PYNQで始めるFPGA開発 - 入門編
TL; DR
FPGAってなに?開発コストが高いんじゃないの?Pythonで開発できるってほんと?初心者でも簡単にC++とPythonだけでFPGA開発する方法を調べました!まだプログラミングで消耗している非フルスタックなエンジニアの方は、非ノイマン型エンジニアになってもっと消耗しましょうハードも作れるフルスタックなエンジニアを目指しましょう!!
はじめに
FPGAはField-Programmable Gate Arrayの略で、製造後に回路構成を変更することができます。CPUやGPUなどの汎用集積回路と違い、FPGAは用途に応じて構成を変更することができるため、ハマる用途ではCPUやGPUよりも速い処理が可能です。用途に特化した回路で処理するためオーバーヘッドが少なく、高い電力効率も実現できます。
CPUやGPUを使うには設計した計算アルゴリズムをC言語などのソフトウェアプログラムとして記述します。FPGAを使うには論理回路を設計し、Verilogなどのハードウェア記述言語(HDL)で回路を記述します。回路設計を行う必要があるためCPUやGPUのソフトウェア記述と比べて開発コストが高いとされています。
近年、高位合成(HLS)と呼ばれる回路設計手法が注目されています。従来のHDL設計ではクロックなど具体的な回路動作を設計する必要がありました。HLS設計ではC言語などを用いて計算アルゴリズムを記述することで回路を設計することができ、具体的な回路動作を設計する必要がないため短期開発を実現します。また、抽象度の高いアルゴリズムで記述できるためテストを簡単に行えます。某ゲーム会社のハードを実装したの記事1によると、HLS設計はHDL設計より30倍短い期間で開発できるそうです。
本稿では、FPGAを用いた数値計算の高速化について説明します。Xilinx社Vivado HLS2によるFPGA回路設計と、PYNQ3による制御プログラム設計について説明し、HLS設計でパフォーマンスを出すための最適化手法について解説します。本稿はソフトウェア開発の経験がある方、FPGA開発をこれから始める方、FPGA設計に興味がある方を想定しています。FPGAとは何かもっと知りたい方はXilinxが日本語で出している公式のFPGA講座4をおすすめします。
Vivado HLS
Vivado HLS2とはXilinx社が提供する高位合成ソフトを含む開発環境です。C++で記述されたプログラムをVerilogなどのHDLによる回路記述に変換するコンパイラだと思って良いでしょう。同時に付属するVivadoはFPGA回路を設計するための回路合成ソフトです。Vivado HLSによって合成されたHDLなどの回路記述はVivadoによってFPGA回路に合成されます。こちらはコンパイラと違い、論理回路の配置や配線を行う回路合成ソフトです。これらのソフトは一部無料で提供されていますが、本稿で紹介する設計法は全て無料の機能で実現できます。
環境
動作するOSはWindowsとLinuxです。特に理由がない場合はUbuntuの使用を推奨します。本稿執筆時のVivado HLSの最新バージョンは2020.1です。本稿では2020.1を元に説明していきます。インストール手順は公式ドキュメント5に詳しいですが、以下にUbuntu 18.04でのインストール手順について簡単に説明します。Ubuntu Serverへのインストールでは追加の手順が必要となります。
- PCを用意します。4コア以上の64bitCPU、16GBメモリ、空き200GB以上のストレージを推奨します。
- Ubuntu 18.04をインストールします。筆者はMacBook ProにVMWare Fusionを用いた仮想環境を用います。
- Xilinxのアカウントを用意し、ダウンロードページからVivado HLSのインストーラをダウンロードします。
- Ubuntuのターミナルから
$ sudo sh ./Xilinx-(略)64.binを実行します。
※オプションは全てデフォルトのまま続行します。
※インストールには数時間かかることがあります。
※OSのタイムゾーン設定が間違っている場合、インストールに失敗することがあります。 - インストールが完了したら、ターミナルからVivado HLSとVivadoの起動を確認します。
※Vivado HLSの起動は$ /tools/Xilinx/Vivado/2020.1/bin/vivado_hlsを実行します。
