はじめに
-
本記事は個人メモです。
- いろいろ書いていますが、私自身はRedshiftのパフォーマンス関連の経験値は低いです。
- 随時内容を追記していきます。粒度にムラがあります。長くなったら記事を分割するかもしれません。
-
RedshiftはSnowflakeなどに比べるとチューニングで考えるべきポイントが多い印象です。
- 学習による認知負荷が極めて高いため、本記事のように学習内容をまとめておく必要があると感じました。
本記事の構造と注意点
-
本記事の構造
- 本記事に記載する情報源やTipsは、「テーブル設計」と「クエリパフォーマンス」で分けて記載しています。
-
注意点
- 本記事は主にRedshiftクラスタ(Provisioned)版(つまりRedshiftサーバレスではない)を念頭に記載しています。
- 記事中に断りがなければRedshiftクラスタ版を指しているものとお考えください。
- パフォーマンスチューニングはワークロードによってアプローチが全く異なるため、銀の弾丸は存在しないと考えています。
- そのためここに記載するメモも、特定のワークロードに依拠した内容になっています。
- Redshiftは日々機能追加が行われているため、参照する情報がいつ書かれたものであるかを多少気にしておく必要があります。
- 機能面については以下の記事にリリース時期まで記載されています。
- 全般的にインフラ視点で記載しています。SQL文チューニングなどアプリ視点は弱いです。
- 本記事は主にRedshiftクラスタ(Provisioned)版(つまりRedshiftサーバレスではない)を念頭に記載しています。
情報源
Redshiftテーブル設計関連の情報源
-
Amazon Redshiftテーブル設計詳細ガイド (2017年)
- https://d1.awsstatic.com/events/jp/2017/summit/slide/D3T1-5.pdf
- 自動テーブル最適化(2020年)がなかった頃の古い記事ですが、ソートキーや分散スタイルを手動で設定する場合は役立ちます。
-
Amazon Redshift テーブル設計のベストプラクティス
- https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/c_designing-tables-best-practices.html
- 公式は図が少なく、薄めにしか書いてませんが概要を理解するのに役立つので一応載せておきます。
Redshiftクエリパフォーマンス関連の情報源
-
Amazon Redshift クエリパフォーマンスチューニング Deep Dive (2023年)
- https://pages.awscloud.com/rs/112-TZM-766/images/AWS-36_AWS-Summit-2023_Analytics.pdf
- クエリパフォーマンスを考える上で熟読すべき資料です。
- 基本的かつ見過ごしがちな、アプローチ方法から記載されています。例えば「いきなりクエリの実行計画を見るのではなく、まずどこで時間がかかっているかを特定する」など。
- p.5に記載されているとおり、同時実行性能(ConcurrencyScaling,WLMなど)については言及していません。「クエリ単体性能」と「同時実行性能」を分けて考えることが重要です。
-
Amazon Redshift のパフォーマンス調整のテクニック15選 (2023年)
-
https://www.integrate.io/jp/blog/15-performance-tuning-techniques-for-amazon-redshift-ja/
- 実績に基づいた力強い論考です。個人的には以下の項目が興味を引きました。
- 「1. カスタムの WLM(ワークロードマネージャー)キューを作成する」
- 「2. CDC(変更データキャプチャ)を使う」
- 実績に基づいた力強い論考です。個人的には以下の項目が興味を引きました。
-
https://www.integrate.io/jp/blog/15-performance-tuning-techniques-for-amazon-redshift-ja/
-
Amazon Redshift のパフォーマンスチューニング 十ヶ条まとめ (2022年 - )
- https://qiita.com/suzukihi724/items/c0c995f459e7bfb4e4d0
- マテリアライズド・ビューなど基本的なところから、ODBC/JDBCの注意ポイントなど幅広く記載されています。
-
Amazon Redshift 運用管理 (2021年)
- https://d1.awsstatic.com/webinars/jp/pdf/services/20210127_AWS_BlackBelt_RedshiftOperation.pdf
