理論編
iOSでも機械学習モデルがつかえる
CoreMLをつかうことで、エッジデバイスでも学習済みモデルが使えます。
以下のモデルは全てiOSのデバイスでサーバー通信なしでつかえます。
Image Classification 画像分類
:EfficientnetをCore MLに変換する【変換済みモデルあり】
類似度測定
Object Detection 物体検出
:公式YOLOv3物体検出モデルをiOSで使う手順。
Semantic Segmentation 意味的画像分割
:DeepLab V3+ をCore MLに変換する
Image Generation 画像生成
:この記事
Style Transfer 画風転送
:ちょうかんたんStyle Transfer。AppleのCreate MLで
Sound Classification 音声分類
Text Classification テキスト分類
データ分類
連続値推定
Recommend 推奨
(参考記事は拙著)
iOSで機械学習モデルを使ったアプリの一例がこちら
AnimateU:画像生成で顔写真をアニメ風に
Blur:セマンティックセグメンテーションで人物を切り取ってぼかす
加工もどし:Pix2Pixで美顔加工をはがす



GANとはなにか
GANは機械学習の一分野。
画像でトレーニングすることにより、データ群と似た画像を生成したり、画像をデータ群のように変換できます。
Generator(前半)とDiscriminator(後半)というニューラルネットワークで構成されています。
ニューラルネットワークは、人間の脳に似た構造を持つ計算グラフが繰り返し計算を行い、自動的に課題に最適化したグラフ値になっていくというものです。
Generatorは、数値列OR画像を受け取り、画像を出力します。最初はランダムノイズの画像を生成します。
Discriminatorは、画像分類ネットワークです。「正解」と「不正解」を分類します。
データセット(正解)を受け取った時は1を出力し、Generatorからの画像(不正解)を受け取った時は出力を0に近づけるように誤差逆伝播法でトレーニングされます。
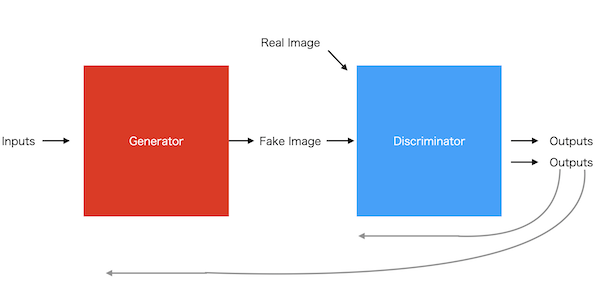
Generatorは自身の出力画像をDiscriminatorに渡し、Discriminatorの出力が正解に近づくように誤差逆伝播法でトレーニングされます。
2つのネットワークを順番にトレーニングすることで、Discriminatorは判別力を上げ、Generator は本物っぽい画像を生成するようになるというわけです。

この記事では、トレーニング済みGANモデルのGeneratorをiOS用に変換し、画像を生成します。
GANをiOSでつかうには
機械学習のモデルは、多くの場合TensorFlow やPytorchといったフレームワークで書かれています。
TensorFlowはGoogle、Pytorchはマイクロソフトがリリースしている機械学習用オープンソースです。
言語はPythonです。
そのままでは、iOSで使うことはできません。
iOSでこれらのモデルをつかうには、アップルのCore MLというフレームワークに変換します。
Core ML形式に変換したモデルは、xcodeのプロジェクトに組み込んでつかうことができます。
変換には、アップルのリリースしている変換ツールであるCore ML Toolsを用います。
Core ML ToolsはTensorFlowやPytorchの機械学習モデルを受け取り、Core MLモデルを出力します。
Core MLモデルファイルは、Xcode プロジェクトにドラッグ&ドロップでバンドルして使えます。

アプリでCore MLモデルを使うには、アップルのVision(コンピュータービジョン・フレームワーク)のVNCoreMLRequestでモデルの実行リクエストを出すことで、手軽に使えます。
Pythonわからなくても大丈夫

元のGANモデルはこのようにPythonで書かれています。Core MLに変換してつかうために、全ての機械学習のコードを理解している必要はありません。
肝は、変換するモデルをスクリプトの中で見つけることです。
変換スクリプト
さて、Core ML Toolsで他フレームワークからCore MLに変換するスクリプトがこちらです。