※Vivadoの起動は$ /tools/Xilinx/Vivado/2020.1/bin/vivadoを実行します。
PYNQ
PYNQ3とはXilinx社のFPGAを簡単に扱うPythonライブラリと、Ubuntuベースの組み込み用イメージで構成されるオープンソースのプロジェクトです。本稿において、単にPYNQという場合はPythonライブラリのことを指します。PYNQを使うことで設計したFPGA回路の制御やCPU-FPGA間のデータ転送をPythonだけで記述することが可能となります。組み込み用のFPGA SoCからサーバー用FPGAカードにまで幅広い用途で使うことができます。PYNQのダウンロードで配布されているイメージファイルをSDカードに書き込むだけで使うことができます。
環境
PYNQは組み込み用のFPGA SoCからサーバー用FPGAカード、AWS上のクラウドサービスでも使うことが可能です。本稿執筆時のPYNQの最新バージョンは2.5.1です。本稿では組み込み用のFPGA SoCボードであるPYNQ-Z16 FPGAボードを元に説明します。PYNQセットアップ方法は公式ドキュメント7に詳しいですが、以下に簡単に説明します。
- PYNQ-Z1^pynq-z1を手元に用意します。必ず実機を用意してください。
※その他に有線LANケーブルとLANスイッチの空きポートが必要です。
※PYNQ-Z2やUltra96では一部の説明が異なりますが、大まかな開発法は同じです。 - PYNQのダウンロードから手元のFPGAボードに合うSDカードイメージをダウンロードします。
※Ultra96用のSDカードイメージはこちらで配布されています。 - ダウンロードしたイメージをSDカードに書き込みます。
※Etcherというイメージ書き込みソフトがおすすめです。 - SDカードを挿入し、電源ケーブルと有線LANを接続し、FPGAボードの電源を入れます。
- PCのブラウザから http://pynq:9090/ に接続して、Jupyter Notebookにアクセスできることを確認します。
※LAN環境によってはhostnameを解決できないことがあります。
※その場合は、DHCPからFPGAボードに割り当てられたIPアドレスを頑張って探します。
※http://:9090/ とすることでJupyter Notebookにアクセスできます。
PYNQを用いたFPGA設計のアウトライン
1. 高速化するターゲットの決定
これが最も重要なことです。どの計算を高速化するか決定します。FPGAでの設計を開始する前に、対象の計算がFPGAによってどのくらい高速化できるのか見積もりを立てることも重要です。本稿では簡単な行列積の高速化を例に設計法を説明します。
2. Vivado HLSによるC++設計
C++を用いて高速化したい計算の動作を記述します。この記述のことを計算カーネルと呼びます。Vivado HLSでは設計される回路パフォーマンスを見積もることができます。所定のパフォーマンスを満たすかこの段階で確認し、パフォーマンスを満たさない場合は計算カーネルの再設計が必要です。
3. Vivadoでの合成
Vivado HLSで設計した計算カーネルを、Vivadoを用いてFPGA回路へと合成します。この工程では周辺回路やクロック信号の接続を設計し、動作周波数などのパラメータを設定します。大規模な回路の設計ではVivadoを用いたFPGA回路の合成には数十時間から数日かかることがあります。簡単な行列積の高速化でも、合成時間には数十分かかります。しかし、多くの場合で、この工程が一回で完了することは稀です。
4. PYNQでのホスト記述
PYNQを用いてFPGA回路を制御するホストプログラムを記述します。FPGA回路化を行なった計算カーネルを呼び出して利用するための周辺プログラムが必要です。行列積の高速化の例では、画像ファイルなど行列データの読み書き、CPUとFPGA間のデータ転送、FPGA回路の制御、計算結果の検証などが必要となります。PYNQではホストプログラムを全てPythonで記述するため、開発コストが削減され、既存のPythonライブラリとの連携が容易になります。
Vivado HLSによる計算カーネルの設計
ターゲット計算を決める
