最近DL(Deep Learning)の各手法についてtensorflowで実装する場合の実際のコードを聞かれることが多くなってきたので一度まとめておきます。
(10/17/2017 Batch Normalization, Gradient Clipping, ビジュアライズ関連 追加)
下のリストはInside of Deep Learning (ディープラーニングの性能改善手法 一覧)に載せたものです。しかし個人的な経験からも性能改善は一筋縄ではいきません。単に性能の高いモデルを使えば良いといういうわけではなくデータの規模や質によってはシンプルなモデルを使った方が良い時もあります。
↑ Best
- より表現力があり問題の処理に適したモデルを利用する
- より多くのデータあるいはより精度の良いデータを使う
- パラメータを収束/学習させるための工夫
- 汎化性能をあげるための工夫
↓ Better
論文として出す場合や実際にデモに組み込む場合はまず性能が出ていないと話になりません。苦労してデータ作成が終わったのに性能が出ないというのは良く聞く話です。
よく聞かれるところとして大まかに ビジュアライズ、初期値設定、正則化、Batch Normalization、伝達関数、Dropout、転移学習(ファインチューニング)、Early Stopping の実装例を載せていこうと思います。
(tensorflow 1.0以降を対象)
ビジュアライズ
さて、まずやるべきことはビジュアライズ(可視化)です。
モデルがちゃんと学習が進んでいるのか、バグはないか、想定したグラフが構築できているのかを確認します。
tensorboardでのビジュアライズ
計算グラフやウェイトやバイアスの初期値、分散やヒストグラムの時間変化などを確認します。
model_name = "my_model"
# 学習したCNNフィルタ(4次元のW_Conv)の書き出し 軸を転置させる必要があることに注意
weight_transposed = tf.transpose(W_conv, [3, 0, 1, 2])
tf.summary.image("W0/" + model_name, weight_transposed, max_outputs=20)
# ロスなどスカラ値の書き出し
tf.summary.scalar("test_loss/" + model_name, loss)
# ウェイトやバイアスの平均値や最大値、分散やヒストグラムの時間変化
with tf.name_scope("my_variable"):
tf.summary.scalar("mean/" + model_name, tf.reduce_mean(var))
tf.summary.scalar("stddev/" + model_name, tf.sqrt(tf.reduce_mean(tf.square(var - tf.reduce_mean(var)))))
tf.summary.scalar("max/" + model_name, tf.reduce_max(var))
tf.summary.scalar("min/" + model_name, tf.reduce_min(var))
tf.summary.histogram(model_name, var)
# 各種 tf.summary.***() を呼んでグラフを作った後、各サマリーグラフを統合取得する
summary_op = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter("tf_log", graph=sess.graph)
saver = tf.train.Saver()
tensorboardへの書き出しはSaverを利用します。summary_op グラフを構築したら1epochに1回など適切なタイミングでsummary_opを計算させ、summary_writer.flush()で書き出します。下記ではsummary_opを独立させて計算していますが、通常のlossの計算やトレーニング時に同時に求めると効率が良いです。
summary_str = sess.run([summary_op], feed_dict={self.x:images, self.y:test_images})
summary_writer.add_summary(summary_str, step)
summary_writer.flush()
DLはただでさえモデルの状態が分かり難いので、下に続く初期値の設定や正則化の効果などを可視化して確認していきます。

バイアスの学習による変化 (エポックが経過するごとに値の分布が広がる)
簡易デバッグ用コンソール出力
簡単デバッグ用にグラフ内の値を tf.Print() を手軽に使ってコンソールに出力できます。
# グラフ内のlossをeval()を使わずにコンソールに表示
loss = tf.Print(loss, [loss], message="Loss:")
