Amazon Redshift は Serverless版もGAされ、さらにATO:Automatic Table Optimization(自動テーブル最適化)など、従来からある Provisioned版含めてパフォーマンスチューニングがどんどん自動化されてきている。
一方で、実運用では高負荷など使い方によって問題が全く起こらないことは考えにくく、困った時にチューニングの余地があることはメリットでもある。
以下の公式ブログの Tips をもとに困った時のチューニング対処ポイントをまとめる
※ 記事は 2020年 のものなので、その後新機能でカバーできる点や、主観的な考えについて適宜補足しています。
[1] マテリアライズドビューを使う
- 予測可能で何度も繰り返されるクエリに特に効果を発揮する
- 内部テーブルだけでなく、外部テーブル(Spectrumやフェデレーション)にも使える
- マテビューの更新はオプションで自動更新(
AUTO REFRESH)も可能 - 自動クエリ書き換えで、マテリアライズドビューを明示的に参照しないクエリでもよしなにマテビューを参照してくれる
- AutoMV機能により、Redshiftが「マテビューにした方が良い」と自動的に判断してマテビューを有効活用もしてくれる(ユーザーが意識しなくてもマテビューの恩恵を受けられる)
- ただし、自動系の機能は各種適用条件などもあるので、かならず恩恵を受けられない可能性もある点は要考慮
[2] 同時実行スケーリングとElastic Resizeでバースト負荷対策
- Serverless版は勝手にやってくれる機能なので、意識するのはProvisioned版のみ
- 複数ユーザの同時アクセス過多など予測が難しいタイミングでキューにクエリが溜まった場合にオフロードしてくれるのが同時実行スケーリング。デフォルトは無効化されているので有効化が必要。
- 月末月初や、夜間バッチなど予測可能な高負荷に対して一時的にクラスタをスケールアップするのがElastic Resize(伸縮自在なサイズ変更)。
- どちらも基本ダウンタイムゼロ。Elastic Resizeはリサイズは数分以内に完了し、コネクションは維持されるが一部クエリが削除される可能性はあるので冪等性を担保したリトライ制御は要考慮。
- どちらも基本的に追加コストがかかる。同時実行スケーリングは1日あたり1時間に相当する無料枠があり、USAGE LIMIT機能で適応時間の上限値の設定もできるので、工夫することで無料枠内での利用もできる。
同時実行スケーリングを有効化べきかの判断材料
- まず、queuing_queries.sql 管理スクリプトを使用して、キューに入っているクエリがあるかどうかを確認
- wlm_apex.sql でクラスターが過去に必要とした最大同時実行数を確認するか、wlm_apex_hourly.sql で時間ごとの履歴分析を行う。
[3] Redshift Advisor のレコメンデーションを参照する
- AWSマネコンの Redshift アドバイザーの推奨事項をチェックして改善する
- 例えば、分散キー、ソートキー、圧縮エンコード、統計情報更新(Analyze実行)など、パフォーマンス改善の対処案を提示してくれる

参考)自動テーブル最適化
自動テーブル最適化(ATO)で、ワークロードから最適な設定に自動チューニングする機能も実装されている。
なおATOはRedshiftがAIで独自にワークロードを分析して最適化を段階的に実施するので、すぐに改善されるものではなく、以下のTPC-Hベンチマークテストでは、段階的に自動最適化され、約1.5日ほどで性能が24%改善されている。

