1、GANをひとつのネットワークとしてとらえる。
 シンプルなニューラルネットワークのトレーニングは、「ネットワークを計算が進んでいって、アウトプットと正解との差を計算し、誤差逆伝播で重みを更新する。。。」と直線的に理解しやすいのですが、GANは2個ネットワークがあるみたいだし、ロスも2種類あるし、どうやってトレーニング計算しているんだろう、と思っていました。
コードを読んでいくと、
GANも「ひとまとまりのネットワーク」としてとらえることによって理解しやすいのではないかと思うようになりました。
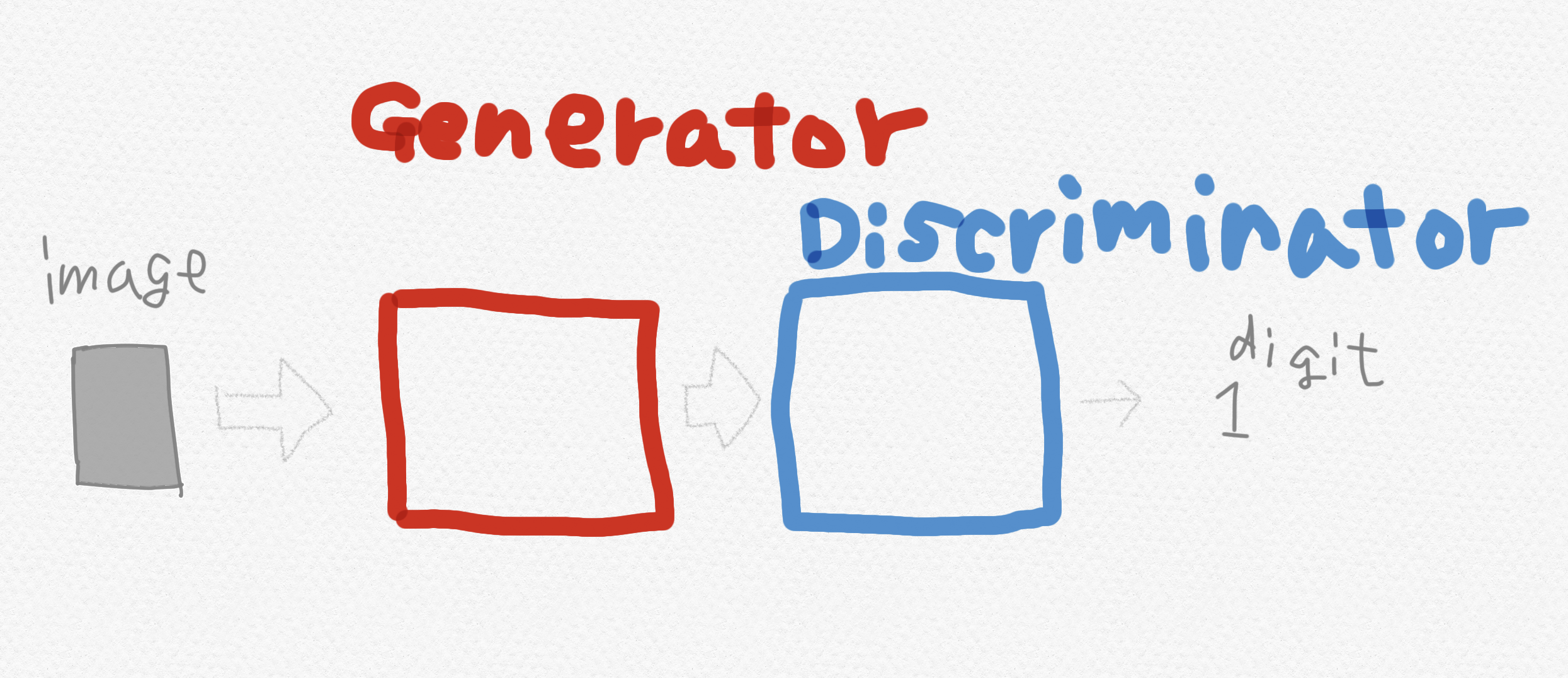
入力→ジェネレーター→ディスクリミネーター→出力、というワンストップのネットワークとしてです。
## 2、GANの本当のアウトプット
GANをひとつのネットワークとしてとらえると、アウトプットはなんだと思いますか?
