この記事の概要と想定するユースケース
この記事は、Python でスクレイピングを行うためのフレームワーク Scrapy で、JavaScript が関係する処理を行うためのライブラリ scrapy-playwright に関する記事です。
後で詳しく述べるように、scrapy-playwright で取得したページに対する処理を実行するには、大きく分けて、 callback 関数(=Scrapy の spider 側の parse などの関数)が呼ばれる前に実行される playwright_page_methods として指定する方法 と、 callback 関数内に記述する方法 の2種類があります。
この記事では、前者の playwright_page_methods である程度複雑な処理を書きたい場合に、JavaScript で処理を記述し、それを evaluate で読ませるというやや裏技的な方法について紹介しています。
Scrapy の HTTP Cache でデータを保存する際に、「<もっと見る>ボタンをクリックして、全データを表示させる」など一定の JS 処理を実行した後のページ内容を保存したいなどの需要がある際に参考にしていただければと思います。
scrapy-playwright の紹介と参考になるサイト
(Playwright の成立経緯などについては別途詳しい記事がありますので、ここでは Scrapy 利用者の観点からのみ述べます)
JavaScript でレンダリングされるサイトを対象に Scrapy でスクレイピングを行ったり、サイト上でボタンをクリックなどの操作を行いたい場合、本記事で紹介する scrapy-playwright などのツールを追加で使用する必要があります。
上記の記事で各ツールの Pro/Con として紹介されているように、Scrapy Puppeteer や Scrapy Selenium はメンテナンスがなされていないこともあり、本記事の執筆者は、scrapy-playwright を使用しています。
やや脱線しますが、Scrapy 用の情報に限らず、JavaScript レンダリングのサイトを対象とした Python でのスクレイピングに関する情報・ツール紹介では、記事の書かれた日時をよく確認した方がよいです。
現在使われているツールはほぼ ChromeDriver などをヘッドレスブラウザとして使用して JS レンダリングを行うと思いますが、この ChromeDriver とのバージョンとツールのバージョンの嚙み合わせなどの問題が起きやすく、ツール選択によっては思わぬ負担が発生しかねません。
scrapy-playwright は、この辺をよしなにやってくれます。
Selenium などの場合は、「このバージョンの ChromeDriver とならうまく動作するよ」という依存関係で固めた Docker イメージを活用する方向になるかと思います。
この scrapy-playwright ですが、公式でも書かれているように、Playwright for Python を使用した wrapper プログラムです。
また、Playwright for Python 自体が、Node.js のライブラリである Playwright を Python で使えるようにしたライブラリであるという特性を持っています。
そのため、何か困ったときに参照すべきサイトとして、第一は scrapy-playwright の公式ページですが、例えば「scrapy_playwright.page.PageMethod(method: str, *args, **kwargs)」の method として指定できる具体的な処理はなんだっけ?といった疑問は、Playwright の API の公式ページの Page メソッドの一覧で確認するなど Playwright の公式ページを見る必要があります。
(scrapy-playwright の公式ページも適宜 Playwright の公式ページにリンクを飛ばしています)
また、海外では、スクレイピング用のツールやダッシュボード、プロキシ、コンサルティングや実装サービスなどを提供する事業者が、集客目的でツールの紹介記事などを書いているケースが多いのですが、最新の情報をさらっと確認したいという目的などでは有用です。
以下は scrapy-playwright の非公式 getting started 的な内容ですが、最初にサクッと触って動かすという目的では、公式ページにあるリファレンス的な情報が削られている分、ハードルが低くてよいかもしれません。
(ただし、「動かせた」後に、自分の目的通りの挙動を得たい場合などには、公式ページのお世話になるケースが多いかと思います)