ここから、FPGA回路を設計を開始します。本稿では実装が簡単な数値計算である行列積の高速化を行います。また数値型や数値計算精度を決める必要があります。FPGAの特徴として計算精度を柔軟に変更できる点が挙げられ、端数の精度や異なる精度の演算を定義することができます。今回の実装では符号付き16bit整数(short型)とします。Pythonの数値計算ライブラリNumpyで記述すると以下となります。高速化ターゲットは最後の一行 y = np.dot(x1, x2) に該当します。
import numpy as np
x1 = np.random.randint(-1000, 1000, size=(16, 16), dtype=np.int16)
x2 = np.random.randint(-1000, 1000, size=(16, 16), dtype=np.int16)
y = np.dot(x1, x2)
新規HLSプロジェクトの作成
- Vivado HLSを起動します。
Ubuntuでは、ターミナルで$ /tools/Xilinx/Vivado/2020.1/bin/vivado_hlsを実行します。
Windowsではアプリ一覧からVivado HLSを選択して起動します。 - 次の画面が表示されます。Create New Projectをクリックします。
 3. プロジェクト名を入力します。今回は `matrix-product` とし、Nextをクリックします。
3. プロジェクト名を入力します。今回は `matrix-product` とし、Nextをクリックします。
 4. 合成対象とするC++の関数名であるTop Functionを決めます。今回は `product` とし、Nextをクリックします。
Top Functionに指定した文字列は、PYNQライブラリからカーネルを呼び出す際に必要となります。
4. 合成対象とするC++の関数名であるTop Functionを決めます。今回は `product` とし、Nextをクリックします。
Top Functionに指定した文字列は、PYNQライブラリからカーネルを呼び出す際に必要となります。
 5. テストベンチを追加します。今回は何も追加しません。空欄のままNextをクリックします。
5. テストベンチを追加します。今回は何も追加しません。空欄のままNextをクリックします。
 6. ターゲットFPGAの情報を入力します。Part Selectionの右の[...]をクリックするとデバイス選択画面が表示されます。
PYNQ-Z1 / Z2の場合は以下のように `xc7z020clg484-1` を選択します。
Ultra96の場合は `xczu3eg-sbva484-1-e` を選択します。
6. ターゲットFPGAの情報を入力します。Part Selectionの右の[...]をクリックするとデバイス選択画面が表示されます。
PYNQ-Z1 / Z2の場合は以下のように `xc7z020clg484-1` を選択します。
Ultra96の場合は `xczu3eg-sbva484-1-e` を選択します。
 7. OKをクリックすると選択したデバイスが表示されています。Finishをクリックするとプロジェクトが作成されます。
その他にClockの設定がありますが初期値のまま続行します。これらの設定は後から変更することが可能です。
7. OKをクリックすると選択したデバイスが表示されています。Finishをクリックするとプロジェクトが作成されます。
その他にClockの設定がありますが初期値のまま続行します。これらの設定は後から変更することが可能です。

C++によるの計算カーネル作成
- カーネルを記述するC++ファイルを作成します。左側のメニューにあるSourceを右クリックし、New Fileを選択します。
 2. 作成するファイル名を `kernel.cpp` とします。ファイルの保存場所に指定はありません。OKをクリックします。
2. 作成するファイル名を `kernel.cpp` とします。ファイルの保存場所に指定はありません。OKをクリックします。
 3. プロジェクトに新規ファイルが追加されました。計算カーネルを記述します。以下のサンプルをコピーしてください。
プラグマ `#pragma HLS XXX...` によってVivado HLSのコンパイラに追加の指示を与えてます。
このサンプルでは、回路の制御方式 (port=returnの行) と、入出力引数のデータ転送方式を指示しています。
PYNQでFPGA回路を制御するためにはこれらのプラグマが必要となるため、忘れないようにしましょう。
3. プロジェクトに新規ファイルが追加されました。計算カーネルを記述します。以下のサンプルをコピーしてください。