イメージ?
ちがうんです。
アウトプットはたったひとつの数字です。
「0.2」とかです。
この単純な数字をもとに、トレーニングはすすみます。
トレーニング1ステップのなかで、
本物画像をGANに入力したアウトプット(リアル・アウトプット)
偽物ノイズをGANに入力したアウトプット(フェイク・アウトプット)
が計算されます。
これらは最初に言った単純な数字です。
たとえば、
リアル・アウトプット「0.6」
フェイク・アウトプット「0.3」
とかです。
ピクセルの数だけ数字があるとかではありません。本当に1個だけの数字です。
シンプルなニューラルネットワークのトレーニングは、「ネットワークを計算が進んでいって、アウトプットと正解との差を計算し、誤差逆伝播で重みを更新する。。。」と直線的に理解しやすいのですが、GANは2個ネットワークがあるみたいだし、ロスも2種類あるし、どうやってトレーニング計算しているんだろう、と思っていました。
コードを読んでいくと、
GANも「ひとまとまりのネットワーク」としてとらえることによって理解しやすいのではないかと思うようになりました。
入力→ジェネレーター→ディスクリミネーター→出力、というワンストップのネットワークとしてです。
## 2、GANの本当のアウトプット
GANをひとつのネットワークとしてとらえると、アウトプットはなんだと思いますか?
イメージ?
ちがうんです。
アウトプットはたったひとつの数字です。
「0.2」とかです。
この単純な数字をもとに、トレーニングはすすみます。
トレーニング1ステップのなかで、
本物画像をGANに入力したアウトプット(リアル・アウトプット)
偽物ノイズをGANに入力したアウトプット(フェイク・アウトプット)
が計算されます。
これらは最初に言った単純な数字です。
たとえば、
リアル・アウトプット「0.6」
フェイク・アウトプット「0.3」
とかです。
ピクセルの数だけ数字があるとかではありません。本当に1個だけの数字です。
3、アウトプットの正解
このアウトプットの正解は、
本物(リアル)が「1」
偽物(フェイク)が「0」
です。
先程の例とくらべると、本物を入力した結果「0.6」は、本物を入力した時の正解の「1」と(単純に引き算して)0.4の差があるといえます。
また、偽物の結果「0.3」は、偽物を入力した時の正解の「0」と(単純に引き算して)0.3の差があるといえます。
4、アウトプットと正解の差をもとにトレーニングされる
ディスクリミネーター・ロスは、
リアル・アウトプットと「1」の差
+
フェイク・アウトプットと「0」の差
です。
要するに、本物は本物、偽物は偽物、となるような正解の数字とどれだけ誤差があるかがディスクリミネーター・ロスです。
ジェネレーター・ロスは、フェイク・アウトプットと「1」の差
です。
要するに、偽物を入れた時に「本物(1)」とどれだけ誤差があるかがジェネレーター・ロスです。
これらのロスをもとに、ネットワークの重みを誤差逆伝播法で調整していくのですが、
ディスクリミネーター・ロスをもとに調整されるのは、ネットワークのうちディスクリミネーターの重みのみ、
ジェネレーター・ロスをもとに調整されるのは、ネットワークのうちジェネレーターの重みのみ、
です。
誤差逆伝播法とは、ロスの差がなるべく小さくなるように少しずつネットワークの重みを調整していくのですが、
ディスクリミネーターは正解との誤差をなるべく小さくするように逆伝播調整され、
ジェネレーターは、フェイク・アウトプットを本物(1)に近づけるように逆伝播調整されます。
これにより、「ディスクリミネーターは本物と偽物を判別するようにトレーニングされる、ジェネレーターは偽物を本物としてディスクリミネーターをあざむくようにトレーニングされる」、というよく聞くGANの構造になるわけです。
そして、トレーニングされたジェネレーターは、本物に似た画像を生成するようになりますが、トレーニング過程において、ジェネレーターの生成する画像は、あくまでGANネットワーク全体の中間表現にすぎません。
Twitterフォローしてくださいお願いします!
https://twitter.com/JackdeS11