はじめに
「請求書の金額や登録番号を、AIが自動で読める時代が来たら便利だな」
そんな思いから、今回は Hugging Faceの Nanonets-OCR2-3Bを使って、
請求書画像から金額・日付・登録番号などを自動で抽出する実験を行いました。
このモデルは、単なるOCRではなく「文書を理解して答えるAI」。
いわば “読むだけでなく、質問にも答えるOCR” です。
使用モデル
-
モデル名:nanonets/Nanonets-OCR2-3B
-
特徴:
文書を「構造ごと理解」してテキスト化できるOCRモデル
表・数値・日付・署名・チェックボックス・登録番号などの抽出に対応
多言語(日本語含む)VQA(Visual Question Answering)にも対応
実験内容
📄 入力画像
請求書(日本語)画像をColabにアップロードして使用しました。
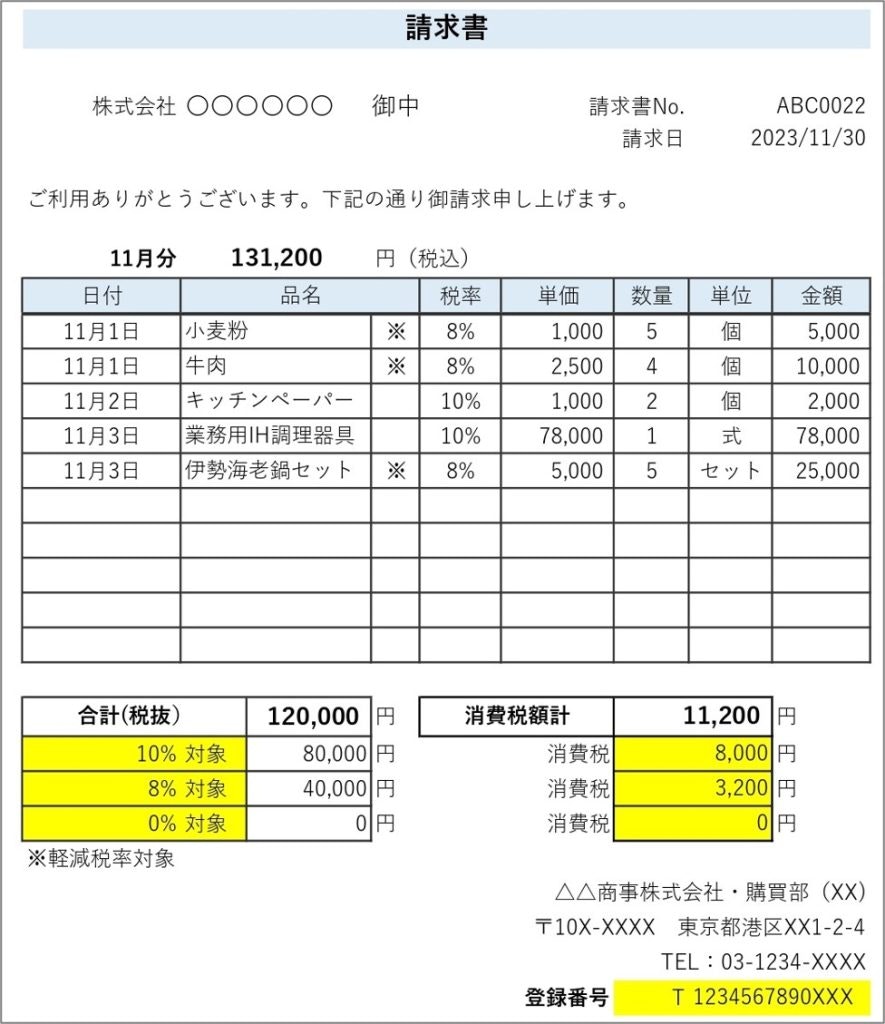
🎯 実験目的
以下のような質問をAIに投げて、画像内から正確に答えられるかを確認します。
questions = [
"請求書番号は何ですか?",
"請求日はいつですか?",
"合計金額(税込)はいくらですか?",
"10%対象の金額はいくらですか?",
"8%対象の金額はいくらですか?",
"消費税合計はいくらですか?",
"登録番号は何ですか?",
"会社の所在地はどこですか?",
"電話番号は何ですか?"
