はじめに
決算発表の要旨には、数値データだけでなく、企業の“トーン”──つまり経営陣がどの程度強気・慎重なのか──が表れます。
本記事では、金融特化言語モデル ProsusAI/FinBERT を使い、前期と今期の決算要旨を章ごとに感情分析。さらにポジティブ/ネガティブの変化をヒートマップで比較し、文章の「温度差」を可視化してみます。
使用モデルと概要
| モデル名 | 用途 | 特徴 |
|---|---|---|
| ProsusAI/FinBERT | 金融文書の感情分析 | 金融ニュース・決算発言に特化したBERT派生モデル |
| Helsinki-NLP/opus-mt-ja-en | 日本語→英語翻訳 | FinBERTが英語モデルのため自動翻訳を経由 |
実験結果
要旨ファイルの準備
「章タイトル」を角括弧【】で区切るだけ。
今回の例では、下記のような構成にしました。
prev_txt = """【見通し】
来期は生産能力の増強と新製品投入を予定しています。需要の底堅さ…(前期)
【売上・利益】
四半期売上は前年同期比+8%…(前期)
【新製品・R&D】
研究開発費は売上比4.2%…(前期)
【リスク要因】
為替変動とサプライチェーン逼迫が主な懸念…(前期)
"""
curr_txt = """【見通し】
来期は生産能力の増強と新製品投入を予定しています。需要の底堅さ…(今期)
【売上・利益】
四半期売上は前年同期比+12%…(今期)
【新製品・R&D】
研究開発費は売上比4.8%…(今期)
【リスク要因】
地政学リスクと価格改定の浸透遅れが懸念…(今期)
"""
with open("earnings_summary_prev.txt","w",encoding="utf-8") as f: f.write(prev_txt)
with open("earnings_summary_curr.txt","w",encoding="utf-8") as f: f.write(curr_txt)
print("Saved prev/curr txt")
今期 vs 前期の章別センチメント比較
下の図は、今期と前期の章ごとのセンチメント差分ヒートマップ(Δ)です。赤は今期で上昇(トーン強化)、青は低下(トーン弱まり)を意味します。
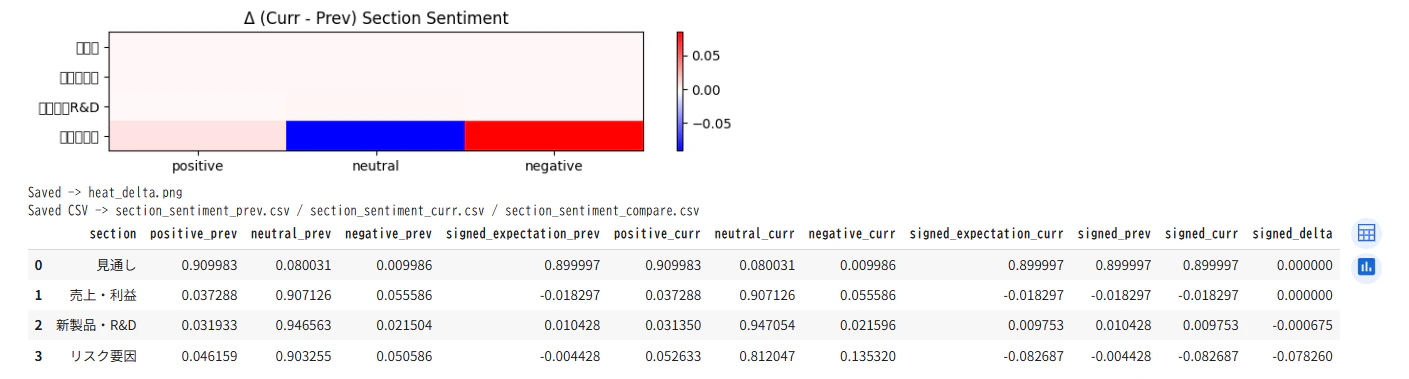
赤=今期で上昇、青=前期より低下(FinBERT出力)
結果の定量データ(抜粋)
| 章 | signed_delta | 解釈 |
|---|---|---|
| 見通し | ±0.00 | トーンは安定。変化なし。 |
| 売上・利益 | -0.018 | わずかに慎重化。強気姿勢がやや緩む。 |
| 新製品・R&D | -0.006 | ほぼ横ばい。技術投資姿勢は継続。 |
| リスク要因 | -0.078 | ネガティブトーンが上昇。リスク強調傾向。 |
図の見方
-
縦軸:決算要旨の章(見通し・売上・R&D・リスク要因など)
-
横軸:感情カテゴリ(positive/neutral/negative)
-
色の意味:
赤系 → 今期で上昇(前期よりポジティブに)
青系 → 今期で低下(より慎重・ネガティブに) -
ブロックが四角いのは正常です。
各マス(セル)が「章×感情クラス」の値を表しているため、矩形ブロックで描かれます。グラデーション表示ではなく、定量比較用のヒートマップとしてはこの形が最も正確です。
考察
今回の結果では、
-
「見通し」章はほぼ変化なし → 安定した業績見通し
-
「売上・利益」章はわずかにポジトーン後退 → 慎重さの増加
-
「リスク要因」章はネガティブ上昇 → 外部リスクへの警戒強化
つまり全体として、「堅調ながら慎重」なトーンへのシフトが見られました。FinBERTの出力は確率値なので、数値としての差分(±0.05〜0.1程度)でも十分に意味を持ちます。
おすすめの用途
| 項目 | 内容 |
|---|---|
| 📊 企業分析 | 決算発言トーンの時系列比較・リスク感度分析 |
| 💹 投資補助 | ニュースセンチメント指数による市場心理把握 |
| 🏢 IR自己分析 | 自社発表文の表現バランス確認・修正支援 |
| 🌍 翻訳検証 | 日本語版/英語版の感情差の検出 |
| 🧭 政策発言解析 | 発言トーンの時系列転換点を定量観測 |
| 🎓 教育用途 | AI×金融リテラシー教材・実験テーマとして最適 |
手順
環境セットアップ
!pip -q install transformers==4.44.2 sentencepiece torch matplotlib pandas numpy scikit-learn
import matplotlib.pyplot as plt
# ※ 解析はCPUでも動きます。GPUがあれば自動で使います。
要旨テキストを用意(前期・今期)
prev_txt = """【見通し】
来期は生産能力の増強と新製品投入を予定しています。需要の底堅さ…(前期)
【売上・利益】
四半期売上は前年同期比+8%…(前期)
【新製品・R&D】
研究開発費は売上比4.2%…(前期)
【リスク要因】
為替変動とサプライチェーン逼迫が主な懸念…(前期)
"""
curr_txt = """【見通し】
来期は生産能力の増強と新製品投入を予定しています。需要の底堅さ…(今期)
【売上・利益】
四半期売上は前年同期比+12%…(今期)
【新製品・R&D】
研究開発費は売上比4.8%…(今期)
【リスク要因】
地政学リスクと価格改定の浸透遅れが懸念…(今期)
"""
with open("earnings_summary_prev.txt","w",encoding="utf-8") as f: f.write(prev_txt)