本記事では、scrapy-playwright の使用法という点から、スクレイピングでの活用に絞って触れていますが、Python Playwright 自体は、テストツールとしての側面の方が強く、情報をググっても、スクレイピング観点での情報はやや見つけにくいです。
scrapy-playwright でページ上でアクションを実行する2つの方法とその実行タイミング
公式ページの「Executing actions on pages」というセクションが詳しいのですが、Scrapy の spider 側の parse 用の関数(=Scrapy のリクエストの callback 関数として指定される関数)より 「前」 に実行されるかそれとも 「parse 用の関数内」 で実行されるかで、大きく2つの方法が用意されています。
公式ページでも紹介されている通り、以下のコードは、screenshot の撮影アクションの実行という点では等価で、異なるのはその記述場所と実行タイミングです。
def start_requests(self):
yield Request(
url="https://example.org",
meta={
"playwright": True,
"playwright_page_methods": [
PageMethod("screenshot", path="example.png", full_page=True),
],
},
)
def parse(self, response, **kwargs):
screenshot = response.meta["playwright_page_methods"][0]
# screenshot.result contains the image's bytes
def start_requests(self):
yield Request(
url="https://example.org",
meta={"playwright": True, "playwright_include_page": True},
)
async def parse(self, response, **kwargs):
page = response.meta["playwright_page"]
screenshot = await page.screenshot(path="example.png", full_page=True)
# screenshot contains the image's bytes
await page.close()
詳しくは、scrapy-playwright の公式ページで確認してほしいのですが、Scrapy の Request を作成するときの meta 情報で「playwright: True」を指定することで、Playwright をダウンロードハンドラとして使用するように指定しているところまではどちらのコードも同じです。
異なるのは、前者のコードでは、playwright_page_methods で、使用したいメソッドと、指定すべき引数を渡し、その結果を parse 関数内の「response.meta["playwright_page_methods"][0]」で受け取っている点です。
(playwright_page_methods はリスト形式で複数指定できるので、その結果もリスト形式で返されるので、その位置に応じてインデックス番号を指定)
これに対して、後者のコードでは、「"playwright_include_page": True」を指定することで、ダウンロードハンドラとして指定した Playwright が使用した Page 自体を response.meta 経由で parse 関数に受け渡してもらい、その page 上でスクリーンショット撮影を行っています。
実行タイミングの話を除くと、直感的には、parase 関数で処理を書く方が柔軟でコードの可読性も担保しやすいと感じるかと思いますが、その通りだと思います。
parase 関数で page を受け取る場合、公式ページでも注意されている通り page.close() が確実に行われるように記述し、errback 関数なども別途作成して指定する必要がある点は要注意ですが、ある程度複雑な処理は、特段の理由がなければ parse 関数に書いてしまう方が楽なはずです。
Scrapy での HTTP Cache の保存タイミングとダウンロードハンドラ・ダウンロードミドルウェアの動作の仕組み
こうした違いを踏まえたうえで、執筆者は、以下のように HTTP Cache に保存される内容の違いから、処理の実行タイミングの点で、playwright_page_methods で処理を実行したいと考えました。
