマスクを掛けます。
5.Transformer その先へ
Transformer は翻訳モデルとして提案されましたが、その後研究が進むと Self Attentionによる文の意味抽出力が相当強力であることが分かって来て、様々な展開がされていますので、簡単に触れておきます。
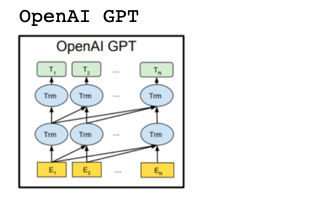
2018年6月。TransformerのEncoder側のみを使い、事前学習+ファインチューニングの2段階学習で性能が向上しました。事前学習は、次に来る単語は何かを当てるというもので、未来の情報が分かるとまずいので、後ろの文にはマスクをかけています。
構造上、後ろの文脈が利用できないという欠点があり、後ろの文脈を活用できればさらなる性能の向上が図れることは周知の事実でした。
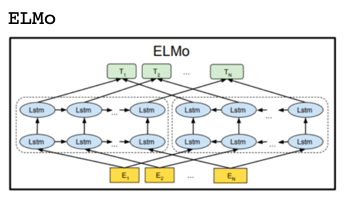
2018年2月。なんとかして後ろの文脈も利用するために、Attentionによる並列処理のメリットは一旦捨てて、多層化した双方向LSTMを使って後ろの文脈も利用してみました。そうすることで、性能が向上することが分かりました。
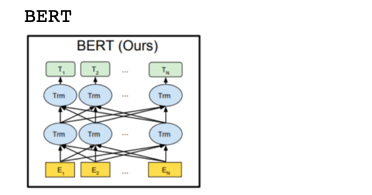
2018年10月。自然言語処理における革命的な手法BERTが発表されました。ザックリ言うと、GPTの事前学習を下記の2つのタスクに置き換えることで、前後の文脈を利用し、かつ並列処理を実現しました。いわば双方向Transformerの誕生です。
①Masked Language Model:穴埋め問題を解かせる。15%の単語を選び80%をマスク、10%を他の単語に置き換え、10%をそのままにする。
②Next Sentence Prediction:2つの文の文脈が繋がっているかを判定する。