資料の紹介
Autonomous AI Databaseカタログは、現在接続しているAutonomous AI Database内のデータおよびその他のオブジェクト、および様々な接続済システム内のデータを検索する方法を提供するマルチカタログ・ツールです。
カタログ・ツールを使用すると、クラウド内のどこからでも、接続されたデータ・アセットを検索、検索、ロードまたはリンクできます。また、他のシステムに新しいカタログをマウントし、接続されたAutonomous AI Databaseでデータやその他のアイテムを検索することもできます。
カタログ・ツールを使用して、次の新しいカタログをマウントできます。
- テナンシ内の他のAutonomous AI Database。
- DBリンクを使用して接続できるその他のデータベース(たとえば、Autonomous AI Databaseが接続できるオンプレミス・データベース)。
- 共有データ(たとえば、デルタ共有を使用してDataBricksから共有されるデータ)。
- AWS GlueやOCI Data Catalogなどの既存の外部データ・カタログ。
本資料では、AWS Glueにマウント手順をご紹介します。これにより、AWS Glueを利用したSnowflakeなどの外部表のデータもクエリできます。
アーキテクチャ
次に示した図が、今回構築したアーキテクチャの概要です。
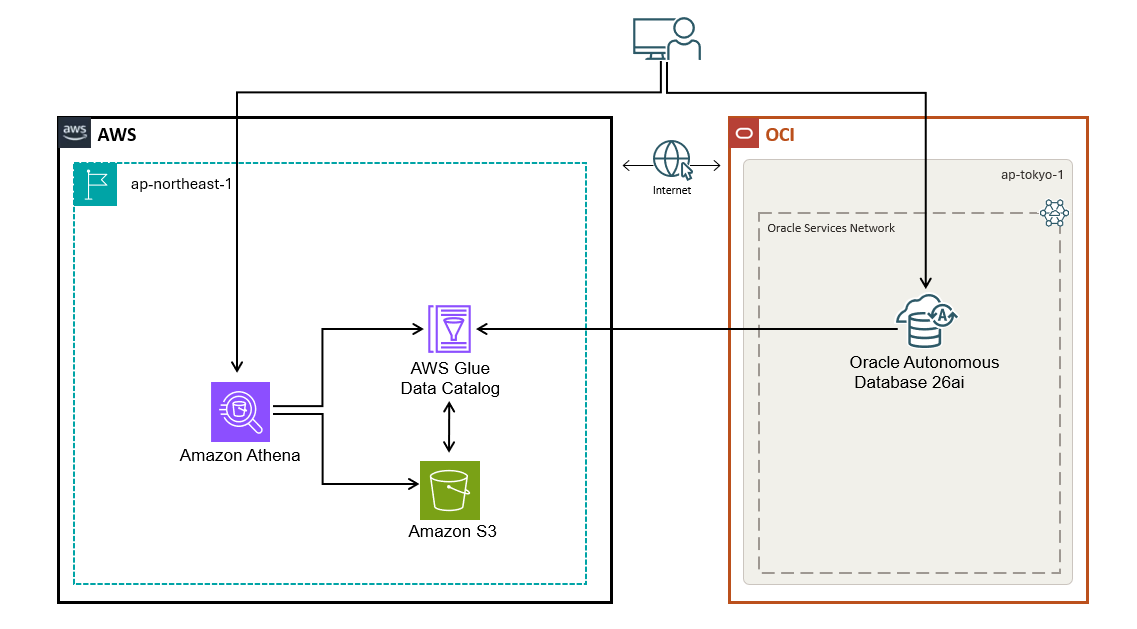
- AWS側で、ユーザーは Athena から SQL 文を実行して、iceberg表を作成して、データをインサートします。これにより、S3バケットにデータが保存され、Glueカタログに表のメタデータが保存されます。
- Oracle OCI側で、Oracle AI Database 26aiのCatalogを利用して、Glueへアクセスし、作成したiceberg表のデータを確認できます。
事前準備
Glueでiceberg表を作成して、データを追加します。
まず、データを保存するS3を準備します。
- AWSコンソールにログインして、S3を選択します。

- 「Create Bucket」をクリックします。

- Bucket名を入力して、「Create」ボタンをクリックします。

- 作成したBucket名をクリックして、ポリシーを設定します。

- 「Permissions」を選択します。

- 下記の部分を自分の環境に合わせて変更してから、Bucket Policyに上書きします。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowAthenaAndGlueAccess", "Effect": "Allow", "Principal": { "Service": [ "athena.amazonaws.com", "glue.amazonaws.com" ] }, "Action": [ "s3:GetObject", "s3:PutObject", "s3:ListBucket", "s3:DeleteObject" ], "Resource": [ "arn:aws:s3:::<bucket-name>", "arn:aws:s3:::<bucket-name>/*" ] } ] }
次は、Glueデータベースを準備します。
- AWSコンソールにログインして、Glueを選択します。