import coremltools as ct
mlmodel = ct.convert(model,
inputs=[ct.ImageType(shape=[1,256,256,3],bias=[-1,-1,-1], scale=1/127)]
引数のmodelには以下のいずれかの形式をあたえます。
| フレームワーク | モデル形式 |
|---|---|
| TensorFlow2 | tf.keras.Modelインスタンス, HDF file path(.h5), SavedModel directory path, concrete function |
| TensorFlow1 | Frozen graphインスタンス, Frozen graph file path (.pb) |
| Pytorch | TorchScript |
表のモデル形式に持ち込めればあとは上記変換スクリプトに渡すだけです。
Core MLへの変換の勘所は、Pythonスクリプトからいかにこれらのモデル形式を取り出すか、だと思います。
今回はgenerator のみを変換しますので、元のスクリプトからgeneratorを効率よく見つけるのがポイントかと。
ぼくがつよくおすすめするのは、元のプロジェクトのtestスクリプトからGeneratorを探すことです。
test スクリプトからたどれば、高確率で変換可能なモデルを見つけられます。
また、変換スクリプトにあるように、入力の前処理方法も理解しておく必要がありますが、これも元プロジェクトのテストから見つけることができます。
これらについては実践編でお伝えします。
モデルの保存
mlmodel.save('./gan.mlmodel')
(ここまではPython のコードとして実行します。)
Xcodeでの使用
入力が画像の場合
Vision フレームワークを使います。
VNCoreMLRequestを作成し、ImageRequestHandlerで実行します。
import Vision
lazy var coreMLRequest:VNCoreMLRequest = {
let model:VNCoreMLModel = try! VNCoreMLModel(for: gan(configuration: MLModelConfiguration()).model)
let request = VNCoreMLRequest(model: model, completionHandler: self.completionHandler)
return request
}
let handler = VNImageRequestHandler(ciImage: ciImage, options: [:])
DispatchQueue.global(qos: .userInitiated).async { [self] in
do {
try handler.perform([self.request])
} catch let error {
print(error)
}
}
Request の実行が完了したら、Completion Handlerが呼ばれます。
入力が数値列の場合
Core MLフレームワーク内のpredictionファンクションをつかいます。
let model = dcgan()
let input = try? MLMultiArray(shape: [1,100] as [NSNumber], dataType: MLMultiArrayDataType.float32)
for i in 0...input!.count - 1 {
input![i] = NSNumber(value: Float32.random(in: 0...1))
}
let mlinput = dcganInput(dense_input: input!)
let output = try? model.prediction(input: mlinput)
出力を画像に変える
方法1:Core ML Model自体を画像出力タイプに変える
デフォルトではCore MLモデルのアウトプットはmulti array になっています。
このままではアプリで画像として表示できません。
CoreMLモデルのアウトプットをpixel buffer にすることができます。
そのためのCore ML Toolsのコードスニペットがこれです。
