こんにちは。某大文学部で言語学を専攻する大学4回生です。
卒論に書くためのデータ採取をTwitterAPIでしようと思い、一念発起してPythonを始めました。
プログラミング知識ゼロから始めたド素人です。あと数学が絶望的にできないド文系です。
何ならQiitaに登録したのも今日……(API関連の記事をストックしおきたかったので)。
やりたかったこと(そんな難しいことではない)
①Twitter上の特定の文字列を含んだツイートからテキストデータを取得
②その特定の文字列と、その前後10文字をtxtまたはCSVファイルにぶちこむ
③それを分析(これは後日やります)
背景
今日から10日前、卒論の中間報告が迫ってきており、何とか進捗を生まないとまずいという時期になったため、いざPythonの勉強を始めました(遅い)。お世話になったのは
です。プログラミングのプの字も知らない私にも読め、1冊目として非常に助かりました。ちゃんとPythonのインストール方法から始めてくれたので。。。
最初は本を買わずにネット先行事例を辿れば行けるかと思っていたのですが、やはり基本的な事項を押さえておかないと何も始まらないことを痛感いたしました。
Python歴2日目に人生で初めて自分で書いたコードが以下になります。上記の参考書p.78の演習問題(任意の整数を受け取ってコラッツ数列を出す)です。思い出深い。
def collatz():
global number
if number % 2 == 0 :
number = int(number / 2)
print(number)
elif number % 2 == 1 :
number = 3 * number +1
print(number)
while True:
print('整数を入力してください:')
try:
number = int(input())
break
except ValueError:
print('整数以外の入力は無効です。')
continue
while number != 1:
collatz()
お目汚し失礼しました。
TwitterAPIを使えるようになりたい
さて、先行事例を参照しつつ、TwitterAPIを使うためには何やらdeveloperアカウントを登録をしなければならないようです(投稿などせず、検索だけでも)。
こちらを参考にさせていただきつつ、登録を進めていきました。ありがとうございます。
2019年8月やし変わってへんやろ、と思ってましたがやや変わっていました(?)
具体的には、個人か団体かの利用を選んで、個人利用にすれば「所属組織に関する情報」などはいれなくても良かったです。
また、私の時は英作文を送信して規約に同意し、来たメールの「Confirm your email」をクリックしたらすぐに「You did it!」と言われました(reviewの時間やreviewのためのメールのやりとりがあるものと思っていたのですが……)
ひとまずこうしてdeveloperアカウントが取得できたので、appを作成しました(app的なものを作成するつもりはないのですがConsumer key、Consumer secret、Access token、Access token secretが必要なので)。
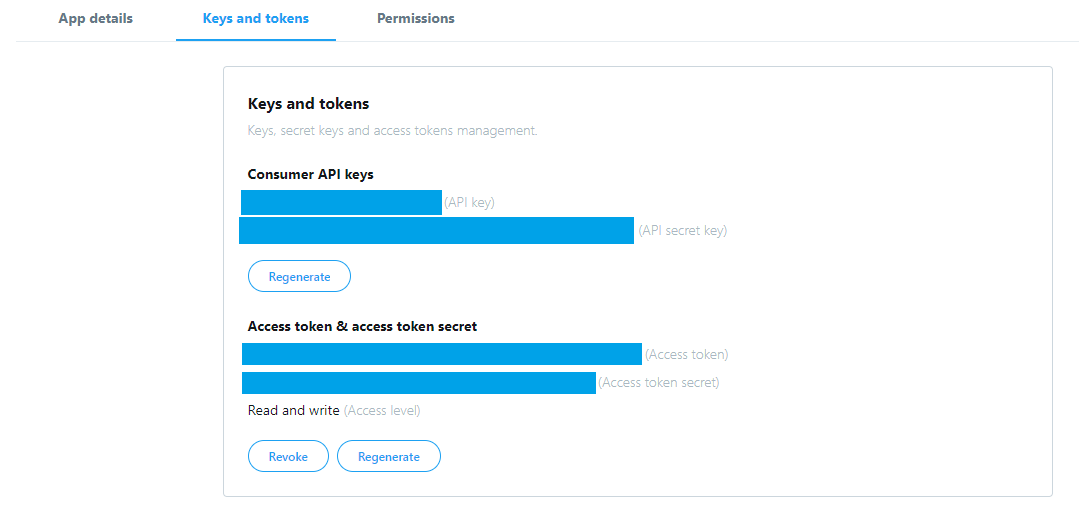
英作文が難しかったですが、ひとまずこれでConsumer key、Consumer secret、Access token、Access token secretの4つが取得できました。
Pythonから最近のツイートを検索する
結論、これはできました。楽しかったです。
こちらを参考にさせていただきました。ありがとうございます。