- 「Add Database」をクリックします。

- 任意のDatabase名を入力して、「Create database」をクリックします。

最後は、AWS Athenaにログインして、表を作成して、データを格納します。
-
AWSコンソールにログインして、Athenaを選択します。

-
「Launch query editor」をクリックします。
-
「Edit settings」ボタンを選択します。

-
作成したS3のBucketを選択します。

-
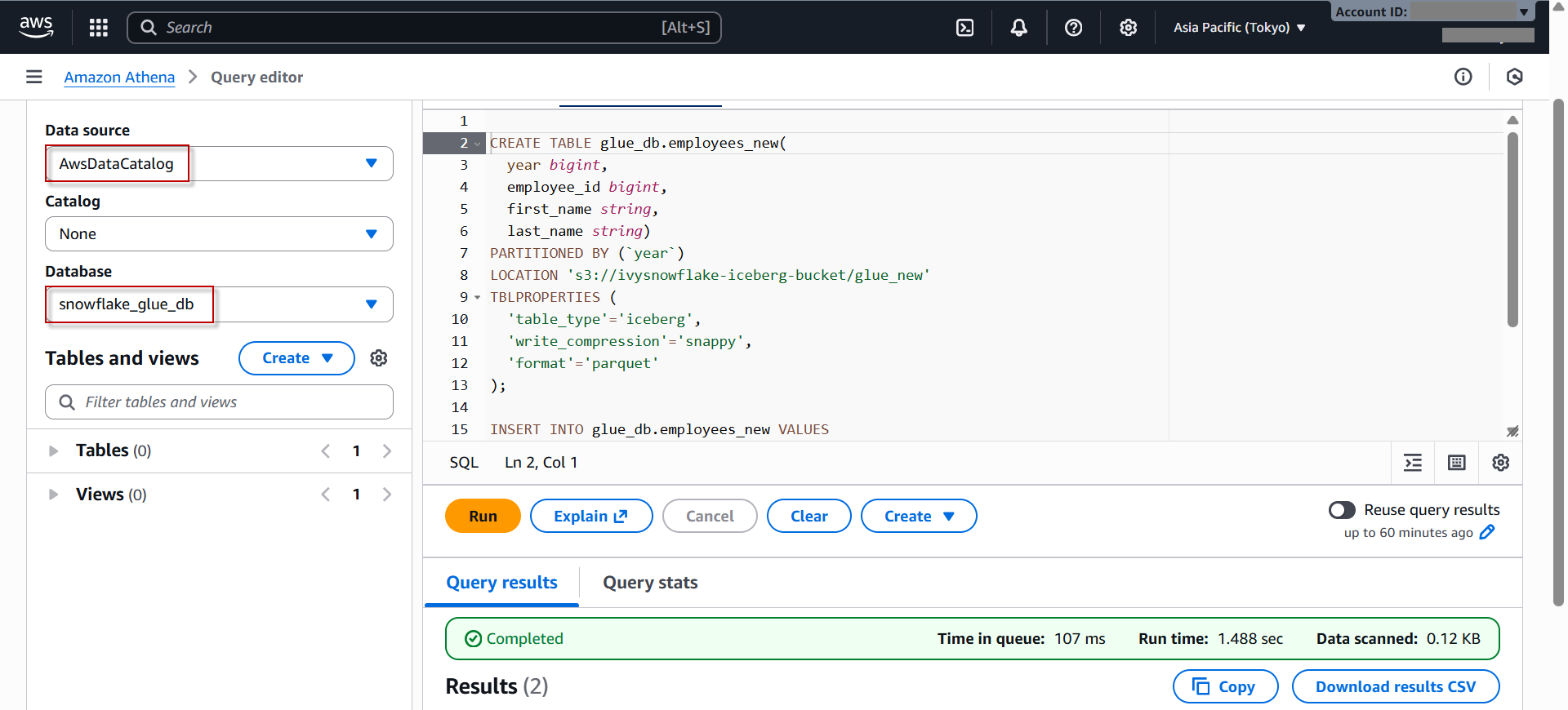
左側でデフォルトのData source「AwsDataCatalog」を選択して、作成したGlueデータベースを選択します。
-
以下のSQL文を入力して、実行します。これにより、iceberg表を作成して、データを挿入し、確認します。
CREATE TABLE glue_db.employees ( year bigint, employee_id bigint, first_name string, last_name string) PARTITIONED BY (`year`) LOCATION 's3://ivysnowflake-iceberg-bucket/glue' TBLPROPERTIES ( 'table_type'='iceberg', 'write_compression'='snappy', 'format'='parquet' );INSERT INTO glue_db.employees VALUES (2024, 1, 'John', 'Doe'), (2024, 2, 'Jane', 'Smith');SELECT * FROM glue_db.employees; -
以上で、Glue側の準備を完了します。S3でメタデータと表のデータを確認できます。またGlueで表のメタデータも確認できます。


Oracle Autonomous AI Databases CatalogでGlueへのマウント
- Autonomous AI Databasesのページで、「ツール構成」→「データベース・アクション」のURLをコピーして、ブラウザで開きます。ここで、ADMINユーザーで登録します。

- 「Data Studio」タブで、「Catalog」メニューを選択します。

- 「Catalogs」→「Manage」を選択して、「Add」をクリックします。

- 「Amazon Glue」を選択して、「Next」をクリックします。

- 「Create Credential」ボタンをクリックします。
Credential名を入力して、Cloud Service「Amazon S3」を選択して、AWSのaccess key IDとsecret access keyを入力します。「Create Credential」ボタンをクリックします。AWSのaccess key IDとsecret access keyはAWSのConsoleで取得します。

- 作成したCredentialを選択して、AWSのリージョンを選択して、「Next」をクリックします。

- 任意のカタログ名を入力して、「Add」をクリックします。

- 「Catalogs」をクリックして、作成したGlueのカタログをチェックして、「Apply」をクリックします。

- Glue中の表が表示されます。表をクリックします。

- Glue表のデータを確認できます。
