はじめに
この記事は、プログラミングスクールでデータ分析講座を受講後、そのカリキュラムの一環として受講要件修了のために公開しています。
家計調査は、統計的な抽出方法に基づき選定された全国約9,000世帯を対象として、家計の収入・支出、貯蓄などについて毎月実施されています。品目別調査は、県庁所在地と政令指定都市を対象に集計されています。
過去の調査結果から、今後の各都市の消費金額を予測できれば2024年のランキングになると考え着手しました。
毎年ランキングが注目される「ラーメン」「パン」「納豆」など品目は多岐にわたっていますが、私の地元の隣の市である浜松市がトップに躍り出ることも多い「ぎょうざ」のランキング予測に取り組みます。
参考:総務省統計局ホームページ 家計調査概要
なお、PythonのバージョンはPython3.10.12、実行環境はGoogle Colaboratoryです。
データの取得・準備
e-Statより家計調査のCSVデータをダウンロードしておきます。
家計調査は毎月実施されており、2024年8月中旬時点では、2024年6月までのデータが取得可能でした。
対象データのページに進み、「DB」から統計表を選択することで、任意の項目が表示可能です。
地域区分(都市名)、年次、ぎょうざの消費金額などの項目を選択、地域区分・期間(月次)、消費金額といった、必要なデータが表示されていることを確認してダウンロードします。
Google Colaboratory を利用してファイル操作するための準備を行います。
# Google Colaboratory を利用してファイル操作するための準備
from google.colab import drive
drive.mount('/content/drive')
必要なライブラリをインポートします。グラフ表示時の日本語文字化け対策も行っています。
pip install japanize-matplotlib
import pandas as pd
import numpy as np
import seaborn as sns
import warnings
import itertools
import statsmodels.api as sm
import matplotlib.pyplot as plt
import japanize_matplotlib
%matplotlib inline
ダウンロードしたCSVデータを読み込み、最初の数行を表示して内容を確認します。
# ファイルの読み込み
file_path = '/content/drive/MyDrive/Colab Notebooks/CSV/FEH_00200561_monthly.csv'
# ファイルをテキスト形式で読み込む
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
# 最初の10行を表示して内容を確認
lines[:10]
内容確認したところ、説明文など、分析に不要なテキストがあるようなので、その部分はスキップします。
# 必要な行をスキップしてデータを読み込む
data = pd.read_csv(file_path, skiprows=6)
# データの確認
data.head()
出力結果
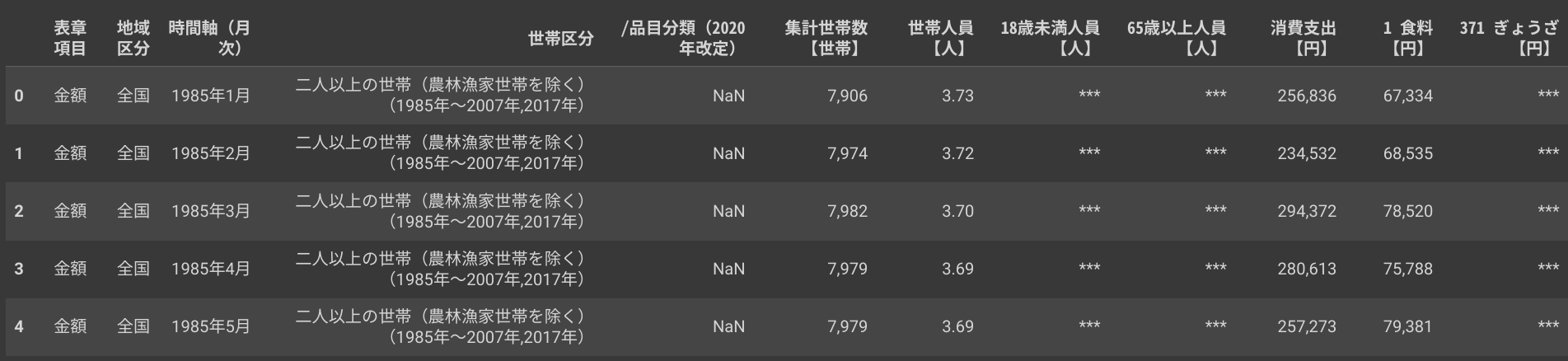
データフレームを読みこみ、項目名称を設定、各項目のデータ形式を確認しました。
金額を表す値が数値形式になっていないようです。 「時間軸(月次)」も、日付形式ではなく文字列になっています。
# データの読み込みと整形
data = pd.read_csv(file_path, skiprows=6)