- p.41からp.50にかけて、WLM,SQA(ショートクエリアクセラレーション),ConcurrencyScalingなど、"クエリパフォーマンスチューニング Deep Dive"では言及されなかった「同時実行性能」に関わる項目が記載されています。
-
Amazon Redshift Advanced Guide 最新ベストプラクティスとアップデート (2020年)
- https://d1.awsstatic.com/webinars/jp/pdf/services/20200729_AWS_BlackBelt_RedshiftAdvancedGuide.pdf
- p.33からp.53にかけて、WLMの細かい優先度ロジックや、キューの設定例などが記載されています。
-
Amazon Redshift クエリの設計のベストプラクティス
- https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/c_designing-queries-best-practices.html
- 公式資料です。「select * は使用しない」等、基本的な重要ポイントを抑えるのに良い情報です。
パフォーマンスチューニングTips
パフォーマンスチューニングのアプローチ
-
正攻法としては以下のような順番でしょうか。
- テーブル設計を最適化する
- スキーマ構造(DWHなスノーフレークスキーマ、データマートなスタースキーマ)
- Redshift特有のテーブル物理設計
- クエリパフォーマンスを最適化する
- 単体クエリパフォーマンス
- 同時実行性能
- (マテリアライズド・ビューを使う)
- テーブル設計を最適化する
-
Redshiftのコンソールで確認できるアプローチとしては、以下のような感じになるかと思います。
- 物理設計(インフラ面)
- 「クラスターのパフォーマンス」を見る
- 論理設計(アプリ面)
- 全体的なチューニング観点
- 「アドバイザー」を見る(後述)
- 各クエリのチューニング観点
- 「クエリとロード」を見る(後述)
- 全体的なチューニング観点
- 物理設計(インフラ面)
-
テーブル設計の見直しは、DDL文にソートキーなどを追加するようなRedshift特有の変更であればたいしたことはありませんが、正規化・非正規化を伴うような場合は大手術になります。スキーマ構造の見直しが現実的でない場合は「クエリパフォーマンス」の対応でなんとかせざるを得ないことがあります。
-
効率的に対応するためには「木を見て森を見ず」にならないように意識がすることが大事です。
- 単体クエリパフォーマンスについては、以下の俯瞰図が便利です。
- 前掲の資料クエリパフォーマンスチューニング Deep DiveのP.40からの引用です。

- 単体クエリパフォーマンスについては、以下の俯瞰図が便利です。
テーブル設計関連
Redshift特有のテーブル物理設計
- データの性質やクエリパターンがわからない初期はAUTOで設定してもよいかと思います。
- 以下の記事では、手動設定による悪影響の例を記載しています。
- https://www.integrate.io/jp/blog/amazon-redshift-distkey-and-sortkey-ja/
-
データやクエリの性質をよく理解するまでは、DISTKEYとSORTKEYを確定しないのも選択してはありです。
- 以下の記事では、手動設定による悪影響の例を記載しています。
- シンプルに考える場合は以下のような設計になるかと思います。
- WHERE句で使用するカラム:sortkey (例)timestamp
- 一番大きいマスターテーブルとのJOINで使用するカラム:distkey (例)商品コード
- 小さいマスターテーブル:diststyle:all
アドバイザーを利用したRedshiftテーブル設計の見直し
- Redshiftコンソール画面左下にある「アドバイザー」をクリックすると、すでに何らかのワークロードがあり性能上の改善点が発生しているとRedshiftがみなした場合は、優先度ごとに推奨事項が表示されます。
- 具体的にはWLM、圧縮エンコード、統計情報、ソートキー、分散キー、データ型、COPY文など多岐にわたるトピックで助言と、具体的なSQLコマンドが表示されます。
- https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/advisor-recommendations.html
- 上記URLにも記載されていますが、対策を行う場合はワークロードが軽い時間帯で実施してください。特にALTER TABLE文を伴うものはテーブルロックが伴うため注意が必要です。
- 感覚値としては、[クエリとロード]に表示されるクエリ単位のチューニング項目よりも、全体的なアドバイザのほうが、実テーブル定義情報に基づいているため、より効果的な内容が表示されている感じがします。