with open("earnings_summary_curr.txt","w",encoding="utf-8") as f: f.write(curr_txt)
print("Saved: earnings_summary_prev.txt / earnings_summary_curr.txt")
共通ユーティリティ(章抽出→翻訳→FinBERT推論→描画)
import re, os, numpy as np, pandas as pd, torch, matplotlib.pyplot as plt
from transformers import pipeline
LANG = "auto" # "auto" / "en" / "ja"
MAX_SECTION_CHARS = 1800 # 章が長いとき先頭だけ解析(高速・実務向け)
def read_sections(path):
text = open(path,"r",encoding="utf-8").read()
if not re.match(r"^\s*【.*?】", text): # 先頭に見出しが無いとき補完
text = "【本文】\n" + text
parts = re.split(r"\n\s*(?=【.*?】)", text)
out=[]
for sec in parts:
s = sec.strip()
if not s: continue
m = re.match(r"^【(.*?)】\s*(.*)$", s, flags=re.DOTALL)
if not m: continue
title = m.group(1).strip()
body = (m.group(2) or "").strip()
if not body: continue
out.append((title, body[:MAX_SECTION_CHARS]))
if not out:
raise ValueError(f"章が抽出できませんでした: {path}")
return out
def looks_japanese(s:str)->bool:
return bool(re.search(r"[\u3040-\u30ff\u4e00-\u9fff]", s))
def translate_sections_if_needed(sections, lang_mode="auto"):
need = (lang_mode=="ja") or (lang_mode=="auto" and looks_japanese(" ".join(b for _,b in sections)))
if not need: return sections, False
mt = pipeline("translation", model="Helsinki-NLP/opus-mt-ja-en", tokenizer="Helsinki-NLP/opus-mt-ja-en")
trans = [(t, mt(b)[0]["translation_text"]) for t,b in sections]
return trans, True
def run_finbert(sections_en):
clf = pipeline(
"text-classification",
model="ProsusAI/finbert",
tokenizer="ProsusAI/finbert",
return_all_scores=True,
truncation=True,
device=0 if torch.cuda.is_available() else -1
)
rows=[]
for title, body in sections_en:
res = clf(body)[0]
d = {x['label'].lower(): float(x['score']) for x in res}
rows.append({
"section": title,
"positive": d.get("positive",0.0),
"neutral": d.get("neutral",0.0),
"negative": d.get("negative",0.0),
"signed_expectation": d.get("positive",0.0) - d.get("negative",0.0) # 簡易極性(pos-neg)
})
return pd.DataFrame(rows)
def heatmap(matrix, ylabels, xlabels, title, outpng, cmap=None, interpolation=None):
plt.figure(figsize=(8, max(2, 0.5*len(ylabels))))
if cmap is None:
plt.imshow(matrix, aspect="auto")
else:
plt.imshow(matrix, aspect="auto", cmap=cmap, interpolation=interpolation)
plt.colorbar()
plt.yticks(range(len(ylabels)), ylabels)
plt.xticks(range(len(xlabels)), xlabels)
plt.title(title)
plt.tight_layout()
plt.savefig(outpng, dpi=200)
plt.show()
print("Saved ->", outpng)
今期・前期を解析 → 2枚のヒートマップ+差分ヒートマップ
