この記事はZeals Advent Calendar 2019の1日目の記事です。
はじめまして。Zealsに来年度から入社予定の玉城です。
Zealsはチャットコマースと呼ばれる、チャットボットの技術を用いた事業を行っております。また私は現在大学で自然言語処理を使った研究をしています。
ボットには自然言語処理を導入していない会話があるのですが、そこに自然言語処理の技術を加えてみても面白いのではないかと考えたので、今回記事のテーマにすることにしました。
Word2Vecとは
ものすごく簡単に言うと、単語をベクトル表現に置き換え、ニューラルネットワークを使って学習を行うことで、単語同士の類似度や、単語同士の足し算引き算が出来るようになる技術です。
(曖昧すぎてマサカリ飛んできそう)
その類似度や足し算引き算の機能をチャットボットに組み込んでみよう!というのが今回のお話です。
作成するチャットボット会話の流れ
チャットボットでの会話は、ユーザーからヒアリングを行い、それをもとにベストなものを提案する流れです。
そこで、今回は私のマイブームであるVtuberをユーザーに紹介するチャットボットを作っていきましょう。
今回のチャットボットの会話の流れは以下のように作っていきます。
- ユーザーに特徴を入力させる
- 特徴の中でもっともあてはまるであろうVtuberを紹介する
紹介するVtuber
紹介するVtuberを決めていきます。
そこで、今回はVtuberの中でも特徴が強く、登録者数の多い方々を選びました。
まず一人目はおめがシスターズ。とてもVRの技術力が高いVtuberです。

おめシスのYoutubeチャンネルはこちら
2人目は月ノ美兎。動画の企画が面白いVtuberです。

月ノ美兎のYoutubeチャンネルはこちら
3人目は花譜。とても歌唱力が高いVtuberです。

花譜のYoutubeチャンネルはこちら
プログラム全体像
では、上記のVtuberを紹介するチャットボットのプログラムを作っていきましょう。
プログラムの全体の流れとしては以下になります。
- TwitterからVtuberの名前でつぶやいているツイートを取得
- ツイートをWord2Vecに学習させるために整形
- 整形したツイート群でWord2Vecモデルを生成
- Word2Vecモデルをチャットボットに組み込む
ディレクトリ構造はこのような感じになります。
.
├── chatbot.py
├── make_model.py
├── model_test.py
└── twitter
今回作成したgithubリポジトリはこちらです
https://github.com/ssabcire/chatbot
今回使用するバージョン
- macOS Catalina 10.15.1
- Python 3.7.3
- gensim==3.8.1
- pyknp==0.4.1
- pandas==0.25.1
- go version 1.11.1
Twitterからデータ取得
Vtuberについてつぶやいているツイートを取得していきます。
TwitterAPIを叩くコードはあまり本筋ではないと思うので、すでに作成してあるリポジトリからバイナリを作って、APIを叩く方法のみを説明させていただきます。
こちらをcloneしてください。
https://github.com/ssabcire/get-tweets
git clone https://github.com/ssabcire/get-tweets.git
次に、keys.goを作成し、TwitterAPIのキーと、ツイートを格納するためのディレクトリを決めておきます。
package lib
const consumerKey string = ""
const consumerSecret string = ""
const accessToken string = ""
const accessTokenSecret string = ""
// path = $HOME+path形式。ホームディレクトリ配下にPATHが作成される
const path = "py/chatbot/search-おめシス"
そして、TwitterAPIを叩いて検索をするバイナリを生成します。
cd search
go build
./search おめシス
TwitterAPIの制限ゆえ多少時間がかかりますが、これでおめシスでつぶやいているツイートを取得できました。
ツイートからモデル作成
次に、ツイートを整形し、Word2Vecモデルを生成していきます。
import re
import json
from itertools import islice
from pathlib import Path
from typing import List, Set, Iterator
from pyknp import Juman
from gensim.models.word2vec import Word2Vec
def make_w2v(json_files: Iterator[Path], model_path: str):
'''
ツイートでWord2Vecモデルを保存
'''
model = Word2Vec(_make_sentences(json_files), size=100,
window=5, min_count=3, workers=4)
model.save(model_path)
def morphological_analysis(tweet: str) -> List[str]:
'''
tweetを形態素解析し、リストで返す
'''
text = _remove_unnecessary(tweet)
