はじめに
非情報系大学院生が一から機械学習を勉強してみました。勉強したことを記録として残すために記事に書きます。
進め方はやりながら決めますがとりあえずは有名な「ゼロから作るDeep-Learning」をなぞりながら基礎から徐々にステップアップしていこうと思います。環境はGoogle Colabで動かしていきます。最終回である第8回はリカレントニューラルネットワーク(RNN)についてです。
目次
- リカレントニューラルネットワークとは
- LSTM
- LSTMの実装
- あとがき
1. リカレントニューラルネットワークとは
再帰型ニューラルネットワーク(RNN: Recurrent Neural Network)は内部にフィードバック構造を持ったニューラルネットワークで(時)系列データの処理に向いています。前回までのMLP、CNNではMNIST手書き数字を例にした画像認識の学習を行ってきました。それとは異なり今回は音声や言語、動画像といった系列データ、例えば文章を例に挙げると、ある文章内で単語の並びはこれまでの単語の並びに強く影響を受けると考えられます。このような$t$番目の単語まで与えられたとき$t+1$番目の単語を予測することを目指します。RNNはこのような文脈をうまく学習し、単語の予測を行うことができ、言語モデルとも呼ばれます。
RNNの構造
RNNの構想は下図のような順伝播型ネットワークと同様の構造を持ち、ただし中間層出力が自分自身に戻されるフィードバック回路を持つと考えることができます。
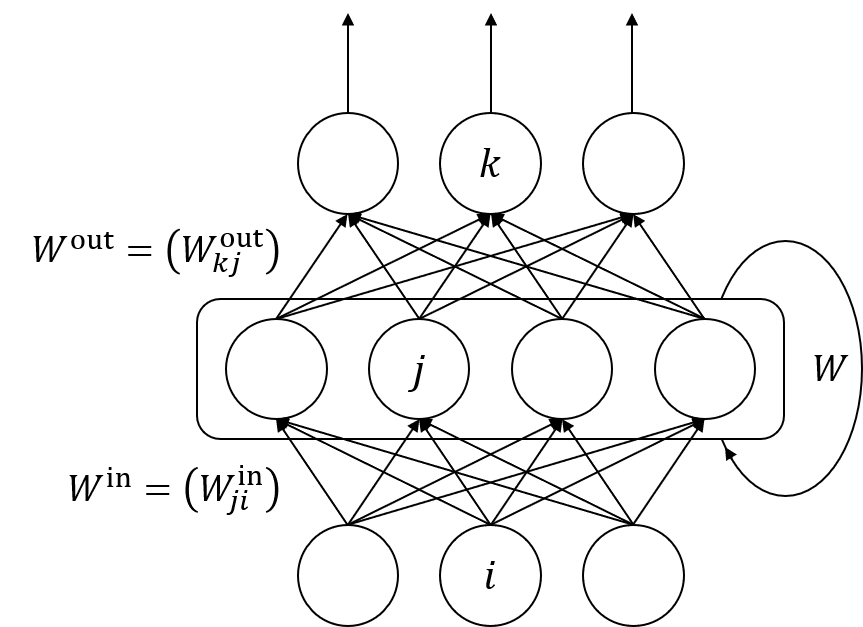
このRNNは各時刻$t$につき一つの入力$x^t$を受け取り、出力$y^t$を返します。その際ネットワーク内部のフィードバック回路によって過去に受け取ったすべての入力を考慮します。順伝播型が入力1つに対し出力1つを返したのに対し、RNNは理論上過去のすべての入力から1つの出力を返します。
RNNは下図のように時間方向に展開して表現することができます。こうすることでフィードバックの各層が全く別々に存在するかのように見なせます。つまりRNNは2層であってもDeep learningができることになります。