- 例えば圧縮エンコードにおけるソートキーについては、第一ソートキーは未圧縮のままで、第二ソートキーは圧縮すべき、というようなアドバイスが表示されたりします。デフォルトのコンパウンドソートキーを使っている場合などは、そもそも現時点のソートキーの順番が適切であるか確認してからアドバイスに従う、という順番にしたほうがよいと思います。
単体クエリパフォーマンス関連
ソートキー(後日詳細記載)
- ソートキーデフォルトの挙動はコンパウンドソート(複合ソート)です。インタリーブソートの場合は明示的な指定が必要です。
圧縮エンコード(後日詳細記載)
- 列圧縮はカラムナデータベースにおいてはパフォーマンス上の重要な要素になります。とくにレコード数が多い場合への影響が大きいです。
- https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/c_Compression_encodings.html
- テーブル定義で圧縮系エンコードを何も指定しない場合
- デフォルト「ENCODE AUTO」となり、すべてのカラムの圧縮が自動で管理されます。
- テーブル定義で圧縮系エンコードを何か指定した場合
- 逆に1つのカラムでも圧縮エンコードを指定すると、「ENCODE AUTO」が解除となります。
- テーブル内で明示的にユーザが圧縮エンコードを指定していないカラムでも、Redshiftが自動的に圧縮エンコードを割り当てます(以下は上記公式ページからの引用です)
- ソートキーとして定義されている列には、RAW 圧縮が割り当てられます。
- BOOLEAN、REAL、または DOUBLE PRECISION データ型として定義されている列には、RAW 圧縮が割り当てられます。
- SMALLINT、INTEGER、BIGINT、DECIMAL、DATE、TIMESTAMP、または TIMESTAMPTZ データ型として定義された列には AZ64 圧縮が割り当てられます。
- CHAR または VARCHAR データ型として定義された列には、LZO 圧縮が割り当てられます。
- なお、コンパウンドソートキーは第1カラムを圧縮すべきではなく、第2カラムは圧縮してもよいようです(Redshiftのアドバイザーでも第1カラム圧縮は提言されない。逆に第1カラムや単一のソートキーが圧縮されているとrawへの戻しを提言される)
- https://aws.typepad.com/sajp/2015/12/top-10-performance-tuning-techniques-for-amazon-redshift.html
-
。コンパウンドソートキーの第1カラムは圧縮すべきでなく
パフォーマンス助言
-
[クエリとロード]画面では前記事にも記載したとおり、遅く改善の余地があるクエリについて、Redshiftからのアドバイスを確認することができます。
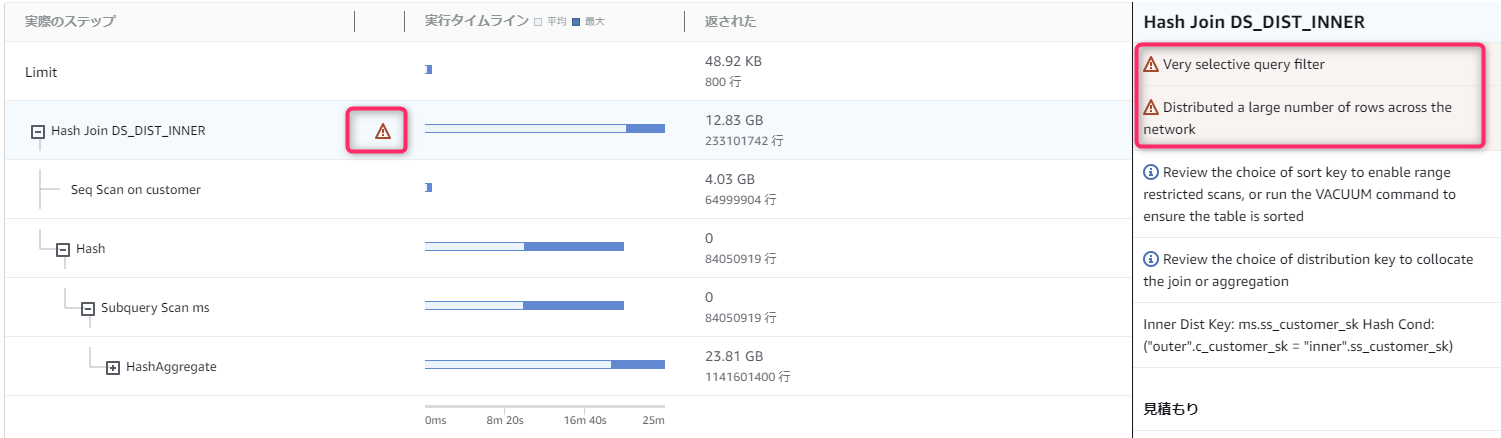
-
助言にたいしての対策はAWS公式にまとまっていません(AWSさんなんとかしてください)。
- 情報として以下のようなところに分散しています。日本語だとよくわからない翻訳になっていたりするので、適宜英語表記に直して確認してください。
-
助言と対策を少し無理やり表にしてみました。
| # | 英語表記 | 日本語表記 | 対策(概要) |
|---|---|---|---|
| 1 | Very selective query filter | 非常に選択的なフィルター | ソートキー見直しとVACUUMの実行 |
| 2 | Distributed a large number of rows across the network | サイズの大きな分散 | 分散スタイルの確認 |
| 3 | Broadcasted a large number of rows across the network | サイズの大きなブロードキャスト | 分散スタイルの確認 |
| 4 | DS_DIST_ALL_INNER for Hash Join in the query plan | 直列実行 | 分散スタイルの確認 |
| 5 | Missing query planner statistics | 見つからない統計 | データロードまたは大規模な更新の後で ANALYZE を実行 |
| 6 | Nested Loop Join in the query plan | Nested Loop | クロス結合を確認し、可能であれば削除 |
| 7 | Scanned a large number of deleted rows | 過剰な数の非実体行 | VACUUM コマンドを実行 |
- 体感として「クエリとロード」に表示されるアドバイスは、「テーブル定義などをRedshiftがチェックしたうえで助言している」のではなく、「統計情報を元に実処理で発生している課題点」という観点でチェックしているように見えます。
- 例えば「サイズの大きな分散」というアドバイスが出た場合に、JOINしているテーブルの定義情報から分散スタイルや分散キーを確認しても、適切に設定されているため対処が難しい場合などがあります。