グラフ内のテンソーの値を取得して内容を表示
例えば1次元のテンソーならeval()で取得した後に下記のように表示します。
# グラフ内の1次元テンソーオブジェクト tensor の内容を表示
print("Tensor[%s] shape=%s" % (tensor.name, str(tensor.get_shape())))
tensor_values = tensor.eval()
line = ""
for i in range(tensor_values.shape[0]):
line += "%2.3f " % tensor_values[i]
print(line)
モデル内のトレーニング可能なパラメータ総数の取得
モデルの複雑さを示す一つの指標として僕はこの値を良く参考にしています。(またグラフが正しく構築できているかを確認する時にも非常に役立ちます)
下の例ではtf.trainable_variables()でトレーニング可能な変数を列挙して各パラメータ数を合計しています。
# トレーニング可能な変数とその次元を列挙、合計する
total_parameters = 0
parameters_string = ""
for variable in tf.trainable_variables():
shape = variable.get_shape()
variable_parameters = 1
for dim in shape:
variable_parameters *= dim.value
total_parameters += variable_parameters
if len(shape) == 1:
parameters_string += ("%s %d, " % (variable.name, variable_parameters))
else:
parameters_string += ("%s %s=%d, " % (variable.name, str(shape), variable_parameters))
print(parameters_string)
print("Total %d variables, %s params" % (len(tf.trainable_variables()), "{:,}".format(total_parameters)))
トレーニング VS テストのロスの重畳グラフ作成
過学習状態になっている場合は、例えばトレーニングセットのロスが下がっているのにテストセットのロスが上がってしまう状況を観測することがあります。また、学習係数の変更タイミングやロスの推移を見ることは必須です。
tensorboardではいちいちコンソールを叩かないと確認できませんし、2つのグラフを重畳して同時に重ねて見ることができません。またあらかたモデルが育ってくるとlossの推移だけを見ればよくなります。この場合は例えば次のようにしてmatplotを使ってグラフを書き出します。
(昔のバージョンではできなかったのですが、今のバーションではできるようになっていました。いつかやり方を追記します。17/10/2017)
import matplotlib.pyplot as plt
csv_epochs = []
csv_loss = []
csv_training_loss = []
# 各epochで下記のようにその時のepochとlossなどを追加していく
csv_epochs.append(epochs)
csv_loss.append(loss)
csv_training_loss.append(training_loss)
# 計算中あるいは計算終了時にpngグラフを作成
plt.plot(csv_epochs, csv_training_loss, "b", label="Training Loss")
plt.plot(csv_epochs, csv_loss, "r", label="Test Loss")
plt.vlines(csv_epochs[-1], 0, csv_loss[-1], color='0.75')
plt.hlines(csv_loss[-1], 0, csv_epochs[-1], color='0.75')
plt.savefig("graphs/model_name.png")

CSVファイルにロスなどを保存する
これも意外と良く聞かれます。私も実験をするたびに異なったファイル名で自動でCSVで途中結果を保存しておくようにしています。numpyのcolumn_stack()を使うと便利です。
import numpy as np
# 上の通りにcsv_epochs などを作成したとして
loss_graph = np.column_stack((csv_epochs, csv_loss, csv_training_loss))
np.savetxt("graphs/model_name.csv", loss_graph, delimiter=",")