[4] 優先順位付きの Auto WLM でスループット向上
- Auto WLM(自動WLM)でクエリ同時実行数とメモリ割り当てを自動最適化してくれる
- ワークロードに応じて(例:ETL、アドホッククエリ)優先度を5段階でつけることも可能
- Auto WLMは 2021年にさらに機能強化されて性能向上し、手動WLMよりもイケてる
- ショートクエリを高速優先処理するSQAもスループット向上に役立つ(デフォルトで有効化されている)
[5] データレイクインテグレーションを活用
- S3のデータへ直接クエリするSpectrum/DataLake Queryをうまく活用
- Redshift Spectrum は、メインクラスターの処理能力の最大約 10 倍の処理能力を自動的に割り当てるため、Redshift Spectrum コンピューティングレイヤーを使用してメインクラスターからワークロードをオフロードするアプローチ。
- UNLOADコマンドでRedshiftのデータをS3にParquetフォーマットで出力もできる
[6] Tempテーブルの有効活用
- Tempテーブル(一時テーブル)とは、現在のセッション内でのみ表示可能な一時テーブル(作成したセッションの終了時に自動的に削除される)
- 以下の理由でTempテーブルへのデータ取り込みはオーバーヘッドが軽減され、実行速度が大幅に向上。
- 通常の永続テーブルとは異なり、一時テーブルにデータを変更しても Amazon S3 への自動インクリメンタルバックアップはトリガーされない。
- データの冗長コピーを別のコンピューティングノードに保存するための同期ブロックミラーリングも必要ない。
- 注意点としては、一時テーブルはデフォルトでRAW圧縮(非圧縮)になる、同時実行スケーリングのオフロード対象外(2022年12月時点)など、永続テーブルと挙動が異なる点もあるため、一律で一時テーブル化がスループット観点で最適とはいえない。
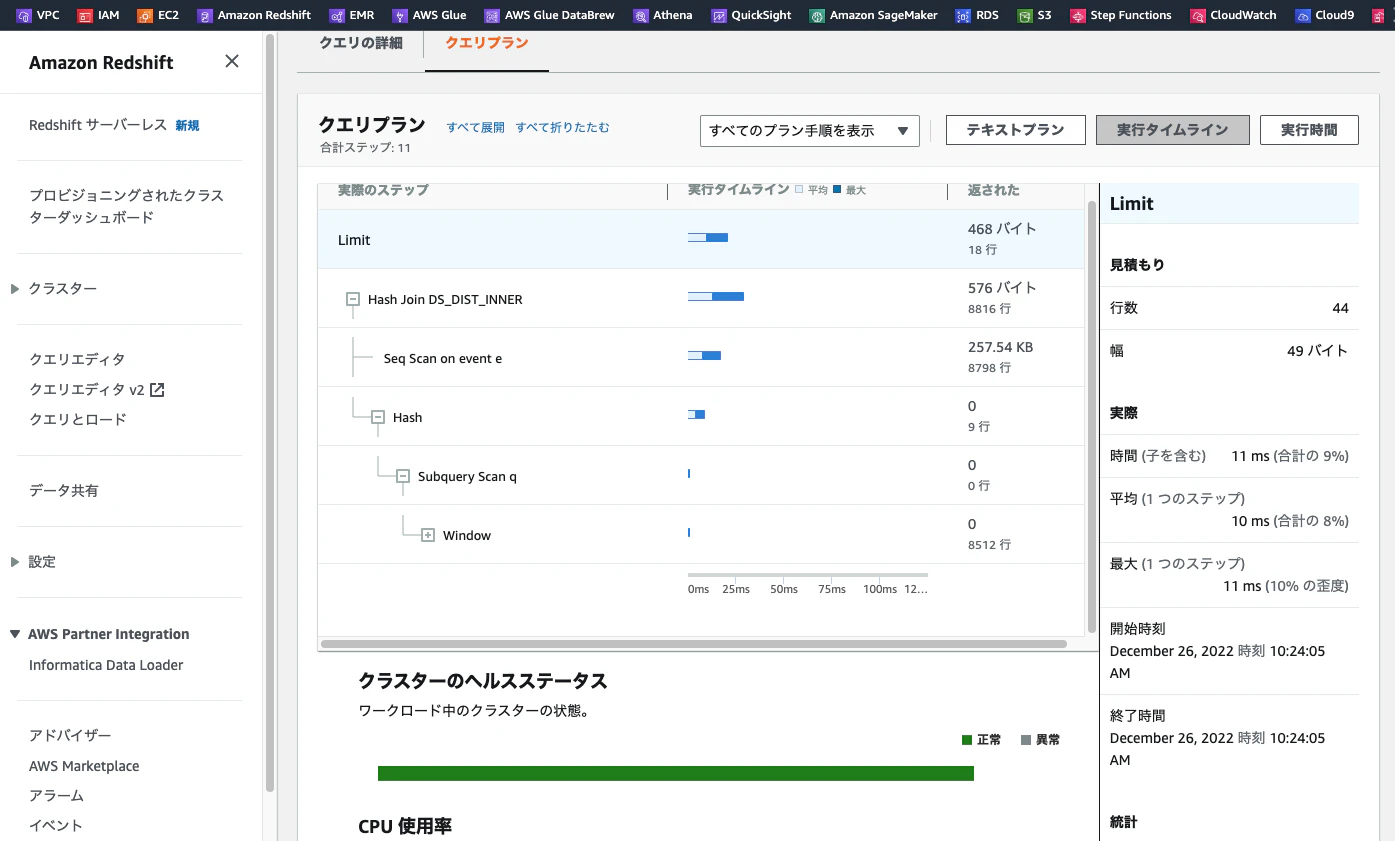
[7] QMR と Cloud Watch メトリクスを活用
- Redshiftコンソール、システムテーブル、Cloud Watch それぞれで負荷状況は色々確認できる
- 特に設定不要で Redshiftコンソールからクエリ履歴、DBパフォーマンス、ワークロードの同時実行数状況などは可視化されている
- 以下のシステムテーブル(ビュー)からより詳細な情報をクエリできる
-
SVL_QUERY_METRICS_SUMMARY
- 例えば
query_temp_blocks_to_diskは中間結果の書き込みに使用するディスク容量 (MB)を示し、処理がオンメモリで完結せずにDISK書き出しのオーバーヘッドがあることを意味する
- 例えば
- STL_QUERY_METRICS
- STV_QUERY_METRICS
-
SVL_QUERY_METRICS_SUMMARY
- Cloud Watchと連携すれば、独自の監視ダッシュボードカスタマイズや、通知連携など可能
参考) AWSマネコン:Redshiftコンソール
①クエリ履歴

