概要
Excel方眼紙にスクリプトを記述することで動作するLisp風スクリプト言語を作ってみました。
機能としてはめちゃくちゃ貧弱なおもちゃ言語です。
デモ
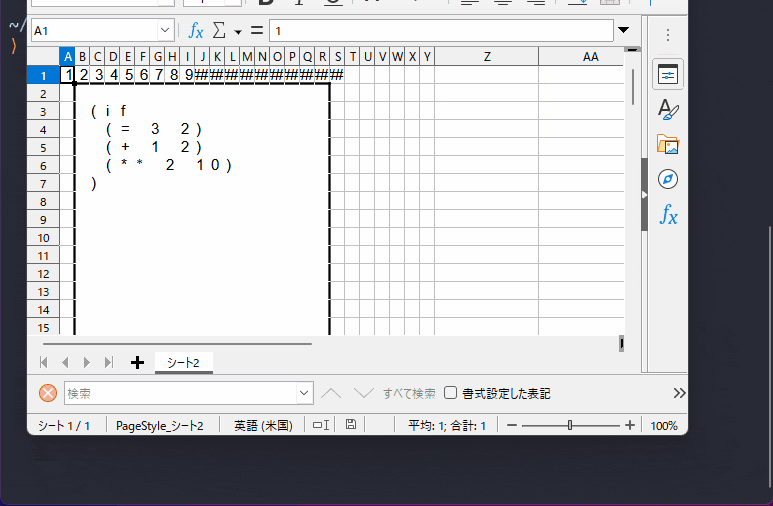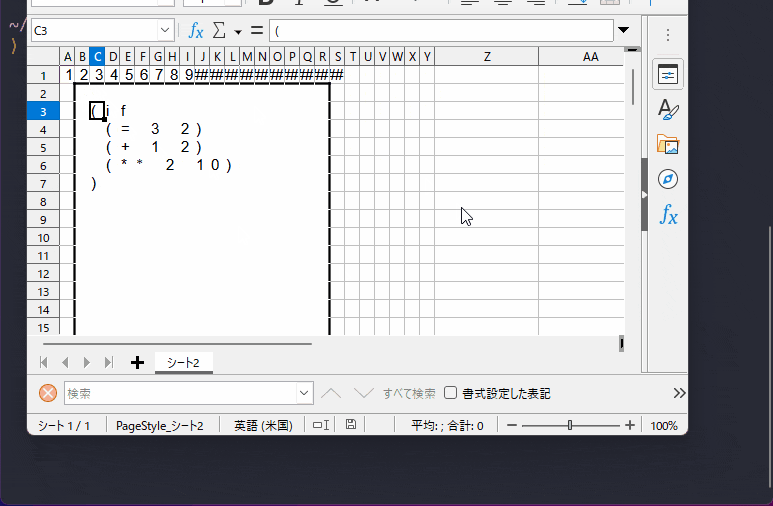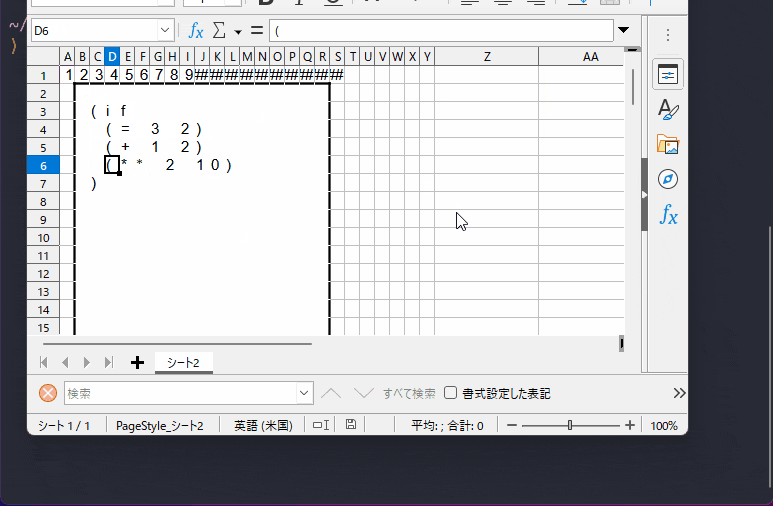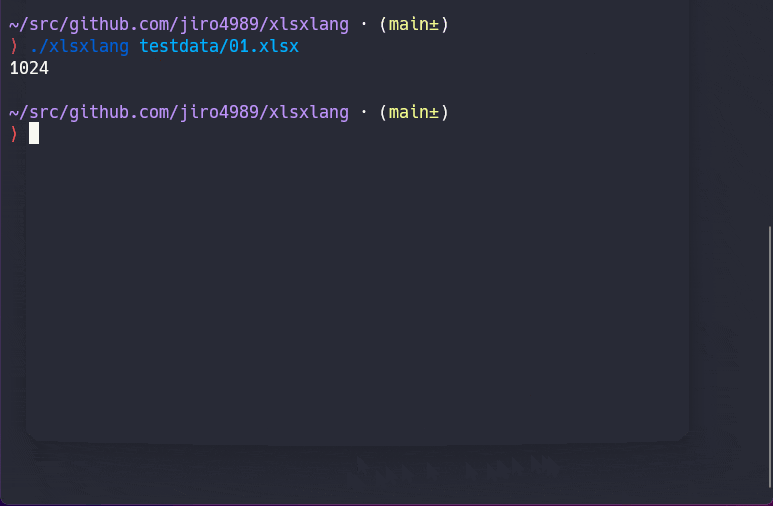
成果物
リポジトリは以下。
作った背景
理由は2つあります
- 以前からスクリプト言語を作って見たかったから
- 暇だったから
入力をExcel方眼紙のみにしたのはなんとなくです。2
どうせ作るなら誰も使いたくないようなバカバカしいものにしたかった。
機能
機能はめちゃくちゃ乏しいです。
出来ることは以下だけです
- 標準出力
- 数値演算(整数のみ)
- 条件分岐
これらは以下の組み込み関数で実現できます
- println
-
+,-,*,/,%,**(累乗) - if
以下の機能はありません
- 関数定義
- 変数定義
- forループ
- マクロ
サポートしているデータ型は以下のみです
- bool
- int64
- string
- nil
- symbol
- list
まぁ最低限BMI値の計算くらいになら使えるかな、というところ。(整数の範囲だけだけれど)
工夫したとこ
テキストの読み取りはB2セルから
Excelつかってたら、値を入力する領域にマージンを取るケースがよくあるので、
このプログラムにも採用しました。
1行目とA列の値は全て無視します。
1セルに書けるのは1文字だけ
Excel方眼紙を入力として受け付けるので、当然1セルに対して1文字しか入力できないようにしました。
1セルに2文字以上入っているとエラーでコケます。
すべて文字列として入力する
数値もすべて文字列として入力する必要があります。
つまり 1 と直接入力するのではなく '1 と入力して明示的に文字列として入力する必要があります。
まぁこれは工夫したというよりは、整数として入力したつもりだけれど、プログラムで読み取ったときに 1.0 と解釈されて困っていたので、もう仕様として受け入れることにしました。
スクリプトをワンラインで実行できない
どうしてもExcelファイルから入力させたかったので、元々コマンドラインでスクリプトを実行できるようにしていたのをできなくしました。
⟩ ./xlsxlang -e '(= (+ 3 3) (* 2 3))'
Use excel file.