プラグマ `#pragma HLS XXX...` によってVivado HLSのコンパイラに追加の指示を与えてます。
このサンプルでは、回路の制御方式 (port=returnの行) と、入出力引数のデータ転送方式を指示しています。
PYNQでFPGA回路を制御するためにはこれらのプラグマが必要となるため、忘れないようにしましょう。
void product(short x1[16][16], short x2[16][16], short y[16][16]) {
# pragma HLS interface s_axilite port=return
# pragma HLS interface s_axilite port=x1
# pragma HLS interface s_axilite port=x2
# pragma HLS interface s_axilite port=y
for (int i=0; i<16; i++) {
for (int j=0; j<16; j++) {
short t = 0;
for (int k=0; k<16; k++) {
t += x1[i][k] * x2[k][j];
}
y[i][j] = t;
}
}
}
HLS合成とレポート
- HLS合成を実行します。上部アイコンの右三角ボタン [▶︎] C Synthesisをクリックします。
 2. 以下のような合成レポートが表示されたら合成は成功です。合成結果に関する情報を見ることができます。
Performance Estimatesでは計算カーネルのパフォーマンスの見積もりを見ることができます。
Latencyの項目にサイクル数と実行時間の見積もりが表示されています。
今回の計算カーネルの実行には8737クロックサイクルが必要で、87.370マイクロ秒の時間がかかることがわかります。
レポートを閉じてしまった場合、上部アイコンのOpen Report (C Synthesisの3つ右) から合成レポートが開けます。
2. 以下のような合成レポートが表示されたら合成は成功です。合成結果に関する情報を見ることができます。
Performance Estimatesでは計算カーネルのパフォーマンスの見積もりを見ることができます。
Latencyの項目にサイクル数と実行時間の見積もりが表示されています。
今回の計算カーネルの実行には8737クロックサイクルが必要で、87.370マイクロ秒の時間がかかることがわかります。
レポートを閉じてしまった場合、上部アイコンのOpen Report (C Synthesisの3つ右) から合成レポートが開けます。
 4. IPコアを作成します。上部アイコンのExport RTL (C Synthesisの2つ右) をクリックします。
IPコアとはFPGA回路を合成するための回路情報と入出力データの通信方式が含まれるパッケージです。
HLS合成したカーネルをVivadoから呼び出すためにIPコアの形式を経由します。
4. IPコアを作成します。上部アイコンのExport RTL (C Synthesisの2つ右) をクリックします。
IPコアとはFPGA回路を合成するための回路情報と入出力データの通信方式が含まれるパッケージです。
HLS合成したカーネルをVivadoから呼び出すためにIPコアの形式を経由します。
 5. Export RTLの画面が表示されたら、デフォルトの設定のままOKをクリックしてIPコア(IPカタログ)を作成します。
Vivado HLSでの作業は以上になります。
5. Export RTLの画面が表示されたら、デフォルトの設定のままOKをクリックしてIPコア(IPカタログ)を作成します。
Vivado HLSでの作業は以上になります。

Vivadoを用いた回路合成
次に、FPGA回路を合成するためのVivadoプロジェクトを作成します。
HLSによる開発では、Vivadoを用いてHLS設計したIPとベンダーに用意されている設計済みIPの配置と配線を行います。
新規Vivadoプロジェクトの作成
- Vivadoを起動します。
- プロジェクトを作成します。
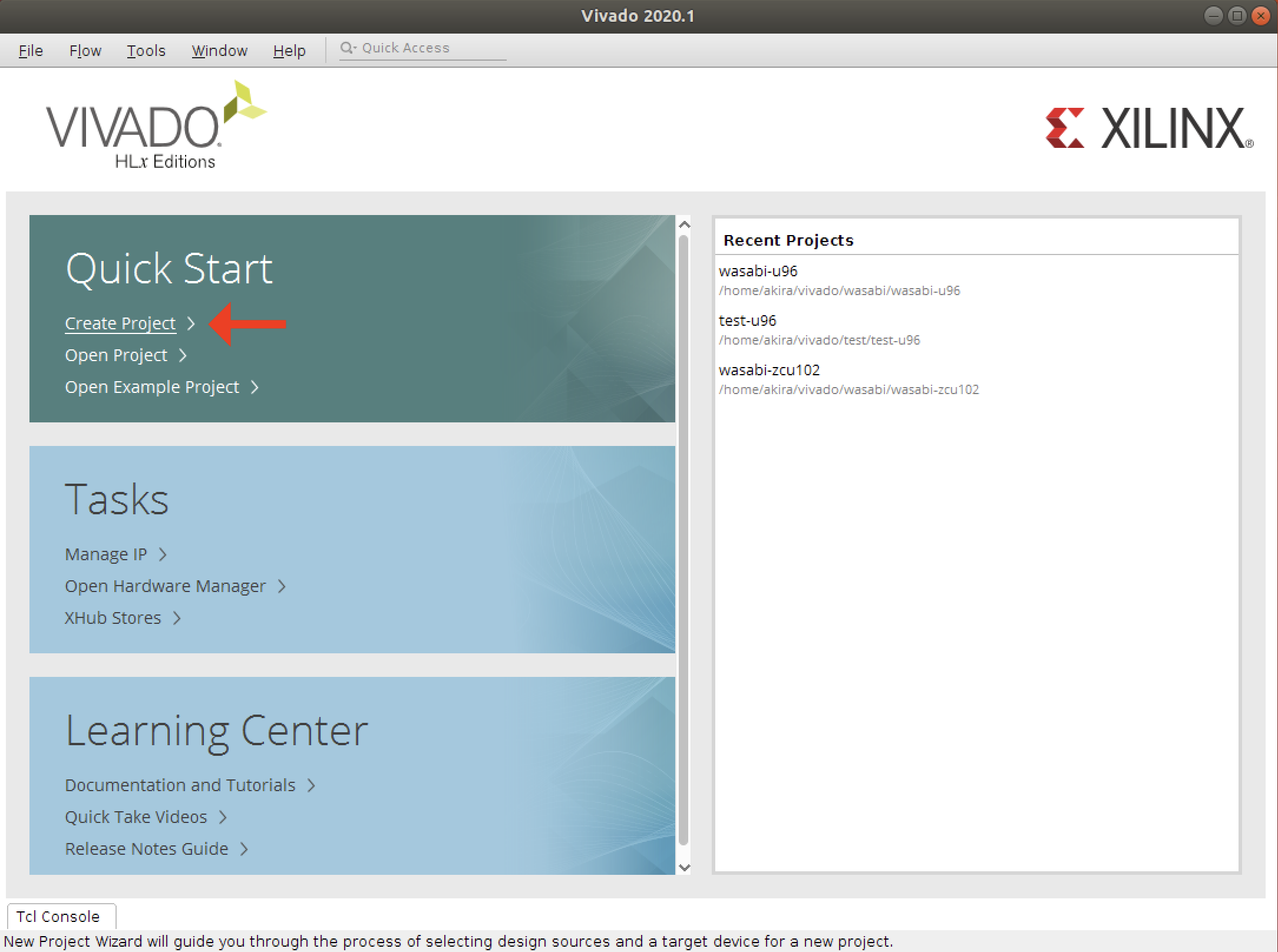 2. 次の画面が表示されます。Nextをクリックします。
2. 次の画面が表示されます。Nextをクリックします。
 2. 次のように記入してNextをクリック。