import coremltools.proto.FeatureTypes_pb2 as ft
mlmodel = ct.models.MLModel('./gan.mlmodel')
spec = mlmodel.get_spec()
output = spec.description.output[0]
output.type.imageType.colorSpace = ft.ImageFeatureType.RGB
output.type.imageType.height = 256
output.type.imageType.width = 256
ct.utils.save_spec(spec, './ganImageOut.mlmodel')
Core ML Mmodelをspecという形式にしてから出力のタイプを変えて保存しています。
ただし、出力の形状がCore MLの幅、高さ、カラーチャネル、の順番の設定に合っていないとうまく出力できません。
その場合、最後のレイヤーで出力形状を変える必要があります。
方法2:Core ML Helpersをつかう
手軽なのは、出力をマルチアレイのままにしておいて、OSSのCore ML Helpersを利用することです。
Core ML Helpersにはマルチアレイを画像に変換できるヘルパー関数があります。
いろんな幅、高さ、チャンネルの配列形状に対応できるオプションがあるので、Core ML Helpersを用いてきちんと画像を出力できているのかを調べることをおすすめします。
MultiArrayからImageへの変換 CoreMLHelper by MLBoyだいすけ on Qiita
実践編
変換するモデルをさがす
モデルはGitHubやTensorFlow,Pytorch などのフレームワークのモデルハブ、あるいは機械学習やコンピュータヴィジョンのカンファレンスページなどで見つけることができます。
GitHub search Results:GAN
TensorFlow Hub
Pytorch Hub
そのほか、機械学習のカンファレンスやSNSでも見つけることができます。
GitHub でGANと検索してみましょう。
面白そうなモデルが並んでいます。
学習済みのケースと、自分で学習させるケース
GitHub上のモデルの場合、リポジトリの作者が事前にトレーニング・保存した重み(モデルの状態)をファイルとして公開してくれていることが多いです。この場合、その事前学習済みモデルからCoreMLモデルに変換できます。
事前学習済みモデルがない場合、もしくは自前のデータでトレーニングしたい場合は、自分でモデルをトレーニングしてから変換する必要があります。
DCGANの変換(TensorFlow2):トレーニングしてから変換
初期に作られたGANの基本的なモデル。
Generatorにランダムな数値をわたし、データ画像のような画像を生成するモデルです。
せっかくなのでTensorFlowのチュートリアルでDCGANをトレーニングしてから変換します。
Colabでトレーニング
TensorFlow Core DCGANチュートリアル Colaboratory ノートブック
Colabのセルを下まで順番に実行していくだけで、DCGANのトレーニングができます。
モジュールのインストール→データセットの読み込み→モデルの定義→トレーニングステップまで全てやってくれます。
なんのことやらわからなくても、とりあえず実行できれば大丈夫です。

トレーニングは数十分で終わります。
Colab上で変換
トレーニングが終わったら変換にうつります。
Colabノートブックでそのまま変換も書いてしまいます。
余談ですが、**ColabはCoreML変換にもとっても便利です。**Python環境など最新のものがインストールされていますので、環境設定でつまづくことがありません。
GPUも無料で使えて、Google Driveのデータにもアクセスできて、上記のようにトレーニングもできますし、GitHubからモデルをクローンして手軽に試してからCoreML変換もできます。
PythonやTensorFlowやPytorchやNVIDIAのGPUドライバなどの環境設定がデフォルトでできています。
無料で安心、いくらでも新しいノーブックが作れる、ので後腐れがありません。
