はじめに
ドキュメント指向データベースをBIツールで分析する場合、どのようなテーブルになるのか確認してみます。
BIツールはTableauを使い、ドキュメント指向データベースはMongoDB Atlasを使ってみます。
MongoDB Atlasを選定した理由は、Tableauで接続できる「BI Connector」が手軽に使えるからです。
なお私はMongoDBもTableauも全くの素人です。
用語の使い方に間違いがあるかもしれません。(ご指摘いただけると嬉しいです)
環境
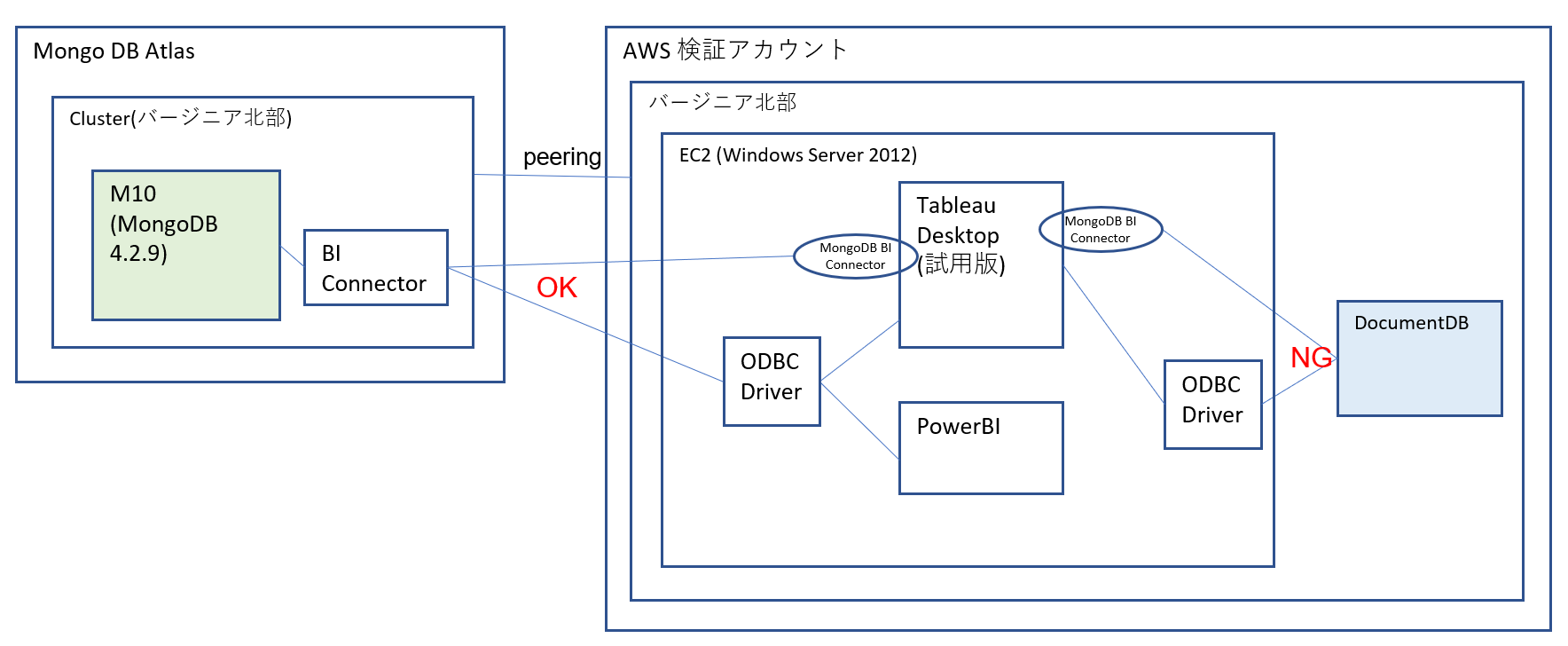
以下のような構成図になっています。
主目的はBI Connectorの利用なのでMongoDBに接続していますが、ついでに以下もためしました。
- [MongoDB Atlas]と[AWS]とのVPCピアリング
- [Tableau]から[Amazon DocumentDB]への接続
バージョンは以下のとおりです。
| 対象 | バージョン |
|---|---|
| Tableau Desktop | 2020.3.0 |
| MongoDB Atlas | 4.2.10 |
なお、
Tableauは「MongoDB BI Connector」というデータソースがあります。
MongoDB Atlasには「BI Connector」というサービスがあります。
まぎらわしいので以後は後者のほうを 「Atlas BI Connector」と呼ぶことにします。
接続先の用意
MongoDB Atlas
アカウントのセットアップ
とりあえずアカウントを作成します。
最初は無料版を選択してみます。
無料版クラスタの作成
AWS上に作成します。無料版なので東京リージョンは選べないため、バージニア北部を選択します。
スクロールしM0クラスタを作成します。
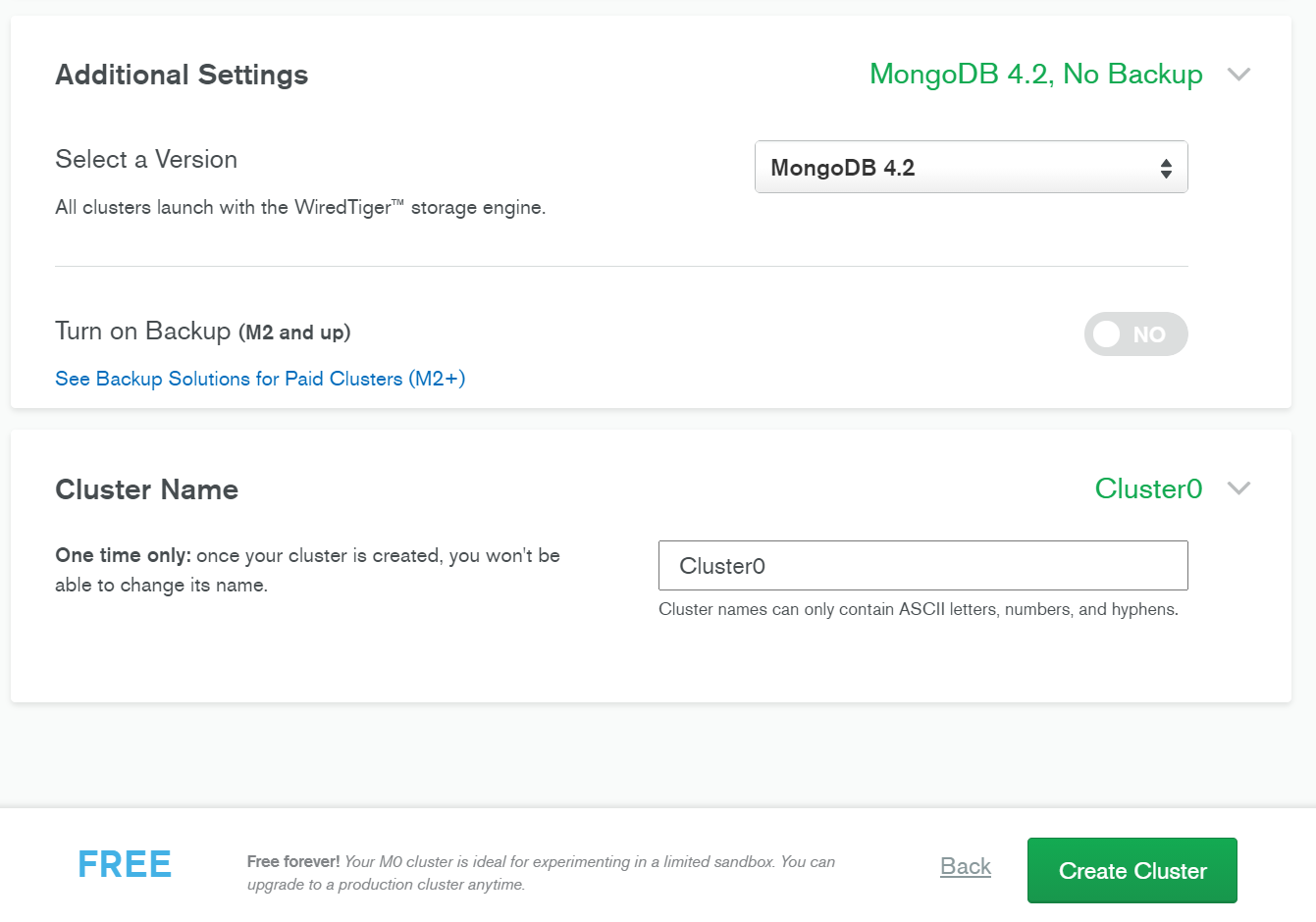
ウィザードが次に何をすべきか指示してくれます。
DBユーザの作成
DBユーザを作成します。
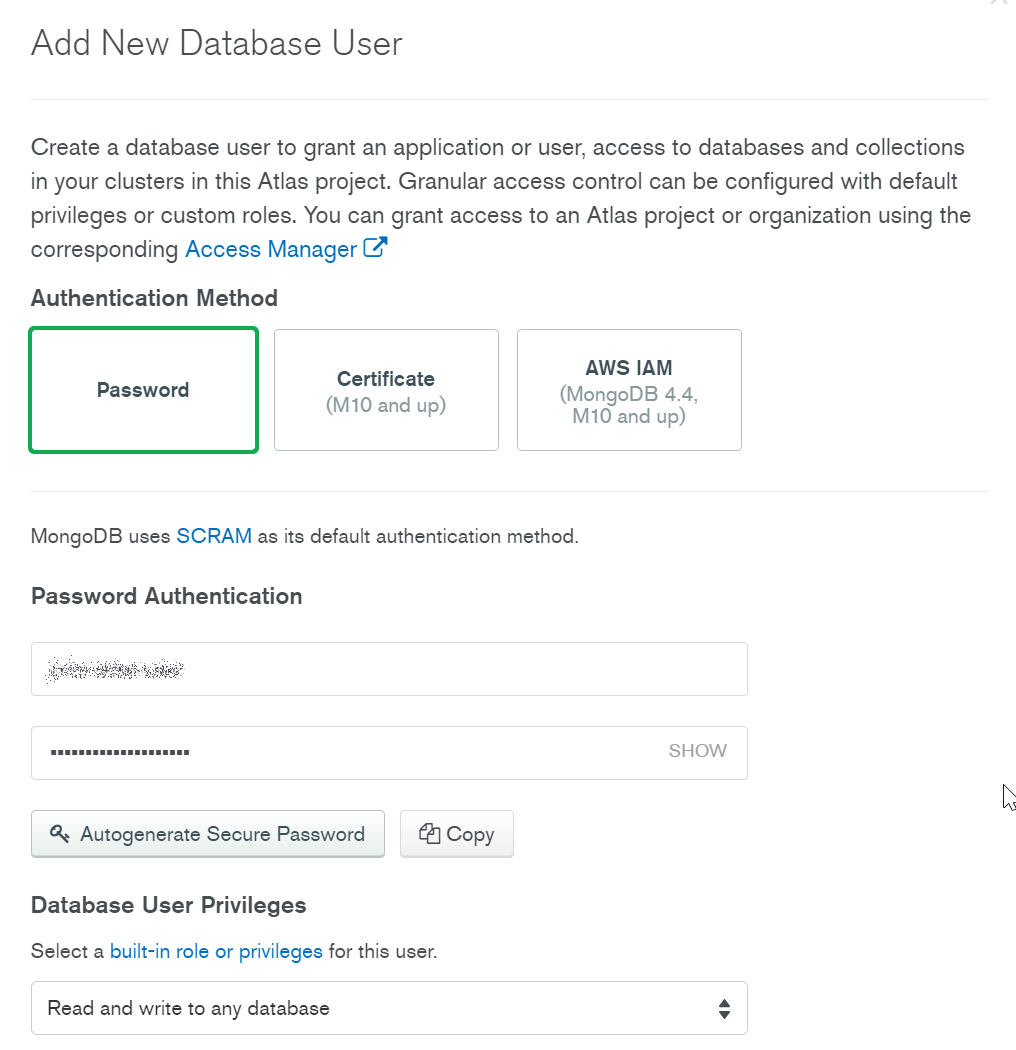
とりあえずパスワード認証で、権限は「Read and write to any database」にしてみます。
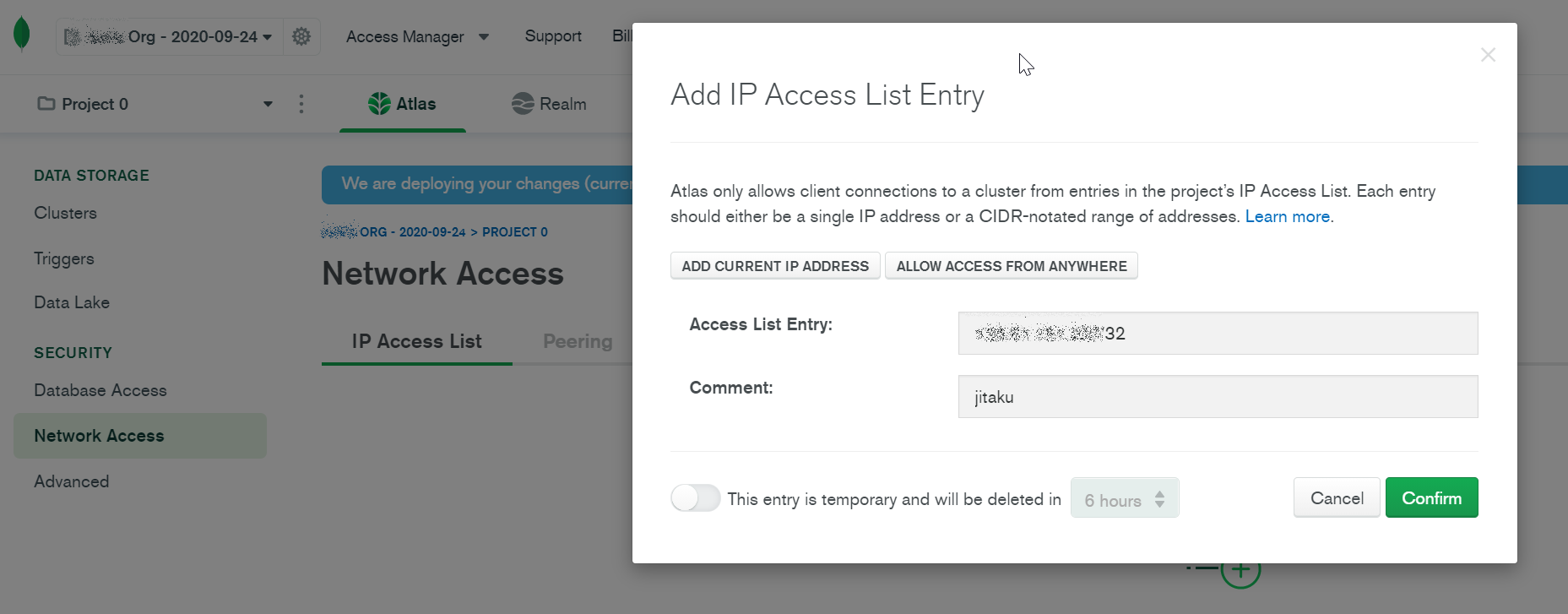
