この記事は、Elasticsearch Advent Calendar 2014 の20日目のエントリーです。
ハイマニアックな内容ですが、早速はじめます。
概要
elasticsearchには、KibanaやLogstash等と並んで elaticsearch-hadoop というプロダクト(?)があるようです。elasticsearchのTopページに一緒に並んでいました。
この名前を見たとき、脳が混ぜるなきけんと叫んでましたが、触ってる内に杞憂だとわかって、だんだん面白くなってきたので紹介したいと思います。
elasticsearch-hadoopとは
プロジェクトの正式名称は、「Elasticsearch for Apache Hadoop」とのこと。
けど、いつもelasticsearch-hadoopって呼ばれています。
出来ること
- Spark、Hive、PigなどからHDFSであるかのようにESをストレージとして扱う
-
Map/Reduceのタスク分散処理をESのノードで実現する追記 - [elaticsearch on yarn] (http://www.elasticsearch.org/blog/elasticsearch-yarn-and-ssl/) というYARN上でESを動かすライブラリも含まれている
など。
[追記]
Map/Reduceのタスク分散処理をESのノードで実行するには、Hadoop側で同じノードをTaskTrackerに指定する必要がありそうで、elasticsearch-hadoopだけで出来ることではないので取り消し線を追記しました。
[追記ここまで]
こういうApache Hadoopのプロジェクトと繋がるライブラリ郡をまとめて、elasticsearch-hadoopと呼んでいるようです。
ソースコード
オープンソースでGithubでも公開されています。
2014年12月現在で、安定バージョンがv2.0、betaがv2.1です。
https://github.com/elasticsearch/elasticsearch-hadoop
- コミット数は1000超(ES本体は10000超、kibanaやlogstashは6000超なので規模は1/10?)
- issuesは300, PRは50程度
- costinさんが頑張って作ってる
これだけ見るとオープンソースとしては発展途上という感じですが、既に十分動くものになっていて、CDH5でも公式に認定されたらしいです。リリースノートにもそれっぽく紹介されてました。
https://twitter.com/ClouderaConnect/status/517748320148914176
特徴
その1 HDFSに成り代わるイメージ
elasticsearchとhadoopがどう繋がるのか。お絵かきしました。
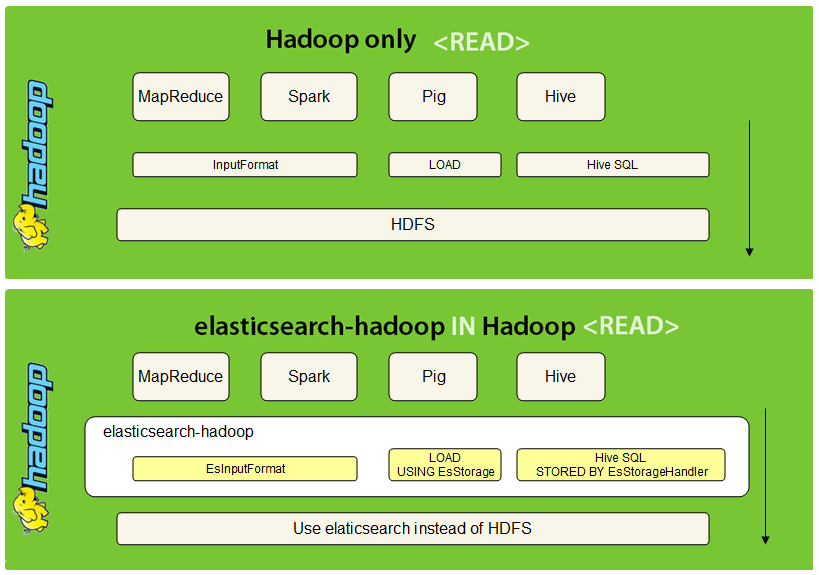
例として一番左のMapReduceを挙げると、上の図では入力値を扱う抽象クラスInputFormatでHDFSとお喋りしています。
下の図では、InputFormatを継承したESInputFormatクラスで
InputFormatが行っていた「入力値の分割(InputSplit)」「行参照クラス生成(RecodeReader)」の役割をESに当てはめて実装しています。
このように、各プロジェクトのHDFSへアクセス部分を継承することで、HDFSの成り代わりを実現しているのが特徴です。
ちょっと絵が紛らわしいですが、elasticsearch-hadoopはHadoopと繋がるライブラリで、Hadoop上で動くアプリケーションではない ので、ご注意ください。
その2 MapRecudeとESのシャード
Map/Reduceの分散という性質は、ESのシャードという関係にうまくフィットしている、とドキュメントで自画自賛していました。
何がフィットするのでしょう。お絵かきしました。
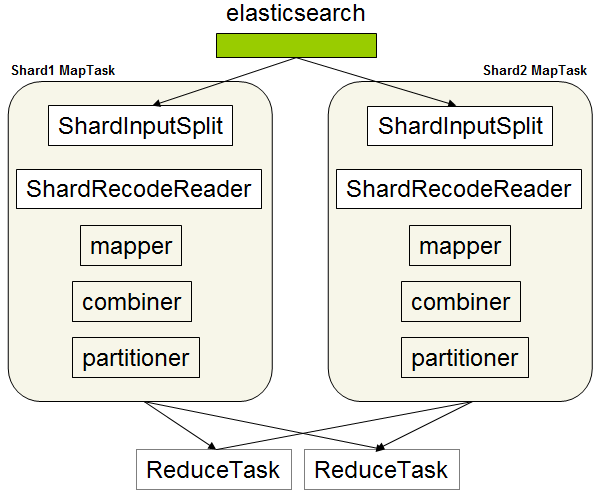
EsInputFormatはESからプライマリシャード情報を取得し、シャード毎にShardInputSplitを生成、それぞれのシャードが持つドキュメントを分割済みの入力値として定義します。
データの重複をさけるためにレプリカは使わない。
Hadoopはこうして分割されたMap数分のタスクを生成するため、elasticsearch-hadoopではshard数=Mapタスク数という図式が成り立ちます。
(これがフィット・・!)
ESから返されたJSONは、Map<docid, JSON>を経て、ShardRecodeReaderとなり、シャッフルに備えられます。
Map関数後の処理は見慣れたMapReduceになります。
その3 ESへの問い合わせはREST
InputSplitでのESのプライマリシャード情報の取得
以下のRESTを${es.nodes}で指定されたESへ投げます。
REST1: _nodes/httpでノード取得
curl ${es.node}/_nodes/http
レスポンスサマリー
- cluster_name
- nodes
- node
- name
- transport_address
- host
- ip
- version
- build
- http_address
- http
- node
REST2: index/_search_shardsでシャードを取得
curl ${es.node}/*/_search_shards
レスポンスサマリー
- shards
- shard
- state
- primary
- node
- relocating_node