プロパティやメソッドや引数の候補もサジェスト表示してくれます。
Core ML Toolsのインストール
Colabに+ボタンでコードラインを追加し、Core ML Toolsをインストールします。
!pip install coremltools
# ColabでShellスクリプトを実行するときは!をつける
変換スクリプトを書きます
import coremltools as ct
mlmodel = ct.convert(モデル) # モデルに入れるべきジェネレーターを探そう!
この変換スクリプトに渡すモデルを探していきましょう。
モデルインスタンスを探すコツは、実際に画像生成をしているラインを探すということです。
画像を生成しているということは、そこにGeneratorがあるはずです。
トレーニング中に画像を生成していますので、そのあたりを探していくと、Colabの21行目でgenerateAndSaveImagesという関数があります。
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False) # ←ここ!!!!!!!!!
fig = plt.figure(figsize=(4,4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
modelクラスのインスタンスにテストインプットが渡されています。そしてPredict結果をpltで表示しています。
で、このmodelは関数の引数ですので、関数が使用されているところを探すと、、、
Colabの20行目のトレーニングステップ内で使われています。
ここで関数に渡されているgeneratorが今回変換すべきモデルです。
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# Produce images for the GIF as we go
display.clear_output(wait=True)
generate_and_save_images(generator, # ←ここ!!!!!!!!!
epoch + 1,
seed)
# Save the model every 15 epochs
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
# Generate after the final epoch
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
seed)
ちなみにこのgeneratorは10行目で初期化されていて、TensorFlow2はモデルインスタンスがトレーニング後の状態も保持していますので、そのまま変換スクリプトに渡せます。
mlmodel = ct.convert(generator)
実行すると、
Running TensorFlow Graph Passes: 100%|██████████| 5/5 [00:00<00:00, 13.17 passes/s]
Converting Frontend ==> MIL Ops: 100%|██████████| 65/65 [00:00<00:00, 1223.26 ops/s]
Running MIL optimization passes: 100%|██████████| 17/17 [00:00<00:00, 324.31 passes/s]
Translating MIL ==> MLModel Ops: 100%|██████████| 51/51 [00:00<00:00, 136.84 ops/s]
保存して、モデルの中身を見てみましょう。
mlmodel.save('./dcgan.mlmodel')
print(mlmodel)
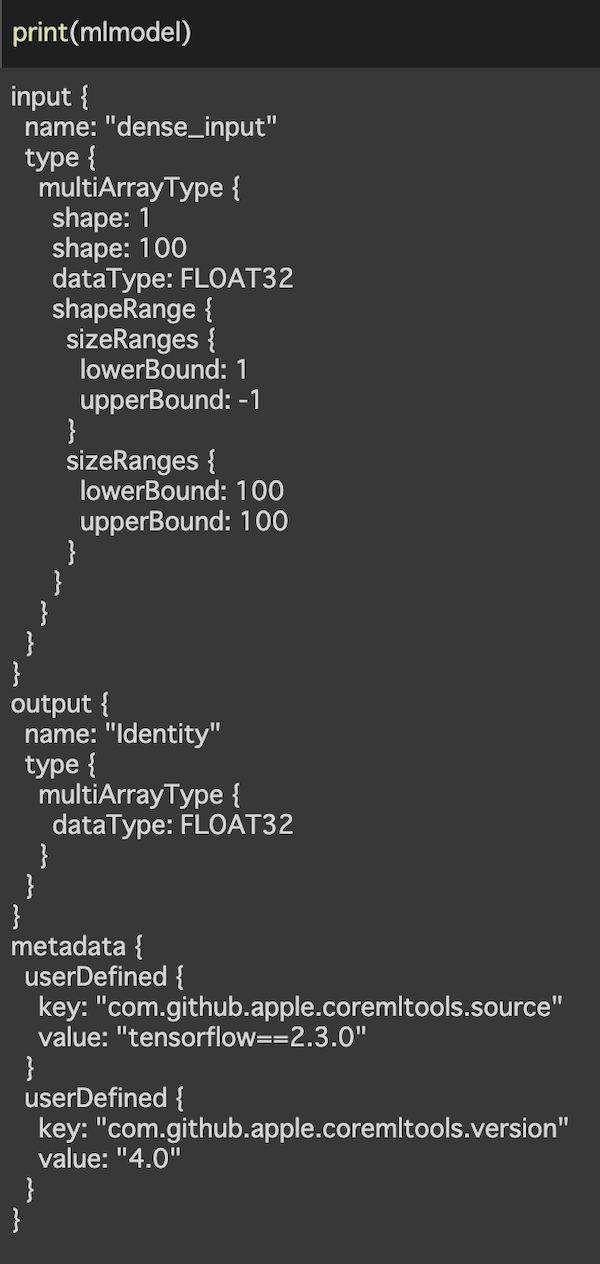
インプットは[1,100](1列の100個のランダム数字)の形状のマルチアレイ。というように表示されます。
Colabの左のファイルフォルダからダウンロードできます。
Xcode見るとこんな感じ。
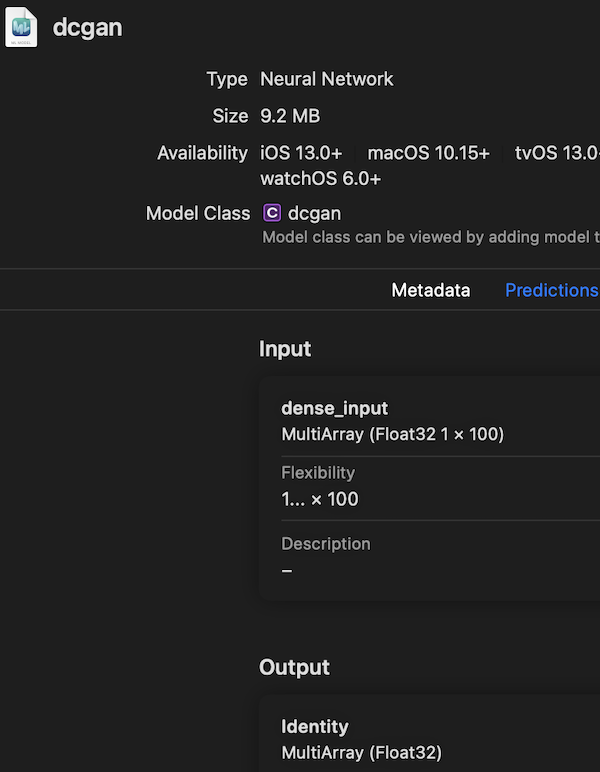
Xcodeで実行
let model = dcgan() // モデルの初期化