# わかりやすい列名を設定
data.columns = [
"item_name","region", "month", "family_group", "item_group",
"household_num", "family_member", "u18_menber", "g65_menber",
"consumption", "food_consumption", "gyoza_consumption"
]
# 不要な列を削除
data = data.drop(columns=[ "item_name", "family_group", "item_group"])
# データの確認
display(data.head(10))
print(f'{data.dtypes} \n')
出力結果
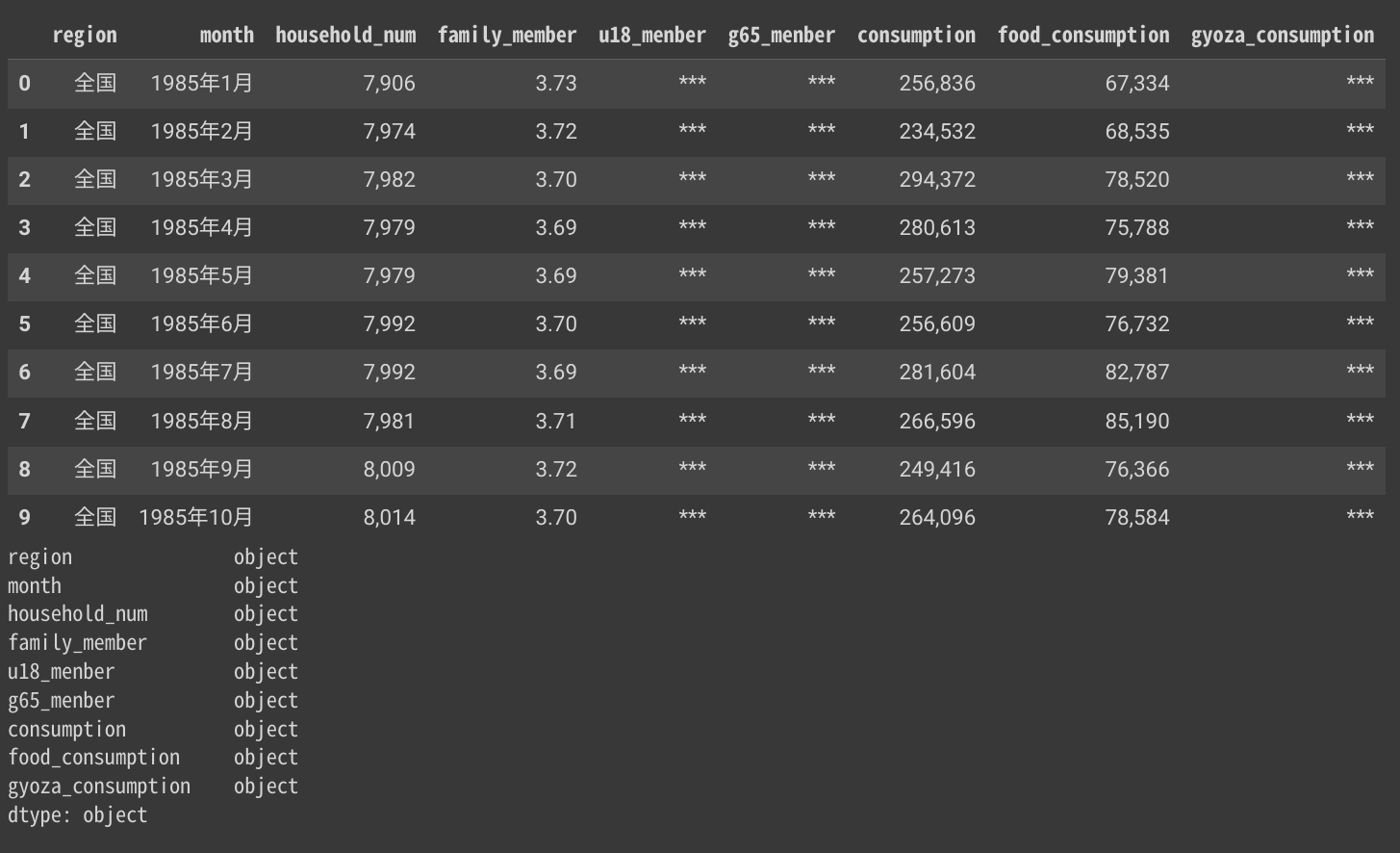
データ形式を変換します。
分析に使わないかもしれない項目も含まれていますが、将来、様々な角度で検証するときのために残しておきます。
都市ごとのランクを知るために、まずは都市ごとの消費金額を知りたいです。どんな都市が集計されているか確認します。
# 「年月」を日付型に変換。便宜上各月の1日とする
data["month_01"] = pd.to_datetime(data["month"].str.replace("年", "-").str.replace("月", "-01") , format='%Y-%m-%d')
# 文字列で表された数字を、数値に変換
data["gyoza_consumption"] = pd.to_numeric(data["gyoza_consumption"].str.replace(",", ""), errors='coerce')
data["household_num"] = pd.to_numeric(data["household_num"].str.replace(",", ""), errors='coerce')
data["consumption"] = pd.to_numeric(data["consumption"].str.replace(",", ""), errors='coerce')
data["food_consumption"] = pd.to_numeric(data["food_consumption"].str.replace(",", ""), errors='coerce')
data["u18_menber"] = pd.to_numeric(data["u18_menber"], errors='coerce')
data["g65_menber"] = pd.to_numeric(data["g65_menber"], errors='coerce')
# データの確認
display(data.head(10))
print()
# データの確認(都市ごとにデータの個数をカウント)
print(data['region'].value_counts(dropna=False, ascending=True))
出力結果

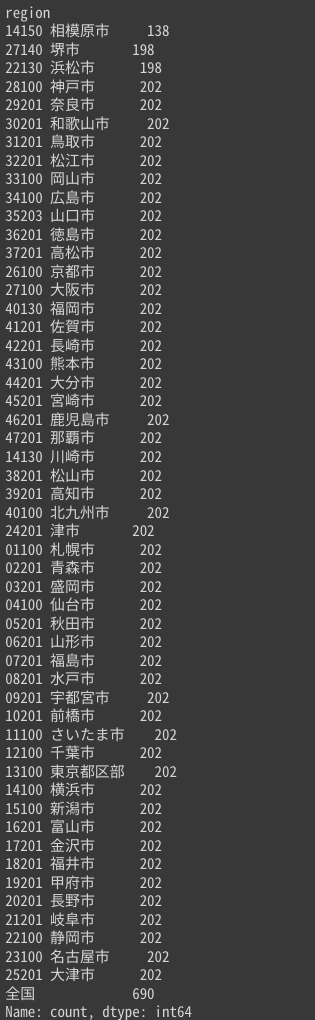
2023年のぎょうざの消費金額を都市ごとに合計し、降順にソートしたところ、おなじみのランキングが確認できました。
print(data[data["month"].str.startswith("2023年")].groupby('region')['gyoza_consumption'].sum().sort_values(ascending=False))
出力結果

データの視覚化
上位3都市の傾向を観察するため、グラフにて可視化します。