PREV_PATH = "earnings_summary_prev.txt"
CURR_PATH = "earnings_summary_curr.txt"
# 章を読む
prev_secs = read_sections(PREV_PATH)
curr_secs = read_sections(CURR_PATH)
# 必要なら日本語→英語翻訳
prev_proc, prev_tr = translate_sections_if_needed(prev_secs, LANG)
curr_proc, curr_tr = translate_sections_if_needed(curr_secs, LANG)
print(f"翻訳: 前期={prev_tr}, 今期={curr_tr}")
# FinBERT推論
df_prev = run_finbert(prev_proc)
df_curr = run_finbert(curr_proc)
# 章名を内部結合(共通章のみ比較)
merged = pd.merge(df_prev, df_curr, on="section", suffixes=("_prev","_curr"))
if len(merged) < max(len(df_prev), len(df_curr)):
missing_prev = set(df_curr["section"]) - set(df_prev["section"])
missing_curr = set(df_prev["section"]) - set(df_curr["section"])
if missing_prev: print("※前期に無く今期にある章:", sorted(missing_prev))
if missing_curr: print("※今期に無く前期にある章:", sorted(missing_curr))
# 2枚のヒートマップ(前期/今期)
cols = ["positive","neutral","negative"]
prev_vals = merged[[c+"_prev" for c in cols]].values
curr_vals = merged[[c+"_curr" for c in cols]].values
ylabels = merged["section"].tolist()
heatmap(prev_vals, ylabels, cols, "Prev: Section Sentiment Heatmap (FinBERT)", "heat_prev.png")
heatmap(curr_vals, ylabels, cols, "Curr: Section Sentiment Heatmap (FinBERT)", "heat_curr.png")
# 差分(今期 - 前期)ヒートマップ
delta = curr_vals - prev_vals
heatmap(delta, ylabels, cols, "Δ (Curr - Prev) Section Sentiment", "heat_delta.png", cmap="bwr")
# ↑ ブロック状表示が定量比較に最適(interpolationは付けないのが基本)
# 便利CSV出力
df_prev.to_csv("section_sentiment_prev.csv", index=False)
df_curr.to_csv("section_sentiment_curr.csv", index=False)
merged.assign(
signed_prev = merged["signed_expectation_prev"],
signed_curr = merged["signed_expectation_curr"],
signed_delta = lambda x: x["signed_expectation_curr"] - x["signed_expectation_prev"]
).to_csv("section_sentiment_compare.csv", index=False)
print("Saved CSV -> section_sentiment_prev.csv / section_sentiment_curr.csv / section_sentiment_compare.csv")
merged.head()
(任意)ダウンロード
from google.colab import files, os
for p in ["heat_prev.png","heat_curr.png","heat_delta.png",
"section_sentiment_prev.csv","section_sentiment_curr.csv","section_sentiment_compare.csv"]:
if os.path.exists(p): files.download(p)
まとめ
| ポイント | 内容 |
|---|---|
| ✅ FinBERTで定量化 | 決算文のポジ/ネガ度を章単位で数値化可能 |
| ✅ 差分で比較 | 今期−前期の差を可視化し、トーン変化を把握 |
| ✅ 日本語にも対応 | 翻訳を挟めば国内企業の要旨にも利用できる |
| ⚙ 可視化精度 | 四角ブロック表示が正確で解釈しやすい |
今後は、段落単位の平均化・重要語抽出・Streamlitによるダッシュボード化など、
“AIによる決算分析の自動レポート化” にも応用できます。
🐣
フリーランスエンジニアです。
お仕事のご相談こちらまで
rockyshikoku@gmail.com
Core MLを使ったアプリを作っています。
機械学習関連の情報を発信しています。