そのうえで、
['検索文字列の前10文字', '検索文字列', '検索文字列の後10文字']
というリストにしてCSVに書き出せばいいかな~と思っていたので、
めちゃくちゃ汚いコードを書き加えました。初心者って感じです。絶対もっとうまく書ける。1
いったん試しに'"ピクミン"'で検索してみます。
# ! python3
# -*- coding: utf-8 -*-
import json
from requests_oauthlib import OAuth1Session
# OAuth認証部分
CK = '取得したConsumer key'
CS = '取得したConsumer secret'
AT = '取得したAccess token'
ATS = '取得したAccess token secret'
twitter = OAuth1Session(CK, CS, AT, ATS)
# Twitter Endpoint(検索結果を取得する)
url = 'https://api.twitter.com/1.1/search/tweets.json?tweet_mode=extended'
# Enedpointへ渡すパラメーター
keyword = '"ピクミン"'
params ={
'count' : 20, # 取得するtweet数
'q' : keyword # 検索キーワード
}
req = twitter.get(url, params = params)
if req.status_code == 200:
res = json.loads(req.text)
for line in res['statuses']:
#print(line['text']) #取得自体が上手く行っているか試すprint
#'ピクミン'で分割、前後10字を取得して再結合。この辺以降急に汚くなります(私が書いたので)
spam = line['full_text'].split('ピクミン')
spam.insert(1, 'ピクミン')
#print(spam) #リストに分割する前のspamが上手く取得できているか試す時のprint
spammae = spam[0]
spammae10 = spammae[-10:]
spamusiro = spam[2]
spamusiro10 = spamusiro[:10]
spamlist = [spammae10, 'ピクミン', spamusiro10]
print(spamlist)
print('*******************************************')
else:
print("Failed: %d" % req.status_code)
これを回すとこんな感じで検索結果の取得・リスト書き出しができました。(四角はリプ相手のID部分)
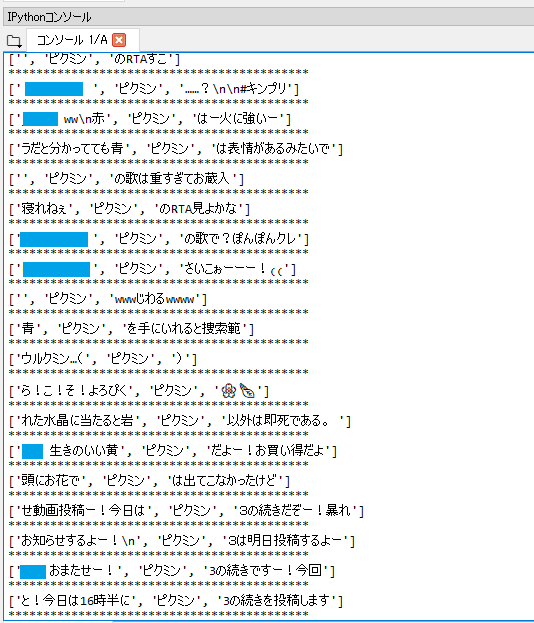
ここまでたどり着いたのが昨日です。
ここに至るまでは結構順調でしたね……(トオイメ
まあ私が敗北した(というより自爆した)のは、下調べを怠ったまま進めてきたのが悪かったんですが。
ちょっと長くなってきたので、私がしたかったことは結局のところ何で、それが普通にできなかったという話は次回に続きます。
2019/10/07追記
次回:プログラミング歴10日の人がTwitterAPIに負けた話 #2
-
後輩に「spam.insertのあと spamlist = [spam[0][-10:], spam[1], spam[2][:10]]で一発でいける気がします」って言われました。間違いない。ありがとうございます。(2019/10/06投降後追記) ↩