デバッグビルドを有効にしないとコマンドラインからのスクリプト実行を拒否します。
実装
PEGを使って字句解析
文法は基本的にLispを踏襲しています。
スクリプト言語を作る場合以下の3つの順序で処理します。
- 字句解析
- 構文解析
- 意味解析
このうち字句解析と構文解析部分を自分で作るのは厳しそうでしたので、PEG (Parsing Expression Grammar)を採用しました。
PEG処理系にはpointlander/pegを使用しました。
Yaccとどっちが良いか検討していたのですが、PEGのほうが楽そうな感じがしたので。
実際のところLispの文法が単純だからというのもあるのでしょうけれど、記述したPEGはたったこれだけです。
package main
import "github.com/jiro4989/xlsxlang/token"
type Parser Peg {
token.Tokenizer
}
program <- cell+
cell <- space* (list / atom) space*
list <- '(' { p.Begin() }
cell+
')' { p.End() }
atom <- bool / int / str / nil / symbol
bool <- < 'true' / 'false' > { p.PushBool(text) }
int <- < [1-9] [0-9]* / [0] > { p.PushInt(text) }
str <- '"' < ([^"\\] / '\\')* > '"' { p.PushStr(text) }
nil <- 'nil' { p.PushNil() }
symbol <- < (!delimiter .)+ > { p.PushSymbol(text) }
space <- ' ' / '\n'
paren <- '(' / ')'
delimiter <- paren / space
このPEGファイルを grammer.peg という名前で保存して、前述のpegのツールを使って以下のコマンドを実行すればPEGからGoのコード (grammer.peg.go)が生成されます。
peg grammer.peg
PEGを使うことで実装量を大幅に抑えることができました。
ただし、いちいちpegコマンドを叩くのが面倒なので、以下のMakefileも作りました。
pegファイルが更新されたときだけpegを再実行してソースコードを生成してから、go buildを実行します。
xlsxlang: grammer.peg.go *.go */*.go
go fmt ./...