tensorboardにオリジナルの値を保存する
グラフ内のtensor以外にも、例えば独自に計算した指標などをプログラムの方からtensorflowのログに書き込むことができます。例えばロスとしてはMSE(平均二乗誤差)を使用しつつ評価にはPSNR(ピーク信号対雑音比)を使いたい場合、わざわざPSNRを計算するグラフを構築しなくともPython上で値を計算して指定のタグ(変数名)、ステップ数に保存できます。
psnr_value = 20 * math.log(max_value / math.sqrt(mse), 10)
step = 10
summary = tf.Summary(value=[tf.Summary.Value(tag="test_PSNR", simple_value=psnr_value)])
writer = tf.summary.FileWriter("tf_log_dir/test", graph=sess.graph)
writer.add_summary(summary, step)
writer.flush()
モデルのリファイン
新規アプリケーションへの深層学習適用のベストプラクティスで詳しく記事にされています。この内容は自分の経験してきたこととも良くマッチしているので、慣れてない方は是非参考にして下さい。まずはシンプルで実績のあるモデル+少量のデータで正しく学習が回ることを確認してからモデルを育てていく方がずっと近道だと感じます。
この章では幾つかの伝達関数やCNNの亜種の実装を紹介します。
Leaky ReLU
ReLUはDLの性能を一段押し上げた非常に使いやすい伝達関数ですが、__”dying ReLU problem"__と言われる問題があります。これは学習中に一度大きな負のウェイトやバイアスを得てしまうと、それに続くReLUユニットは常にゼロを出力し続けてしまいそれ以降の学習が適切に行われなくなってしまうという問題があります。
それに対抗するのがLeakyReLUです。詳しくは私の以前に書いたDLの手法解説を見て頂くとして、とりあえず実装は下記のようなコードで実現できます。
# convテンソーの出力にLeaky ReLUをかける
h = tf.maximum(conv, 0.1 * conv)
Parametric ReLU
Leaky ReLUは個人的な経験では非常に有用でした。なかなか上がらなかったモデルの性能を若干押し上げたり、DQNの強化学習などで時々ローカルミニマムに落ち込んでしまうのを防ぐことがありました。
Leaky ReLUのα値を各要素ごとに学習で決めるのがParametric ReLUです。詳しくは ["Delving Deep into Rectifiers"の論文] (https://arxiv.org/abs/1502.01852)を参照して頂きたいですがこれもなかなか有用です。ただし実装方法がちょっとトリッキーで若干難しかったので、ここでは実装方法の一例を載せます。
# 入力x に対して ウェイトw のCNNフィルタを作成し、各出力に対してのα変数を作成。Parametric ReLUを作成する
conv = tf.nn.conv2d(x, w, strides=[stride, stride, 1, 1], padding="SAME")
alphas = tf.Variable(tf.constant(0.1, shape=[w.get_shape()[3]]))
h = tf.nn.relu(conv) + tf.multiply(alphas, (conv - tf.abs(conv))) * 0.5
Dilated CNN
CNNをプーリングしてローカルな特徴をサマライズしていく時に、より少ないパラメータや計算量で特徴をつかめるのがDilated CNNです。隙間を開けて飛び飛びにCNNをかけていくもので、画像だけでなくWaveNetと呼ばれる音声認識などのモデルでも使われています。こちらのブログの解説が分かりやすいです。
CNNの代わりに使うことで性能が上がる時もあります。
# Dilated CNNのサンプル. rateで指定した分だけ飛んでCNNを適用する
conv = tf.nn.atrous_conv2d(x, w, rate, padding="SAME")
Deconvolution Filter (Transposed CNN)
デコンボリューショナルフィルタはCNNと動作は似ていますが、CNNとは逆に入力した要素数よりも大きな要素数の出力を出すことができます。例えばアップサンプリングなどに利用することができ、データを補完して解像度を上げたりすることが可能です。動作の仕組みについてはこちらのgithubの図解が詳しいです。
TensorflowではTransposed CNNと呼ばれています。
