この記事はFUJITSU Advent Calendar 2023の22日目の投稿です。
LLVM Projectの実行バイナリの最適化ツールBOLTについて書きたいと思います。
BOLTの最適化
論文によると、BOLTの主要な最適化はメモリ配置最適化です。これは実行オブジェクト(ELF)のメモリアドレスをソートして、アクセス頻度の高い処理(関数や基本ブロック)の命令コードがキャッシュ(I-Cache)に残りやすいように再配置するというものです。
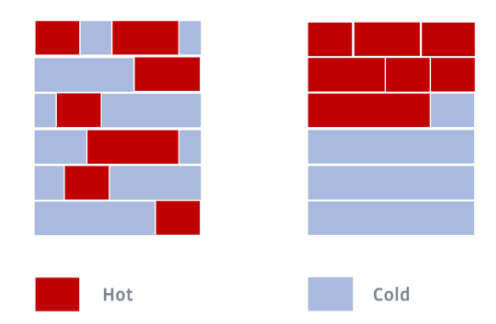
メモリ再配置はメモリのホットスポットをソートするイメージ(右が最適化後)
引用元: Optimizing the Linux Kernel with LLVM
また、これに加えていくつかのアーキレベルの最適化が可能です。
BOLTはオブジェクトを逆アセンブルし、LLVMバックエンドの後段の中間表現(MC/MCInst)まで戻して命令を解析しています。そのため、コンパイラレベル(IRレベル)の最適化はできませんが、マシンコードに近い状態での細かい最適化が可能のようです。
インストール方法
インストール方法にしたがってビルド・インストールすることができます。
適用方法
BOLTはELFのリロケーション情報と実行プロファイルを利用します。
ドキュメントに沿って以下の手順で最適化します。
- Step 0: 実行オブジェクト(ELF)の生成
最適化対象の実行オブジェクトはリンク時に-Wl,-qオプションを付与し、リロケーション情報(.rela.text)を保持しておく必要があります。 - Step 1: プロファイルの取得
perf recordでサンプリングプロファイルを取得します。
$ perf record -e cycles:u -j any,u -o perf.data -- <executable> <args> ... - Step 2: プロファイルの変換
perf2boltでプロファイルをBOLTの形式に変換します。
$ perf2bolt -p perf.data -o perf.fdata <executable> - Step 3: 最適化
llvm-boltで実行オブジェクトを最適化します。
$ llvm-bolt <executable> -o <executable>.bolt -data=perf.fdata -reorder-blocks=ext-tsp -reorder-functions=hfsort -split-functions -split-all-cold -split-eh -dyno-stats
アプリケーションへの適用例
実践事例のClangの最適化を試してみました。ここでは3つのstageで以下のようにclangを作成しています。(手順はAppendixに記載しました)
- stage1: ビルド用の
clangを作成 - stage2: PGO, LTOで最適化した
clangを作成 - stage3: stage2の
clangをBOLTで最適化
LLVMのバージョンはrelease/17.xとしました。
stage2でのclangをclang-17.org、BOLTで最適化したclangをclang-17.boltとします。以下のようにPATHを通したclang-17に対してシンボリックリンクを張ることで置き換えられます。
$ mv clang-17 clang-17.org
$ ln -fs clang-17.bolt clang-17 # BOLT適用のClangが使われる
$ ln -fs clang-17.org clang-17 # オリジナルのClangが使われる
BOLTで最適化したclang-17.boltは.textとしてHot([27])とCold([28])の再配置されたセクションが追加されていることがわかります。
$ readelf -S stage2-prof-use-lto/install/bin/clang-17.bolt | grep text
[13] .bolt.org.text PROGBITS 0000000001c423c0 01c413c0
[27] .text PROGBITS 0000000005600000 05400000
[28] .text.cold PROGBITS 0000000006079b00 05e79b00
それぞれのclangで再度別のclangをビルドさせたときの性能(実行時間、命令数、L1-icacheミス数、分岐ミス数)を測定したところ以下のようになりました。(8並列で実行)
- PGO+LTOで最適化した
clang
908.873482227 seconds time elapsed
23756046943016 instructions
1291835627141 L1-icache-misses
180990120408 branch-misses
- PGO+LTO+BOLTで最適化した
clang
828.821684585 seconds time elapsed
23688958701467 instructions
1039604605495 L1-icache-misses
174180292775 branch-misses
測定スクリプト
$ CPATH=${TOPLEV}/stage2-prof-use-lto/install/bin/