ホワイトリストの登録
接続元のIPを登録(自宅と、ピアリング先のAWSのVPCのセグメントを登録しました)
サンプルデータの読み込み
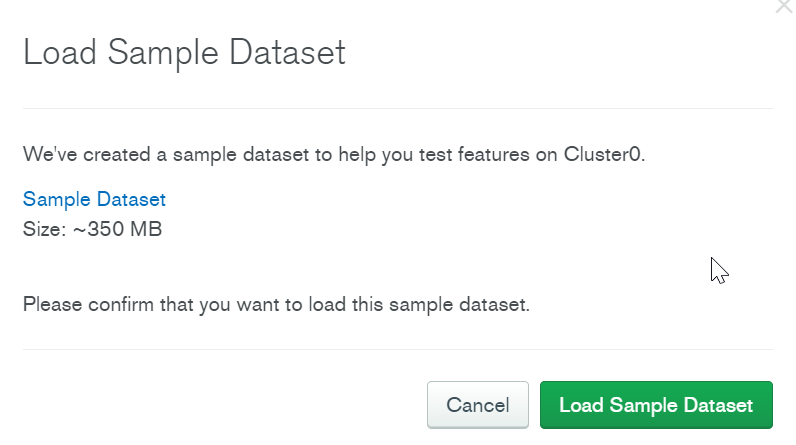
サンプルデータがあるようなので、三点リーダーから取り込んでみます。
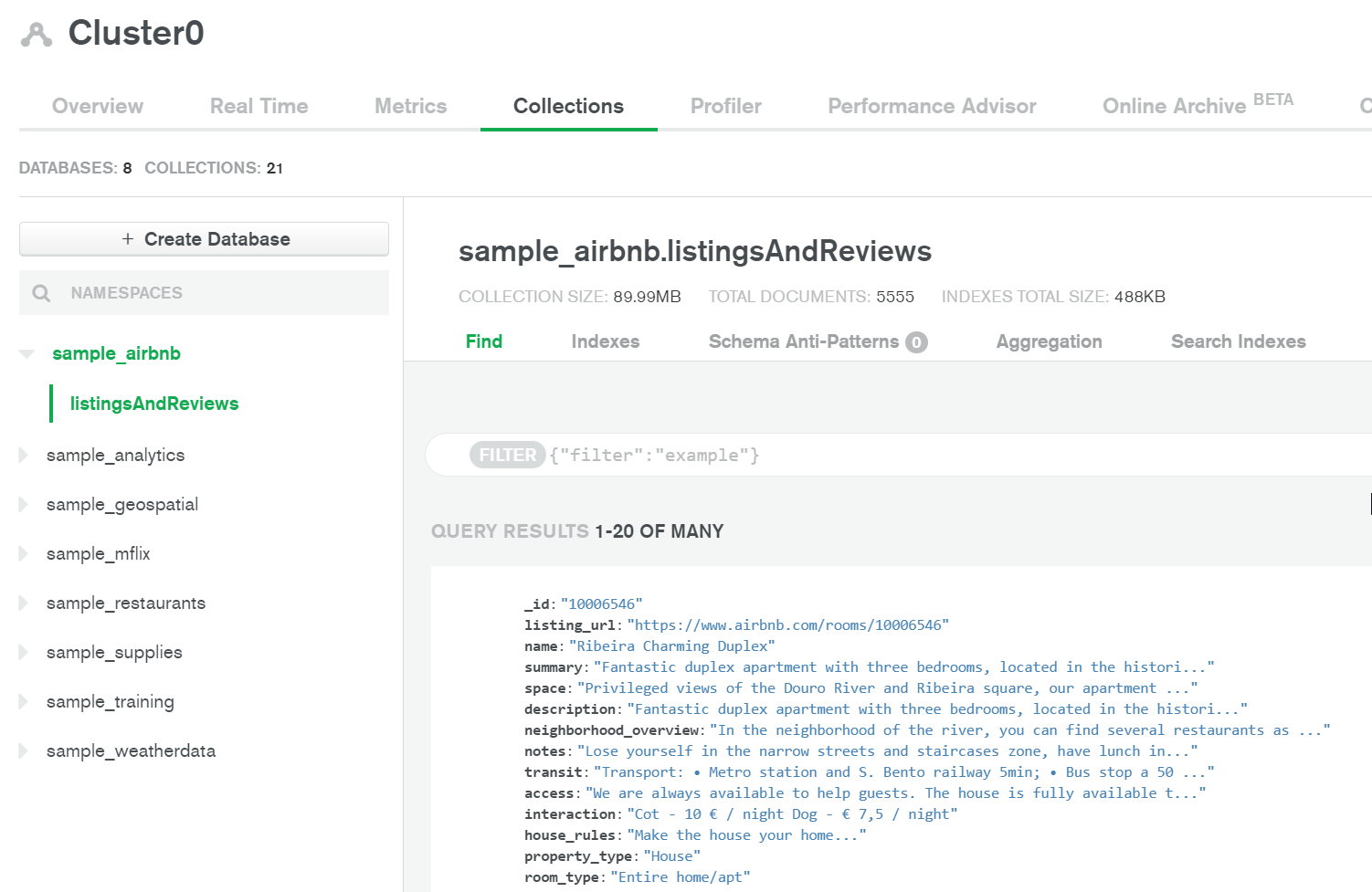
Clusterを選択してCollectionsを選択するとデータが確認できます。
クレジットカードの登録
今回は BI Connectorを使うのが目的です。BI Connectorはそれ自体が有料です。さらに利用には有料版のクラスタ(M10以上)が必要です。
有料版を使うため、クレジットカードを登録します。
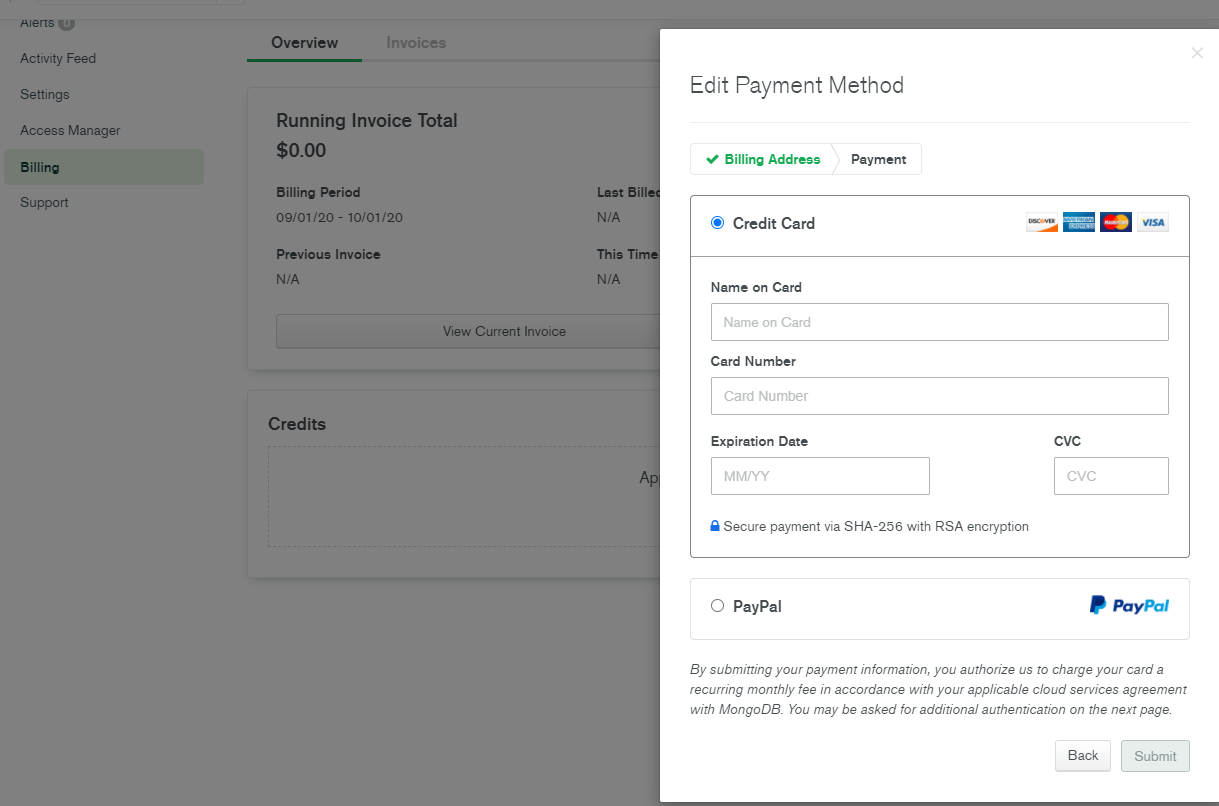
有料版クラスタの作成
クラスター作成画面より、有料のM10を選択してみます。
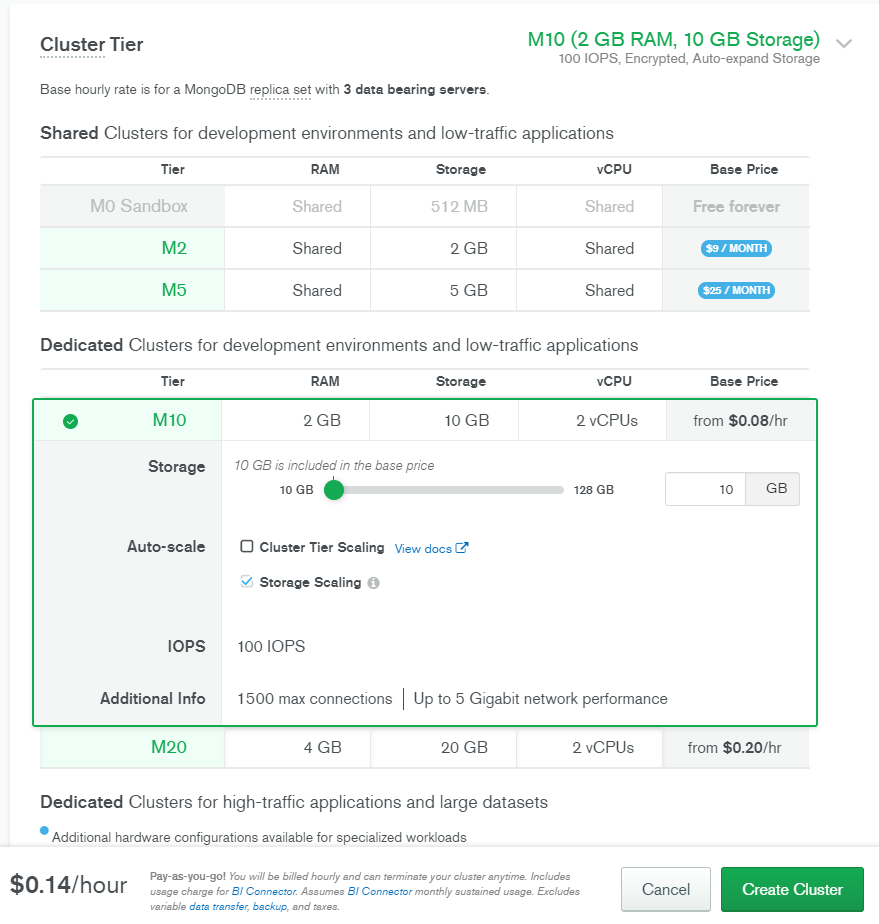
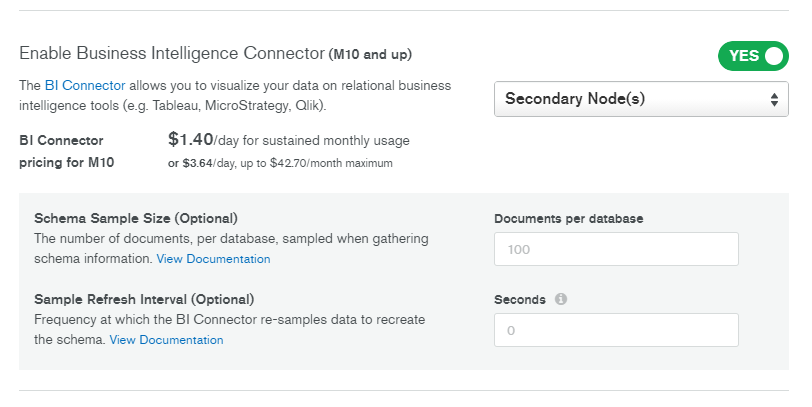
Atlas BI Connector の有効化
下にスクロールし、「Advanced Settings」からBI コネクタを有効化してみます。
あまり課金ロジックを理解していませんが、数日間利用したところ、1日あたり $3.64 かかっていました。おそらくBIコネクタを有効化している日数ではなく、使用した日の日数分だけ課金されているような気がします。実際にコネクションを張らなかった日は課金されていないように思えました。
作成後は、この有料版クラスタにもサンプルデータを読み込ませておきます(省略します)
接続文字列の確認
Atlas BI Connectorは通常のクラスタ接続先と異なるようです。
Atlas BI Connectorの接続文字列を見てみます。
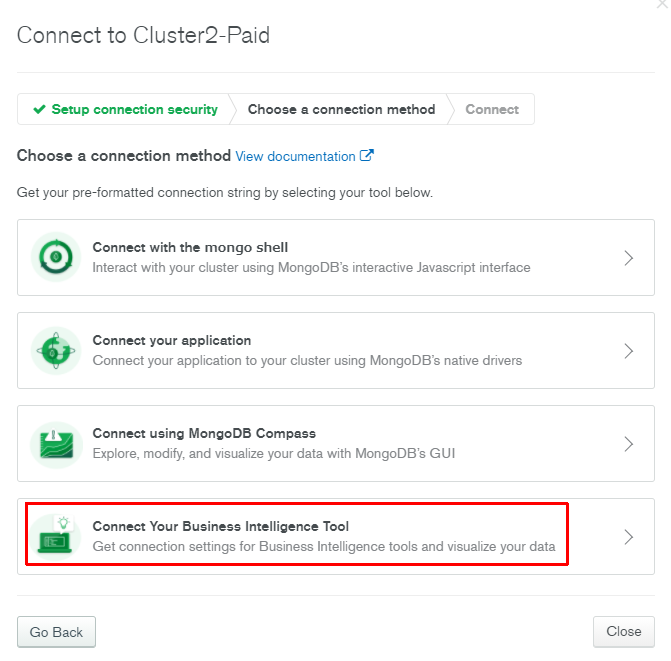
ホスト名に「biconnector」という文字列が追加されていますね。それぞれコピーしておきます。
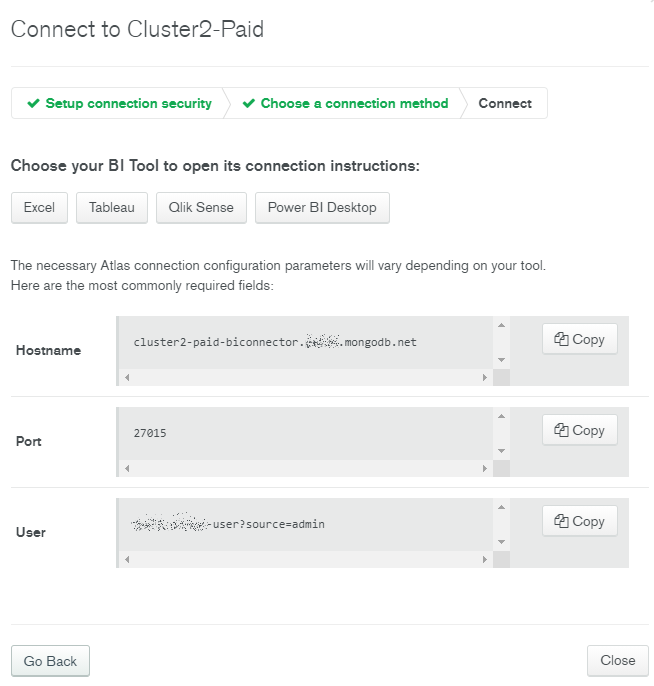
VPC ピアリング
主目的ではありませんが、AWSとのピアリングも試しておきます。