# Transposed CNNのサンプル. stridesで指定した分だけ値をゼロで補完してCNNを適用する
h = tf.nn.conv2d_transpose(x, w, output_shape=output_shape, strides=strides, padding='SAME')
データオーギュメンテーション
例えば画像であればトレーニングセットにノイズを混ぜたり上下左右の反転画像を混ぜたりすることで簡易に性能が上がることがあります。下記は自前で構築しているあるモデルについてオーギュンテーションを行ったり、データサイズの大きな別のセットをトレーニングに使った場合のトータルデータ量(横軸)と性能(縦軸)のグラフです。

まずはデータ量が十分であるかを確認したり、ロスが大きなデータを目視で確認して変なデータが混ざっていたりしないかを確認します。
画像のオーギュメンテーションについては機械学習のデータセット画像枚数を増やす方法で一覧が見れますのでここでは割愛します。
パラメータを収束/学習させるための工夫
ここでは初期値の設定方法や正則化の実装を見ていきましょう。まず初期値はモデルのレイヤーが増えてきた場合に非常に重要です。各レイヤーの間で出力値の分散が等しくなるように初期値を設定することでフォワードプロパゲーションやバックプロパゲーションの計算中の出力や誤差の発散や消失を抑えることができます。
Xavierの初期化
Xavierの初期化は実はReLUには対応せずSigmoidやtanhなどの伝達関数に使うので実際は使う場所は少ないかもしれませんが、下記のように計算して初期化します。
# shape = 初期化するウェイトの次元として、4次元のCNNの場合は下記
fan_in = shape[0] * shape[1] * shape[2]
fan_out = shape[0] * shape[1] * shape[3]
n = fan_in + fan_out
# さらに一様の分布にする場合は下記
init_range = math.sqrt(6.0 / n)
initial = tf.random_uniform(shape, minval=-init_range, maxval=init_range)
weight = tf.Variable(initial, name=name)
# さらに正規分布にする場合は下記
stddev = math.sqrt(3.0 / n)
initial = tf.truncated_normal(shape=shape, stddev=stddev)
weight = tf.Variable(initial, name=name)
Heの初期化
Heの初期化はReLU用ですのでこちらは使い所が多いです。
# shape = 初期化するウェイトの次元として、4次元のCNNの場合は下記
n = shape[0] * shape[1] * shape[2]
stddev = math.sqrt(2.0 / n)
initial = tf.truncated_normal(shape=shape, stddev=stddev)
weight = tf.Variable(initial, name=name)
L1 / L2 正則化
各ウェイトが発散しないようにするための工夫が L1 / L2 正則化です。
L1正則化はいわゆるマンハッタン距離などと呼ばれているもので、各ウェイトの要素の絶対値を全て足したものです。L2正則化はユークリッド距離で、全ての要素の二乗和の平方根です。それぞれ L1 / L2 項をロスに加えて最適化します。
L2の方がウェイトの大きさをより正確に表していてより正しく正則化できるように見えるのに何故L1を使う選択肢もあるのかというと、L1の方が計算が速くまた距離の表現としてそこまで離れてはいないため十分な正則化性能を得られることも多いためです。
# L1正則化項をlossに加える
l1_loss = 0.001 * tf.reduce_sum( tf.abs( W_conv0 ) + tf.abs( W_conv1 ) + ... )
train_step = tf.train.GradientDescentOptimizer(0.05).minimize(loss+l1_loss)
L1/L2の計算の場合は通常バイアス項は含まずウェイト項のみを使います。
ウェイト項は配列として保持しておくといろいろと便利です。
# ウェイト配列のL2正則化項をlossに加える
l2_decay = 0.0001
weights = 5 * [None]
weights[0] = tf.truncated_normal(shape=shape, stddev=stddev)
...
l2_losses = [tf.nn.l2_loss(w) for w in weights]
l2_loss = l2_decay * tf.add_n(l2_losses)
Sparse Regularization
また、正則化にはウェイトだけを正則化するのではなく、例えば計算途中の隠れ層の出力値を正則化する方法もあります。これを行うことで次の層の入力データの範囲を整え、ReLUのユニットが死んでしまう問題などへの効果も期待できます。