# 対象都市リスト
cities = ["22130 浜松市", "45201 宮崎市", "09201 宇都宮市"]
# 各都市ごとにデータを処理
for city in cities:
# 都市ごとのデータ抽出
city_data = data[data["region"] == city]
# 必要なカラムの抽出とインデックスの設定
city_data = city_data[["gyoza_consumption", "month_01"]]
city_data.set_index('month_01', inplace=True)
# 確認用に都市ごとにグラフを表示
plt.plot(city_data)
plt.title(f"{city} Gyoza Consumption")
plt.xlabel("Date")
plt.ylabel("Gyoza Consumption")
plt.grid()
plt.show()
出力結果
浜松市 宮崎市
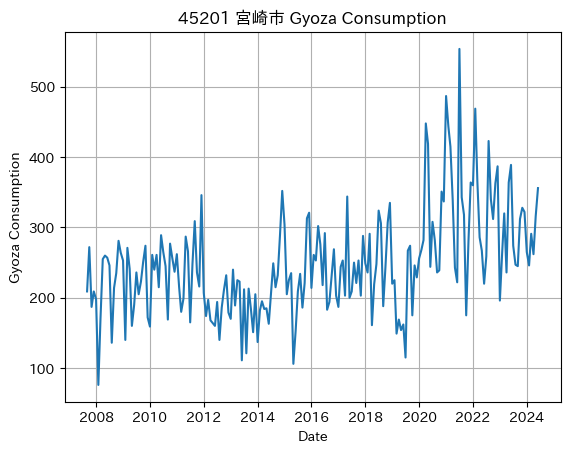
宇都宮市

モデルの構築・予測の実行
ここからは都市ごとの推移を予測します。都市ごとに次年以降の金額が予測できれば、その金額を比較して未来のランキングができるというわけです。
本データには季節性とトレンドがあると思われるため「SARIMAモデル」を選定します。
ARIMAモデルは、以前の値に影響されるモデルであり、直前p個の値と相関をもつようなARモデルと、以前の誤差に影響されるモデルで直前q個の値の影響を受けるようなMAモデルを合成したARMA(p,q)を、d時点前の階差系列に適応したものです。
SARIMAモデルとはARIMAモデルをさらに季節周期を持つ時系列データにも拡張できるようにしたモデルで、(p, d, q)のパラメーターに加えて(sp, sd, sq, s)というパラメーターを持ちます。
PythonにはSARIMAモデルのパラメーターを自動で最適にする機能はありませんが、BIC(ベイズ情報量基準) によってどの値が最も適切なのか調べるプログラムを講座にて習いましたので、「selectparameter」として利用します。
まずは、2023年の上位3都市について、2024年〜2026年の予測を行い、実績と合わせてグラフ化します。これは視覚化しての確認のために行っています。
# 対象都市リスト
cities = ["22130 浜松市", "45201 宮崎市", "09201 宇都宮市"]
# SARIMAモデルのパラメータ選択関数
def selectparameter(DATA, s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs, results.bic)
except:
continue
return parameters[np.argmin(BICs)]
# 各都市ごとにデータを処理
for city in cities:
# 都市ごとのデータ抽出
city_data = data[data["region"] == city]
# 必要なカラムの抽出とインデックスの設定
city_data = city_data[["gyoza_consumption", "month_01"]]
city_data.set_index('month_01', inplace=True)
# SARIMAモデルの最適パラメータを選択
# 周期は月ごとのデータであることも考慮してs=12となります
# orderはselectparameter関数の0インデックス, seasonal_orderは1インデックスに格納されています
best_params = selectparameter(city_data, 12)