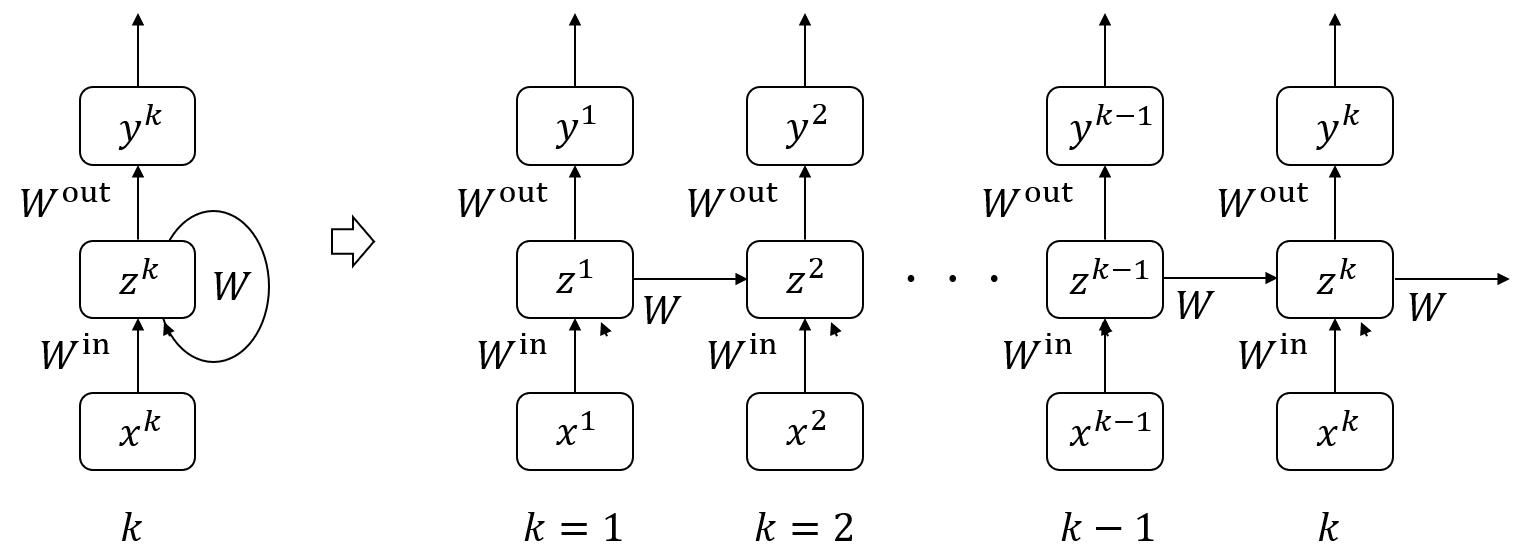
2. LSTM
前章で述べたようにRNNは理論的には過去の全ての入力が考慮されます。しかし実際は高々過去の10時刻分程度だと言われています。これは第6回で述べた勾配消失問題と同様です。層数の多い深いネットワークでは層の計算を行うと勾配は爆発的に大きくなるか0に消滅してしまいやすい性質があります。RNNは時間方向に展開すると深い順伝播ネットワークに置き換えられます。よってRNNは元々の層数は少なくても、深い層を扱っているのと同等になり勾配消失問題が発生してしまいます。よって基本的なRNNでは短期な記憶は実現できても、より長期の記憶を実現するのは難しいと言えます。
この問題を踏まえ、長期の記憶を実現できるようにしたのがLSTM(Long Short-Term Memory)です。LTSMは単純にフィードバックするだけでなく、下図のようにいくつかのゲートを挟んでフィードバックを行います。
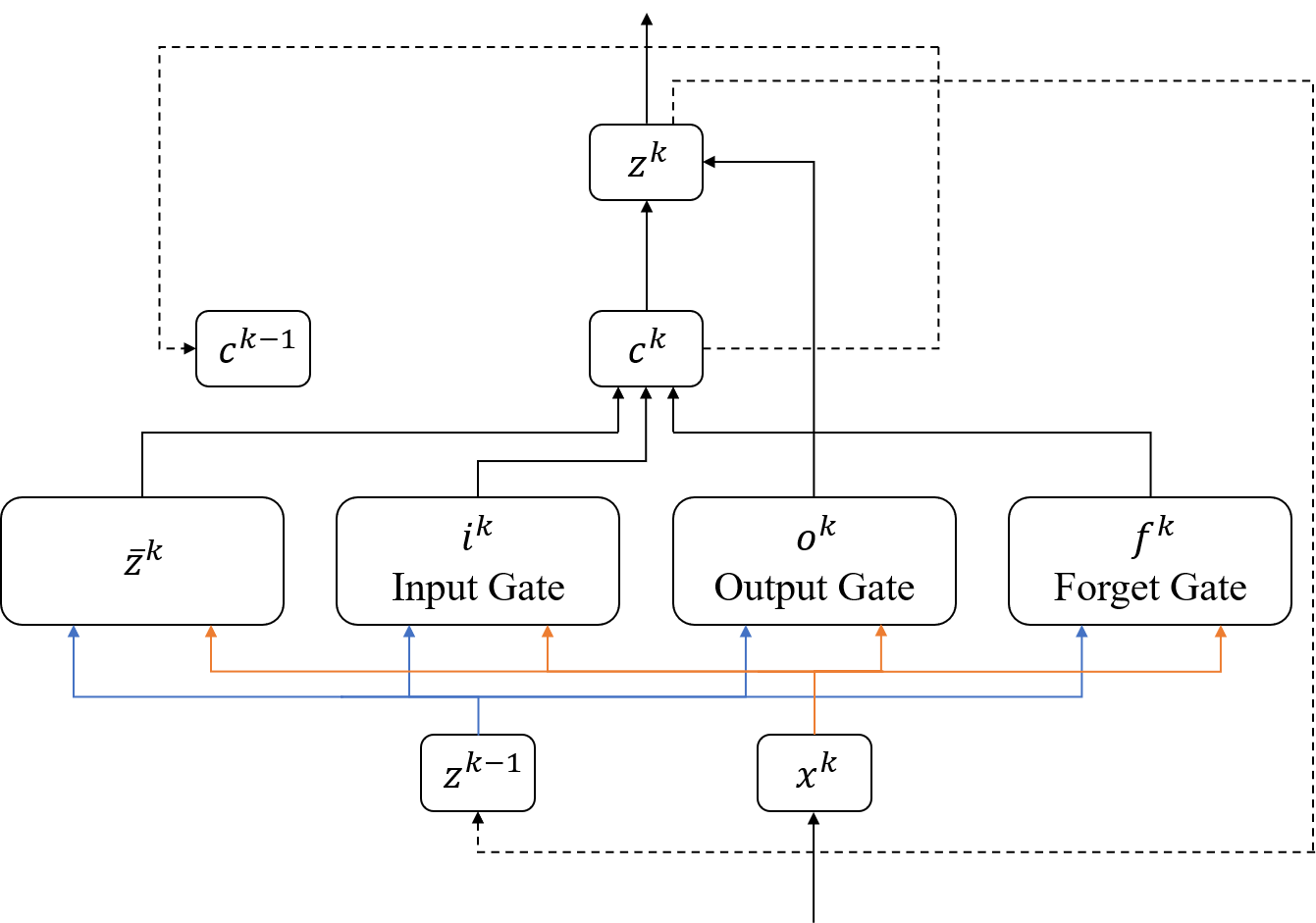
状態量$c^k$は階層型RNNと同じである$\bar{z}^k$と入力ゲート出力$i^k$、忘却ゲート出力$f^k$からなります。入力ゲートで入力された短期の情報の影響を調整し、忘却ゲートで長期の記憶の影響を調整して$c^k$を更新します。最後に$c^k$を出力ゲートで調整して出力$z^k$を決定します。
3. LSTMの実装
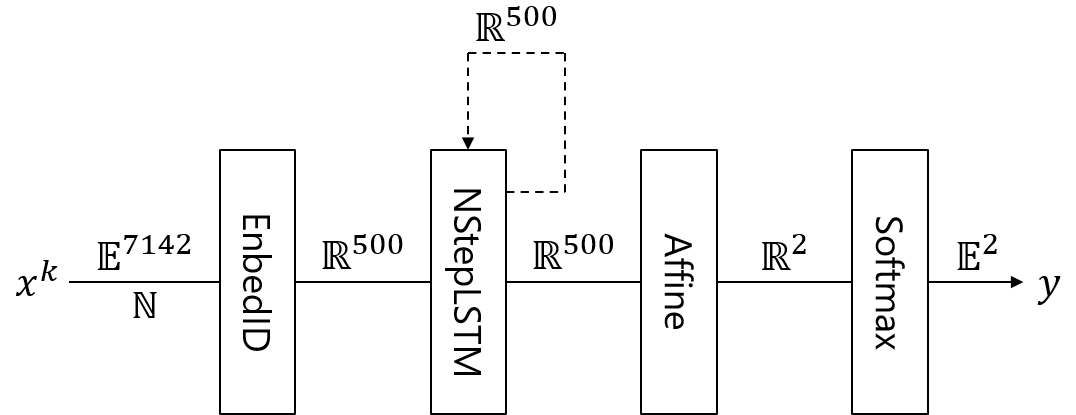
以上を踏まえて実装を行います。今回はChainerを使用して映画のレビューテキストから感情を推定する下図のようなネットワークを実装します。
Chainer、訓練データ、必要なモジュールをインストールします。
!wget https://raw.githubusercontent.com/chainer/chainer/master/examples/text_classification/README.md
!wget https://raw.githubusercontent.com/chainer/chainer/master/examples/text_classification/nets.py