go build -tags debug
go test -cover
grammer.peg.go: grammer.peg
peg grammer.peg
.PHONY: setup
setup:
go install github.com/pointlander/peg
構文解析
このpegのツールの特徴として {} の部分になんらかの処理を差し込める点があります。
この処理で解析されたトークンを構造化データにしています。
pegファイル内で呼び出している関数は以下です。たったこれだけです。3
package token
import (
"strconv"
)
type Tokenizer struct {
tokens []Token
depth int
bufferTokens []Token
}
func (e *Tokenizer) GetTokens() []Token {
return e.tokens
}
func (e *Tokenizer) PushBool(s string) {
b, _ := strconv.ParseBool(s)
token := NewBoolToken(b)
e.push(token)
}
func (e *Tokenizer) PushInt(s string) {
i, _ := strconv.ParseInt(s, 10, 64)
token := NewIntToken(i)
e.push(token)
}
func (e *Tokenizer) PushStr(s string) {
token := NewStrToken(s)
e.push(token)
}
func (e *Tokenizer) PushNil() {
token := NewNilToken()
e.push(token)
}
func (e *Tokenizer) PushSymbol(s string) {
token := NewSymbolToken(s)
e.push(token)
}
func (e *Tokenizer) Begin() {
e.depth++
token := NewListToken()
e.bufferTokens = append(e.bufferTokens, token)
}
func (e *Tokenizer) End() {
e.depth--
token := e.bufferTokens[e.depth]
e.bufferTokens = e.bufferTokens[:e.depth]
e.push(token)
}
func (e *Tokenizer) push(token Token) {
d := e.depth
if d < 1 {
e.tokens = append(e.tokens, token)
return
}
d--
e.bufferTokens[d].ValueList = append(e.bufferTokens[d].ValueList, token)
}
pegの記述と合わせて見ていくと、以下のような処理になっています。
1 listの開始場所が見つかったらBeginを呼び出して、一時的な空リストを生成する
list <- '(' { p.Begin() }
cell+
')' { p.End() }
2 cellをたどっていって、atomが見つかったら、それぞれ先程生成した一時的なリストに末尾追加する。listが見つかったら更に一時的なリストを生成する。
cell <- space* (list / atom) space*
atom <- bool / int / str / nil / symbol
bool <- < 'true' / 'false' > { p.PushBool(text) }
int <- < [1-9] [0-9]* / [0] > { p.PushInt(text) }
str <- '"' < ([^"\\] / '\\')* > '"' { p.PushStr(text) }
nil <- 'nil' { p.PushNil() }
symbol <- < (!delimiter .)+ > { p.PushSymbol(text) }
3 listの終端が見つかったらEndを呼び出し、生成していた一時的なリストを正式に登録して一時的なリストを削除する
list <- '(' { p.Begin() }
cell+
')' { p.End() }
ひたすらコレを繰り返しているだけです。かなり単純でした。
意味解析
字句解析、構文解析が終わったら最後は意味解析です。
機能が全然足りないのでコード量としてはたったこれだけです。
まだ変数を扱えないので、シンボルが見つかったらそれは全て組み込み関数として処理します。
組み込み関数名がヒットしたら、必要な分だけトークンをリストから取り出して評価して、結果を返します。
package main
import (
"github.com/jiro4989/xlsxlang/builtin"
"github.com/jiro4989/xlsxlang/token"
)
type Eval struct {
tokens []token.Token
}
func Evaluate(tokens []token.Token) token.Token {
for 0 < len(tokens) {
var t token.Token
t, tokens = dequeue(tokens)
switch t.Kind {
case token.KindBool:
return t
case token.KindInt:
return t
case token.KindStr:
