はじめに
この記事はZeals Advent Calendar 2019の7日目の記事です。
はじめまして。11月にZealsのMLチームにJoinしましたジョーです。
※恐縮ですが、完全に個人感覚のブログのため、
他のAdvent Calendarと違って、かなりふさげてる内容になります!
なぜこのタイトルにしたのか
会社でAdvent Calendar投稿しようぜとなって、しぶしぶと
気づいてたら冬になって、イベントの季節になりましたね。
聞いている曲も自然とクリスマスや恋愛関連のものになってきました(私だけ?)
そこで最近流行りの曲から、歌詞を解析して人々が求めている共通の何かが分かると面白いと思ったからです。
仮説
ある曲を好きになるというのは、歌詞からの意味やメッセージ性に共感して好きになったと仮定します。
そこで最近の人気ランキングの曲は、最近の出来事や流行り、季節感の何かを表しているに違いない!(本当かよ)
※ここで曲の音楽性は考慮しない前提です。
使った技術・ツール
fastText
教師データの単語を学習して、単語をベクトル表現にできるすごいツールです。
ベクトル表現ができることによって、単語間の距離を求めることができます。
「距離が近い」=「類似性が高い」と考えられます。
人気曲の歌詞を教師データとして学習させておき、そこに「人生」と関連性の高いものを出してみます。
他にWord2Vecという似たツールがありますが、fastTextにはSubWordという概念が導入されています。
Subwordは何かと言うと、
例えば、「Go」、「Goes」、「Going」という単語があります。
人間的には近しい単語だが、
Word2Vecの場合は、単語ごとで学習しているため、それぞれは全然別の単語となります。
fastTextの場合は、単語より小さい単位のsubword(文字のかたまり)に分割して、学習していますので、これらの単語間に関連性を持たせることができるというわけです。
以下のように、3つの単語とも「Go」という共通のsubwordがあります。
| 単語 | subword |
|---|---|
| Go | 「Go」 |
| Goes | 「Go」、「oe」、「es」 |
| Going | 「Go」、「oi」、「in」、「ng」 |
ざっくりに説明すると、こんな感じです。
より詳しい説明は他の記事に譲るとします。
Word2Vecの記事は、AdventCalenderの1日目に @ssabcireさんが書いてくれています。
https://qiita.com/ssabcire/items/7244b2d434752f30ba0e
Janome
pure pythonで書かれた形態素解析器です。
こちらもMecabと似たようなものですが、pythonのpipで簡単に導入できるメリットですが、解析速度はMecabより遅いです。
小規模の解析でサクッと試してみたい場合は、こちらがおすすめです。
環境&ライブラリ
MacOS Majave 10.14.5
python 3.7.5
beautifulsoup4==4.8.1
fasttext==0.9.1
Janome==0.3.10
requests==2.22.0
wordcloud==1.6.0
実装&結果
今回の人気歌詞は、Uta-Netさんのを使わせてもらいました。
以下のように、歌詞はデイリー、ウィークリー、マンスリーのページに分けられており、
各トップ100の曲を取得しました(合計300、重複あり)
https://www.uta-net.com/user/ranking/daily.html
まずは、使用ライブライブのインポート
import os
import re
import bs4
import time
import requests
import pprint
from janome.tokenizer import Tokenizer
from wordcloud import WordCloud
import fasttext
スクレイピングのための処理
def load(url):
res = requests.get(url)
res.raise_for_status()
return res.text
def pickup_tag(html, find_tag):
soup = bs4.BeautifulSoup(str(html), 'html.parser')
paragraphs = soup.find_all(find_tag)
return paragraphs
def parse(html):
soup = bs4.BeautifulSoup(str(html), 'html.parser')
# htmlタグの排除
kashi_row = soup.getText()
kashi_row = kashi_row.replace('\n', '')
kashi_row = kashi_row.replace(' ', '')
# 英数字の排除
kashi_row = re.sub(r'[a-zA-Z0-9]', '', kashi_row)
# 記号の排除
kashi_row = re.sub(r'[ <>♪`‘’“”・…_!?!-/:-@[-`{-~]', '', kashi_row)
# 注意書きの排除
kashi = re.sub(r'注意:.+', '', kashi_row)
return kashi
歌詞の内容を取得し、テキストに保存
with open('lyrics_ranking.txt', 'a') as f:
# 歌詞はUta-netさんのデイリー、ウィークリー、マンスリーの各トップ100の曲を取得(合計300、重複あり)
url_list = [
'https://www.uta-net.com/user/ranking/daily.html?p=1',
'https://www.uta-net.com/user/ranking/daily.html?p=2',
'https://www.uta-net.com/user/ranking/weekly.html?p=1',
'https://www.uta-net.com/user/ranking/weekly.html?p=2',
'https://www.uta-net.com/user/ranking/monthly.html?p=1',
'https://www.uta-net.com/user/ranking/monthly.html?p=2',
]
# 歌詞を格納
lyrics = ''
for url in url_list:
# 曲ページの先頭アドレス
base_url = 'https://www.uta-net.com'
# ページの取得
html = load(url)
# 曲ごとのurlを格納
musics_url = []
""" 曲のurlを取得 """
# td要素の取り出し
for td in pickup_tag(html, 'td'):
# a要素の取り出し
for a in pickup_tag(td, 'a'):
# href属性にsongを含むか
if 'song' in a.get('href'):
# urlを配列に追加
musics_url.append(base_url + a.get('href'))
""" 歌詞の取得 """
for i, page in enumerate(musics_url):
print('{}曲目:{}'.format(i + 1, page))
html = load(page)
for div in pickup_tag(html, 'div'):
# id検索がうまく行えなかった為、一度strにキャスト
div = str(div)
# 歌詞が格納されているdiv要素か
if r'itemprop="text"' in div:
# 不要なデータを取り除く
lyric = parse(div)
print(lyric, end = '\n\n')
# 歌詞を1つにまとめる
lyrics += lyric + '\n'
# 1秒待機
time.sleep(1)
break
# 歌詞の書き込み
f.write(lyrics)
テキストの内容のこのような形です。