AWSのアカウントID、VPC ID、とそのCIDRを指定します。Atlas側のCIDRは自動入力されていました。
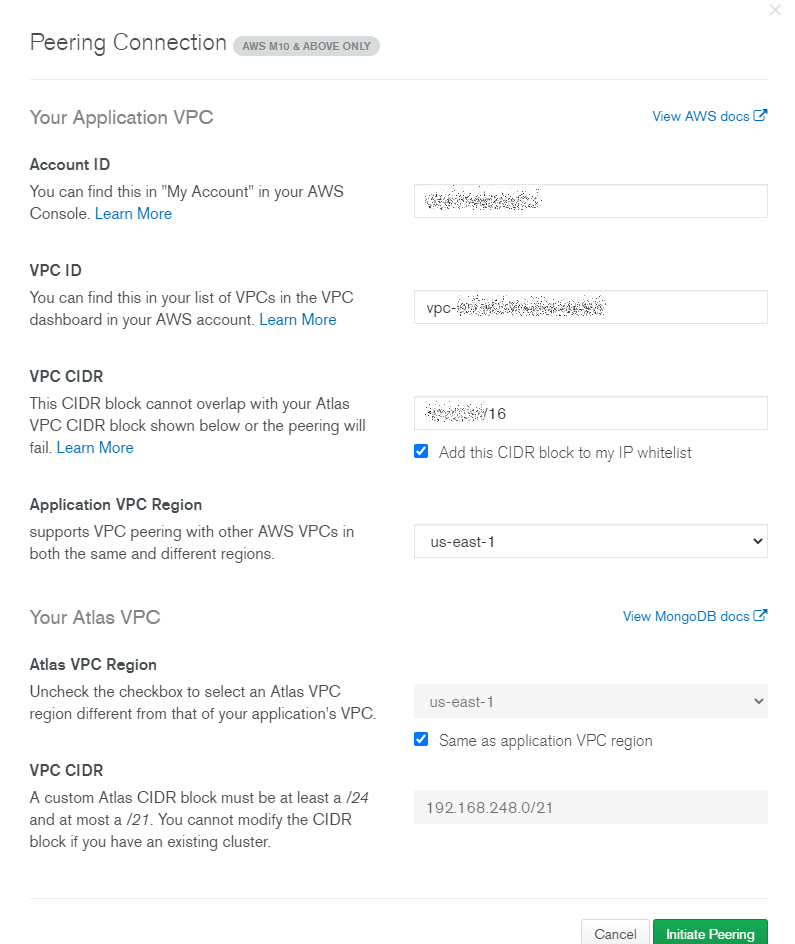
AWS側にピアリング申請がきているので承認しておきます。
接続したいサブネットのルートテーブルにもVPCピアリングを通しておきます。先程確認したAtlas側のCIDRをいれます。

VPC側でDNSホスト名とDNS解決が有効になっていることを確認します。

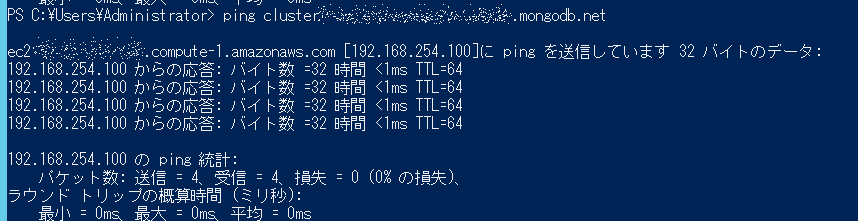
AWS側からクラスタのドメイン名にpingを通すと、プライベートIPで応答が帰ってきます。
TableauからMongoDB Atlasへ接続
AWSのEC2上にインストールしてあるTableau Desktopから操作します。
tableauからMongoDB BIコネクターを選択すると、まずはドライバダウンロードを求められます。
リンクをクリックするとブラウザが開きます。Windows用のmysql odbcドライバ「mysql-connector-odbc-8.0.21-winx64.msi」を落とします。
インストールしようとすると「this application requires visual studio 2019 x64 redistributable」と警告が出たため、「VC_redist.x64.exe」をインストールし再起動します。再起動したらmysql odbcドライバを改めて入れ(たような気がし)ます。
https://support.microsoft.com/ja-jp/help/2977003/the-latest-supported-visual-c-downloads
tableauから接続してみます。
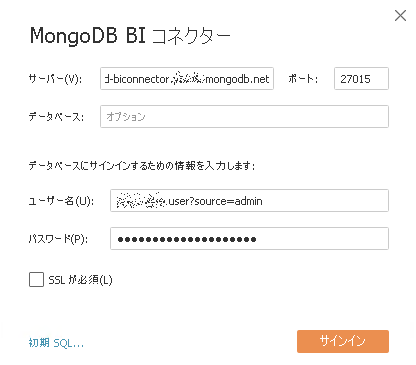
接続は成功するも、システムDBしか見えません。
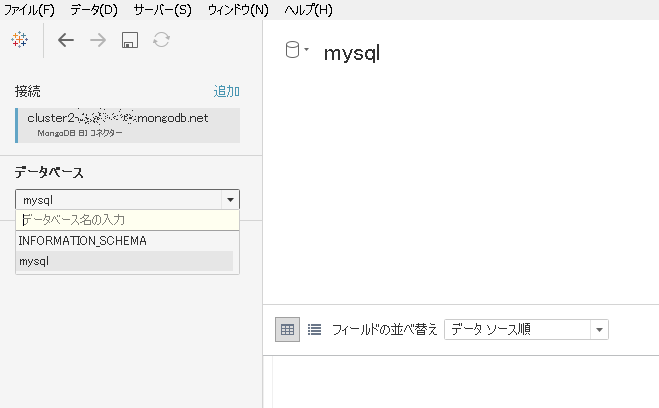
MongoDB Atlasのほうで、接続用ユーザの権限を「Read and write to any database」から「Atlas admin」に変更してみます。
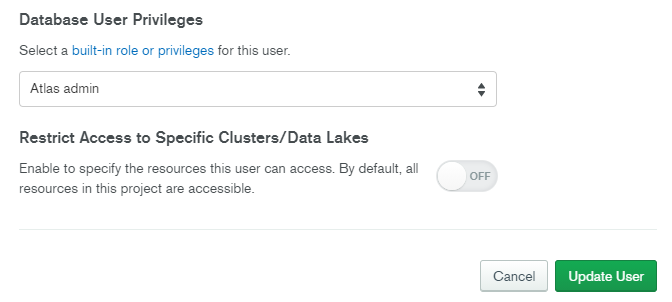