if not text:
return []
return [mrph.genkei for mrph in Juman().analysis(text).mrph_list()
if mrph.hinsi in ['名詞', '動詞', '形容詞']]
def _make_sentences(json_files: Iterator[Path]) -> List[List[str]]:
'''
ツイートを読み込み形態素解析を行い、2次元のリストを返す
'''
return [morphological_analysis(tweet) for tweet in _load_files(json_files)]
def _load_files(json_files: Iterator[Path]) -> Set[str]:
'''
取得したJSONツイートのPATHが記載されたリストからファイルすべてを読み込み、
テキストのSetを返す
'''
tweets = set()
for file in json_files:
with file.open(encoding='utf-8') as f:
try:
tweets.add(json.load(f)['full_text'])
except json.JSONDecodeError as e:
print(e, "\njsofilename: ", file)
return tweets
def _remove_unnecessary(tweet: str) -> str:
'''
ツイートの不要な部分を削除
'''
# URL, 'RT@...:', '@<ID> '
text = re.sub(
r'(https?://[\w/:%#\$&\?\(\)~\.=\+\-]+)|(RT@.*?:)|(@(.)+ )',
'', tweet
)
# ツイートがひらがな1,2文字しかない場合, 空白
# [", #, @] はjumanが扱えない
return re.sub(
r'(^[あ-ん]{1,2}$)|([ | ])|([#"@])',
'', text
)
if __name__ == '__main__':
cwd = Path().cwd()
make_w2v(
islice((cwd / "twitter" / "search-omesis").iterdir(), 0, 5000),
str(cwd / 'omesis.model')
)
make_w2v(
islice((cwd / "twitter" / "search-kahu").iterdir(), 0, 5000),
str(cwd / 'kahu.model')
)
make_w2v(
islice((cwd / "twitter" / "search-mito").iterdir(), 0, 5000),
str(cwd / 'mito.model')
)
まず、一番上のこちらのメソッドから解説していきます。
Word2Vecクラスを使い、モデルを作成します。第1引数には2次元配列を渡す必要があるので、_make_sentences()で2次元配列を作成していきます。
def make_w2v(json_files: Iterator[Path], model_path: str):
model = Word2Vec(_make_sentences(json_files), size=100,
window=5, min_count=3, workers=4)
model.save(model_path)
_make_sentences()は、ツイートのリストからツイートを取り出し、ツイートを形態素解析し、単語のリストを作成します。
def _make_sentences(json_files: Iterator[Path]) -> List[List[str]]:
return [morphological_analysis(tweet) for tweet in _load_files(json_files)]
形態素解析にはJuman++を用いています。今回はJumanを使っていますが、形態素解析できるやつなら何でもいいので好きなものをお使いください
def morphological_analysis(tweet: str) -> List[str]:
'''
tweetを形態素解析し、リストで返す
'''
text = _remove_unnecessary(tweet)
if not text:
return []
return [mrph.genkei for mrph in Juman().analysis(text).mrph_list()
if mrph.hinsi in ['名詞', '動詞', '形容詞']]
ではこちらのスクリプトを実行していきましょう。
python make_model.py
かなりの量のツイートを解析するので時間がかかりますが、3つのWord2Vecモデルを生成できました。
モデルに学習された単語の確認
モデルでどんな言葉が学習されたか少し確認してみましょう
from pathlib import Path
from gensim.models.word2vec import Word2Vec
cwd = Path().cwd()
model = Word2Vec.load(str(cwd / "kahu.model"))
print(model.wv.index2entity)
['花譜', 'する', '展', '行く', '歌う', '曲', 'なる', 'の', '好きだ', .......