# SARIMAモデルによる予測
SARIMA_data = sm.tsa.statespace.SARIMAX(city_data,
order=best_params[0],
seasonal_order=best_params[1]).fit()
# 予測期間は2024年1月から2026年12月まで
pred = SARIMA_data.predict('2024-01-01', '2026-12-01')
# 確認用に都市ごとにグラフを表示
plt.plot(city_data, label="Actual")
plt.plot(pred, color="r", label="Forecast")
plt.title(f"{city} Gyoza Consumption Forecast")
plt.legend()
plt.grid()
plt.show()
出力結果
浜松市

宮崎市

宇都宮市

いよいよランキング予測を行います。
2023年の上位10都市を対象に2024年の予測を行い、1〜12月までを合計します。この結果を降順に並べてランキングとします。
2025年、2026年の予測も同時に行っています。
# 2023年の餃子消費量が多い順に並べ、上位10都市を抽出
top_10_cities = data[data["month"].str.startswith("2023年")].groupby('region')['gyoza_consumption'].sum().sort_values(ascending=False).head(10)
# 都市名をリストに格納
cities = top_10_cities.index.tolist()
# 確認のために都市リストを表示
print(cities)
# 各都市ごとの予測値を格納する辞書(年ごとに分ける)
city_predictions_2024 = {}
city_predictions_2025 = {}
city_predictions_2026 = {}
# SARIMAモデルのパラメータ選択関数
def selectparameter(DATA, s):
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs, results.bic)
except:
continue
return parameters[np.argmin(BICs)]
# 各都市ごとにデータを処理
for city in cities:
# 都市ごとのデータ抽出
city_data = data[data["region"] == city]
# 必要なカラムの抽出とインデックスの設定
city_data = city_data[["gyoza_consumption", "month_01"]]
city_data.set_index('month_01', inplace=True)
# SARIMAモデルの最適パラメータを選択
# 周期は月ごとのデータであることも考慮してs=12となります
# orderはselectparameter関数の0インデックス, seasonal_orderは1インデックスに格納されています
best_params = selectparameter(city_data, 12)
# SARIMAモデルによる予測
SARIMA_data = sm.tsa.statespace.SARIMAX(city_data,
order=best_params[0],
seasonal_order=best_params[1]).fit()