let input = try? MLMultiArray(shape: [1,100] as [NSNumber], dataType: MLMultiArrayDataType.float32) // 1*100の形状の空のマルチアレイを作る
for i in 0...input!.count - 1 {
input![i] = NSNumber(value: Float32.random(in: 0...1))
} // ランダムな数字をマルチアレイに入れていく。ここで入れる数字は0〜1の範囲
let mlinput = dcganInput(dense_input: input!) // マルチアレイをモデルのインプットの形にする
let output = try? model.prediction(input: mlinput) // 実行
入力は正規化されている
ここで、入力の数値の範囲を調べる必要があります。このモデルでは0〜1です。
どうやったらこれがわかるかというと、Pythonモデルの入力の前処理や出力の後処理を調べます。
機械学習の入力は、計算を効率化するために、生のピクセル値0〜255から小さな値に正規化されています。
例えば−1〜1や0〜1などです。
今回の場合Colabの6行目で、データセット画像の入力から127.5を引いてから127.5で割っています。
train_images = (train_images - 127.5) / 127.5
元々のピクセル値は0〜255の範囲ですので、これを127.5を引いてから127.5で割ると、0から1の入力に正規化されているということがわかります。
| 前処理 | 正規化後の入力の数値 |
|---|---|
| (データ画像 - 127.5) / 127.5 | 0〜1 |
| (データ画像 / 127.5) - 1 | −1〜1 |
のパターンが多いです。
インプットとアウトプットの数値範囲は基本一致します。
モデルの出力はCoreMLHelpersで画像にして表示しましょう。
CoreMLHelpersの使い方はリンク参照。
let uiImage = output?.Identity.image(min: 0, max: 1, channel: nil, axes: nil)
DispatchQueue.main.async {
imageView.image = uiImage
}

数値っぽいものが表示されました。
AnimeGanv2の変換(TensorFlow1):学習済みモデルから変換
TensorFlow1の変換はTensorFlow2とけっこうちがいます。
AnimeGANv2は画像を入力として受け取って、それをアニメ風のスタイルに変換するモデルです。

これもColabで変換します。
モデルを試してみる
GitHubからリポジトリをクローンます。
!git clone https://github.com/TachibanaYoshino/AnimeGANv2.git
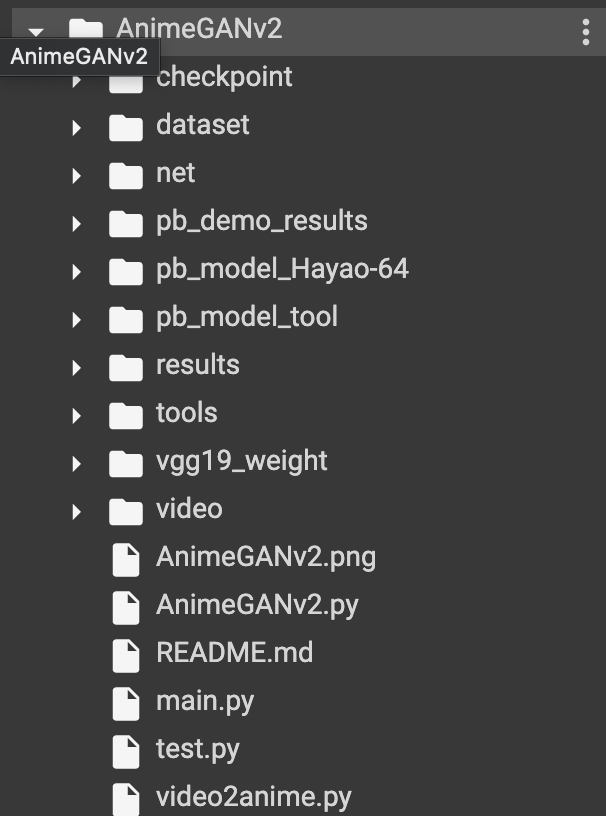
リポジトリの構成はこのような感じです。
GANリポジトリは、だいたいmain.pyやtest.pyからモデルクラス(AnimeGAN v2.py)を呼び出して、実行するような構成になっています。
作業ディレクトリを移動します。
cd AnimeGANv2/
ColabのTensorFlowのデフォルトバージョンは2なので、1に切り替えます。
%tensorflow_version 1.x
モデルをクローンしたら、とりあえずテストスクリプトを実行してみてモデルが動くか確かめることをおすすめします。
テスト方法はだいたいGitHubのプロジェクトページに書いてあります。
作者が提供してくれたテストスクリプトがこちら。

そのまま実行してみます。引数で事前学習済みモデルの重みチェックポイントやテストする画像、結果の保存先を指定しています。
!python test.py --checkpoint_dir checkpoint/generator_Hayao_weight --test_dir dataset/test/HR_photo --style_name Hayao/HR_photo


テスト画像がアニメ風に変換されてResultsディレクトリに保存されます。
これでモデルが動くことが分かったので、変換していきます。
凍結グラフを作る。モデルはどこ?