- そのため、必ずしもRedshiftのテーブル定義だけで対処できるものとは限らず、データマートのテーブル設計や、クエリ発行側の改善など、広い視野で対処が必要なアドバイスが出る、という点には注意してください。
同時実行性能
Redshiftを使うと同時実行性能のチューニングを考える必要が出てくるのは、ある意味Redshiftのアーキテクチャの宿痾ともいえます。SnowflakeやBigQueryと比較すると、クエリ受付レイヤのリソースがシングルテナントのリソースに限定されてしまうからです。
SQAによるショートクエリの自動振り分け
- デフォルトで有効になっているキュー振り分け機能としてSQAがあります。
-
下図はAmazon Redshift 運用管理からの引用です。
-
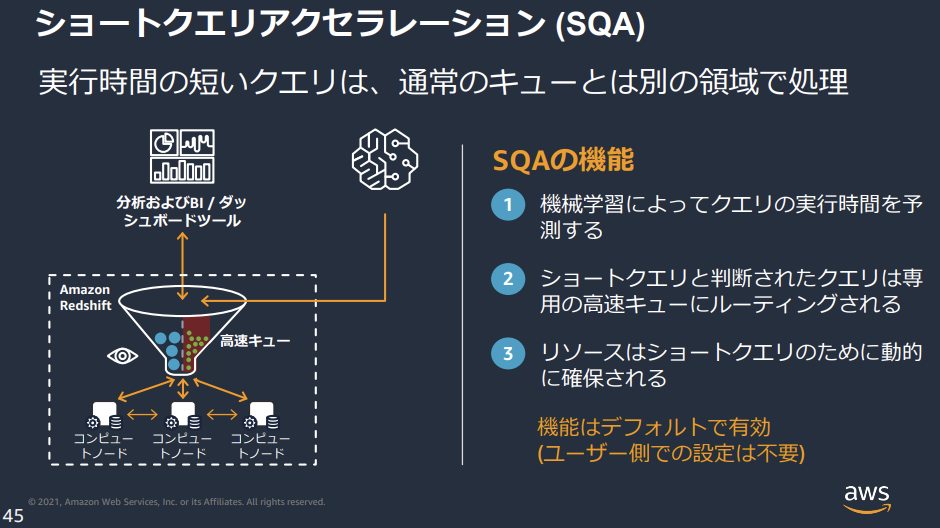
-
仕組みとしては以下のように、AIが予想した時間とキュー待ち状況に基づいてWLMからクエリを引きはがすようです。
-
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/wlm-short-query-acceleration.html
-
クエリの予測実行時間が、定義済みまたは動的に割り当てられた SQA の最大ランタイムよりも短く、クエリが WLM キューで待機している場合、SQA はクエリを WLM キューから分離し、優先的に実行するようにスケジュールします。
-
-
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/wlm-short-query-acceleration.html
-
また、SQAは後述するWLMと自動で連携するため、キュー管理機能のバッティングを気にする必要はありません。
-
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/automatic-wlm.html
-
自動 WLM と SQA は連携して動作し、長時間実行されるリソース集約型のクエリがアクティブな場合でも、短時間実行されるクエリや軽量のクエリを完了させることができます。
-
-
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/automatic-wlm.html
-
SQAは機械学習を利用しているので使うほど精度があがるようです。基本的にショートクエリはSQAに任せることにして、ワークロードに違いがある場合(バッチ用・BI用等)は、後述のWLMのカスタマイズがよいと思います。
-
WLMによるクエリキューの振り分け
事後的にクエリの長さでAIが自動でキューを判断するSQAと異なり、WLMは事前にユーザが設定した優先順位に基づき、キューの細かい振り分けができます。
WLMの理解
-
全般
- ワークロード管理 (WLM) とは
- クエリのキューが効率よく実行できるように順番やメモリ量などを管理できる機能です。
- リーダーノードにクエリが到達する前に、クエリの同時実行数や総メモリに基づいてキューの振り分けを自動で行います。
-
自動WLM(デフォルト)
- デフォルトでは、自動 WLM (クエリ優先度なし )の設定になっています。ただ以下の記事にあるように本番においては全体的な最適化がされるにしても、ビジネス視点ではムラが発生することもしばしばなようです。
-
https://www.integrate.io/blog/redshifts-automatic-wlm-with-query-priority-a-first-look-at-performance/
-
ただし、実際には、自動 WLM (クエリ優先度なし ) では、追加のキュー時間がデータ SLA、ひいてはビジネスに与える影響を知る方法がありません。したがって、クラスターのリソース使用がある程度効率的であるとしても、データ SLA に対する自動 WLM の最終結果はマイナスになる可能性があります。
-
-
https://www.integrate.io/blog/redshifts-automatic-wlm-with-query-priority-a-first-look-at-performance/
- デフォルトでは、自動 WLM (クエリ優先度なし )の設定になっています。ただ以下の記事にあるように本番においては全体的な最適化がされるにしても、ビジネス視点ではムラが発生することもしばしばなようです。
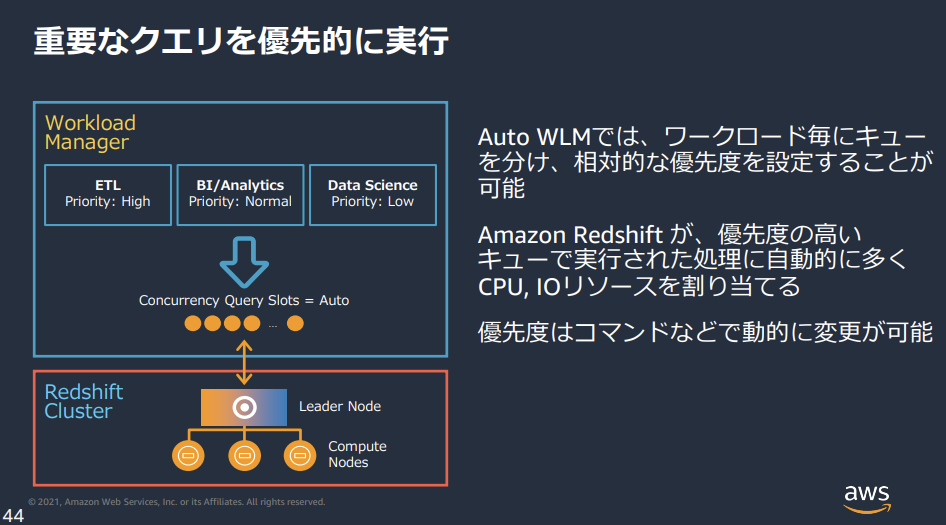
- 自動WLM(クエリ優先度あり)
- 自動WLMでは、メモリ量などは自動化の恩恵を受けつつ、人間がクエリを分類しHIGHEST,NORMAL,LOWなど優先度だけ設定することができます。
- 例えば、同一の負荷・同一のメモリ使用量のクエリが2つあったとして、人間がどちらのクエリを重視しているかはコンピュータには知りようがありません。それを教えてあげるのが、クエリ優先度の設定になります。