2. 次のように記入してNextをクリック。
 2. そのままでNextをクリック。
2. そのままでNextをクリック。
 2. そのままでNextをクリック。
2. そのままでNextをクリック。
 2. そのままでNextをクリック。
2. そのままでNextをクリック。
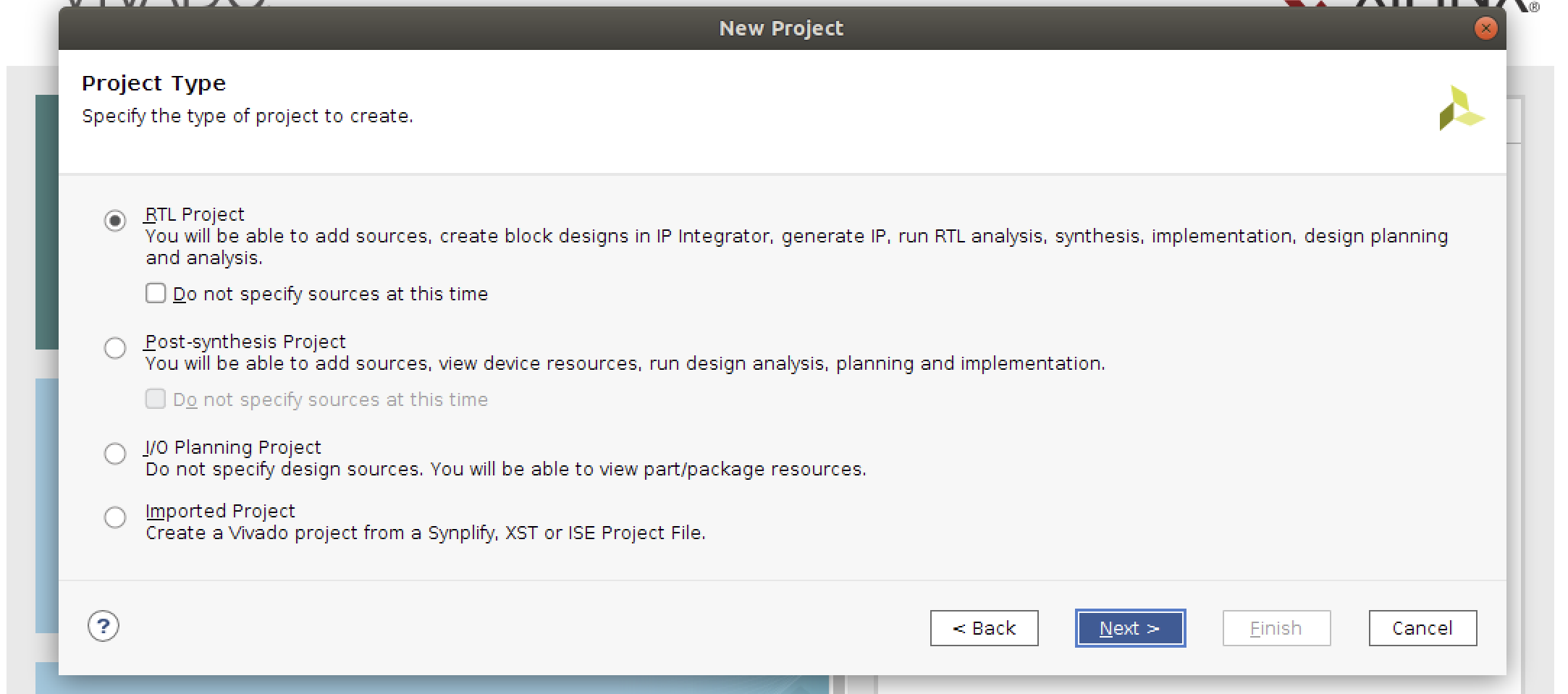
 1. パーツにxc7z020clg484-1を選択して、Nextをクリック。
1. パーツにxc7z020clg484-1を選択して、Nextをクリック。
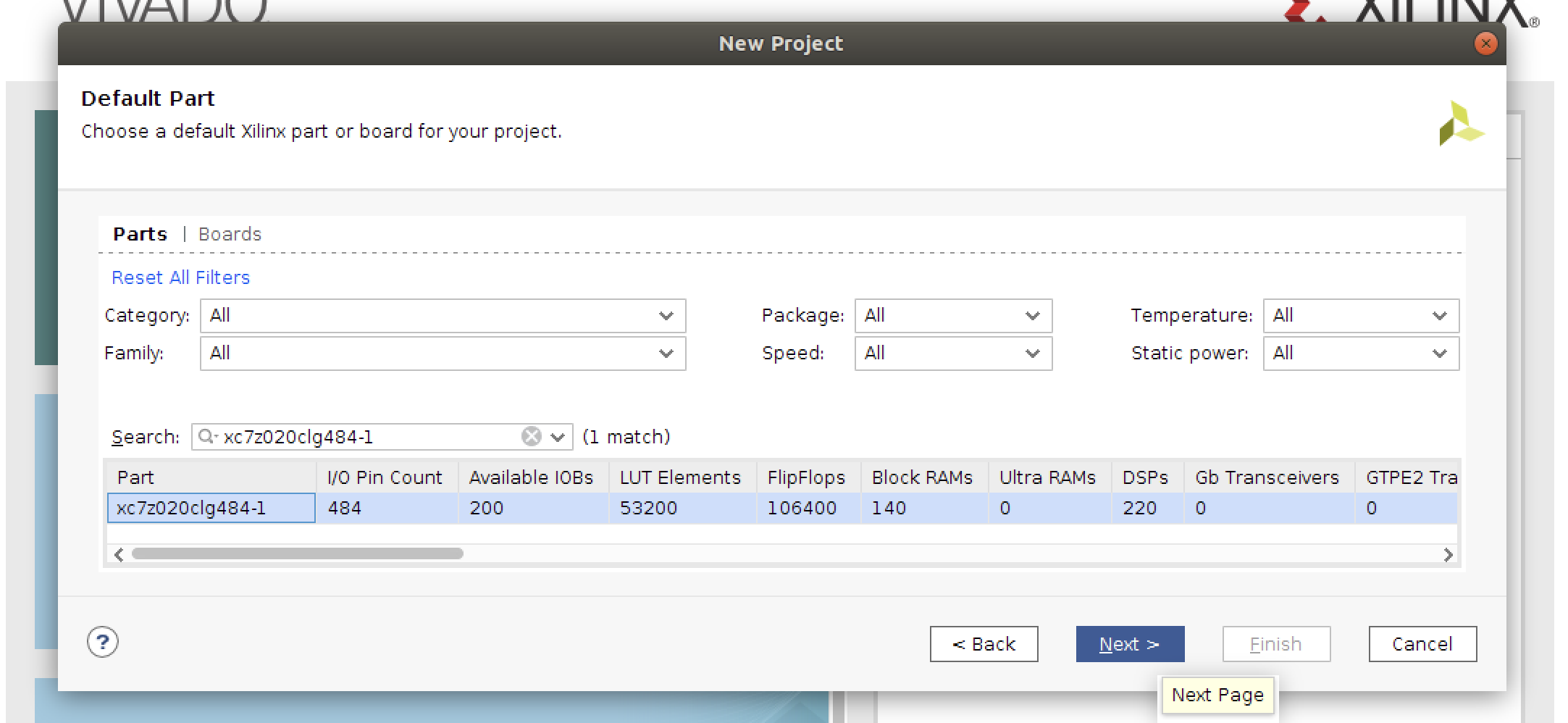 1. Finishをクリックするとプロジェクトが作成されます。
1. Finishをクリックするとプロジェクトが作成されます。

IP設計
- ブロックデザインを作成します。
IP INTEGRATORのCreate Block Designをクリックします。
 2. OKをクリック。
2. OKをクリック。
 3. Vivado HLSで作成したIPコアを追加します。
上部の歯車アイコンからSettingを開きます。
3. Vivado HLSで作成したIPコアを追加します。
上部の歯車アイコンからSettingを開きます。
 1. IPのRepositoryタブを開いて、ブラスボタンをクリックします。
1. IPのRepositoryタブを開いて、ブラスボタンをクリックします。
 1. HLS設計で作成したプロジェクトを選択します。
1. HLS設計で作成したプロジェクトを選択します。
 1. IPsの右の数字が1となっていれば、HLS設計したIPが認識されています。
1. IPsの右の数字が1となっていれば、HLS設計したIPが認識されています。
 1. OKをクリックして設定を閉じます。
1. OKをクリックして設定を閉じます。
 1. ハードコアされたARM CPUを認識するためのIPコアを追加します。
Diagramの中のプラスボタンから、図のようにZYNQを選択します。
1. ハードコアされたARM CPUを認識するためのIPコアを追加します。
Diagramの中のプラスボタンから、図のようにZYNQを選択します。
 1. 同様にHLSで設計したIPを追加します。
HLSの関数名と同じ、Productとなっています。
1. 同様にHLSで設計したIPを追加します。
HLSの関数名と同じ、Productとなっています。
 1. 二種類のAutomationを実行します。
1. 二種類のAutomationを実行します。
 1. バリデーションを実行して、エラーがないことを確かめます。
1. バリデーションを実行して、エラーがないことを確かめます。

 1. 最後に、ラッパーRTLを作成します。
1. 最後に、ラッパーRTLを作成します。


回路合成と成果物
- 回路合成を行います。合成は数十分かかります。
左部メニューのGenerate Bitstreamをクリックし、ポップアップのOKをクリックします。
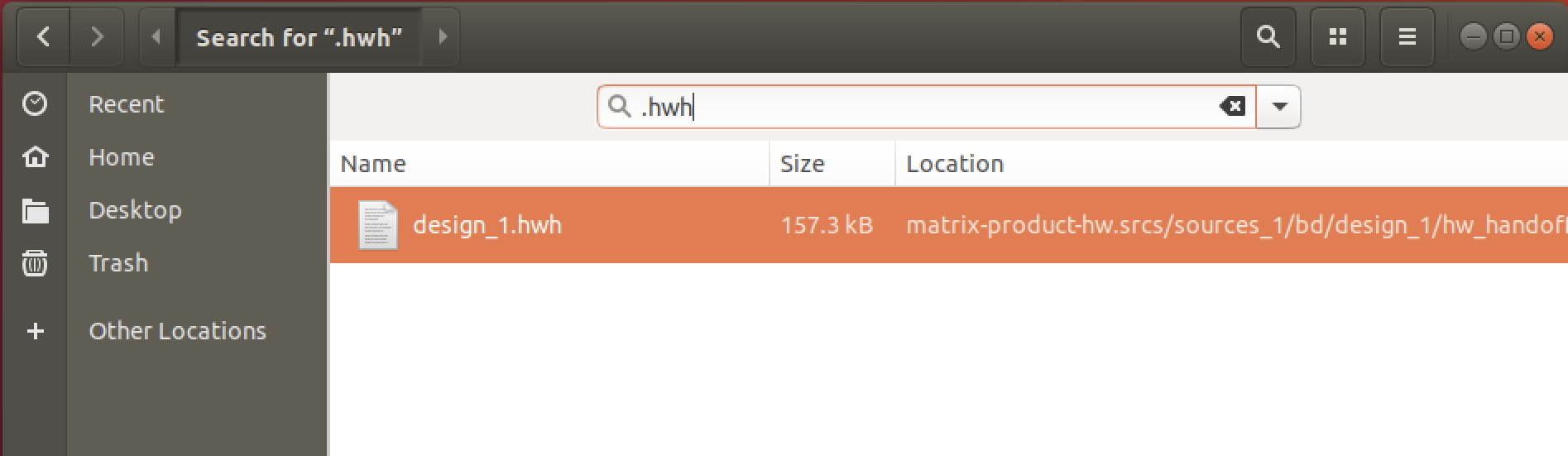
 2. 合成結果の成果物として.bitと.hwhファイルが生成されます。
FinderからVivadoプロジェクトのディレクトリを開いてファイル名で検索すると簡単に見つかります。
分かりやすいディレクトリにコピーしておきます。
Vivado環境での作業は以上です。
2. 合成結果の成果物として.bitと.hwhファイルが生成されます。
FinderからVivadoプロジェクトのディレクトリを開いてファイル名で検索すると簡単に見つかります。
分かりやすいディレクトリにコピーしておきます。
Vivado環境での作業は以上です。


PYNQでホストプログラムを書く
次に、FPGA回路を制御するホストプログラムを記述します。
実際にFPGAで数値計算を実行します。
Jupyter Notebookの作成とホストプログラムの記述
- PCのブラウザからJupyter Notebookにログインします。デフォルトパスワードはxilinxです。
 3. 作業用ディレクトリを作成し、作成したディレクトリに移動します。
3. 作業用ディレクトリを作成し、作成したディレクトリに移動します。
 4. design_1_wrapper.bitとdesign_1.hwhをアップロードします。
design_1_wrapper.bitをdesign_1.bitにリネームしておきます。