CoreMLToolsのインストール手順は上記のDCGANと同じです。
TensorFlow1は、凍結グラフを作って変換する必要があります。
そのために、モデルグラフを定義した.pbtextとチェックポイントの重みが必要です。
チェックポイントは、リポジトリのCheckpointディレクトリにあります。
pbtextは作る必要があります。
pbtextを作るためには、モデルグラフを探す必要があります。
モデルグラフはどこで見つかるか。
コツは画像生成をしたテストファイルの中を探すことです。
先ほどのテストでtest.pyを実行しました。
test.pyを開きましょう。
67行目でモデルを実行しています。
fake_img = sess.run(test_generated, feed_dict = {test_real : sample_image})
sample_imageを入力として与えて、グラフセッションをrunしています。
このsess.runを探しましょう。
だいたいこんな感じでモデルを実行しています。
グラフが見つかったので、pbtextを作りましょう。
pbtextを作るスクリプトはこちら。
tf.train.write_graph(sess.graph_def, './', 'animegan.pbtxt')
僕のおすすめ方法ですが、pbtextを作るスクリプトを直接test.pyに書き込んでしまいます。
実際に画像を生成しているコードですので、確実にGeneratorを含んだグラフをゲットできます。
先ほど見つけた
sess.run
のラインのすぐ下に書き込んでしまいましょう。
凍結グラフを作るためにグラフのアウトプットノードの名前も必要ですので、これをプリントアウトするメソッドもすぐ下に書き込みます。
graph = sess.graph
print([node.name for node in graph.as_graph_def().node])
これでもう一度先ほどのテストスクリプト(test.py)を実行すると、
animegan.pbtxtがカレントディレクトリに保存され、
ノードの名前がドバッと全部プリントされます。
['test', 'generator/G_MODEL/A/MirrorPad/paddings', 'generator/G_MODEL/A/MirrorPad', 'generator/G_MODEL/A/Conv/weights/Initializer/truncated_normal/shape', 'generator/G_MODEL/A/Conv/weights/Initializer/truncated_normal/mean',
・・・
'generator/G_MODEL/out_layer/Conv/weights/read', 'generator/G_MODEL/out_layer/Conv/dilation_rate', 'generator/G_MODEL/out_layer/Conv/Conv2D', 'generator/G_MODEL/out_layer/Tanh', 'save/filename/input',
・・・・
'save/Assign_74', 'save/Assign_75', 'save/Assign_76', 'save/restore_all']