- 下図はAmazon Redshift 運用管理からの引用です。
- ワークロード管理 (WLM) とは
-
クエリキューの調整
- クエリキューの調整は、自動WLMと手動WLMのどちらでも可能です。自動のほうが設定が楽です。
-
https://repost.aws/ja/knowledge-center/redshift-wlm-etl-queues
- クエリキュー調整の選択肢は以下の3つです。
- [1] 自動WLM(デフォルト)
- [2] 自動WLM(クエリ優先度あり)
- [3] 手動WLM(クエリ優先度あり(きめ細やか))
- クエリのキューへの割り当て方法
- [2] 自動WLMの場合は、相対的な優先度を決めます。
- [3] 手動WLMの場合は、メモリ割り当て量などを決める必要があります。
- 割り当て対象
- その他知識
-
共通(自動WLM/手動WLM)
- 最大8個までキューを作成できる
- 最大50個までスロットを作成できる。ただし15個以下に抑えたほうがよい。
- 増やしすぎると1スロットあたりで使えるメモリが減り、悪影響もある。
- 実行時間が長いクエリを制限するようにクエリモニタリングルール (QMR) を設定することもできる
- 自動WLM
- 自動WLMの場合、デフォルト状態ではデフォルトキュー1つだけ存在し、スロット数(同時実行クエリ数)やメモリ量は自動で増減します。
- [メモリ] フィールドと [Concurrency on main (メインでの同時実行数)] フィールドはいずれも、[Auto (自動)] に設定されます
- 自動WLMで複数のキューを作成し、全て同一の優先度とした場合でも、特定のキューが無駄に未使用なメモリ領域を確保することはなく、各キューが横断的にクラスタ全体のメモリを利用します。
- https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/query-priority.html
-
クラスターで分析ワークロードのみが実行されている場合は、システム全体が最適化され、最適なシステム使用率で高いスループットが得られます。
- 手動WLM
- [メモリ] フィールドおよび [Concurrency on main (メインでの同時実行数)] フィールドの値を指定する必要があります。
- 手動WLMの場合、デフォルト状態ではデフォルトキュー1つだけ存在し、キュー内で5クエリを並列実行できます。
- https://www.slideshare.net/AmazonWebServicesJapan/amazon-redshift-118303349#42
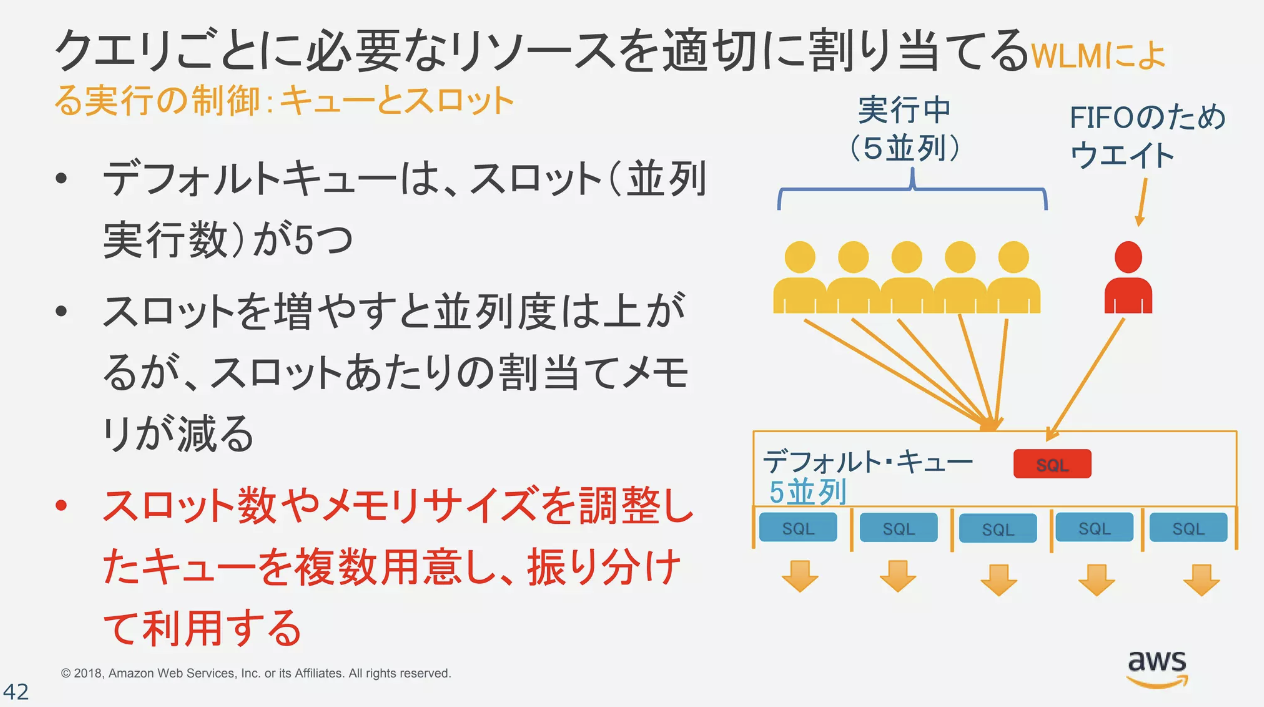
- [Concurrency on main (メインでの同時実行数)]とは
- 「Concurrency on main」とは、キュー内における「スロット数」を指します。手動WLMでは意識する必要はあります。
-
共通(自動WLM/手動WLM)

クエリキューの設計
-
キューの考慮で悩ましいのは、一般にキューの混雑状況が判明するのは本番のワークロードが始まったあとになるにもかかわらず、その対策はデータベースユーザやSQL文の変更が必要になるという点です。
-
キューのモニタリング
-
公式の「ワークロードの同時実行と同時実行スケーリングデータの表示」にRedshiftコンソールから待ちキューの確認方法が記載されています。
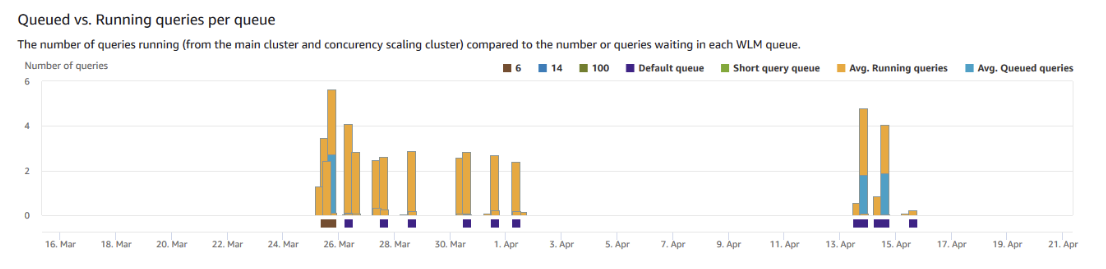
- このグラフの見方については後述します。
-
SQL文でクエリ毎の優先度を確認することもできます。
-
Manual WLM モードの Redshift クラスターで Concurrency Scaling 有効化や同時実行数のチューニングを行った運用知見と注意点について
- 実環境のグラフがありわかりやすいです。手動WLMでのConcurrency Scalingを用いた対策も記載されており、大変勉強になる記事です。
-
-
キューの設計について
-
個人的には、自動WLMでキュー優先度をカスタマイズできるように、早いうちにデータベースグループを設計しておくことが重要かと思います。
-
前掲の資料Amazon Redshift のパフォーマンス調整のテクニック15選では、真っ先に「カスタムの WLM(ワークロードマネージャー)キューを作成する」という項目が挙げられています。
-
デフォルトの WLM の構成では、5つのスロットを持つ単一のキューがあります。ただこのデフォルトの構成ではほぼ99%うまくいかないので、微調整が必要です。
- 上記のページは自動WLMローンチ後の2023年の記事ですが、書き方として手動WLM/自動WLMどちらでも参考になる書き方がされているので読解に注意が必要です。