Scrapy でのダウンロードリクエストとその結果のレスポンスが処理されていく流れに触れる必要があるのですが、Scrapy 公式ページの「Architecture overview」に掲載されている図を参照しながら説明します。
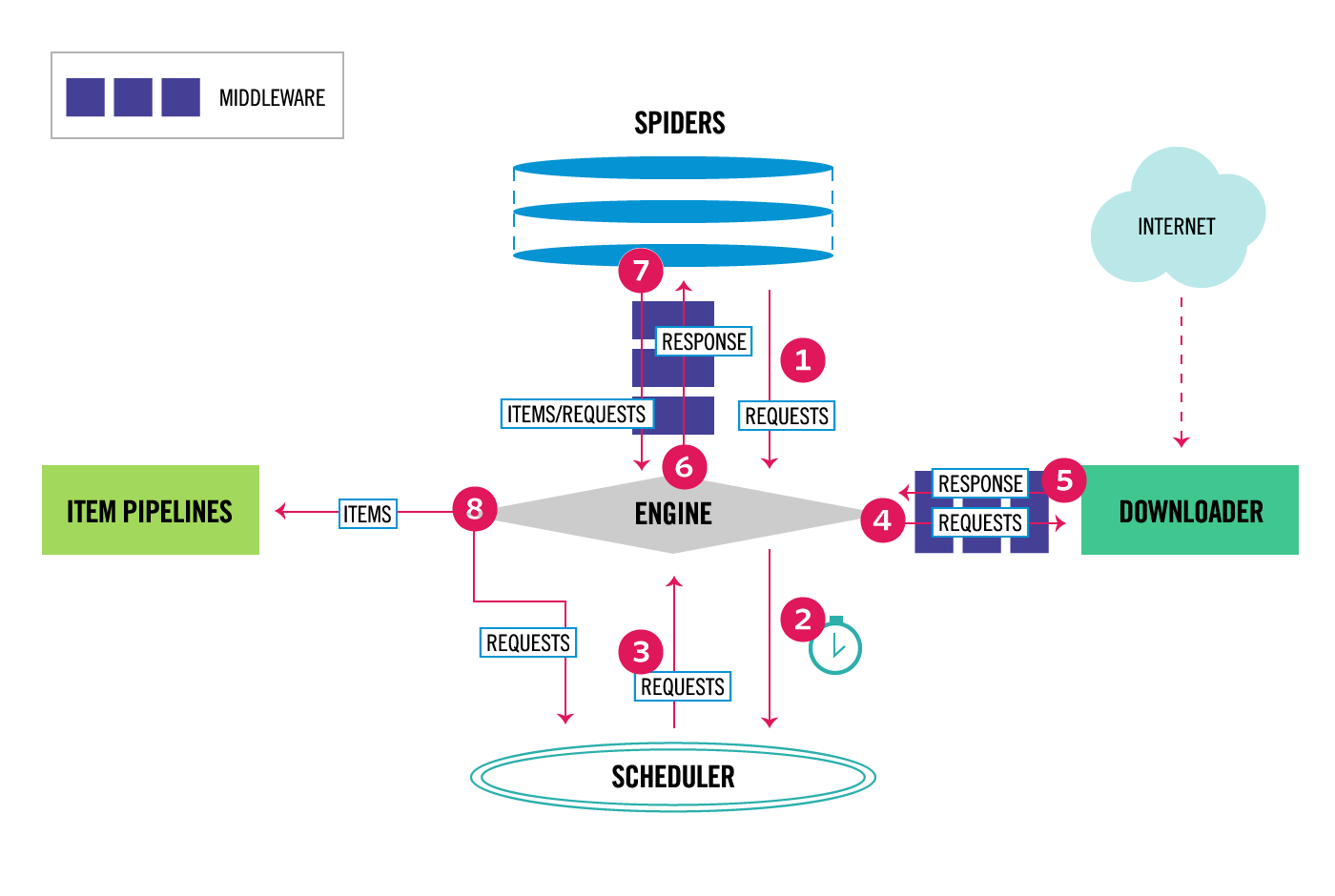
ここまで parse 用の関数と呼んできたものは、図の中央上の Spiders の位置にあるのですが、ここで作成された Request は、②と③のスケジューラーでの手配を経て、④で Request 内容に適宜処理を受けながら Downloader の位置に運ばれ、ここでダウンロード・ハンドラで Web ページのダウンロードが実行された後、⑤で Response 内容に適宜処理を受けながら、Engine を経由して Spider に返され(⑥)、Spider に記載された parse 用の関数の処理を受けるという流れになります。
この④と⑤の部分に書かれているのが Scrapy のダウンロード・ミドルウェアと呼ばれるもので、ダウンロード・ミドルウェアは指定された order 番号に沿って、④のプロセスでは番号の若い順に、⑤のプロセスでは番号の大きい順に実行されます。
ダウンロード・ミドルウェアとダウンロード・ハンドラの動作の模式図
(④のプロセス)
ダウンロードミドルウェア(order 番号:100)
↓
ダウンロードミドルウェア(order 番号:500)
↓
ダウンロードミドルウェア(order 番号:800)
↓
ダウンローダー
(設定に応じて Playwright などがダウンロード・ハンドラとして使用される)
↓
(⑤のプロセス)
ダウンロードミドルウェア(order 番号:800)
↓
ダウンロードミドルウェア(order 番号:500)
↓
ダウンロードミドルウェア(order 番号:100)
↓
Scrapy Engine
(⑥「のプロセス)
↓
Spider:parse 用の関数
そして、Scrapy の組み込みの HTTP Cache は、実は、ダウンローダー(ダウンロード・ハンドラ)にとても近い位置にある order 番号 900 のダウンロード・ミドルウェアとして実装されています。
流れとしては次の模式図の通りですが、ざっくりと比喩的なイメージで話すと、④の流れでは、リクエストされた URL に対して有効期限内の HTTP Cache が存在するなら、リクエストをダウンローダに渡さずにキャッシュされたデータを返す、最後の門番のような役割として働き、⑤の流れでは、 取得されたリスポンスが、他のダウンロードミドルウェアや Spider の parse 用の関数で処理される前の状態で保存する という役目を担っています。
HTTP Cache ダウンロード・ミドルウェアの動作位置の模式図
(④のプロセス)
ダウンロードミドルウェア(order 番号:100)
↓
ダウンロードミドルウェア(order 番号:500)
↓
ダウンロードミドルウェア(order 番号:800)
↓
HTTP Cache ダウンロードミドルウェア(order 番号:900)
↓
ダウンローダー
(設定に応じて Playwright などがダウンロード・ハンドラとして使用される)
↓
(⑤のプロセス)
HTTP Cache ダウンロードミドルウェア(order 番号:900)
↓
ダウンロードミドルウェア(order 番号:800)
↓
ダウンロードミドルウェア(order 番号:500)
↓
ダウンロードミドルウェア(order 番号:100)
↓
Scrapy Engine
(⑥「のプロセス)
↓
Spider:parse 用の関数
そして、Scrapy の HTTP Cache のこうした仕組みを踏まえると、たとえば「Playwright でページ上の<もっと情報を見る>ボタンをクリックしてデータがすべて出そろった状態のページを HTTP Cache に保存したい」というニーズがある場合、parse 関数に Playwright の処理を書くわけにはいかず、playwright_page_methods で処理を指定するという話になるわけです。
scrapy-playwright の page method で複雑な処理を実装するのに、evaluate メソッドを活用する
「初期状態では50件しかデータが表示されないページで、<もっと見る>ボタンを一定間隔でクリックし、ボタンの属性が「display: none」になるまで繰り返す」という処理自体を書くことは while 文などを使えばある程度簡単です。