②データベースパフォーマンス

③ワークロードの同時実行

[8] フェデレーテッドクエリの活用
- [5]と同様のアプローチで外部データソースに直接クエリする
- ETLやLOAD負荷を簡素化する
[9] データロードの効率化
- INSERTではなくCOPYコマンドを使う
- ロードするデータファイルは圧縮する(圧縮ファイルサイズは 1MB〜1GB 目安)
- ロードするデータファイルは大きいファイル1つより、小さいファイル複数(クラスターの合計スライス数の倍数)とする
- amazon-redshift-utils の CopyPerformance は、各ロードの統計情報を計算できる。また、[3] の Amazon Redshift Advisor は、スライスの数に基づいて圧縮されていない場合やファイルが少なすぎる場合にも警告してくれる。
[10] AWS の最新の Amazon Redshift ドライバーを使用
- 古いものは使わない
JDBC の場合は次の点を考慮
- JDBC を使用して大規模なデータ セットを取得するときにクライアント側のメモリ不足エラーを回避するには、JDBC fetch size パラメータまたは BlockingRowsMode を設定して、クライアントがバッチでデータをフェッチできるようにします。
- Amazon Redshift は JDBC maxRows パラメータを認識しません。代わりに、LIMIT 句を指定して結果セットを制限してください。また、OFFSET 句を使用して、結果セット内の特定の開始点にスキップすることもできます。
ODBC の場合は、次の点を考慮
- useDelareFecth が有効な場合、クラスターのリーダー ノードでカーソルが有効になります。カーソルは fetchsize/cursorsize までフェッチし、アプリケーションが追加の行を要求すると、追加の行をフェッチするために待機します。
- CURSOR コマンドは、リーダー ノードでカーソルの動作を操作するためにアプリケーションが使用する明示的なディレクティブです。 JDBC ドライバーとは異なり、ODBC ドライバーには BlockingRowsMode メカニズムがありません。
- 明確な必要性がない限り、ドライバーのチューニングを行わないことをお勧めします。