- 例えば「5つのスロットを持つ単一のキュー」があるのは手動WLMです(自動WLMはスロット数が変動)。自動WLMがローンチされたのは2019年であり、上記記事は2023年のものですが、文脈から見る限り手動WLMを前提とした観点で語られています。
-
-
自動WLMの設定指針については、上記と同じintegrate.ioによる記事に記載されています。(それぞれ異なる著者で、異なる視点のワークロード)
- どちらもBIダッシュボード系をHIGHESTとして、バッチ系はHIGHなどに設定されています。
- 3 Steps to Set up Automatic WLM with Query Priority in Amazon Redshift 2021年
-
Redshift’s Automatic WLM with Query Priority:
A First Look at Performance 2021年- バッチ系のクエリキューはConcurrency Scalingを有効にしているようです。
-
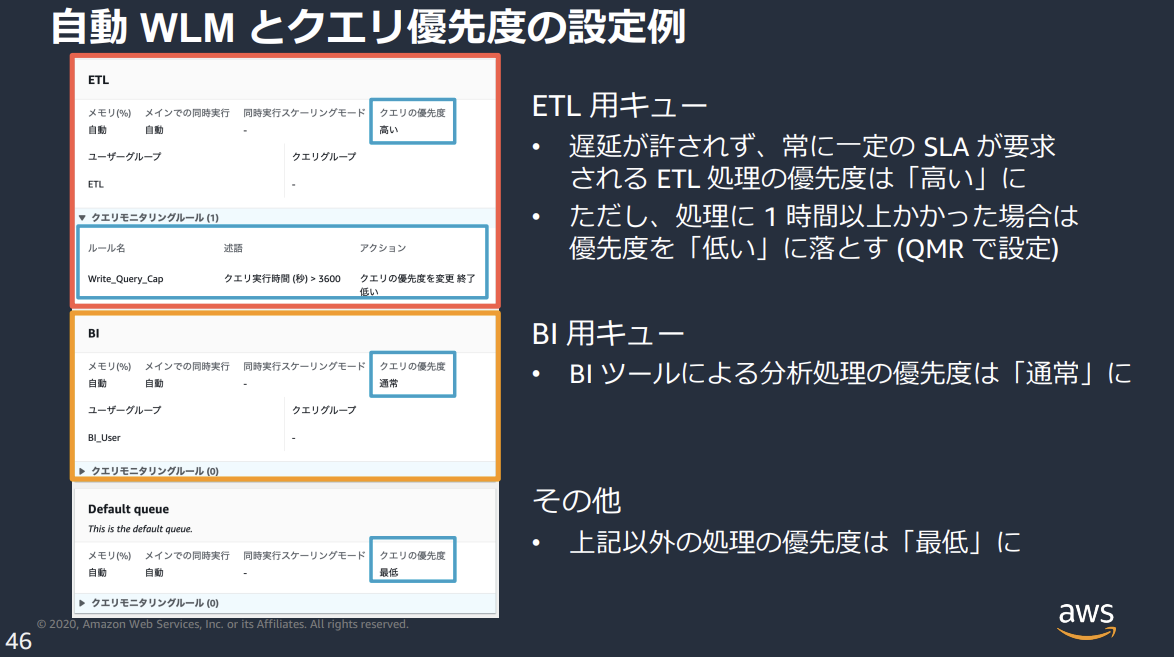
前掲の資料Amazon Redshift Advanced Guide 最新ベストプラクティスとアップデートには設定例が記載されています。こちらはintegrate.ioの例とは異なり、BIよりもETLを優先しています。
-
Redshiftを数百人で使うためのコツ(クラスター構成編) 2018年
- 手動の設計方針が記載されています。SQAの効果など非常に貴重な情報が記載されています。
-
- 2014年の記事ですが、手動の場合の設計方針や、優先順位、設定変更による影響など、まとまっています。
-
チュートリアル: 手動ワークロード管理 (WLM) キューの設定
- 公式によるチュートリアルです。
-
-
キューの変更適用について
- 自動WLMの全てのパラメータの変更はクラスタ再起動が不要です。手動WLMの各パラメータの変更は多くがクラスタ再起動を伴います。自動・手動の切替はクラスタ再起動が伴います。詳しくは下表に記載があります。
ConcurrencyScaling
(後日記載)
その他(Redhsift機能がらみ)
「アドバイザー」を利用した調査(後日詳細記載)
クエリエディタ(Redshift query editor v2)
-
SQL文字数の上限
- 実行できる文字数と保存できる文字数に違いがあります。
-
https://docs.aws.amazon.com/ja_jp/redshift/latest/mgmt/query-editor-v2-using.html
-
最大 300,000 文字のクエリを実行できます。
-
最大 30,000 文字のクエリを保存できます。
-
- 長文のクエリを複数実行した場合、(基本的に警告を出してくれますが)、実行後セッションに再接続するとSQL文が全て消えていたなんてこともあります。
-
「クエリエディタの履歴」「クエリとロード」どちらを見るべきか?
- 基本的に情報が豊富な「クエリとロード」を見ましょう。
- クエリの実行履歴を見る場合は以下の2つの方法があります。
- マネジメントコンソールの「クエリとロード」
- クラスタに対して実行されたクエリが表示されます。
- クラスタの再起動で履歴が消えます。
- システムで最も長く実行されている最大 100 件のクエリが表示されます。
- クエリエディタの「履歴」
- こちらはクエリエディタつまりSQLクライアント単体の実行履歴という扱いです。
- 過去にクエリエディタで実行したクエリの所要時間を確認する程度であれば役に立ちます。
- クラスタ再起動でも履歴は残ります。
- 直近の 1000 個までのクエリ実行記録を保持します。
- マネジメントコンソールの「クエリとロード」
-
注意事項
- クエリエディタは内部で複数のAPIなどを実行することから表示がおかしくなることがあります(2023年8月時点)。
- たとえばマネジメントコンソールの「クエリとロード」上では状態が「中止済み」となっているクエリのIDが、クエリエディタ上だと「実行中」になっている場合などがあります。
- 私が確認した限りでは「クエリとロード」のほうが正しい状態を表示しますので、「クエリとロード」を信用するようにしましょう。
- クエリエディタは内部で複数のAPIなどを実行することから表示がおかしくなることがあります(2023年8月時点)。
「クエリとロード」
概要
- 概要
クエリのチューニング(後日詳細記載)
-
クエリプランの評価
-
Top 10 performance tuning techniques for Amazon Redshift
-
クエリ調整用の診断クエリ
WLMキューのモニタリング
前述しましたように、自動WLMでキューを複数作った場合は各キューの優先度が適切にパフォーマンスを発揮しているかモニタリングしていく必要があります。
- 確認するにはクラスタを選択後、「クエリのモニタリング」-> 「ワークロードの同時実行」を選択します。