しかし、playwright_page_methods で指定できるメソッドと引数の通常の組み合わせでは、こうした条件分岐を伴う処理の指定は困難です。
(「指定した回数だけボタンをクリックする」ような操作は、その回数だけ playwright_page_methods の処理を指定することで可能だと思いますが、ページの状態を条件にして処理の繰り返し回数を決めたりすることは難しそうです)
こうした場合に、JavaScript のコードを文字列として受け取って実行する evaluate に、条件分岐なども含めて JavaScript で書いたコードを引数として渡すという方法も一つのオプションです。
scrolling_script = """
const scrolls = 8
let scrollCount = 0
// scroll down and then wait for 0.5s
const scrollInterval = setInterval(() => {
window.scrollTo(0, document.body.scrollHeight)
scrollCount++
if (scrollCount === numScrolls) {
clearInterval(scrollInterval)
}
}, 500)
"""
class ScrapingClubSpider(scrapy.Spider):
name = "scraping_club"
allowed_domains = ["scrapingclub.com"]
def start_requests(self):
url = "https://scrapingclub.com/exercise/list_infinite_scroll/"
yield scrapy.Request(url, meta={
"playwright": True,
"playwright_page_methods": [
PageMethod("evaluate", scrolling_script),
],
})
こちらは、Zenrows.com の「Scrapy Playwright: Complete Tutorial 2023」で紹介されていたコードですが、このように script を JavaScript で書いて evaluate で実行させるかたちなら、JavaScript で書ける限り、任意の処理を playwright_page_methods 実行させることができます。
難点1:コメントで書くのでコード補完などが効かない
短い処理ならまだよいのですが、コード補完や文法チェックなしで JavaScript のコードを書くのは辛いです。
難点2:Python でコードを書いていたはずが JavaScript のコードを書いている
そもそも Python の Scrapy をスクレイピング用のフレームワークに使用している前提なので、JavaScript には詳しくない・積極的に書こうとは思わないという方も多いかと思います。
自分もそうした一人ですが、他の方法よりは手軽そうという理由で ChatGPT (Bing) の力も借りて、該当するコードを作成して利用しました。
ChatGPT には「<もっと見る>ボタンを一定間隔でクリックし、ボタンの属性が「display: none」になるまで繰り返す」のような要件で、JavaScript のコードを書いてもらってもよいと思いますし、
Zenrows.com の「Scrapy Playwright: Complete Tutorial 2023」のサンプルコードなどをまず読ませて、evaluate というメソッドがあることを理解してもらってから、このフォーマットに合わせて、希望する処理の JavaScript に書き換えてもらうこともよいと思います。
また、特に While 文の処理などは、適切に書かれていないと処理が止まらない可能性などもありますので、ブラウザの開発コンソールで、対象の Web ページで期待する動作が行われるか確認したり(これも、ChatGPT に、開発コンソールで JavaScript の部分だけ動作を試すにはどうしたらよいか?と尋ねると、よしなにコードを出力してくれます)、なんらかのカウントとその上限を設定するとよいかと思います。
自分もそのように Bing におんぶにだっこで作成したコードが以下になります。
もっといい書き方はあると思いますが、ご参考までに。
(クリックの後に明示的に 5 秒待つなどは、やり過ぎだったりするかと思いますが、安全側に倒したかったということでお見逃しください)
def parse(self, response):