といった感じで、単語が学習されています。
次は、花譜と最も似ている単語を調べてみます。
print(model.wv.most_similar(positive=['花譜'], topn=5))
> [('する', 0.9999604225158691), ('の', 0.9999315738677979), ('なる', 0.9999290704727173), ('いう', 0.9999224543571472), ('観測', 0.9999198317527771)]
上位語で意味がわかりそうな単語は観測くらいですね...
他にも、単語と単語の類似度を調べることもできます。
print(model.wv.similarity('歌', '花譜'))
> 0.9998921
ではこのWord2Vecの類似度などの機能を使って、チャットボットに組み込んでいってみましょう。
チャットボット作成
LINE APIを使ってbotを作成するのは時間がなくて無理だった大変なので、今回は標準入力と標準出力を使ってやっていきます。
import random
from pathlib import Path
from typing import List, Tuple
from gensim.models.word2vec import Word2Vec
from make_model import morphological_analysis
def exec(vtubers: List[Tuple[str, str]]):
print("特徴からVtuberを紹介します。どんな特徴のVtuberが見たいですか?")
utterance = input("例: 面白い, かわいい, 技術力が高い, ... 特徴を試しに入力してください: ")
if not utterance:
return print("特徴が入力されていません")
wakati_utterance = morphological_analysis(utterance)
if not wakati_utterance:
return print("すみませんが、他のワードで特徴の入力をお願いします")
s = set()
for name, path in vtubers:
model = Word2Vec.load(path)
utterance_entities = [word for word in wakati_utterance
if word in model.wv.index2entity]
if not utterance_entities:
continue
most_similar_word = model.wv.most_similar_to_given(
name, utterance_entities)
if model.wv.similarity(name, most_similar_word) > 0.95:
s.add(name)
if s:
print("入力した特徴に合うVtuberはこちらです!", _introduce(s.pop()))
else:
print('''すみませんが、その特徴のVtuberは見つかりませんでした.
代わりにこちらはどうでしょう.''', _introduce())
def _introduce(name: str = "") -> str:
if not name:
return random.choice((_message1(), _message2(), _message3()))
elif name == "おめシス":
return _message1()
elif name == "花譜":
return _message2()
elif name == "月ノ美兎":
return _message3()
def _message1() -> str:
return """\"おめシス\"
リンクはこちら https://www.youtube.com/channel/UCNjTjd2-PMC8Oo_-dCEss7A"""
def _message2() -> str:
return """\"花譜\"
リンクはこちら https://www.youtube.com/channel/UCQ1U65-CQdIoZ2_NA4Z4F7A"""
def _message3() -> str:
return """\"月ノ美兎\"
リンクはこちら https://www.youtube.com/channel/UCD-miitqNY3nyukJ4Fnf4_A"""
if __name__ == '__main__':
cwd = Path().cwd()
exec([('おめシス', str(cwd / 'omesis.model')),
('花譜', str(cwd / 'kahu.model')),
('月ノ美兎', str(cwd / 'mito.model'))
])
では簡単にコードの説明をしていきます。
標準入力を受け取り形態素解析を行います。
def exec(vtubers: List[Tuple[str, str]]):
print("特徴からVtuberを紹介します。どんな特徴のVtuberが見たいですか?")
utterance = input("例: 面白い, かわいい, 技術力が高い, ... 特徴を試しに入力してください: ")
if not utterance:
return print("特徴が入力されていません")
wakati_utterance = morphological_analysis(utterance)
if not wakati_utterance:
return print("すみませんが、他のワードで特徴の入力をお願いします")
形態素解析した単語が入ったリストのwakati_utteranceから単語をひとつずつWord2Vecモデルに存在するか確認し、存在するならリストに追加します。
そして、その中から類似度が最も高いものを取り出し、その値が0.95以上(これは各々決めてください)なら、Setに追加し、Vtuberを紹介していきます。
類似度が95%以上なら、その単語はVtuberの特徴と言っても間違いないんじゃないかな!っていう考えです。
s = set()
for name, path in vtubers:
model = Word2Vec.load(path)
utterance_entities = [word for word in wakati_utterance
if word in model.wv.index2entity]
if not utterance_entities:
continue
most_similar_word = model.wv.most_similar_to_given(
name, utterance_entities)
if model.wv.similarity(name, most_similar_word) > 0.95:
s.add(name)
if s:
print("入力した特徴に合うVtuberはこちらです!", _introduce(s.pop()))
else:
print('''すみませんが、その特徴のVtuberは見つかりませんでした.