反映まで念のため数分待ち、再度接続してみます。今度はデータベース名も指定します。
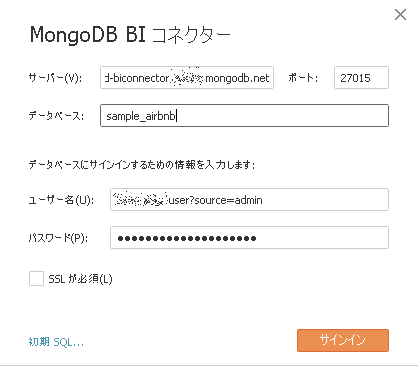
正常に接続でき、データベースや表もちゃんと見えました。
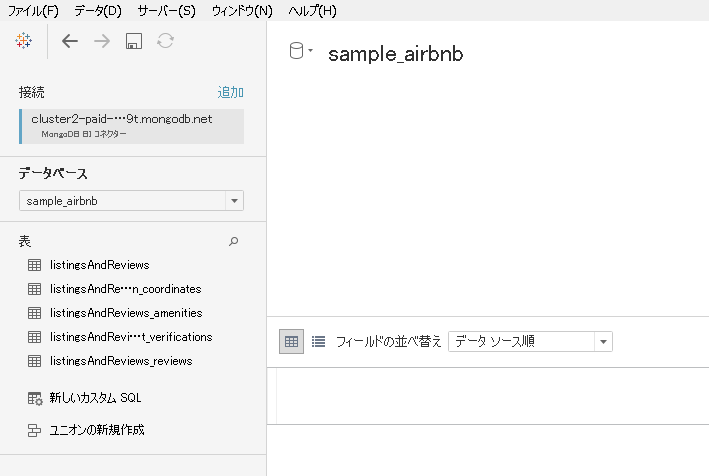
BI Connectorでどのように見えるか確認する
テーブル構造の確認
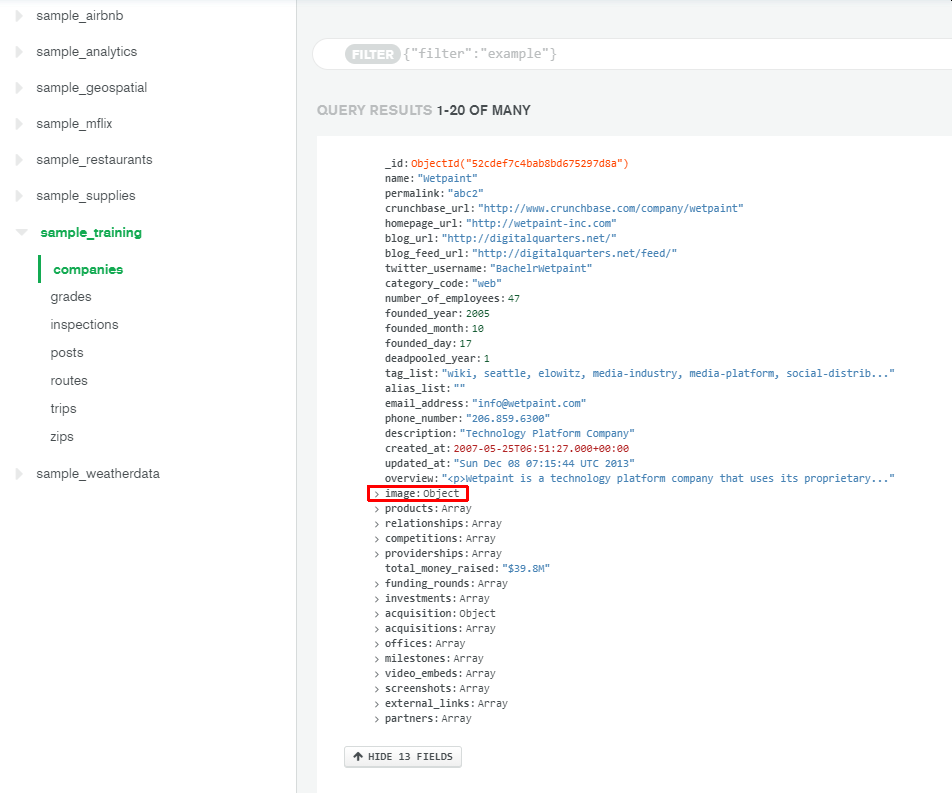
"sample_training"データベースの"companies"コレクションの1データをMongoDB Atlasから見てみます。
以下のような構造をしています。例として image は Object型になっていることが確認できます。
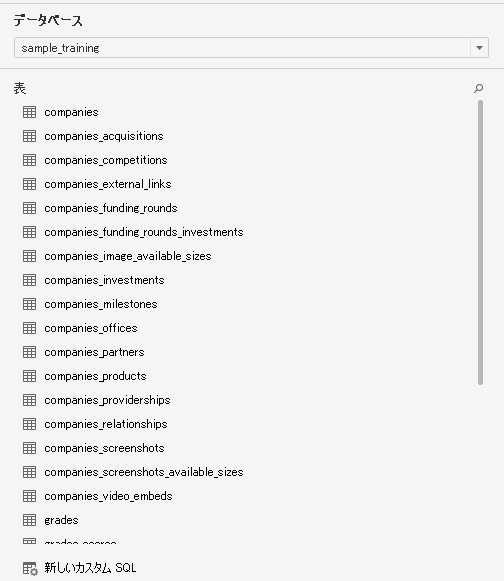
tableauからみると、companiesコレクションはオブジェクト単位で分離していることがわかります。
オブジェクトのネストはアンダーバーで表現されています。
imageの実際のJSONデータを抜粋します。
$numberIntで型定義されている配列と、ファイルパスの文字列というデータになっています。
"image": {
"available_sizes": [
[
[
{
"$numberInt": "150"
},
{
"$numberInt": "75"
}
],
"assets/images/resized/0000/3604/3604v14-max-150x150.jpg"
],
[
[
{
"$numberInt": "250"
},
{
"$numberInt": "125"
}
],
"assets/images/resized/0000/3604/3604v14-max-250x250.jpg"
],
上記のような構造のデータは、tableau側ではこうなります。
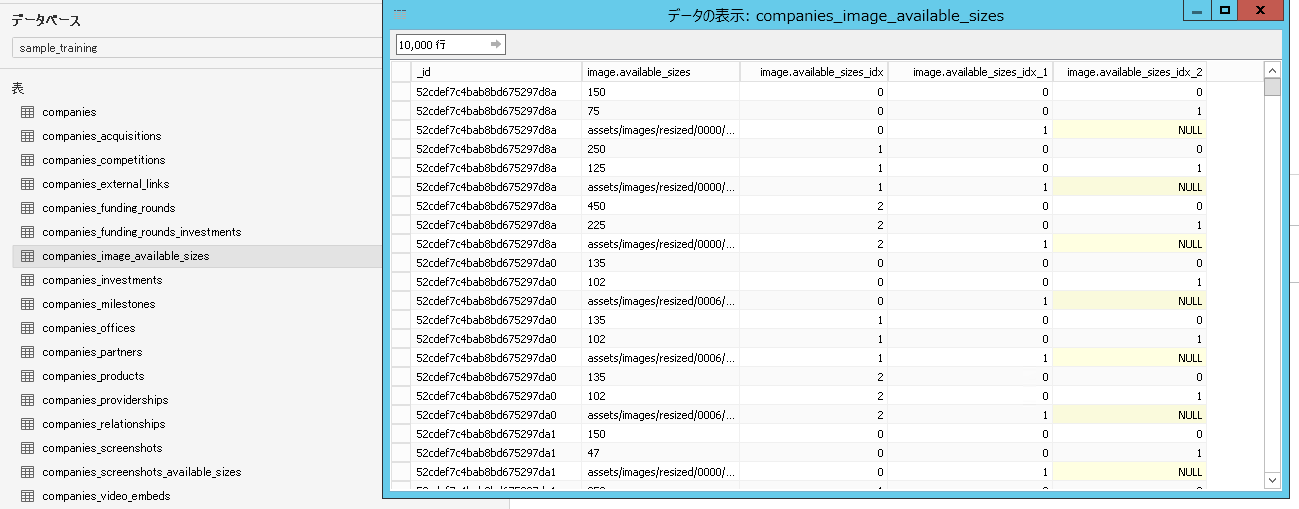
今度はオブジェクトのネストが2階層になっているテーブルの元データを見てみます。
"funding_rounds": [
{
"id": {
"$numberInt": "888"
},
"round_code": "a",