Janomeを使って、分かち書きのリストの作成
# テキストを読み込み
f = open("lyrics_ranking.txt","r")
text = f.read()
# Tokenizerの初期化
t = Tokenizer()
# テキストを分析
results = t.tokenize(text)
wakati_list = []
for result in results:
#意味をなさないような単語を除外する。
stopword_list = ['そう', 'それ', 'られ', 'れる', 'くい','ん','よう','の', 'いい', 'ない', 'ある', 'する', 'なる', 'なっ']
if result.part_of_speech.split(',')[0] in ["名詞","形容詞","動詞"] and result.part_of_speech.split(',')[1] not in ["非自立"] and result.surface not in stopword_list:
print(result)
wakati_list.append(result.surface)
分かち書きリストの様子

歌詞の中に高頻出単語を抽出して、イケてる感じにまとめてくれるツールのWordcloudで今回の歌詞の全体像を確認してみます。
# 形態素解析された単語のリストをWordCloud用に処理している。
wc_text = ' '.join(wakati_list)
wc = WordCloud(background_color='White', font_path="/System/Library/Fonts/ヒラギノ角ゴシック W6.ttc", width=800, height=600).generate(wc_text)
# WordCloudの画像は同じディレクトリ内に保存されます。
wc.to_file("./lyrics_ranking_wordcloud.png")
出力された図は、こちら

「あなた」が一番出現率高いですね。
他に「世界」や「生きる」、「僕ら」、「好き」、「幸せ」など
個人的に面白いと思ったのは、「未来」より「今日」が重要だと読み取れるところです。
fasttextの学習のために、分かち書きのリストを一旦テキストに保存
with open('lyrics_ranking_wakati.txt', 'a') as f:
f.write(wc_text)
fasttextでの学習
# train model
model = fasttext.train_unsupervised('lyrics_ranking_wakati.txt', dim=50, thread=12)
学習したモデルに「人生とは」を聞いてみた

「へばりつく」など、頑張っていくという意味でしょうか。
「始め」や「生まれ変わる」などは、別の人生や新しい自分を歩んでいきたい?
「終わった」は、なんか悲しくなりますね。
他にも、いろいろ聞いてみたので、載せておきます。