代わりにこちらはどうでしょう.''', _introduce())
試しにこのスクリプトを実行していきましょう。
python chatbot.py
特徴からVtuberを紹介します。どんな特徴のVtuberが見たいですか?
例: 面白い, かわいい, 技術力が高い, ... 特徴を試しに入力してください: 面白い
入力した特徴に合うVtuberはこちらです! "おめシス"
リンクはこちら https://www.youtube.com/channel/UCNjTjd2-PMC8Oo_-dCEss7A
python chatbot.py
特徴からVtuberを紹介します。どんな特徴のVtuberが見たいですか?
例: 面白い, かわいい, 技術力が高い, ... 特徴を試しに入力してください: 歌声
入力した特徴に合うVtuberはこちらです! "花譜"
リンクはこちら https://www.youtube.com/channel/UCQ1U65-CQdIoZ2_NA4Z4F7A
うむうむ。いい感じに紹介できました。最高ですね!
このプログラムの問題点
今回は入力された単語がモデルに含まれているかで紹介するしないを決めていたので、
もし歌がうまい 歌が下手のどちらの入力をしても、上記のコードだと歌に反応してしまい、歌が下手でも上手い人が紹介されてしまいます。
ようするに、文の係り受けを理解できていません。
しかしWord2Vecは単語の演算ができるので、歌-下手=<とある単語>のようにすると、うまくできるかもしれません。このあたりの工夫をさらにやってみるのも面白そうですね。
おまけ
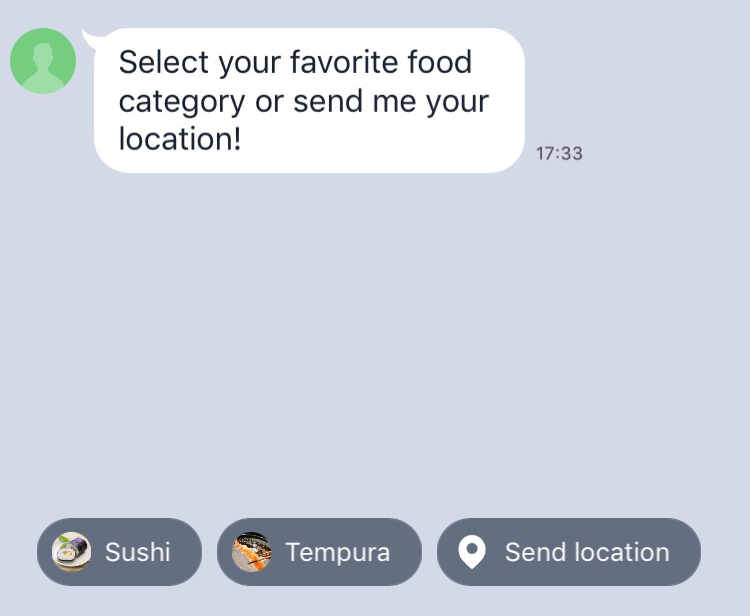
ここまで長々と書いてきましたが、実はチャットボットではあまり自由発話を使いません。
その理由として、ユーザーに自由発話をさせるよりも、クイックリプライなどの選択肢形式でユーザーに回答を促したほうが回答率が高いからです。
(↓クイックリプライはこのように表示される機能です)
おわりに
私がもっとも推しているVtuberは花鋏キョウちゃんです。かわいいし歌がうますぎるのでぜひ一度ご覧になっていただけると泣いて喜びます!!!

花鋏キョウちゃんのYoutubeチャンネルはこちらです...何卒よろしくお願いします...!