- shard
- index
- shard
- nodes
- node
RecodeReaderでのESへのクエリ問い合わせ
REST3: _search apiでドキュメント取得
curl XPOST ${SHARD_HOST}/${INDEX}/_search/scroll -d "${QUERY}"
- params
- search_type=scan
- scroll=keepalive(default 10m)
- size=(default 50)
- preference=_shards:shard;_only_node:node
変数SHARD_HOSTはここまでに取得したシャードのホスト、変数INDEXとQUERYはジョブ実行前にConfigurationであらかじめ指定しておいたもの(後述)
elasticsearch-hadoopは、与えられたクエリを、scan and scroll で順次読み込んでいきます。ドキュメントでは見つけられなかったので、ソースコードを読みました。
_scroll_idを使って必要なサイズだけ取得、足りなくなったら_scroll_idで続きを取得している。
curl XPOST ${SHARD_HOST}/${INDEX}/_search/scroll -d "${scrollId}"
- params
- scroll=keepalive(default 10m)
これはつまり、クエリに一致するドキュメントを全取得するための処理で、ディープ・スクロールが必要になる大きなデータセットでも、elasticsearch-hadoopならクエリを指定するだけ全取得できるようになっているようです。
※scan and scrollは、たとえばスクロール中に更新がかかってもスクロール開始時の内容を一貫して取得するための検索タイプ。reindexとかに使う(負荷が高いので、リアルタイム検索には使えない)
その他、所感
- HDFSと比べてREST分のオーバーヘッドがかかるので、単純に同じドキュメントサイズだとHDFSと同パフォーマンスはでないかも
- elasticsearch-hadoopが得意とするのは、バッチ処理の中でデータを検索してドキュメントサイズを一気に減らせるようなケースや、
更新がかかりにくくてキャッシュヒット率の高いデータを扱うケースだと思う - 扱うデータを選べばHDFS以上のパフォーマンスを発揮してくれそうな気配を感じる(実証なし)
動かしてみる
目的
こんな状況を仮定して、ekasticsearch-hadoopを使ってSpark RDDを作るところまでをチュートリアルとします。
- kibana格好いいから、とりあえずアクセスログを突っ込んだ
- しばらくして、kibanaでは出来ないような複雑な解析もしたくなった
- もちろんHadoopなんてない。ログはESにしか入ってない(しかも一ヶ月で吐き捨て)
一ヶ月分もあれば、Sparkでショートバッチで作って十分に回せそうです。繋いでみましょう。
必要なものをいれる
環境を再現するために、アクセスログを突っ込みます。
| 入れるもの | バージョン |
|---|---|
| elasticsearch | 1.4.2 |
| logstash | 1.4.2 |
| spark | 1.1.0 |
ダウンロード
cd ~/es-advent-calendar
wget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.4.2.tar.gz
wget https://download.elasticsearch.org/logstash/logstash/logstash-1.4.2.tar.gz
wget http://d3kbcqa49mib13.cloudfront.net/spark-1.1.0.tgz
tar -zxvf elasticsearch-1.4.2.tar.gz
tar -zxvf logstash-1.4.2.tar.gz
tar zxvf spark-1.1.0.tgz
elasticsearch インストール
echo '
################################### My Configuration ###################################
cluster.name: logs_cluster
index.number_of_replicas: 0
' >> config/elasticsearch.yml
mkdir config/templates && echo '
{
"template": "access_log-*",
"mappings": {
"_default_": {
"dynamic_templates": [
{
"string_template" : {
"match" : "*",
"match_mapping_type" : "string",
"mapping": {
"type": "string",
"index": "not_analyzed"
}
}
}
],
"properties": {
"request": {
"type": "multi_field",
"fields": {
"request": {
"type": "string",
"index" : "not_analyzed"
},
"split_request": {
"type": "string",
"index" : "analyzed"
}
}
},
"referrer": {
"type": "multi_field",
"fields": {
"referrer": {