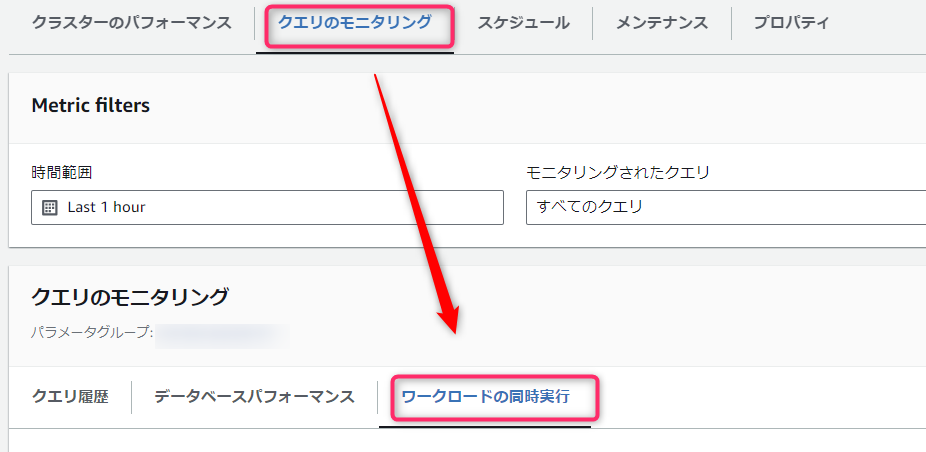
- 例えばワークロード管理のパラメータグループで、以下のように自動WLMのキューを作成したとします。
- bi
- dwh
- dataengineer
- Default queue
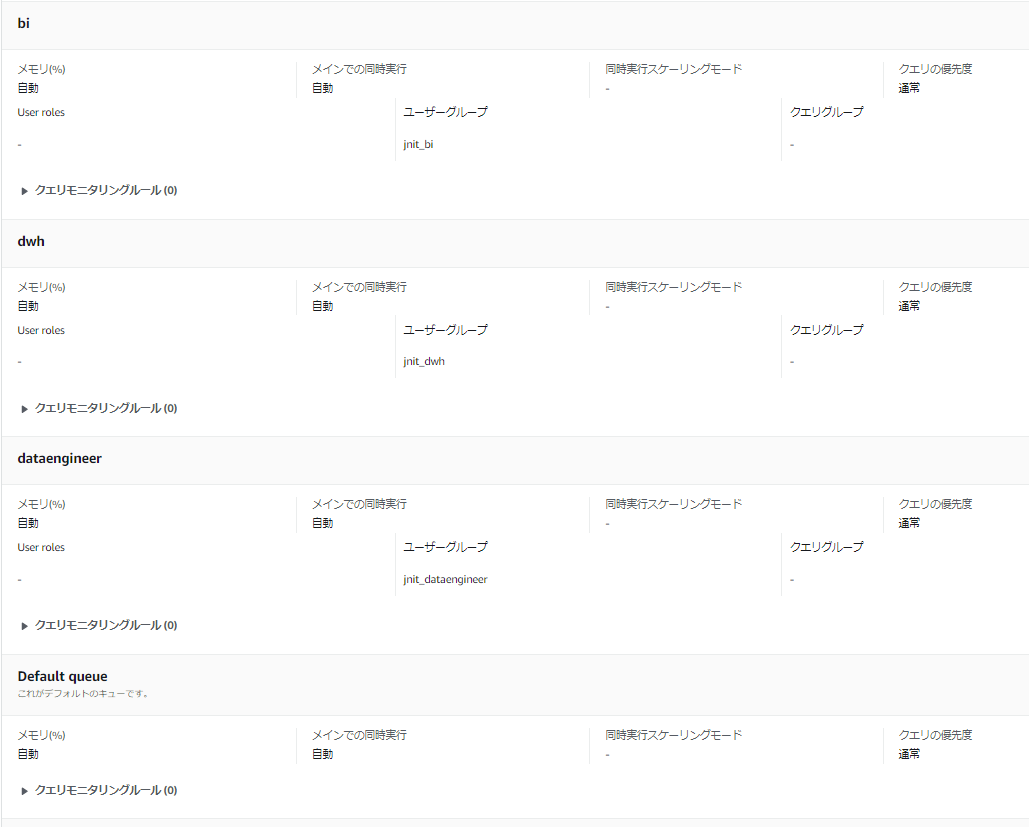
- 上記のような構成で、以下のように作成したキューが「WLMサービスクラスID」で色分けされて表示されます。
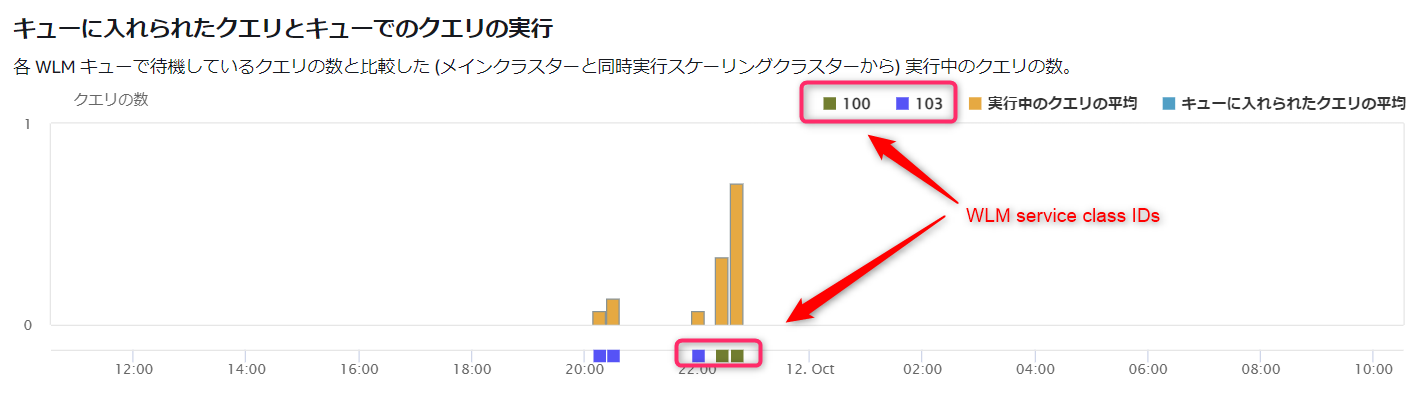
- 2023/10/12時点では残念ながらグラフ上にサービスクラス名(上記でいうと「bi」など)が表示されることはなく、サービスクラスIDで表示されてしまいます。
- また、「Default queue」は追加キューがない状態だとグラフ上で「Default queue」としてサービスクラス名が表示されるのですが、自分でキューを追加するとグラフ上もサービスクラスIDで表示されるようになってしまいます。
- サービスクラスIDを確認するには、別途SQL文で調査する必要があります。調査はシステムテーブルのSTV_WLM_SERVICE_CLASS_CONFIGを参照します。
select
service_class,
rtrim(name) as name,
rtrim(concurrency_scaling) as concurrency_scaling,
rtrim(query_priority) as query_priority
from
stv_wlm_service_class_config
where
service_class >= 100; -- ユーザ追加キューはservice_classが100以上の値となる
出力結果例

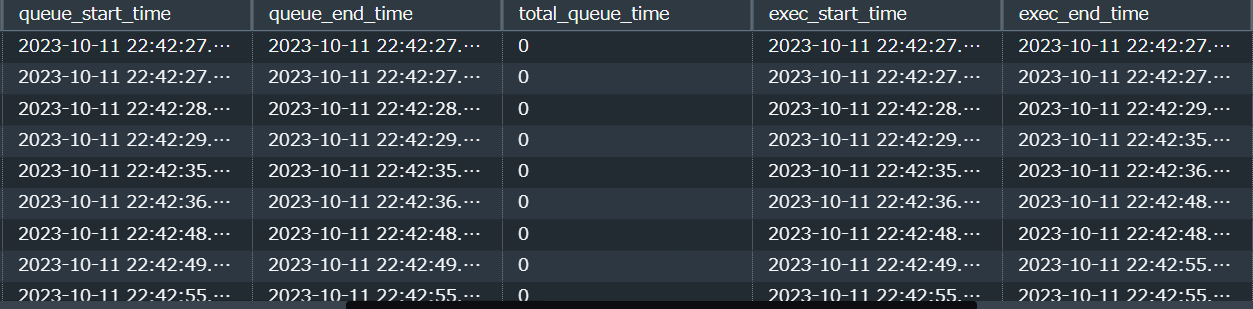
そのほか、過去7日分のキューの状況はシステムテーブルのSTL_WLM_QUERYから調査することができます。
select
query,
service_class,
rtrim(service_class_name) as service_class_name,
slot_count,
CONVERT_TIMEZONE('Asia/Tokyo', queue_start_time) as queue_start_time,
CONVERT_TIMEZONE('Asia/Tokyo', queue_end_time) as queue_end_time,
total_queue_time,
CONVERT_TIMEZONE('Asia/Tokyo', exec_start_time) as exec_start_time,
CONVERT_TIMEZONE('Asia/Tokyo', exec_end_time) as exec_end_time,
total_exec_time,
CONVERT_TIMEZONE('Asia/Tokyo', service_class_end_time) as service_class_end_time,
rtrim(query_priority) as query_priority
from
STL_WLM_QUERY
where
service_class >= 100;
出力結果例(一部の列のみ抜粋)
-
各キューの以下の時間を見比べることでキュー待ち状況を確認することができます。
- 「キューに入って実行待ちになっている時間( queue_start_time から queue_end_time )」
- 上記2つの差分が「total_queue_time」
- 「実行時間( exec_start_time から exec_end_time )」
- 上記2つの差分が「total_exec_time」
- 「キューに入って実行待ちになっている時間( queue_start_time から queue_end_time )」
-
調査方法は他にも公式のサンプルクエリもあるので確認してください。
その他(Tableauがらみ)
Tableauクエリのパフォーマンス調査アプローチ
TableauなどBIツールからRedshiftを参照することが多いと思います。そのような場合、Tableau側とRedshift側のどちらで対処すべきパフォーマンス問題なのか、確認が必要になります。
- Tableau側では1つのダッシュボードの表示であっても、複数のレポートが含まれていたり、各種フィルタがかかっている場合などに、内部で複数のクエリが並列実行されます。
- まずTableau側で時間がかかる処理を行う際に、「パフォーマンスの記録」情報を取得してください。
- 取得する際は、Tableau側とRedshift側のキャッシュをOFFにします。
- 可能であれば、同じ操作を複数回記録してください。同じ操作であっても、Tableau側で並列実行されるクエリの順番が異なることが多いため、クリティカルパスも毎回変化します。複数回の記録を確認したうえで、効果の高そうなクエリを複数、選定します。