「クリスマス」のスコアのすごい低いのは、使ったランキングが11月のものだからでしょうか?
最後に
当初は、季節関連の内容が出てくると予想しましたが、全く出てきませんね。
(上の「クリスマス」のスコアがすごく低い)
今回取得した歌詞のランキングは11月末ぐらいまでのものが関連すると考えられます。
また、デイリー、ウィークリー、マンスリーのランキングを使いましたが、重複を許容するため、
最近人気の「King Gnu」や「Official髭男dism」の重複が多く、偏りが出てしまうことも考えられます。
あと、単純に教師データが少なすぎるのです(300曲の歌詞のデータサイズは500KB未満)
今後は、歌詞のランキングの他に、実際に聴かれている音楽ストリーミングサービスのランキングで検証してみたいです。また、比較対象がないので、結果の違いも分からないまま考察もできないので、定期的に季節やその時期の出来事に影響されるかも検証してみたいと思います。
最後に、自然言語処理は全くの初心者なので、間違いや勘違いなどがあれば、ご指摘いただけると嬉しいです!
おまけ
「人生」や「自分」の最も近い距離の単語ベクトルを出してみましたが、逆に最も遠いもの(=足りないもの)も気になったので、出してみました。

「人生」に最も足りないものは、「オオサカ」??(だれ?)
同様に「自分」は?
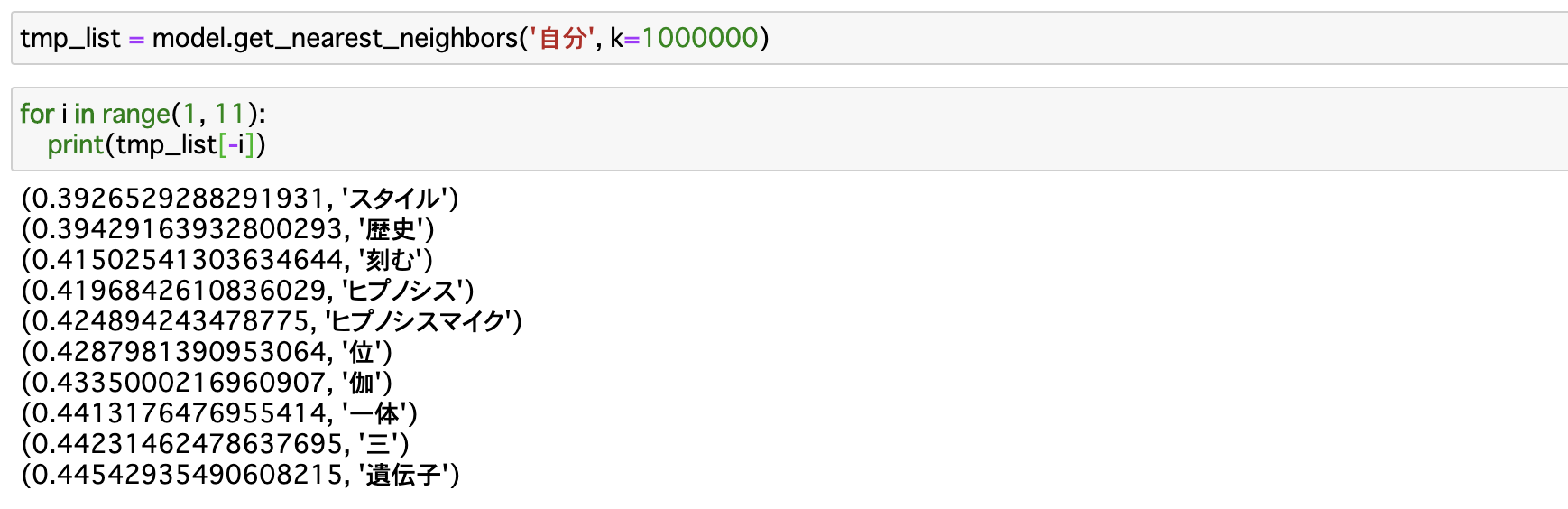
「人生」の結果とほど同じなので、単純にこれらの単語はどの単語からも離れていることが考えられます。
参考文献
歌詞の収集部分
https://qiita.com/Senple/items/1ad08b1a7ac9560bef62
歌詞から意味を探索する元ネタ
https://www.randpy.tokyo/entry/r_word2vec