4. design_1_wrapper.bitとdesign_1.hwhをアップロードします。
design_1_wrapper.bitをdesign_1.bitにリネームしておきます。
 5. 新しいNotebookを作成します。
5. 新しいNotebookを作成します。
 6. 以下のサンプルプログラム1を記述して実行する。
テキストエリアにコピペしてください。
実行にはRunをクリックするか、Shift+Enterを入力します。
JupyterNotebookでは`%time`を使うことで簡単に処理速度を計測できます。
6. 以下のサンプルプログラム1を記述して実行する。
テキストエリアにコピペしてください。
実行にはRunをクリックするか、Shift+Enterを入力します。
JupyterNotebookでは`%time`を使うことで簡単に処理速度を計測できます。


import pynq
import numpy as np
# 合成した回路をPYNQを通じてFPGAに書き込む
ol = pynq.Overlay('./design_1.bit')
mmio = ol.product_0.mmio
# Memory Mapped I/Oを通じてNumpyインターフェイスでAXI LITEレジスタにアクセスできる
# Numpyのアクセス幅が32bit整数であるため、アドレスを32bit/8bit(1byte)=4で割る
def ndarray_from_mmio(name, size, dtype):
reginfo = ol.ip_dict['product_0']['registers'][name]
addr_start = reginfo['address_offset'] // 4
addr_end = addr_start + reginfo['size'] // 4
mmio_array = mmio.array[addr_start:addr_end]
mmio_array.dtype = np.int16
return mmio_array.reshape(size)
mmio_x1 = ndarray_from_mmio('Memory_x1', size=(16, 16), dtype=np.int16)
mmio_x2 = ndarray_from_mmio('Memory_x2', size=(16, 16), dtype=np.int16)
mmio_y1 = ndarray_from_mmio('Memory_y', size=(16, 16), dtype=np.int16)
DONE = 0x02
def mydot(x1: np.ndarray, x2: np.ndarray) -> np.ndarray:
# 入力データを書き込む
mmio_x1[:] = x1
mmio_x2[:] = x2
# 回路の動作開始の指示
mmio.write(0, 1)
# 回路が終了するのを待つ
while not mmio.read(0) & DONE: pass
# 結果を返す
return mmio_y1.copy()
x1 = np.random.randint(-1000, 1000, size=(16, 16), dtype=np.int16)
x2 = np.random.randint(-1000, 1000, size=(16, 16), dtype=np.int16)
y_true = np.dot(x1, x2)
y_test = mydot(x1, x2)
print('Validation:', np.all(y_true == y_test))
print()
print('=> Running 1000 times on CPU')
%time for i in range(1000): _ = np.dot(x1, x2)
print()
print('=> Running 1000 times on FPGA')
%time for i in range(1000): _ = mydot(x1, x2)
考察
この時点ではCPUでの処理よりもFPGAの処理は遅くなってしまってます。
考えられる原因として次のようなものがあります。
- 転送が遅い。
入出力データの転送として、AXI LiteプロトコルをMemory Mapped IOを用いたCPU制御で実現しています。
より高速な転送方法としてAXI Streamプロトコルが挙げられます。