"type": "string",
"index" : "not_analyzed"
},
"split_referrer": {
"type": "string",
"index" : "analyzed"
}
}
},
"response": {
"type": "integer"
},
"bytes": {
"type": "integer"
}
}
}
}
}
' > config/templates/access_log_template.json
bin/elasticsearch
logstash インストール
cd ./logstash-1.4.2
mkdir config && echo '
input {
file {
path => "~/es-advent-calendar/demo-access-logs/access_log-*"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
break_on_match => false
tag_on_failure => ["_message_parse_failure"]
}
date {
match => ["timestamp", "dd/MMM/YYYY:HH:mm:ss Z"]
locale => en
}
grok {
match => { "request" => "^/%{WORD:first_path}/%{GREEDYDATA}$" }
tag_on_failure => ["_request_parse_failure"]
}
useragent {
source => "agent"
target => "useragent"
}
}
output {
elasticsearch {
host => "localhost"
index => "access_log-%{+YYYY.MM.dd}"
cluster => "logs_cluster"
protocol => "http"
}
}
' > config/logstash.conf
bin/logstash --config config/logstash.conf
spark インストール
cd spark-1.1.0
mvn -DskipTests clean package
Javaアプリケーションを作る
elasticsearch-hadoopとsparkのバージョン管理はmavenで行えます。
ソースコードこれだけ↓なので、Githubにはあがってません。
pom.xml抜粋
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop</artifactId>
<version>${eshadoop.version}</version>
</dependency>
HelloElasticsearchSpark.java
package org.jtodo.demo;
import org.apache.hadoop.conf.Configuration;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.JavaPairRDD;
import org.elasticsearch.hadoop.mr.EsInputFormat;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.MapWritable;
public class HelloElasticsearchSpark {
public static void main(String[] args) {
Configuration conf = new Configuration(); ①
conf.set("es.nodes", "localhost:9200");
conf.set("es.resource", "access_log-2014.12.20/logs");
conf.set("es.query", "{\"query\": {\"term\": {\"first_path\": \"action\"}}}");
SparkConf sparkConf = new SparkConf().setAppName("HelloElasticsearchSpark");
sparkConf.set("spark.serializer", org.apache.spark.serializer.KryoSerializer.class.getName());
JavaSparkContext sc = new JavaSparkContext(sparkConf);
JavaPairRDD<Text, MapWritable> esRDD =
sc.newAPIHadoopRDD(conf, EsInputFormat.class, Text.class, MapWritable.class); ②
System.out.println("Count of records founds is " + esRDD.count());
}
}
ポイント① Configuration
es.nodes (default localhost)
ESを指定。クラスタ内のノードを全て列挙するわけではなく、複数のクラスタへ同じクエリを実行したいときに列挙する
es.port (default 9200)
nodesで指定しなかったときに使われるポート
es.resource
ESの_search APIのエンドポイント。index/typeで指定する。ワイルドカード可。
es.query