]
出力結果
| 質問 | モデルの回答 | ✅ 判定 |
|---|---|---|
| 請求書番号は? | ABC0022 | ✅ 正解 |
| 請求日は? | 2023/11/30 | ✅ 正解 |
| 合計金額(税込)は? | 120,000円 | ⭕(税込は131,200円、税抜120,000円。かなり近い) |
| 10%対象金額は? | 80,000円 | ✅ 正解 |
| 8%対象金額は? | 40,000円 | ✅ 正解 |
| 消費税合計は? | 11,200円 | ✅ 正解 |
| 登録番号は? | T1234567890XXX | ✅ 正解 |
| 会社所在地は? | 東京都港区(略) | ✅ 概ね正しい |
| 電話番号は? | 03-1234-XXXX | ✅ 正解 |
評価・考察
-
主要な数値・日付・登録番号はすべて正確に抽出できた。
-
「税込/税抜」表現の解釈がやや曖昧になる場面もあるが、OCRモデルとしては非常に高精度。
-
表構造・税率区分・電話番号・登録番号といった細部まで検出できる点が印象的。
おすすめの活用例
| 用途 | 説明 |
|---|---|
| 📄 請求書・領収書管理 | OCRで自動データ抽出+VQAで特定項目を問い合わせ可能 |
| 💰 経理AIアシスタント | 合計金額や税率を自然言語で問い合わせ |
| 🧾 帳票仕分け | 税率別金額・取引日ごとの分類に応用 |
| 🗂️ OCR+構造理解の教材 | 単純OCRとの差を体感できるサンプルとして最適 |
手順
Colabで必要ライブラリをインストール
!pip install Pillow==9.5.0
!pip -q install --upgrade transformers accelerate safetensors
モデルのロード
import torch
from transformers import AutoProcessor, AutoModelForCausalLM
MODEL_ID = "nanonets/Nanonets-OCR2-3B"
device = "cuda" if torch.cuda.is_available() else "cpu"
dtype = torch.bfloat16 if torch.cuda.is_available() else torch.float32
processor = AutoProcessor.from_pretrained(MODEL_ID, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_ID,
torch_dtype=dtype,
trust_remote_code=True
).to(device).eval()
print(f"✅ Loaded {MODEL_ID} on {device}")
請求書画像をアップロード
from google.colab import files
from PIL import Image
uploaded = files.upload() # ← 請求書画像を選択
img_path = list(uploaded.keys())[0]
image = Image.open(img_path).convert("RGB")
image
VQA(質問応答)関数を定義
def ask_vqa(image, question, max_new_tokens=96):
IMAGE_TOKEN = getattr(processor, "image_token", "<image>")
messages = [
{"role": "system", "content":
"You are an OCR and document understanding assistant. "
"Read all numbers, dates, and text carefully from the image and answer the question based only on the image content. "
"If the answer is not present, reply exactly: Not mentioned."},
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": question}
]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=[text], images=[image], return_tensors="pt").to(device)
with torch.no_grad():
out_ids = model.generate(**inputs, max_new_tokens=max_new_tokens)
gen = out_ids[:, inputs["input_ids"].shape[1]:]
return processor.batch_decode(gen, skip_special_tokens=True)[0].strip()
質問セットを実行
請求書に関する質問を日本語で投げてみます。
questions = [
"請求書番号は何ですか?",
"請求日はいつですか?",
"合計金額(税込)はいくらですか?",
"10%対象の金額はいくらですか?",
"8%対象の金額はいくらですか?",
"消費税合計はいくらですか?",
"登録番号は何ですか?",
"会社の所在地はどこですか?",
"電話番号は何ですか?"
]
for q in questions:
a = ask_vqa(image, q)
print(f"Q: {q}\nA: {a}\n" + "-"*60)
まとめ
今回の実験では、Nanonets-OCR2-3B が単なる文字起こしに留まらず、「文書の意味構造」を理解して正確に答えを返すことが確認できました。
このモデルは、帳票理解・請求書OCR・契約書解析といったビジネス用途で特に強力です。
🐣
フリーランスエンジニアです。
お仕事のご相談こちらまで
rockyshikoku@gmail.com
Core MLを使ったアプリを作っています。
機械学習関連の情報を発信しています。