AXI Streamメモリ連続アクセスに対応し、FPGAからDRAMに直接アクセスアクセスできるため、高速なデータ転送を実現できます。 - 制御のオーバーヘッドが大きい。
今回高速化した関数は16×16の行列積であり、そもそもそんなに計算量が多くありません。
この規模の計算では、FPGAにオフロードするための制御のオーバーヘッドが大部分を占めてしまいます。 - そもそも回路が並列化されていない。
今回の設計では一切並列化を行なっていません。
100MHzで動作する並列化されていないFPGA回路より、1000MHz程度で動作するCPUの方が明らかに高速に処理できてしまいます。
より高パフォーマンスな動作のために
ここまでの説明で、PYNQを用いたFPGA回路のHLS設計の基本について説明しました。
ここからは、今回の実装のさらなる高速化の方法を説明します。
Vivado HLS編
以下に、並列化を施したサンプルコードを載せておきます。
高速化のために対象の計算を少し変更しました。
N×16行列と16×16行列の計算を行います。
計算の変更は、制御のオーバーヘッドの問題を解消するために行います。
HLS実装では、プラグマを用いて回路の並列設計などを支持します。
#pragma HLS PIPELINE, UNROLL, ARRAY_PARTITIONなどが該当します。
ここでプラグマの詳細な動作についての説明は省略します。
# include <ap_int.h>
# include <hls_stream.h>
struct DataBus {
ap_int<256> data;
ap_uint<1> last;
};
void product(short w[16][16], hls::stream<DataBus> &x, hls::stream<DataBus> &y) {
# pragma HLS INTERFACE s_axilite port=return
# pragma HLS INTERFACE s_axilite port=w
# pragma HLS INTERFACE axis port=x
# pragma HLS INTERFACE axis port=y
# pragma HLS ARRAY_PARTITION variable=w dim=0
while (true) {
# pragma HLS pipeline
short xx[16];
# pragma HLS ARRAY_PARTITION variable=xx
short yy[16];
# pragma HLS ARRAY_PARTITION variable=yy
// read input data
DataBus src = x.read();
for (int i=0; i<16; i++) xx[i] = short(src.data >> 16*i);
// matrix product
for (int j=0; j<16; j++) {
# pragma HLS UNROLL
short t = 0;
for (int k=0; k<16; k++) t += xx[k] * w[k][j];
yy[j] = t;
}
// write output
DataBus dst;
dst.data = 0;
for (int i=0; i<16; i++) dst.data |= ap_uint<256>(yy[i]) << 16*i;
dst.last = src.last;
y.write(dst);
if (src.last) break;
}
}
また、高速化のためにクロック周波数を変更します。
と言っても、CPUのように高速化はできず、Z1ボードでは200MHzくらいが妥当です。
以下のような手順で対象のクロック周波数を変更できます。
なお、周波数ではなく周期(200MHz => 5ns)を指定します。



最後に、三角ボタンでHLSの合成を行います。
また、IPコアのエクスポートを忘れずに。
Vivado編
AXI Streamを用いた通信を実装します。
ブロックデザインでDMAを追加します。
配線はドラッグアンドドロップ
クロック周波数を200MHzに変更します。
詳しい説明は省略しますが、図のように進めるとブロックデザインが完成します。















ブロックデザインの合成が終わったら、GenerateBitstreamから合成を開始します。
先の例と同様に、成果物の.bitと.hwhファイルをコピーして、ブラウザを通してFPGAにアップロードしてください。