# 各層の出力hに対して、下記の値を全て足し合わせてlossに加える
sparse_regularization_values += tf.reduce_mean(tf.log(1 + h * h))
sparse_regularization_values *= 0.0001
loss += sparse_regularization_values
Batch Normalization
ReLU等のアクティベーション層の前にBN層をはさみ、ここで入力データの平均値と分散を揃えるように試みます。これにより学習が安定化し、出力が正則化される効果があります。通常はCNNの計算後に設置するイメージですが、ある条件下ではCNNの前にBNとReLUをセットで設置するPre-Activationというテクニックもあるようです。
実装については単純に用意されたレイヤーを使うだけですが、BN層は内部のパラメータを学習しながら調整していくものであり推論時には動作が異なるため、学習中かどうかを示すPlaceHolderを用意してis_trainingオプションにセットする必要があることに注意して下さい。
# trainingフェーズであるかどうかの入力ポイントを作成
phase = tf.placeholder(tf.bool, name="phase")
# グラフ作成時にBN層を追加
conv = tf.contrib.layers.batch_norm(x, center=True, scale=True, is_training=phase, scope='bn')
# セッションの実行時に、トレーニング中は1、推論時は0を指定する
feed_dict = {..., phase: 1}
Gradient Clipping
グラディエント・クリッピングは、学習時のパラメータの収束をより安定化させるための手法です。例えば二つの変数の間でロスの分布が下図のようになっていたとします。この場合オプティマイザに勾配降下法を使っていると、崖の部分にパラメータが触れた場合、勾配が強いため次の探索位置は大きく離れたところに飛ばされてしまいます(下図太矢印)。そしてまた崖付近に近づいていっても一旦崖に触れるとまた跳ね飛ばされてしまいます。
GCではオプティマイズのステップで勾配を計算した時に、ある最大値で勾配の値をクリッピングして探索を安定化させることができます。
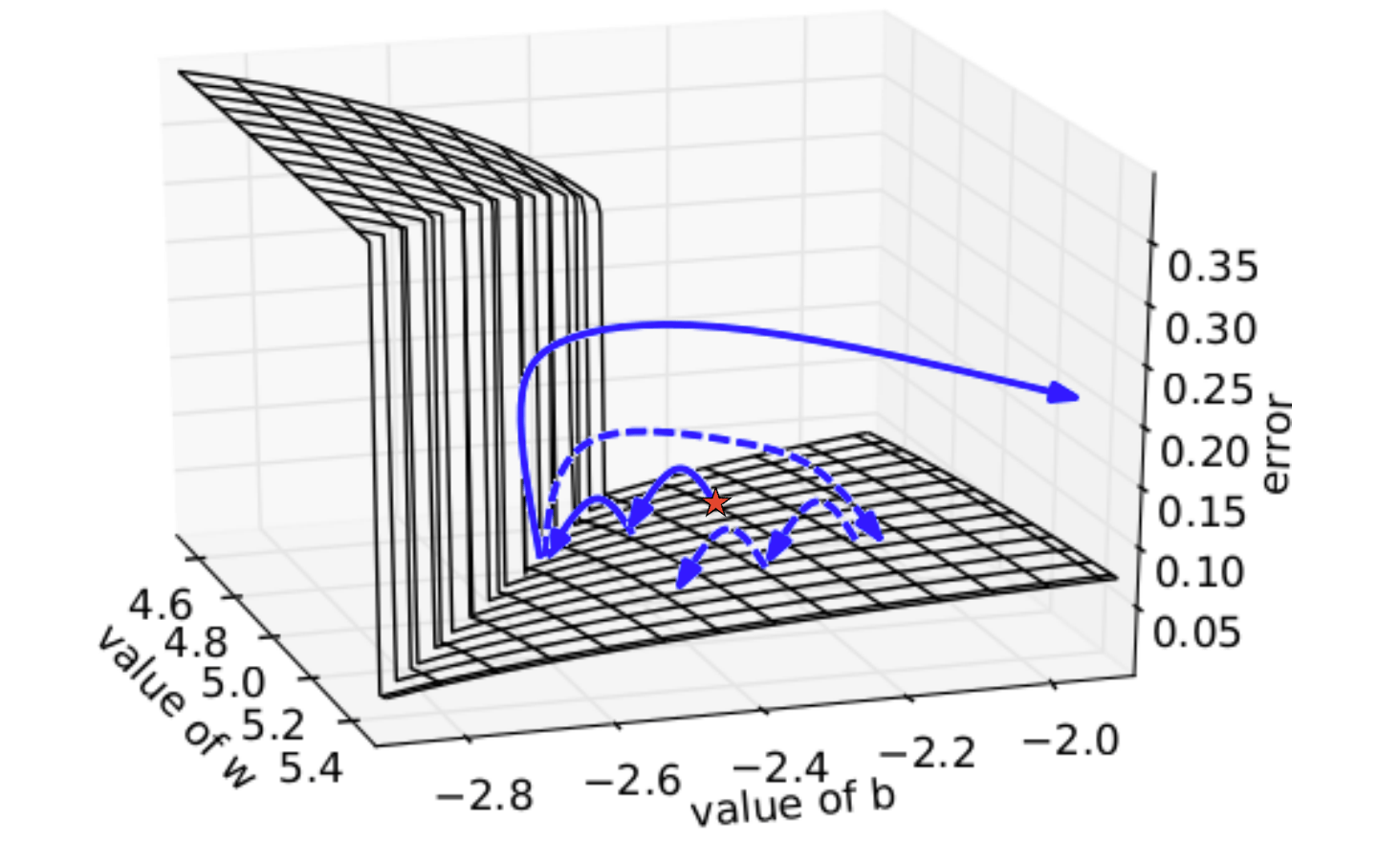
画像は IFT6266 – H2015 Representation Learningより使用させてもらっています。
optimizer = tf.train.AdamOptimizer(lr_input, beta1=self.beta1, beta2=self.beta2)
# 通常はoptimzerを定義したらそのまま下記のようにロスを入れるが、
# training_optimizer = optimizer.minimize(loss)
# GCではまずトレーニングできる変数を列挙し、それらの勾配を計算する。
trainables = tf.trainable_variables()
grads = tf.gradients(loss, trainables)
# その後、clipping_normに指定した値を上限としてクリッピングし、オプティマイズする
grads, _ = tf.clip_by_global_norm(grads, clip_norm=clipping_norm)
grad_var_pairs = zip(grads, trainables)
gc_optimizer = optimizer.apply_gradients(grad_var_pairs)
汎化性能を上げる / 特定のデータセットに適応させる
一応最後にはなりましたが、汎化性能を上げて過学習状態を解消することは常に意識するべきポイントです。また転移学習やファインチューニングを使って既存のモデルを特定のデータ領域や目的に転用するテクニックもよく使われます。
Dropout
dropoutはわざわざソースコードを載せるほどではないのですが、効果が高く手軽なので念のため載せておきます。
# トレーニング時はdropoutを設定し、テスト時はdropoutを行わないために入力用のplaceholderを作成する
dropout_input = tf.placeholder(tf.float32, shape=[], name="dropout_keep_rate")
# 出力hにdropoutを適用する
h = tf.nn.dropout(h, dropout_input)
# トレーニング時/テスト時などに合わせてdropout rateを指定する
sess.run(optimizer, feed_dict={self.x: input, self.y: true, dropout_input: 0.8})