return t
case token.KindNil:
return t
case token.KindSymbol:
// if は引数が3つ
if t.ValueSymbol == "if" {
var a, b, c token.Token
a, tokens = dequeue(tokens)
b, tokens = dequeue(tokens)
c, tokens = dequeue(tokens)
a = Evaluate([]token.Token{a})
var arg token.Token
// trueのときはbだけ評価、そうでなければcだけ評価
if a.IsTrue() {
arg = b
} else {
arg = c
}
return Evaluate([]token.Token{arg})
}
// mathの関数はいずれも引数が2つだけ
if f, ok := isBuiltinMathFunction(t); ok {
var a, b token.Token
a, tokens = dequeue(tokens)
b, tokens = dequeue(tokens)
a = Evaluate([]token.Token{a})
b = Evaluate([]token.Token{b})
return f(a, b)
}
// print関数はいずれも引数が1つだけ
if f, ok := isBuiltinPrintFunction(t); ok {
var a token.Token
a, tokens = dequeue(tokens)
a = Evaluate([]token.Token{a})
return f(a)
}
case token.KindList:
return Evaluate(t.ValueList)
}
}
return token.NewNilToken()
}
func dequeue(tokens []token.Token) (token.Token, []token.Token) {
t := tokens[0]
tokens = tokens[1:]
return t, tokens
}
func isBuiltinMathFunction(t token.Token) (builtin.MathFunction, bool) {
sym := t.ValueSymbol
f, ok := builtin.MathFunctions[sym]
if !ok {
return nil, false
}
return f, ok
}
func isBuiltinPrintFunction(t token.Token) (builtin.PrintFunction, bool) {
sym := t.ValueSymbol
f, ok := builtin.PrintFunctions[sym]
if !ok {
return nil, false
}
return f, ok
}
かかった時間
12時間ほどでした。(うち、このQiitaの記事を書くのに2,3時間ほど)
初めてやった試みにしてはあんまり時間かからなかった感触です。
pegを使ってだいぶ省力化できたのと、文法が単純なlispの文法を踏襲したおかげで、思っていたほど苦戦しませんでした。(多少は苦戦した)
感想
おもちゃみたいな言語ですけれど、一通り形になるまで作りきってみると、やはり学びが多いですね。
簡易な文法を定義して、それを解釈できるプログラムの作り方をざっくり把握しておけば、技術の幅が広がりそうです。
特に今回の実装の過程で、PEGをつかって日付の解釈をしているプログラムを発見できたのは思ってもない収穫でした。(後述)
すでに成熟したプログラミング言語がたくさん存在する中で、わざわざ自分がくだらないプログラミング言語を作ろう、と、やる前から時間を無駄にするつもりで始めた開発でしたが、終わってみれば未踏の領域からいろんな学びを得ました。
作った物に意味が無くてもその過程で得た知識には価値があったものと感じています。
これをモチベーションに今後もいろんな挑戦を続けよう、という気持ちになりました。
まとめ
- Excel方眼紙にスクリプトを記述することで動作するLisp風スクリプト言語を作った
- 機能はしょぼい
- 字句解析、構文解析にはPEGを採用した
以上です
参考文献
以下の記事を参考にしました
また、実装レベルでは以下のプログラムが参考になりました。
go-naturaldate, dtime はどちらも日付文字列の解釈にpegを使っているようで、こんな使い方もあるんだなぁと学びがありました。
- pointlander/peg - GitHub
- tj/go-naturaldate/blob/master/grammar.peg - GitHub
- rwxrob/dtime/blob/main/grammar.peg - GitHub
-
残念ながらExcelを僕は持っていないのでLibreOfficeでファイルを作ってxlsxとしてエクスポートして作りました。動作確認もLibreOfficeで行っています ↩
-
ExcelやGoogleSpreadsheetは非常に素晴らしいソフトウェアで、僕も業務で頻繁に活用しています。しかしながら、表計算ソフトとしての用途と違う目的で方眼紙として使う文化は嫌いです。ただし止むに止まれぬ事情があることもまた分かります。 ↩
-
pegで字句解析と構文解析をまとめてやってるのでpegのparserに渡す構造体名として何が適当なのかめちゃくちゃ悩んだ末にTokenizerという名前にしたのですが、これもまだ適当ではない気がします。どういう名前が適当なんだろう ↩