# 予測期間は2024年1月から2026年12月まで
pred = SARIMA_data.predict('2024-01-01', '2026-12-01')
# 年ごとに予測を抽出し、合計を計算して辞書に格納
city_predictions_2024[city] = round(pred['2024-01-01':'2024-12-01'].sum())
city_predictions_2025[city] = round(pred['2025-01-01':'2025-12-01'].sum())
city_predictions_2026[city] = round(pred['2026-01-01':'2026-12-01'].sum())
# 各年の結果を表示(都市ごとの合計値を降順に並べ替え)
sorted_predictions_2024 = pd.Series(city_predictions_2024).sort_values(ascending=False)
sorted_predictions_2025 = pd.Series(city_predictions_2025).sort_values(ascending=False)
sorted_predictions_2026 = pd.Series(city_predictions_2026).sort_values(ascending=False)
print("2024年ぎょうざ消費金額ランキング予想:")
print(sorted_predictions_2024)
print("\n2025年ぎょうざ消費金額ランキング予想:")
print(sorted_predictions_2025)
print("\n2026年ぎょうざ消費金額ランキング予想:")
print(sorted_predictions_2026)
出力結果

結果のまとめと考察
2024年「ぎょうざ」消費金額ランキング予測の結果をまとめると、下記となりました。2023年実績と比較してみます。
「ぎょうざ」年間消費金額ランキング(円)
| 都市名 | 2023年実績 | 都市名 | 2024年予測 |
|---|---|---|---|
| 浜松市 | 4041 | 浜松市 | 3973 |
| 宮崎市 | 3497 | 宮崎市 | 3703 |
| 宇都宮市 | 3200 | 宇都宮市 | 3127 |
| 京都市 | 2661 | 大津市 | 2446 |
| 大津市 | 2487 | 京都市 | 2303 |
| 奈良市 | 2439 | 大阪市 | 2263 |
| 名古屋市 | 2392 | さいたま市 | 2261 |
| さいたま市 | 2286 | 名古屋市 | 2257 |
| 東京都区部 | 2205 | 東京都区部 | 2219 |
| 大阪市 | 2168 | 奈良市 | 2066 |
2023年実績での上位3都市間では、2024年予測での順位の入れ替わりはありませんでした。2023年は、浜松市が3年ぶりに「ぎょうざ消費金額」の首位に立った年でありますが、2024年もそのまま首位を保ち続けるということになります。
しかし、1位の浜松市も4,000円台を割り込む他、2位の宮崎市以外は全体的に金額の減少が見られます。
一方、4位以下では順位の入れ替わりが見られます。もともと数十円〜数百円の差でしたので、少しの変動がそのまま順位の変動につながります。
今回は利用しませんでしたが、もとのデータには、世帯人数や食料品全体の消費金額といった項目も含まれており、今後は相関関係の発見や更なる分析もしてみたいと思いました。
2024年の1年間での家計調査は、おそらく2025年2月に発表となるでしょう。今回のデータ予測が、実際の結果にどれだけ近づけているか、今から楽しみにしています。
以上となります。