!wget https://raw.githubusercontent.com/chainer/chainer/master/examples/text_classification/nlp_utils.py
!wget https://raw.githubusercontent.com/chainer/chainer/master/examples/text_classification/run_text_classifier.py
!wget https://raw.githubusercontent.com/chainer/chainer/master/examples/text_classification/text_datasets.py
!wget https://raw.githubusercontent.com/chainer/chainer/master/examples/text_classification/train_text_classifier.py
!wget https://raw.githubusercontent.com/harvardnlp/sent-conv-torch/master/data/stsa.binary.train
import random
import numpy as np
import chainer
from chainer import Variable
from chainer import functions as F
from chainer import links as L
import matplotlib.pyplot as plt
続いてデータセットを準備します。
import text_datasets
# Set dataset
dataset = "stsa.binary"
# Read dataset
if dataset == 'dbpedia':
train, test, vocab = text_datasets.get_dbpedia()
elif dataset.startswith('imdb.'):
train, test, vocab = text_datasets.get_imdb(fine_grained=dataset.endswith('.fine'))
elif dataset in ['TREC', 'stsa.binary', 'stsa.fine', 'custrev', 'mpqa', 'rt-polarity', 'subj']:
train, test, vocab = text_datasets.get_other_text_dataset(dataset)
# Show dataset information
print('# train data: {}'.format(len(train))) # train data: 6920
print('# test data: {}'.format(len(test))) # test data: 1821
print('# vocab: {}'.format(len(vocab))) # vocab: 7142
n_class = len(set([int(d[1]) for d in train]))
print('# class: {}'.format(n_class)) # class: 2
確認したように訓練データ数は6920、テストデータは1821です。単語は無数に存在するので学習に使用する単語数をあらかじめ絞っておきます。今回は7142語を使用します。出力は感情がpositive(1)、negetive(0)の2値です。
具体的に中身を確認してみます。
# Read source data
f = open("stsa.binary.train", "r")
lines = f.readlines()
# Target line number
n = 100
# Print source sentence
print(lines[n])
# Show numerical train data and corresponding words
for v_ in train[n][0]:
for k, v in vocab.items():
if v_ == v:
print(str(v) + " : " + k)
# Print sentiment data
print("Sentiment: " + str(train[n][1][0]))