URI, Query dsl, 外部ファイルから選択できる。
URI (or parameter) query http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/search-
uri-request.html
es.query = ?q=costinl
Query dsl http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/search-request-body.html
es.query = { "query" : { "term" : { "user" : "costinl" } } }
External Resource
es.query = org/mypackage/myquery.json
etc. http://www.elasticsearch.org/guide/en/elasticsearch/hadoop/current/configuration.html
ポイント② EsInputFormat
InputFormatクラスにelasticsearch-hadoopのEsInputFormatを使う。
ここさえ間違えなければ、既存のHDFS用Sparkドライバをそのまま流用できる。
実行する
maven package
cd ~/es-advent-calendar/spark-1.1.0
bin/spark-submit --class org.jtodo.demo.HelloElasticsearchSpark --master local[5] ~/es-advent-calendar/demo-elasticsearch-spark/target/demo-elasticsearch-spark-0.0.1-SNAPSHOT-jar-with-dependencies.jar
結果
何も考えずにESを使ってると、number_of_shardsはデフォルトのままでインデックス毎に5シャード生成される。
14/12/07 21:31:59 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, ANY, 9895 bytes)
14/12/07 21:31:59 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, ANY, 9895 bytes)
14/12/07 21:31:59 INFO TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, localhost, ANY, 9895 bytes)
14/12/07 21:31:59 INFO TaskSetManager: Starting task 3.0 in stage 0.0 (TID 3, localhost, ANY, 9895 bytes)
14/12/07 21:31:59 INFO TaskSetManager: Starting task 4.0 in stage 0.0 (TID 4, localhost, ANY, 9895 bytes)
14/12/07 21:31:59 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
14/12/07 21:31:59 INFO Executor: Running task 3.0 in stage 0.0 (TID 3)
14/12/07 21:31:59 INFO Executor: Running task 4.0 in stage 0.0 (TID 4)
14/12/07 21:31:59 INFO Executor: Running task 2.0 in stage 0.0 (TID 2)
14/12/07 21:31:59 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
14/12/07 21:31:59 INFO Executor: Fetching http://localhost:57392/jars/demo-elasticsearch-spark-0.0.1-SNAPSHOT-jar-with-dependencies.jar with timestamp 1417955518911
14/12/07 21:31:59 INFO Utils: Fetching http://localhost:57392/jars/demo-elasticsearch-spark-0.0.1-SNAPSHOT-jar-with-dependencies.jar to /tmp/fetchFileTemp3143049760330881914.tmp
14/12/07 21:31:59 INFO Executor: Adding file:/tmp/spark-f0cec1a7-6496-47a9-bc7b-5f7ad126a3b5/demo-elasticsearch-spark-0.0.1-SNAPSHOT-jar-with-dependencies.jar to class loader
14/12/07 21:31:59 INFO NewHadoopRDD: Input split: ShardInputSplit [node=[I9ed1kejTR6aLUTuS55YKw/Jerome Beechman|127.0.0.1:9200],shard=1]
14/12/07 21:31:59 INFO NewHadoopRDD: Input split: ShardInputSplit [node=[I9ed1kejTR6aLUTuS55YKw/Jerome Beechman|127.0.0.1:9200],shard=2]