$ cmake -G Ninja ${TOPLEV}/llvm-project/llvm \
-DLLVM_ENABLE_PROJECTS="clang" \
-DLLVM_TARGETS_TO_BUILD=X86 -DCMAKE_BUILD_TYPE=Release \
-DCMAKE_C_COMPILER=$CPATH/clang -DCMAKE_CXX_COMPILER=$CPATH/clang++ \
-DLLVM_USE_LINKER=lld -DCMAKE_INSTALL_PREFIX=${TOPLEV}/stage4-eval/install
$ ninja clean
$ perf stat -e instructions,L1-icache-misses,branch-misses ninja clang
BOLTを適用したことで、10%近く実行時間が短縮しています👏
この例では、評価と同じ条件(clangをビルドしたとき)で取得したプロファイルをつかってBOLTの最適化をしています。プロファイル取得時と異なるタスクでは、最適化の効果は薄くなる可能性があります。
環境
CPU: Intel Core(TM) i7-9700 CPU
MEM: DDR4-2666
OS: Ubuntu 22.04
Appendix: Clangの最適化の手順
流れは以下のとおりです。
stage1: ビルド用のclangを作成
最適化対象のclangのビルドに使用するclangをgccでビルドします。
TOPLEVは任意のディレクトリで、直下にllvm-projectのソースコードをダウンロードしています。
スクリプト
$ mkdir {TOPLEV}/stage1
$ cd {TOPLEV}/stage1
$ cmake -G Ninja ${TOPLEV}/llvm-project/llvm -DLLVM_TARGETS_TO_BUILD=X86 \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_C_COMPILER=gcc -DCMAKE_CXX_COMPILER=g++ -DCMAKE_ASM_COMPILER=gcc \
-DLLVM_ENABLE_PROJECTS="clang;lld" \
-DLLVM_ENABLE_RUNTIMES="compiler-rt" \
-DCOMPILER_RT_BUILD_SANITIZERS=OFF -DCOMPILER_RT_BUILD_XRAY=OFF \
-DCOMPILER_RT_BUILD_LIBFUZZER=OFF \
-DCMAKE_INSTALL_PREFIX=${TOPLEV}/stage1/install
$ ninja install
stage2: PGO, LTOで最適化したclangを作成
ここでは、PGO+LTOで最適化したclangをビルドしています。
PGOはプロファイルを利用した最適化です。そのため、インストルメント(計測機能)を埋め込んだclangで何らかのタスク(コンパイル)を行い、実行プロファイルの取得することになります。
1). インストルメントを埋め込んだclangのビルド
まずは、インストルメントを埋め込んだclangをビルドします。
スクリプト
$ export CPATH=${TOPLEV}/stage1/install/bin
$ mkdir ${TOPLEV}/stage2-prof-gen
$ cd ${TOPLEV}/stage2-prof-gen
$ cmake -G Ninja ${TOPLEV}/llvm-project/llvm -DLLVM_TARGETS_TO_BUILD=X86 \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_C_COMPILER=${CPATH}/clang -DCMAKE_CXX_COMPILER=${CPATH}/clang++ \
-DLLVM_ENABLE_PROJECTS="clang;lld" \
-DLLVM_USE_LINKER=lld -DLLVM_BUILD_INSTRUMENTED=ON \
-DCMAKE_INSTALL_PREFIX=${TOPLEV}/stage2-prof-gen/install
$ ninja install
2). プロファイルの取得
インストルメントを埋め込んだclangでタスクを実行し、プロファイルを取得します。
ここでは、再度clangをビルドするというタスクをしています。プロファイルはstage2-prof-gen/profilesに配置されます。
スクリプト
$ export CPATH=${TOPLEV}/stage2-prof-gen/install/bin
$ mkdir ${TOPLEV}/stage2-train
$ cd ${TOPLEV}/stage2-train
$ cmake -G Ninja ${TOPLEV}/llvm-project/llvm -DLLVM_TARGETS_TO_BUILD=X86 \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_C_COMPILER=${CPATH}/clang -DCMAKE_CXX_COMPILER=${CPATH}/clang++ \