この中でgeneratorと書かれた部分の最後のノードを探しましょう。
generator/G_MODEL/out_layer/Tanh
というのがアウトプットの名前です。
Tanhは活性化関数です。だいたいこういう名前になってます。
ゲットしたpbtextとアウトプットの名前とチェックポイントで凍結グラフを作ります。
from tensorflow.python.tools.freeze_graph import freeze_graph
graph_def_file = 'animegan.pbtxt'
checkpoint_file = 'checkpoint/generator_Hayao_weight/Hayao-64.ckpt'
frozen_model_file = './frozen_model.pb'
output_node_names = 'generator/G_MODEL/out_layer/Tanh'
freeze_graph(input_graph=graph_def_file,
input_saver="",
input_binary=False,
input_checkpoint=checkpoint_file,
output_node_names=output_node_names,
restore_op_name="save/restore_all",
filename_tensor_name="save/Const:0",
output_graph=frozen_model_file,
clear_devices=True,
initializer_nodes="")
変換する。
この凍結グラフをCoreMLToolsに渡して変換します。
import coremltools as ct
mlmodel = ct.convert('./frozen_model.pb',
inputs=[ct.ImageType(shape=[1,256,256,3],bias=[-1,-1,-1], scale=1/127)])
mlmodel.save('./animegan.mlmodel')
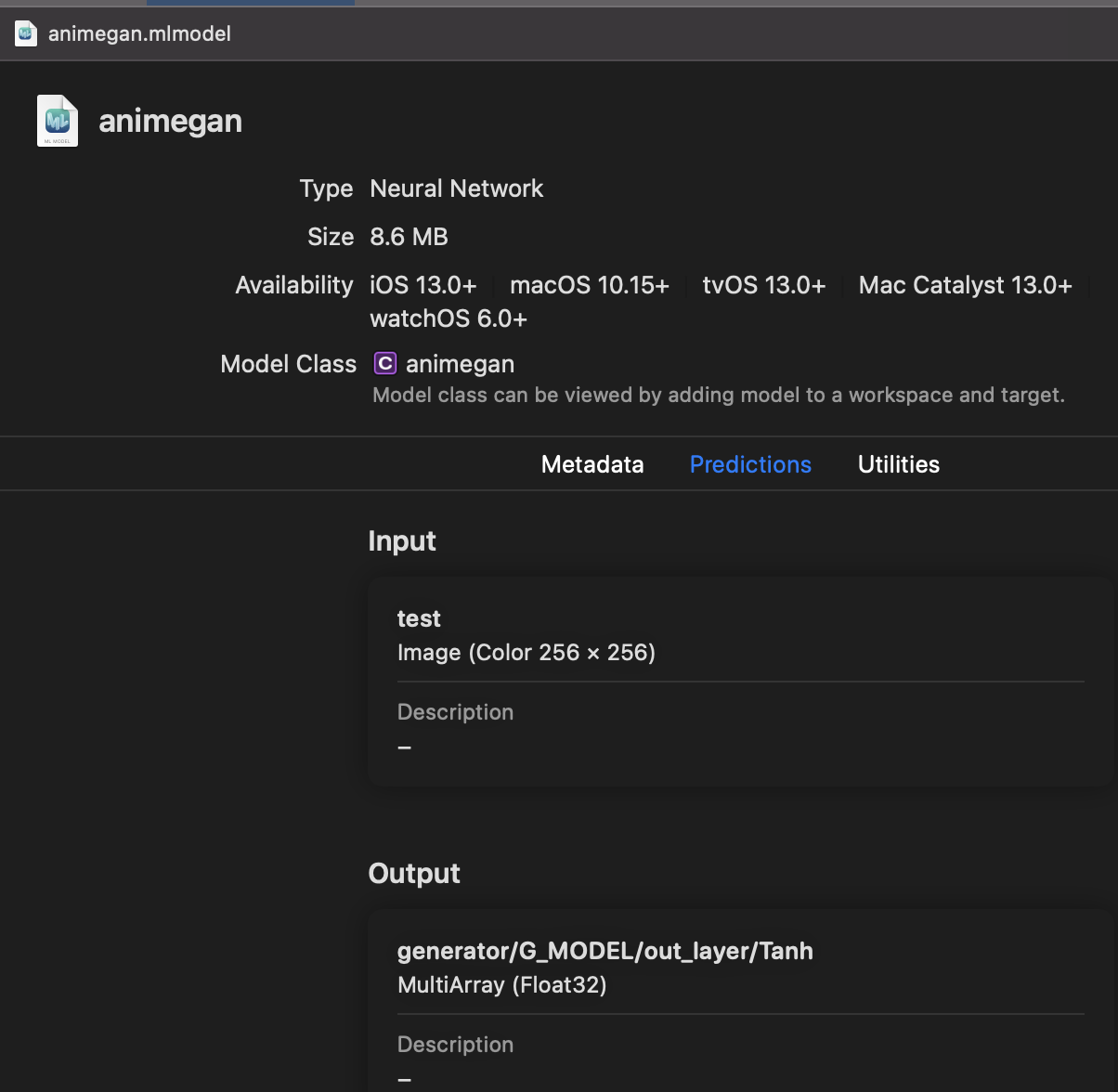
今回は入力が画像ですので、inputsにイメージタイプを指定しています。
ここで、入力画像の形状と前処理の方法を指定する必要があります。
これもテストスクリプトから探します。
def test(checkpoint_dir, style_name, test_dir, if_adjust_brightness, img_size=[256,256]): # 高さと幅が256であることがわかる
# tf.reset_default_graph()
result_dir = 'results/'+style_name
check_folder(result_dir)
test_files = glob('{}/*.*'.format(test_dir))
test_real = tf.placeholder(tf.float32, [1, None, None, 3], name='test') # バッチ1の3チャネルであることがわかる
・・・