# =========以下出力=========
# 0 you can taste it , but there 's no fizz .
# 23 : you
# 70 : can
# 781 : taste
# 11 : it
# 4 : ,
# 17 : but
# 53 : there
# 10 : 's
# 64 : no
# 3163 : fizz
# 2 : .
# 0 : <eos>
# Sentiment: 0
このようにtrain内には文章が格納されており、train[n][0]にはn番目文章のそれぞれの単語の番号、train[n][1]にはn番目文章のそれぞれの感情が格納されています。
ここから具体的なネットワークの構成に入ります。基本的に前回のCNN実装と同じです。まずモデルを定義します。
N_in = len(vocab) # vocabulary size
N_i = 500 # input dimension
N_l = 1 # LSTM layers
N_h = 500 # state dimension
dropout = 0.5 # dropout rate
N_out = 2 # output size
class LSTM(chainer.Chain):
# Constructor
def __init__(self, N_in, N_i, N_l, N_h, dropout, N_out, initializer = None):
super().__init__(
layer1 = L.EmbedID(N_in, N_i, initialW = initializer),
layer2 = L.NStepLSTM(N_l, N_i, N_h, dropout),
layer3 = L.Linear(N_h, N_out, initialW = initializer),
)
# Forward operation
def __call__(self, x, t = None):
z1 = [self.layer1(item) for item in x] # EmbedID
h, c, y = self.layer2(None, None, z1) # LSTM
a3 = self.layer3(h[-1]) # Affine
if chainer.config.train:
return F.softmax_cross_entropy(a3, t) # Softmax3 with cross entropy error, training
else:
return F.softmax(a3) # Softmax3, evaluation
EmbedID(入力サイズ, 出力サイズ, 初期重み, 無視する列)は訓練データを表したいものに割り振った次元のみ1、その他を0にしたone-hot-vector表現の処理に特化した層で、計算はAffine layerと同じです。
NStepLTSM(LSTMレイヤ数, 入力ベクトル次元, 出力ベクトル、内部状態次元数, ドロップアウトレート)は可変長の入力を受け付けることができるLSTM layerです。さきほど訓練データ内部を見てみたように文章の長さはそれぞれ異なるので可変である必要があります。前向き演算の際は引数が(初期内部状態変数, 初期メモリセル状態変数, 入力変数)となります。第1、2変数がNoneのときゼロベクトルが指定され、通常はNoneで問題ないそうです。
あとは前回のCNNと同様にGPU定義、学習と評価を行います。CNNのときとほぼ同じなので説明は省きます。
# GPUの設定
gpu_device = 0
chainer.cuda.get_device(gpu_device).use()
# モデル定義
model = LSTM(N_in, N_i, N_l, N_h, dropout, N_out, initializer = chainer.initializers.HeNormal())
# GPU転送
model.to_gpu(gpu_device)
# 最適化エンジン設定
optimizer = chainer.optimizers.Adam()
optimizer.use_cleargrads()
optimizer.setup(model)
# Set parameters and initialiation
iters_num = 5000
train_size = len(train)
test_size = len(test)
batch_size = 100
iter_per_epoch = int(max(train_size / batch_size, 1))
train_acc_list = []
test_acc_list = []
# Training and evaluation
for i in range(iters_num):
# Set mini-batch
batch_list = random.sample(train, batch_size)
x_batch = [batch_list[j][0] for j in range(len(batch_list))]
t_batch = np.array([batch_list[j][1] for j in range(len(batch_list))]).flatten()
x_batch = chainer.cuda.to_gpu(x_batch, device = gpu_device)
t_batch = chainer.cuda.to_gpu(t_batch, device = gpu_device)