なお、ファイル名はそれぞれdesign_2.bitとdesign_2.hwhとしてください。
PYNQホスト編
DMA転送に対応したホストプログラムです。
コピペして実行してください。
CPUよりFPGAは約3倍高速化されています。
import pynq
import numpy as np
# 合成した回路をPYNQを通じてFPGAに書き込む
ol = pynq.Overlay('./design_2.bit')
mmio = ol.product_0.mmio
# pragma HLS array_partitionの影響でアドレス配置が変更された
# プラグマの指定によって適宜変更する必要がある。
# アドレスはVivado HLSの Solution>Impl>misc>Drivers>src>xxx_hw.hで見ることができる
mmio_w = mmio.array[0x010//4:0x810//4]
mmio_w.dtype = np.int16
mmio_w = mmio_w.reshape(16, 16, 4)[:,:,0]
# AXI DMAを使ってメモリ転送を行う
dma_x = ol.axi_dma_0.sendchannel
dma_y = ol.axi_dma_0.recvchannel
# 大量のデータを処理
N = 30000
buff_x = pynq.allocate(shape=(N,16), dtype=np.int16)
buff_y = pynq.allocate(shape=(N,16), dtype=np.int16)
DONE = 0x02
def mydot(x: np.ndarray) -> np.ndarray:
# 入力データを書き込む
buff_x[:] = x
# DMA転送を開始する
dma_x.transfer(buff_x)
dma_y.transfer(buff_y)
# 回路の動作開始の指示
mmio.write(0, 1)
# 回路が終了するのを待つ
while not mmio.read(0) & DONE: pass
# 結果を返す
return buff_y.copy()
x = np.random.randint(-1000, 1000, size=(N, 16), dtype=np.int16)
w = np.random.randint(-1000, 1000, size=(16, 16), dtype=np.int16)
# 固定パラメータを書き込む
mmio_w[:] = w
# 動作周波数を設定する
pynq.Clocks.fclk0_mhz = 200
y_true = np.dot(x, w)
y_test = mydot(x)
print('Validation:', np.all(y_true == y_test))
print()
print('=> Running on CPU')
%time _ = np.dot(x, w)
print()
print('=> Running on FPGA')
%time _ = mydot(x)
PYNQライブラリはPythonのオーバーヘッドが存在するため、
秒間100回を超えてくるとPythonに起因する遅延が問題となってきます。
サンプルでは高速化のためにmmio.arrayに直接アクセスしていますが、
PYNQライブラリでは実際はmmio.writeメソッドを使った読み書きが推奨されます。
メモリアライメントに気をつけないと、Ubuntuがクラッシュします。
また、例えば、dmaの.transfer()はオーバーヘッドの大きい処理です。
このオーバーヘッドは、メモリを直叩きすることで解消されます(サンプルでは説明していません)
黒魔術ですね。
おわりに
以上で、PYNQを用いたFPGAのHLS設計のチュートリアルを終了します。
みなさんが、楽しい、アットホームな、FPGA設計ライフを送ることを期待して。
この資料は研究室内の勉強会のために作成した資料の焼き直しです。
説明の終盤が雑になってしまっています。
間違いや誤植があれば気軽に報告していただけると助かります。
あなたが次にすべきこと
- この行列積プログラムをもっと高速化する
- Vivado HLSの設計方法について勉強する
- PYNQライブラリについて勉強する
- 既存のHLS実装を見て学ぶ
- いろんな計算を実装する(FIRフィルタ, テキストマイニングなど)