categories = response.xpath('/html/body/main/section/div/ul/li/a')
for category in categories:
category_item = CategoryPage()
category_item["category_text"] = category.xpath('./text()').get()
category_item["list_page_url"] = category.xpath('./@href').get()
#中略
yield category_item
yield scrapy.Request(
url = category_item["list_page_url"],
callback= self.parse_list_page,
meta=dict(
playwright = True,
playwright_page_methods = [
PageMethod('wait_for_timeout', 2000),
PageMethod("evaluate", """
(async () => {
const buttonText = 'もっと見る';
let clickCount = 0;
while (true) {
const buttons = Array.from(document.querySelectorAll('button'));
const targetButton = buttons.find(button => button.textContent.includes(buttonText));
if (targetButton && window.getComputedStyle(targetButton).display !== 'none') {
targetButton.click();
clickCount++;
await new Promise(resolve => setTimeout(resolve, 5000));
} else {
break;
}
}
return clickCount;
})()
"""),],
category_item_dict=category_item
))
def parse_list_page(self, response):
category_item_dict = response.meta["category_item_dict"]
click_count = response.meta["playwright_page_methods"][1].result
stores = response.xpath('/html/body/main/div/div/section/div/section/ul/li')
#後略
JavaScript の部分についてはページ内の button 要素の中で「もっと見る」という文字列を含む部分を、それが「display: none」になるまで5秒間隔でクリックするというものになっています。
この処理が実行されることで parse_list_page 関数が受け取る response はすべてのデータが読み込まれた状態になっており、保存される HTTP Cache も、この状態のデータとなります。
(これにより、xpath や値の validation などを調整している段階で、xpath を変更するたびに相手先サイトにリクエストを送ったりすることなく、HTTP Cache に保存されているデータを対象に存分に試行錯誤を行うことができます)
また、動作確認の点でも、何回クリックしたかの情報は取得したかったので、clickCount を return 値とすることで、後続の parse_list_page 関数でも response.meta から返り値を取得しています。
おわりに
今回が初の Qiita 投稿なのですが、自分では分かっているつもりのことでも、いざ書くとなると、ここまで言い切っていいのかなと確認したりしながらの作業になり3時間くらいかかってしまいました。
自分がこれまでよんできた技術記事も、そうした見えにくい確認などの手間をかけて執筆されてきたのだなと感じ、改めて感謝です。
スクレイピング関連で、今回のようなニッチな情報ですがいくつかネタはあるので、また時間を見つけて記事を投稿できればと思います。
また、今回の裏テーマとして、海外のスクレイピング界隈の事業者が投稿している記事は、自社サービスへの集客目的だったりはするものの、最新情報をさらっと入手するという点では意外と役に立つという点と、ツールの移り変わりが早いので記事の更新日には要注意という点も少しはアピールできていたら幸いです。