"source_url": "http://seattlepi.nwsource.com/business/246734_wiki02.html",
"source_description": "",
"raised_amount": {
"$numberInt": "5250000"
},
"raised_currency_code": "USD",
"funded_year": {
"$numberInt": "2005"
},
"funded_month": {
"$numberInt": "10"
},
"funded_day": {
"$numberInt": "1"
},
"investments": [
{
"company": null,
"financial_org": {
"name": "Frazier Technology Ventures",
"permalink": "frazier-technology-ventures"
},
"person": null
},
{
"company": null,
"financial_org": {
"name": "Trinity Ventures",
"permalink": "trinity-ventures"
},
"person": null
}
]
},
1階層目。自テーブルのidxカラムが自動追加されています。
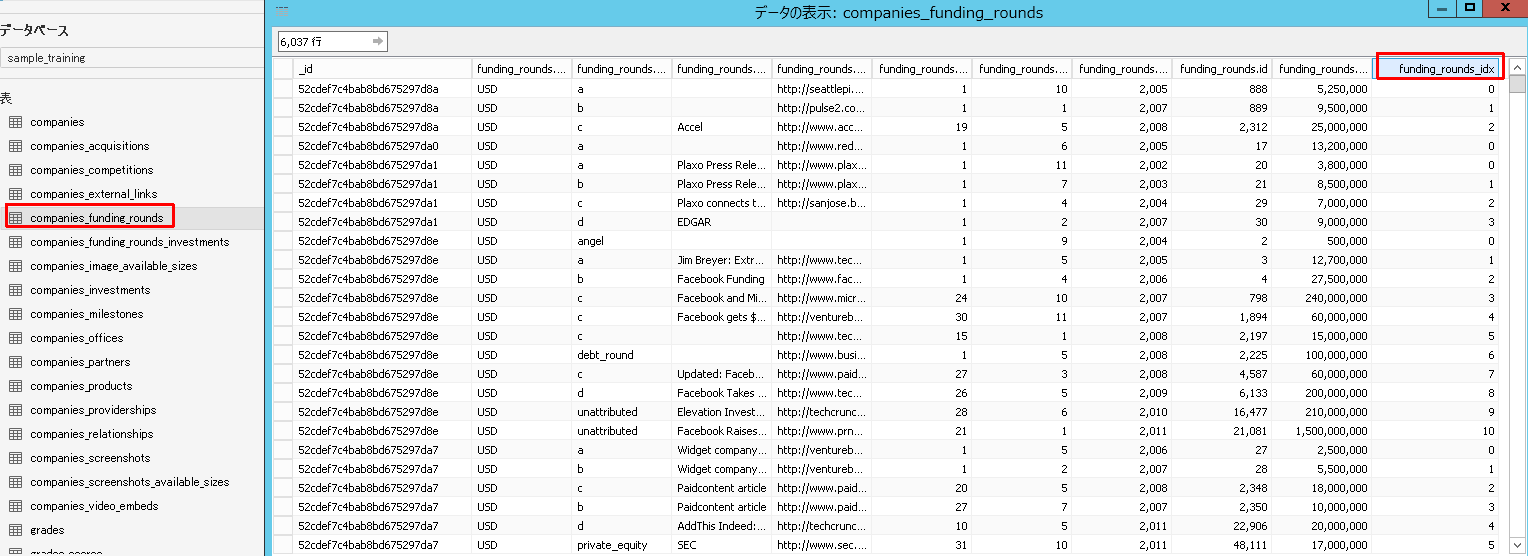
2階層目。自テーブルのidxカラムと、親テーブルのidxカラムが自動追加されています。このidxカラムの組み合わせにより、データを一意的に識別できるようになっています。
Tableauのシートに表示してみる
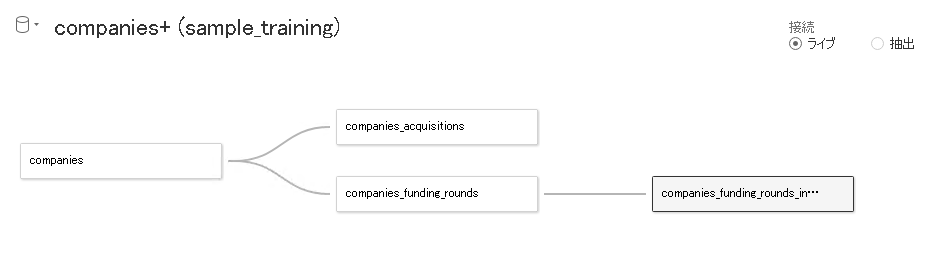
Tableauのデータソースから、2階層にネストしたテーブルをリレーションシップで組み合わせてみます。
まずはrootの companies と companies_acquisitionsをドラッグアンドドロップします。
同名のカラムがあるため、カラム指定せずに自動で紐付けてくれます。

rootの companies と companies_funding_roundsも同じように自動紐付けされます。

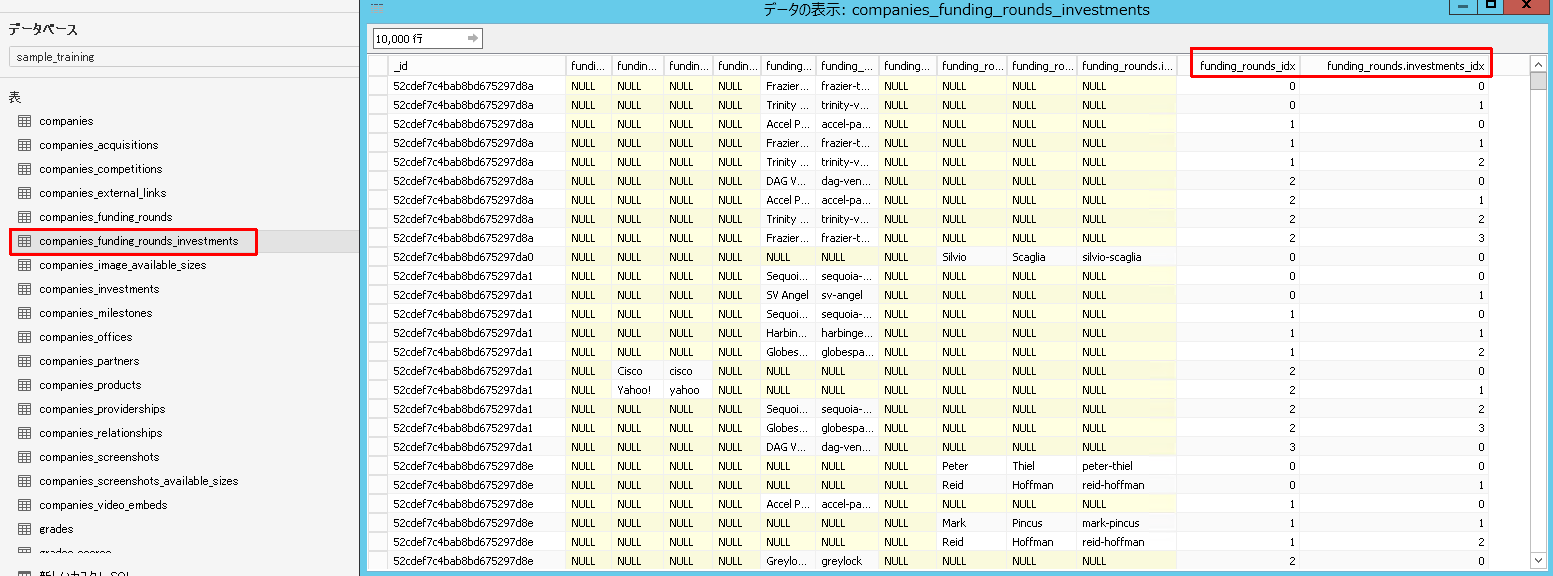