- Tableau Desktopにおける「パフォーマンスの記録」方法は以下。
- パフォーマンスの結果は、Tableauのワークブック(.twbx)として出力されます。
- 出力されたファイルをTableauDesktopで確認してください(TableauPublicでは閲覧不可)
カーソルの調査
- Tableau からRedshiftへのクエリはカーソルで実行されることがしばしばあります。Redshiftの「クエリとロード」画面では以下のように表示され、チューニングしようにも元のSQL文がわかりません。
fetch 10000 in "(カーソル名称)";
そこで、クエリを復元する必要がでてきます。
所要時間から調査するアプローチ
- 「クエリとロード」画面にて、所要時間の遅いカーソル利用クエリをつぶしていく場合は、カーソル名称とプロセスID(PID)をメモしておきます。

- 注:なお、ここで見つけづらい場合はSTL_QUERY テーブルを直接参照するのも一つの手です。
次に以下のSQL文を実行します。("カーソル名称" と "PID" はご自身の情報に置き換えてください。)
SELECT
*
FROM
(
SELECT
DISTINCT xid,
pid,
CONVERT_TIMEZONE('Asia/Tokyo', starttime) as starttime,
LISTAGG(rtrim(text)) WITHIN GROUP (
ORDER BY
sequence
) OVER (PARTITION BY starttime) AS sql_text
FROM
svl_statementtext
GROUP BY
xid,
pid,
starttime,
sequence,
text
) as t
WHERE
sql_text like 'declare%<カーソル名称>%'
AND pid = '<PID>';
-
ポイント
- カーソルの宣言箇所「declare」を元に「svl_statementtext」テーブルに保存されたクエリ(ただし1SQL文は往々にして複数行に分割されている)を復元しています。
- PIDを限定することで、Tableau側で同一のカーソル名称が使い回されている場合でも特定できるようにしています。
- テキストのスペースをrtirm関数で除外することで、LISTAGG関数の文字制限(65535)にできるだけ引っかからないようにしています。
- 注意点として、複数の行を強引に結合しているため、結合箇所の文字列が一部欠損します。
-
結果として、クエリの実行時間(JST)とSQL本文が表示されます。
-
なお上記SQLは以下の記事をアレンジしたものです。執筆者様に深く感謝します。

Tableauの操作時間から調査するアプローチ
Tableau側の特定の操作時間がわかる場合は、「クエリとロード」を見る前に、先程のSQL文のWHERE句を以下例のように書き換えて実行してください。(時間は要書き換え。少なくともクエリエディタからの場合は、JSTベースで扱ってくれます)
WHERE
sql_text like 'declare%SQL_CUR%'
AND starttime between '2023-10-31 11:55:00' and '2023-10-31 12:00:00'
order by starttime asc;
該当する時間の複数のクエリが出力されますので、そこからTableau側のクエリと合致しそうなものを抜き出し、pidを確認します。その後「クエリとロード」から該当するpidを検索し、アドバイス内容を確認します。
Tableauによるクエリの調査
- あとはクエリプランのアドバイス内容をもとに対処が必要そうな処理を特定します。そしてSQL本文をもとにテーブル名を特定します。テーブルの定義情報を確認し、ソートキーや分散キーの見直しを検討していきます。
- ただし、Tableauでは計算フィールド、フィルタ、LOD表現を使う場合などに、複数のJOINやサブクエリを用いるような複雑なクエリが生成されることが多く、調査は茨の道になりがちです。
- 正論・理想論にはなってしまいますが、BI側で複雑な処理をするよりも、可能な限りRedshift側でテーブル設計の見直し(ETLで集計済みデータマート用テーブルを作る、マテリアライズド・ビューを作る、など)をしたほうが望ましいです。
おわりに
各クラウドデータウェアハウスサービスの使い分け
- 私の印象としてはインフラ運用の簡便さで考えるとSnowflake、性能で考えるとBigQuery、常時起動をベースとしたコストパフォーマンスで考えるとRedshift、という使い分けがよい気がしています。(Azure Synapse Analyticsは触ったことがない)
- なお、Clouderaスポンサーのレポートではコスパの良さを比較していますが、Redshiftは良い成績を記録しています。(あくまでコスパであり、速度ではない点に注意)
以上です