# Forward operation
loss = model(x_batch, t_batch)
# Backward operation
model.cleargrads()
loss.backward()
# Update parameters
optimizer.update()
# Evaluation
if i % iter_per_epoch == 0 or i == iters_num - 1:
# Turn training flag off
chainer.config.train = False
# Evaluate training set
y_train = []
for s in range(0, train_size, batch_size):
train_batch = train[s:s + batch_size]
x_batch = [train_batch[j][0] for j in range(len(train_batch))]
x_batch = chainer.cuda.to_gpu(x_batch, device = gpu_device)
y_train.extend(chainer.cuda.to_cpu(model(x_batch).data).tolist())
# Evaluate test set
y_test = []
for s in range(0, test_size, batch_size):
test_batch = test[s:s + batch_size]
x_batch = [test_batch[j][0] for j in range(len(test_batch))]
x_batch = chainer.cuda.to_gpu(x_batch, device = gpu_device)
y_test.extend(chainer.cuda.to_cpu(model(x_batch).data).tolist())
# Compute accuracy
t_train = np.array([train[j][1] for j in range(len(train))]).flatten()
t_test = np.array([test[j][1] for j in range(len(test))]).flatten()
train_acc = F.accuracy(np.array(y_train), t_train).data
test_acc = F.accuracy(np.array(y_test), t_test).data
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
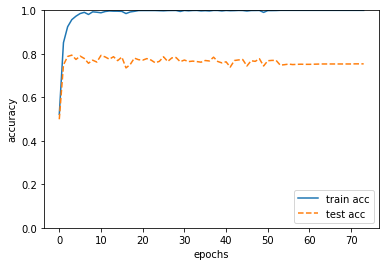
print(i, train_acc, test_acc) # 4999 1.0 0.7732015376166941
# Turn training flag on
chainer.config.train = True
# Plot figure
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc')
plt.plot(x, test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
その結果以下のようなグラフがプロットされ、約77%の正答率で文章から感情を認識できるようになりました。(8割弱だと若干低いような気もしますが…)
4. あとがき
このシリーズは「なんでもいいから好きなことを勉強してみろ」との課題として全8回シリーズで書きました。結果、機械学習の基礎が理解できたので良い機会になりました。最近"AI"は「よく分からないけどなんでもできるすごいやつ」みたいな雰囲気が世間にある気がして嫌だな~と思っていましたが、自分で組んでみることでようはただパラメータの最適化が元になっていることや、こういう用途は得意だから積極的に使えるな、逆に機械学習は決して万能ではなくこっちの用途は苦手だから他の手法を考える必要がありそうだな、ということが考えられるようになったのは良かったです。これからは自分の専門分野×機械学習なんてことも考えていけたら良いです。一応月2本程度と決めて書いていましたが、メインの研究が忙しいときは減らしたり余裕があるときにまとめて進めたりとスケジューリングができたのも良かったです。
その一方、勉強や実装はもう少しいろいろやってみたのですが、時間や労力の都合で記事にするのはその途中までになってしまったのは残念でした。また、あくまで初学者の自分のアウトプットとして書いていてリアクションを求めていたわけではないですが内容がQiitaにしては当たり前すぎてリアクションが少ないのが残念でした。
練習で書いてみた自分の得意なTeXやMATLABの記事は着眼点がちゃんと必要としている人に刺さったのか、view数、LGTM、ストック、どれも多くの人に役立てていただけ、やりがいにつながりました。やっぱりこの世の中を生きていくためにはすべてが80点よりある一分野で120点の方が需要があると感じました。これからはまず自分の得意分野をとことん深めて社会で戦っていける武器を作りたいです。それから更に得意分野を広げられるように横の関連へどんどん触手をのばしていきたいですね。全8回お付き合いありがとうございました。
参考文献
ゼロから作るDeep-Learning
ゼロから作るDeep-Learning GitHub
深層学習 (機械学習プロフェッショナルシリーズ)