companies_funding_rounds と companies_funding_rounds_investmentsは自動紐付けされないようです。同名カラムが複数ある(_IdとFunding Rounds Idx)からですかね?

手動で子にとっての親を指すインデックスカラム(Funding Rounds Idx)を選択します。
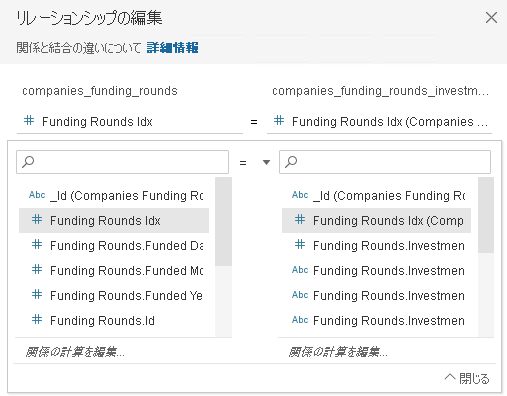
リレーションシップができました。
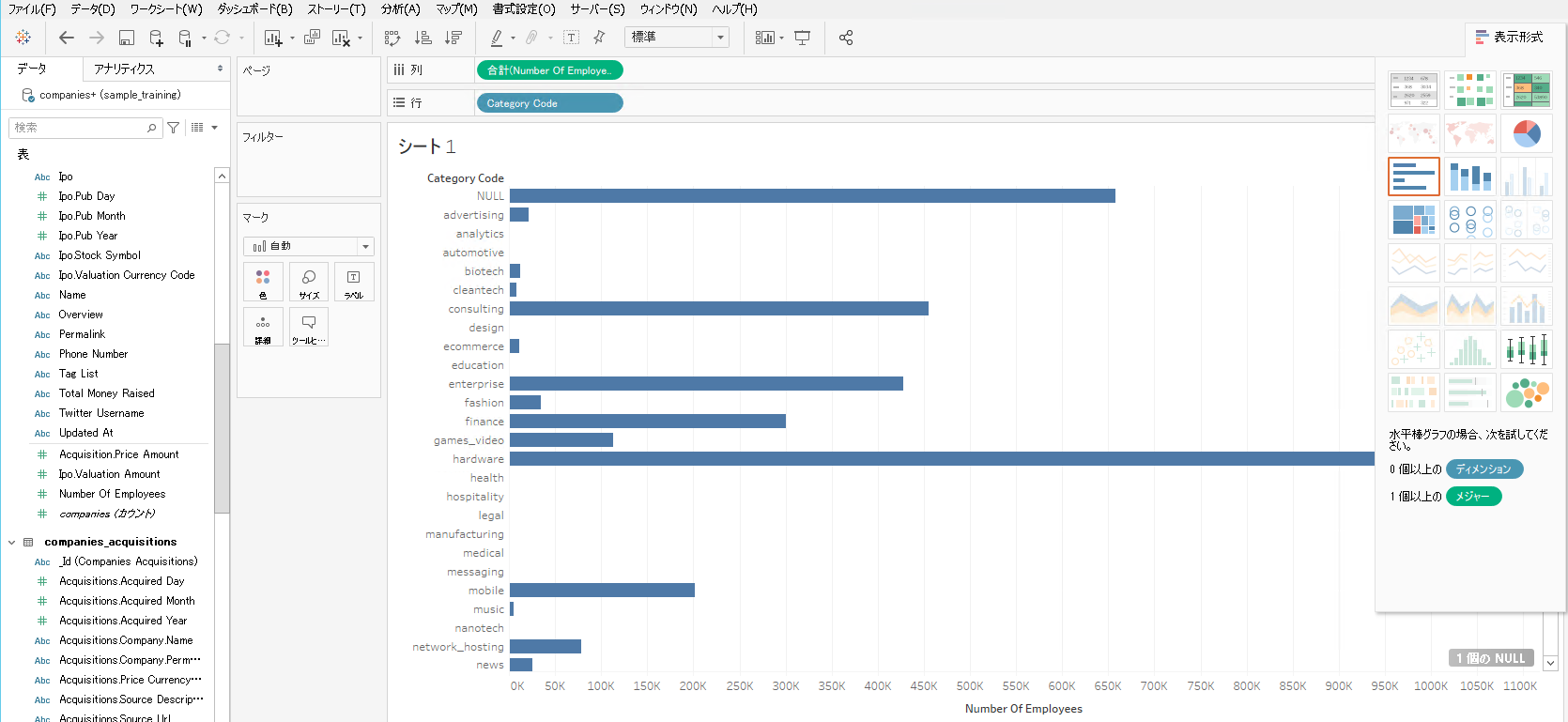
シートに移ります。
業種カテゴリと従業員数でグラフを作ってみました。
所感
- オブジェクト単位でテーブルが分割されるものの、自動で追加されるインデックスカラムによって結びつけができるという点は便利です。ドキュメントDBを表現するにはこういうアプローチしかなさそうですし。
- ただ元データ側は、やはりドキュメント指向なためか文字列型が多く、Tableauで分析するにはメジャーが少ない印象です。
- このサンプルデータはキレイなのでなんとか棒グラフを作ることはできましたが、データによってはTableauの「テキスト表」でしか表現できないケースもあるようです。
- データ入力時のバリデーションはアプリの正常動作に必要不可欠な機能だったりしますが、ことドキュメント指向DBに関していえば、BIで分析するためにも重要な機能であると思いました。厳密なバリデーションをかければBIはしやすくなりますが、アプリの柔軟性が落ちます。特定のサブスキーマだけ柔軟性を持たせたいというような場合はどうすればいいのでしょうか。。
- [2020.10.16追記]IIJさんの以下のブログが、あいまいな構造のデータを扱う場合に非常に参考になります。
- https://eng-blog.iij.ad.jp/archives/6813
- JSON Schemaなど各種のSchema Validationの得手不得手や、サブスキーマの検索手法(速さ)も含め比較されています。
- JTD(JSON Type Definition)がよさそうですがRFC標準化前の状態のようですね。
* IETFの読み込みを重視しているという文化も含めて、さすがの記事です。
- JTD(JSON Type Definition)がよさそうですがRFC標準化前の状態のようですね。