14/12/07 21:31:59 INFO NewHadoopRDD: Input split: ShardInputSplit [node=[I9ed1kejTR6aLUTuS55YKw/Jerome Beechman|127.0.0.1:9200],shard=3]
14/12/07 21:31:59 INFO NewHadoopRDD: Input split: ShardInputSplit [node=[I9ed1kejTR6aLUTuS55YKw/Jerome Beechman|127.0.0.1:9200],shard=0]
14/12/07 21:31:59 INFO NewHadoopRDD: Input split: ShardInputSplit [node=[I9ed1kejTR6aLUTuS55YKw/Jerome Beechman|127.0.0.1:9200],shard=4]
14/12/07 21:31:59 WARN EsInputFormat: Cannot determine task id...
14/12/07 21:31:59 WARN EsInputFormat: Cannot determine task id...
14/12/07 21:31:59 WARN EsInputFormat: Cannot determine task id...
14/12/07 21:31:59 WARN EsInputFormat: Cannot determine task id...
14/12/07 21:32:00 WARN EsInputFormat: Cannot determine task id...
14/12/07 21:32:00 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 1651 bytes result sent to driver
14/12/07 21:32:00 INFO Executor: Finished task 3.0 in stage 0.0 (TID 3). 1651 bytes result sent to driver
14/12/07 21:32:00 INFO Executor: Finished task 4.0 in stage 0.0 (TID 4). 1651 bytes result sent to driver
14/12/07 21:32:00 INFO Executor: Finished task 2.0 in stage 0.0 (TID 2). 1651 bytes result sent to driver
14/12/07 21:32:00 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1651 bytes result sent to driver
14/12/07 21:32:00 INFO TaskSetManager: Finished task 4.0 in stage 0.0 (TID 4) in 919 ms on localhost (1/5)
14/12/07 21:32:00 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 939 ms on localhost (2/5)
14/12/07 21:32:00 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 939 ms on localhost (3/5)
14/12/07 21:32:00 INFO TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 944 ms on localhost (4/5)
14/12/07 21:32:00 INFO TaskSetManager: Finished task 3.0 in stage 0.0 (TID 3) in 950 ms on localhost (5/5)
14/12/07 21:32:00 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
14/12/07 21:32:00 INFO DAGScheduler: Stage 0 (count at HelloElasticsearchSpark.java:25) finished in 0.977 s
14/12/07 21:32:00 INFO SparkContext: Job finished: count at HelloElasticsearchSpark.java:25, took 1.08602996 s
Count of records founds is 147
5つのタスクがそれぞれのシャードに対して実行されました。
まとめ
こんな感じでSparkのドライバでEsInputFormatを指定するだけで、elasticsearchからRDDを作成することができ、しかも高度な検索機能までついてきました。
ログが増えてきたらnumber_of_shardsを増やして翌日分からスケールアウトとか、elasticsearchのノウハウがまるっと使えるのが、とてもいいですね。
elasticsearch-hadoopのおかげで、年末はSparkを使って遊べそうです。
ここまで読んでくださって、ありがとうございました。
次の記事は@snuffkinさんです。