sample_image = np.asarray(load_test_data(sample_file, img_size)) # load_test_dataという関数で前処理している
load_test_dataはutils.pyの中にあり、さらにたどると、preprocessingで127.5で割って1を引いていることがわかる
def preprocessing(img, size):
h, w = img.shape[:2]
if h <= size[0]:
h = size[0]
else:
x = h % 32
h = h - x
if w < size[1]:
w = size[1]
else:
y = w % 32
w = w - y
# the cv2 resize func : dsize format is (W ,H)
img = cv2.resize(img, (w, h))
return img/127.5 - 1.0 ←ここ
前処理では、各ピクセルの数値を127.5で割っているので ImageTypeのscaleを1/127.5、そして全てのカラーチャネルから1を引いているので、biasに[-1,-1,-1](レッド・ブルー・グリーン)を指定します。カラーチャネルを別に指定するのは、それぞれのカラーチャネルごとに異なる値を引く前処理をするモデルも存在するからです。
この状態で、出力マルチアレイのままで、理論編のVisionフレームワークのコードスニペットとCoreMLHelpersで使うことができます。
func completionHandler(request:VNRequest?,error:Error?) {
let result = request?.results?.first as! VNCoreMLFeatureValueObservation
let multiArray = result.featureValue.multiArrayValue
let uiImage = multiArray?.image(min: -1, max: 1, channel: nil, axes:nil) # /127.5 - 1で正規化したので出力の範囲は−1〜1。画像出力がうまくできない場合は出力の形状があっていないのでaxes:(3,1,2)など設定してみてください。
}
ビデオに適用すると、アニメーションになります。

宣伝編
1,変換したGANモデルをドラッグ&ドロップするだけで使えるOSSを作りました。
CoreGANContainer
ランダムな数値列・画像・ビデオからの変換ができます。
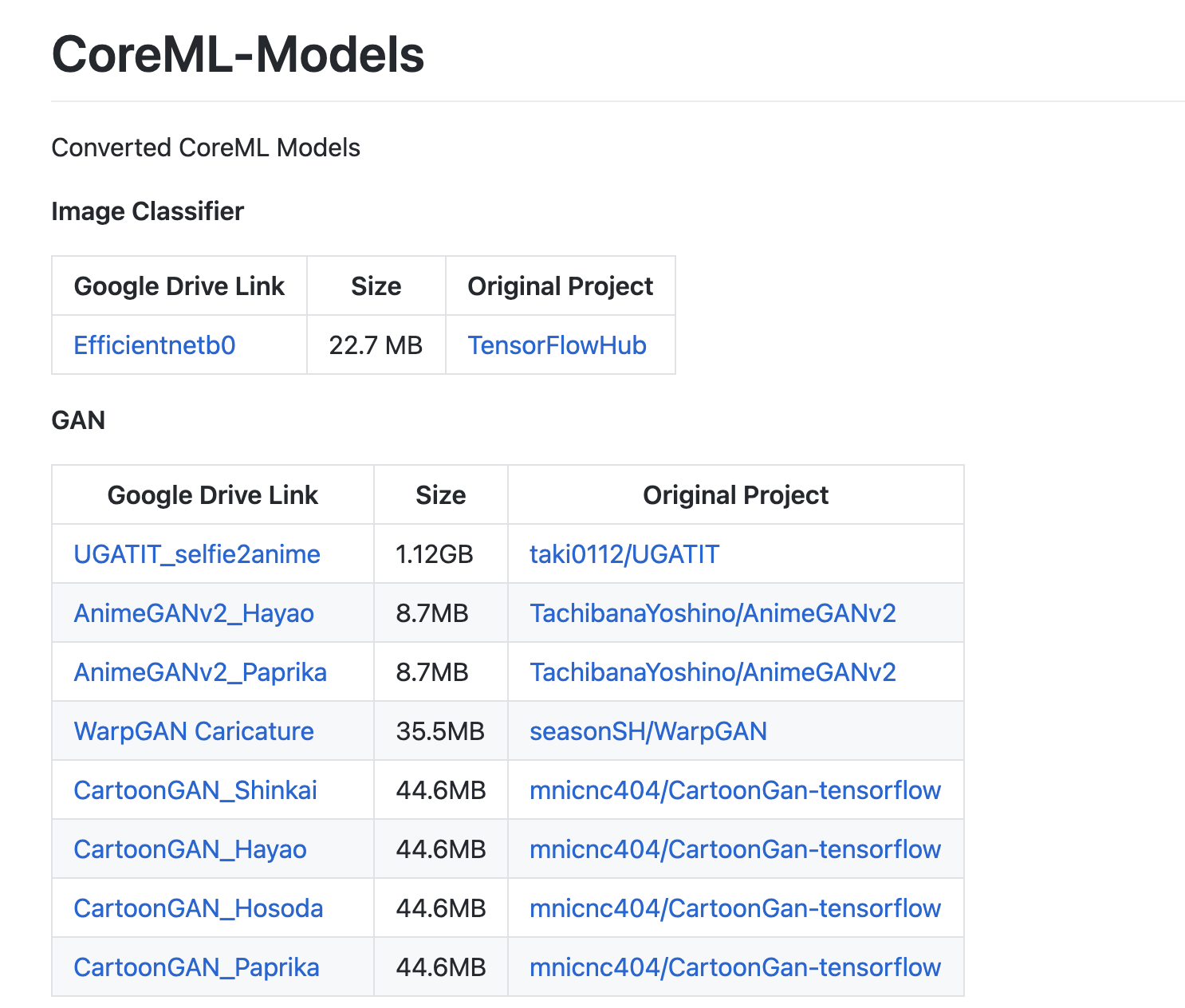
2,CoreMLに変換済みのモデルもアップしています。
CoreMLModels
似顔絵変換のWarpGANや画像分類モデルなどもダウンロードできます。
3,iOSDC2020に登壇して同内容を発表したので、Youtubeでみられます
文字がつぶれちゃって見えにくいですけど,本記事でわかりにくいところなどは参照していただけると。
iOSDC Japan 2020: iOS端末でGANを利用して画像を生成する / だいすけ
🐣
フリーランスエンジニアです。
お仕事のご相談こちらまで
rockyshikoku@gmail.com
Core MLを使ったアプリを作っています。
機械学習関連の情報を発信しています。