- ですのでtableauで表示をするまえに、どのような分析をしたいか、その分析をするためにどのようなデータ型で定義するか、を検討すべきであるという当たり前の事実を再確認しました。
- データパイプラインの後工程(TableauやTableau Prep)で吸収するという手もあるかもしれませんが、あまり試していません。
- 必要であれば事前にETL処理などを行うべきですし、ETLを行えば何もBIツールから直接ドキュメント指向データベースに接続する必要もない気がします。
おまけ(TableauからAmazon DocumentDBへの接続試行など)
直接アプローチ
Tableauの「MongoDB BI Connector」からAmazon DocumentDBへの接続
ダメ元でやってみたらやはりだめでした。
Tableauの「MongoDB BI Connector」は、Tableau側に DocumentDBのマッピング機能があるわけではなく、あくまで接続機能でしかないようです。マッピング機能は MongoDB側の BI Connector(Atlas BI Connector)にあります。
接続先のサーバをDocumentDBにしてみると、
エラーになります。
Tableauのカスタムコネクタ(JDBC/ODBC)の利用
-
有償コネクタ(未検証)
-
MongoDBへのコネクタは世間にいろいろありますが、試していません。
-
無償コネクタ
-
以下のようなものを見つけてGradleでビルドし、JDBCドライバを作り、TDCファイルを置いてみたりしましたが接続できず諦めました。
ODBCドライバから Atlas BI Connectorへ接続
DocumentDBへのアクセスではなくMongoDB Atlasへの接続です。これはうまくいきました。接続後、Collectionは検索しないと表示されませんでしたが、それ以外は問題なし。
機能的にはMongoDB側のAtlas BI Connectorがあればクライアント側の機能はさほど問われないということなんでしょう。
WindowsにODBCドライバをインストールし、
https://github.com/mongodb/mongo-odbc-driver/releases/
mongodb-connector-odbc-1.4.2-win-64-bit.msi