Early Stopping
下図のグラフのように学習が進むとトレーニングセットに過学習してしまうことがあります。こうならないうちに(テストセットのロスがピークのうちに)学習を打ち切るのがEarly Stoppingです。個人的にはあまり本質的な対応ではなく、そもそもこのような状態にならないように他の技を利用する方が良いのではと思ってはいます。ですが論文発表などでほんの少しでも高い性能を得たい場合などは参考にして下さい。

画像はDeep Learning 4Jより
tensorflowではValidationMonitorがそのための機能として用意されているのですが、転移学習などでも利用できるためここでは直接目的のウェイト値を保存するコードを載せておきます。
# 注意事項として、Saver作成時にmax_to_keep=Noneを指定しておくこと。
# こうしないとある規定数以上のファイルを保存した時に自動的に古いものから削除されてしまう
saver = tf.train.Saver(max_to_keep=None)
# テストセットで最高の性能が出た場合にモデルを保存する
saver.save(sess, filename)
# テストセットでの性能が落ち始めたら保存していたモデルをリストアする
# あるいはモデル初期化時に sess.run(tf.global_variables_initializer()) の代わりに呼び出す
saver.restore(sess, filename)
転移学習
他のモデルで学習されたウェイトを読み込んで初期値として利用します。例えば学習済みのテンソーから.eval()関数を使って値を取得しnumpyのオブジェクトとして保存。その後テンソーの初期化時に読み込んで指定する方法などがあります。
ですがここでは転移させたいtensorに共通する接頭語をつけてグループ化し、Saverを使ってそのグループ化されたテンソーへのみロードする方法を紹介します。
# CNN 5層分のウェイトを作成し、名前の先頭に "C_"をつける
W_conv = 5 * [None]
for i in range(5):
initial = tf.truncated_normal(shape=[3, 3, 64, 64], stddev=0.01, name=("C_W%d_conv" % i.level))
W_conv[i] = tf.Variable(initial)
# 名前の先頭に"C_"がついた変数だけを取得し、それら用のsaverを作成し利用
saver_c = tf.train.Saver([v for v in tf.all_variables() if v.name.startswith("C_")])
saver_c.restore(sess, filename)
ファインチューニング
ファインチューニングでは、例えばモデルの前半を特徴抽出器として事前に学習されたウェイトを利用し、最終段のみ学習させることで少ない量のデータでもそれに特化したモデルを構築することができます。
これは指定したレイヤーのみ値が更新されるオプティマイザを作成することで実現できます。
# 上記と同様にファィンチューンしたい最終弾のウェイトのみに "F_"で始まる名前をつけます。
Fc1 = tf.Variable(tf.truncated_normal(shape=[1024, 64], stddev=0.01, name=("F_Fc1")))
Fc2 = tf.Variable(tf.truncated_normal(shape=[64, 10], stddev=0.01, name=("F_Fc2")))
# トレーニング可能な変数のうち"F_"で始まるもののみを集め、その勾配を計算し最適化するオプティマイザを作成します
tuning_grads = optimizer.compute_gradients(
loss,
[v for v in tf.trainable_variables() if (v.name.startswith("F_"))]
)
tuning_optimizer = optimizer.apply_gradients(tuning_grads)
# ファインチューニングを行う場合、行わない場合とでそれぞれ別のオプティマイザを利用する
if tuning:
optimizer = tuning_optimizer
else:
optimizer = training_optimizer
_, loss_eval = sess.run([optimizer, loss], feed_dict={self.x: batch_input, self.y: batch_true})
と、以上で一通りのコードを載せておきました。kerasを使えば必要のないコードもありますが、やはり細かいモデルを作ろうとするとtensorflowを直接触る機会も多くなると思います。
実装時の参考になれば幸いです。皆でやろうDL!