iPhoneでLLMを動かしたい。
が、
ランタイムの選択肢が複数あり、どれを選べばいいのかわからない。
比較ベンチもあんまり見当たらない。
| ランタイム | 概要 |
|---|---|
| MLX | appleがローカルLLM業界にカチこんでがんばっている。 |
| llama.cpp | ローカルLLMといえば、ってぐらいコミュニティも成熟して練れてるイメージがある。 |
| LiteRT-LM | Gemma4限定だけど、Googleが満を持してぶち込んできたスーパー戦士。 |
| CoreML-LLM | LLMはGPU/Metal全盛で割りを食ってる感のあるApple Neural Engineを使える。僕が作ったのですが、嗚呼、太刀打ちできるのか。。。 |
ええい、やってしまえと、
iPhone 17 Pro(A19 Pro)で、同じモデルを4つのオンデバイス推論ランタイムで動かし、decode速度とメモリを実測しました。
結果は
「ローカルLLMをiPhoneでやるなら基本MLX」
「Gemma4限定でいえばLiteRT-LMが最強」
という結論を得ました。
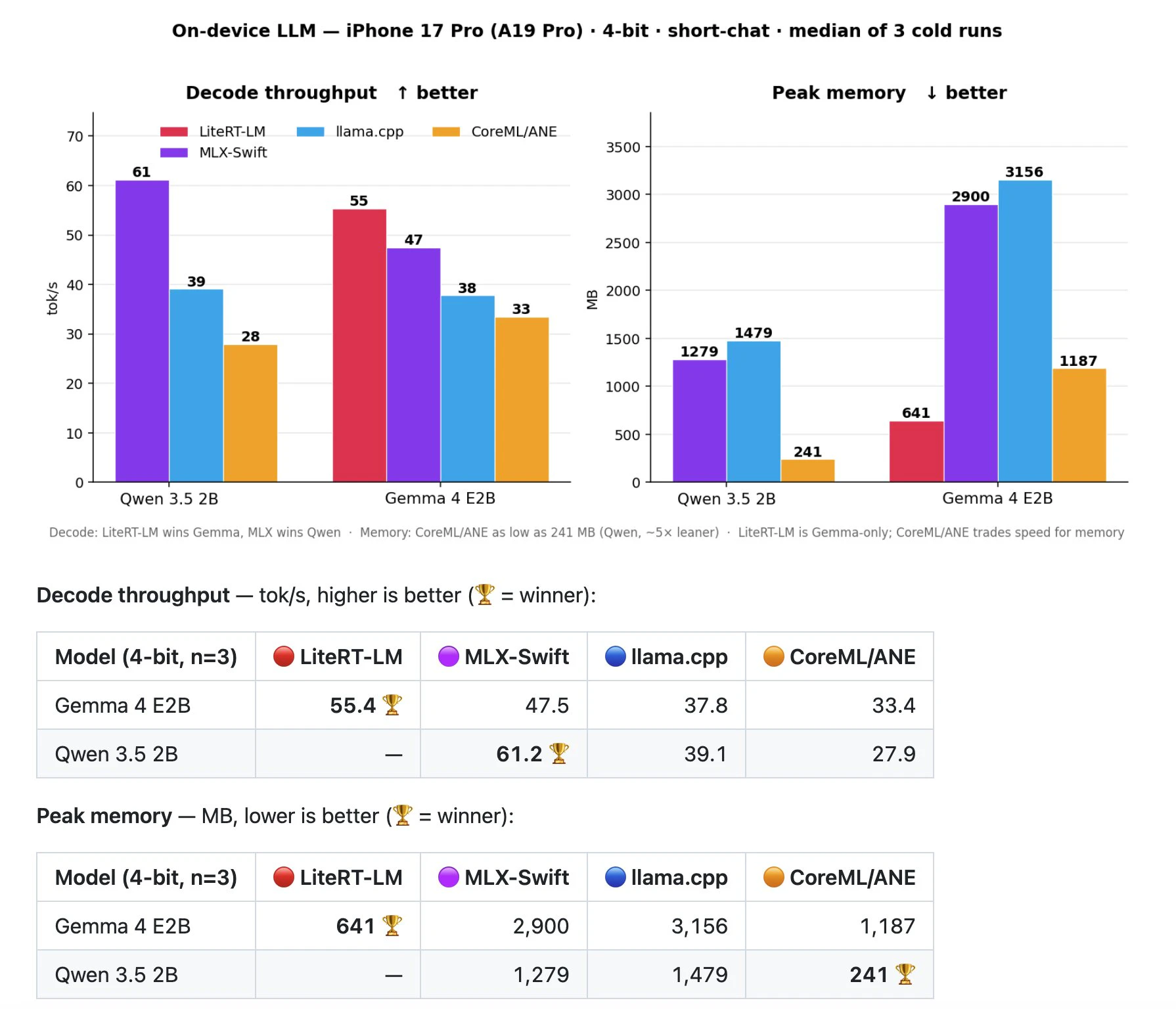
結論から
-
decode速度:
Qwen 3.5 2B は MLX が最速(61 tok/s)。
Gemma 4 E2B は LiteRT-LM が 圧倒的勝利(55tok/s)。 -
メモリ:
CoreML / ANE(Apple Neural Engine) が圧勝。Qwen 3.5 2B をわずか 241 MB で動かす(MLXの約 1/5)。ただし速度は最遅。でも頑張ったね。CoreML. -
用途別おすすめは記事末尾に。
測定条件
| 項目 | 内容 |
|---|---|
| 端末 | iPhone 17 Pro(A19 Pro / iOS 26.4.2) |
| ランタイム | MLX Swift / llama.cpp / LiteRT-LM / CoreML(ANE) |
| モデル | Gemma 4 E2B、Qwen 3.5 2B(いずれも4bit級) |
| タスク | short-chat(128トークン生成) |
| 集計 | コールドラン3回の中央値 |
| 指標 | decode tok/s(高い=良い)、ピークメモリ MB(低い=良い) |
結果①:decode 速度(tok/s, 高いほど良い)
| ランタイム | Gemma 4 E2B | Qwen 3.5 2B |
|---|---|---|
| 🔴 LiteRT-LM | 55.4 🏆 | —(Gemma専用) |
| 🟣 MLX-Swift | 47.5 | 61.2 🏆 |
| 🔵 llama.cpp | 37.8 | 39.1 |
| 🟠 CoreML/ANE | 33.4 | 27.9 |
Gemma 4 E2B ではやはり LiteRT-LM が 横綱相撲。
LiteRT-LM は Google のオンデバイス推論ランタイムで、Gemma を自前の .litertlm(INT4 QAT)フォーマットで GPU 実行します。自社モデル × 自社ランタイムの最適化が効いている形です。SwiftAPIはずっと開発中だったけど、頑張ったね、担当さん。
一方 Qwen 3.5 2B では MLX が最速(61 tok/s)。
AppleもローカルLLMでガチ勝負してる感がある。
(LiteRT-LM のカタログは Gemma(.litertlm)専用なので Qwen には不参加。)
結果②:ピークメモリ(MB, 低いほど良い)
| ランタイム | Gemma 4 E2B | Qwen 3.5 2B |
|---|---|---|
| 🔴 LiteRT-LM | 641 🏆 | — |
| 🟣 MLX-Swift | 2,900 | 1,279 |
| 🔵 llama.cpp | 3,156 | 1,479 |