Windowsの標準機能からODBCドライバを作ります。
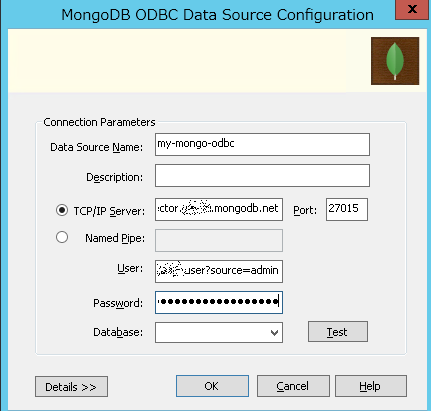
tableauからはODBCで接続できます。
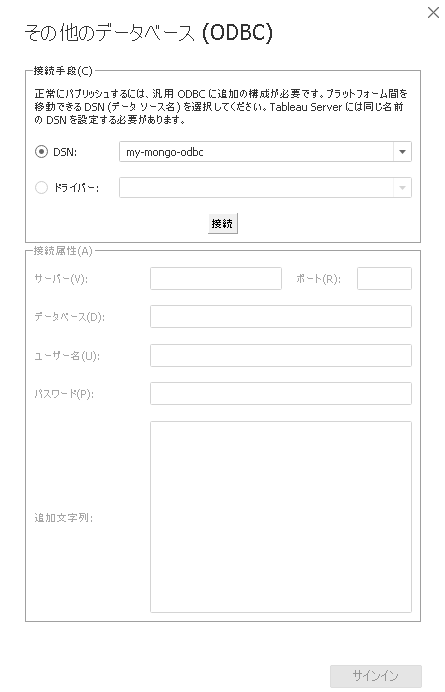
PowerBIからはODBCを指定して、
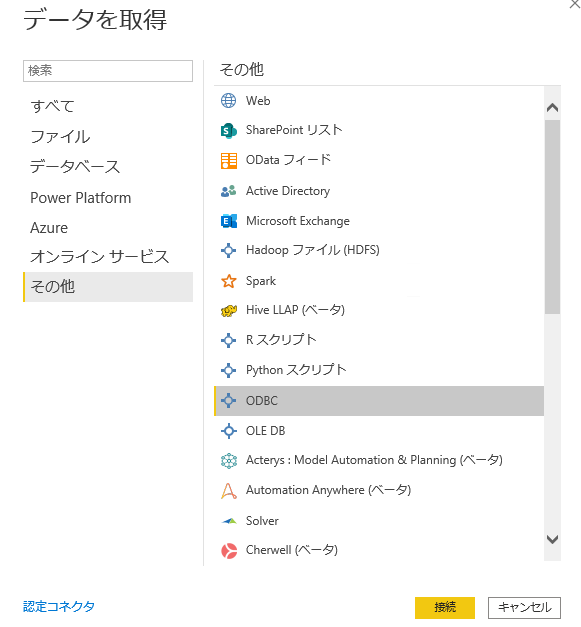
さきほどのコネクタを指定し、

改めてユーザ名とパスワードをいれると、
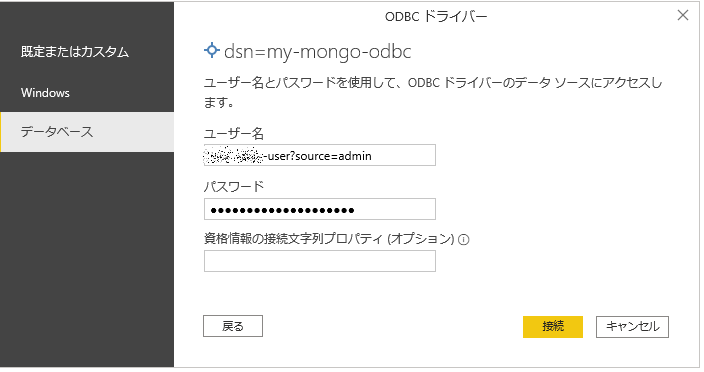
接続ができました。
ODBCドライバから DocumentDBへ接続
MongoDBのODBCドライバの接続先をDocumentDBに変え、Tableauからそれを指定し接続してみましたが、接続できずテスト接続でフリーズしました。アクセス元がBIツールなので仕方ないです。これができればAtlas BI Connectorの存在理由はありませんし。
間接アプローチ
Athenaを経由しAmazon DocumentDBへの接続
AthenaはDocumentDBへの接続機能があるようなので、Athenaを経由すればTableauから見えないか?という案
そもそもTableau側のAthenaコネクタがS3しか想定しない作りになっているので、NG。
Tableauからはだめそうですが、AthenaのFederated Queryそのものについては別の機会で記事にしてみようと思います。
GlueジョブでDocumentDBにETL処理を行うパターン
詳細は省きますが、DocumentDBへの接続はできました。以下のようなデータが、
{
"_id": "01001",
"city": "AGAWAM",
"loc": [
-72.622739,
42.070206
],
"pop": 15338,
"state": "MA"
}
GlueのDynamicFrameによって以下のように型認識されています。
|-- _id: string
|-- city: string
|-- loc: array
| |-- element: double
|-- pop: int
|-- state: string
型はちゃんと認識できているので、ETL処理を行うことはできると思います。
以上です。