-DLLVM_ENABLE_PROJECTS="clang" \
-DLLVM_USE_LINKER=lld -DCMAKE_INSTALL_PREFIX=${TOPLEV}/stage2-train/install
$ ninja clang
プロファイルはstage2-prof-gen/profilesに配置されます。
複数のプロファイルが配置されるため、以下のコマンドでマージします。
$ cd ${TOPLEV}/stage2-prof-gen/profiles
$ ${TOPLEV}/stage1/install/bin/llvm-profdata merge -output=clang.profdata *
3). PGO+LTOの最適化を有効にしclangをビルド
取得したプロファイルによるPGO、およびLTOを有効にしてclangをビルドします。コンパイラはstage1のclangを使用します。
また、このclangはBOLTを適用することになるため、リンクオプションとして-Wl,-qを指定します。
スクリプト
$ export CPATH=${TOPLEV}/stage1/install/bin
$ mkdir ${TOPLEV}/stage2-prof-use-lto
$ cd ${TOPLEV}/stage2-prof-use-lto
$ export LDFLAGS="-Wl,-q"
$ cmake -G Ninja ${TOPLEV}/llvm-project/llvm -DLLVM_TARGETS_TO_BUILD=X86 \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_C_COMPILER=${CPATH}/clang -DCMAKE_CXX_COMPILER=${CPATH}/clang++ \
-DLLVM_ENABLE_PROJECTS="clang;lld" \
-DLLVM_ENABLE_LTO=Full \
-DLLVM_PROFDATA_FILE=${TOPLEV}/stage2-prof-gen/profiles/clang.profdata \
-DLLVM_USE_LINKER=lld \
-DCMAKE_INSTALL_PREFIX=${TOPLEV}/stage2-prof-use-lto/install
ninja -j 1 install ## 並列数はメモリ不足を考慮して設定
stage3: stage2のclangをBOLTで最適化
stage2で作成したclangにBOLTを適用して最適化します。
前述の通り、BOLTはプロファイルを使用します。stage3では、まずそのプロファイルをperfで取得します。
スクリプト
$ export CPATH=${TOPLEV}/stage2-prof-use-lto/install/bin
$ mkdir ${TOPLEV}/stage3
$ cd ${TOPLEV}/stage3
$ export LDFLAGS="-Wl,-q"
$ cmake -G Ninja ${TOPLEV}/llvm-project/llvm \
-DLLVM_ENABLE_PROJECTS="clang" \
-DLLVM_TARGETS_TO_BUILD=X86 -DCMAKE_BUILD_TYPE=Release \
-DCMAKE_C_COMPILER=${CPATH}/clang -DCMAKE_CXX_COMPILER=${CPATH}/clang++ \
-DLLVM_USE_LINKER=lld -DCMAKE_INSTALL_PREFIX=${TOPLEV}/stage3/install
ninja -j 1 install ## 並列数はメモリ不足を考慮して設定
プロファイルprof.dataが取得できたら、それをBOLTの読み込める形式に変換します。clang-17が最適化対象です。
$ export CPATH=${TOPLEV}/stage2-prof-use-lto/install/bin
$ perf2bolt $CPATH/clang-17 -p perf.data -o clang-17.fdata -w clang-17.yaml
変換後のclang-17.yamlを使ってBOLTを適用します。
$ llvm-bolt $CPATH/clang-17 -o $CPATH/clang-17.bolt -b clang-17.yaml \
-reorder-blocks=ext-tsp -reorder-functions=hfsort+ -split-functions \
-split-all-cold -dyno-stats -icf=1 -use-gnu-stack
${TOPLEV}/stage2-prof-use-lto/install/bin/clang-17.boltが作成されていることを確認します。
BOLTが適用されているかどうかは.noteを参照することで確認できます。
$ readelf -p .note.bolt_info stage2-prof-use-lto/install/bin/clang-17.bolt | grep BOLT
[ 10] BOLT revision: 6009708b4367171ccdbf4b5905cb6a803753fe18, command line: llvm-bolt ...