| 🟠 CoreML/ANE | 1,187 | 241 🏆 |
CoreML / ANE が圧勝。特に Qwen 3.5 2B は 241 MB。これは重みと KV キャッシュをチャンク化して ANE に載せる chunked-MLKV 方式(CoreML-LLM の Qwen35MLKVGenerator)によるもので、MLX(1,279)・llama.cpp(1,479) の約 1/5。
「メモリの厳しい iPhone で 2B クラスを動かしたい」「アプリ本体や他機能とメモリを食い合いたくない」なら ANE は非常に強い選択肢です。
フェアネス上の注意点
- CoreML/ANE:ANE はスループットよりメモリ・電力に振った設計。初回ロードで ANE コンパイルが走るためロード時間は長め。decode は生成ピース数での概算(≒トークン)。
-
LiteRT-LM:出力トークン数の上限 API が無く EOS まで生成(=フル応答 約458トークン)。他は128で打ち切り。ただし decode は「速度(レート)」なので比較は成立。数値は LiteRT-LM 自身のベンチカウンタ(
getBenchmarkInfo)から取った実測値。 - 4bit 級で揃えていますが、量子化方式は各ランタイムで微妙に異なります(MLX 4bit / GGUF Q4_K_M / LiteRT INT4-QAT / CoreML INT4-palettized・INT8)。
用途別おすすめ
-
とにかく速く・汎用・モデル豊富 → MLX Swift。 Qwen で最速、Swift から扱いやすく、
mlx-communityにモデルが大量。AppleデバイスでのローカルLLM第一選択肢でしょう。 - Gemma を最速で → LiteRT-LM。 Gemma 系なら速度・メモリとも最強。勝てん。
- メモリ最優先(端末を選ばず/他機能と共存)→ CoreML / ANE。 241 MB は破格。速度を許容できるなら最強の省メモリ&省電力。
- 移植性・どこでも動かす → llama.cpp。 GGUF 資産と全プラットフォーム対応。尖りはないが堅実。
計測方法と再現
全ラン Mac から devicectl でヘッドレス自動実行(端末タップ不要)。モデルは Mac からサイドロードしました。結果の生 JSONL とチャートはリポジトリにあります。1行=「1ランタイム × 1モデル × 1デバイス」の PR を歓迎しています:
👉 https://github.com/john-rocky/apple-silicon-llm-bench
計測の完全自動化やビルド格闘(git-LFS / SwiftPM の unsafe-flags /
@preconcurrency等)の裏側は、別記事で書く予定です。
まとめ
- iPhone のローカル LLM は 「速度なら MLX / LiteRT-LM、メモリなら CoreML/ANE」。
あなたのローカルLLM開発のご参考に!
🐥
お仕事・技術相談について
iOS / Android / LLM / CoreML / LiterRT / ARKit / LiDAR / カメラ・画像認識まわりの開発支援を行っています。
特に、以下のような「実機・現場で詰まりやすい部分」の相談が得意です。
- モバイルデバイス上でのAIモデル推論・CoreML変換・高速化
- カメラ / Vision / YOLO / OCR / CLIP などを組み合わせた認識アプリ
- ARKit / LiDAR を使った3D座標推定・計測・現場スキャン
- PoCの引き継ぎ、性能改善、納品前の技術的な立て直し
- 「デモでは動くが、現場では安定しない」AIアプリの設計見直し
単なる技術検証だけでなく、現場制約・UX・運用フローまで含めて、実際に使える形に落とし込む支援ができます。
似たような課題で困っている方がいれば、rockyshikoku@gmail.com、または X / LinkedIn からご相談ください。