AWS re:Invent 2014でDatadogの展示スタッフとしてブースに立ち、NYCオフィスで開発を担当しているエンジニアさん達のデモ内容を3日間見ていると、自分が持っていたDatadogの利用イメージが幼稚であったことをつくづく実感しました。この感覚が薄れる前に、学んだことを書き残しておくことにします。
Datadogは、OPSの視界を確保する!
一般的にDatadogは、綺麗なグラフが書けるモニタリングSaaSだと思っている人が多いと思います。しかし、実際はそれだけではないです。(実際にグラフ描写だけで考えると圧倒的に綺麗なのは間違いないけど…。)むしろDatadogというサービスは、いま自分たちが運用しているシステム全体の状況をtagを使って多次元に解析できるフレームワークと考えたほうが良いと思います。したがって、Datadogのサービスから価値を引き出すには、tagを使いこなすことがキーポイントになります。
このtagの有効活用は、今までのモニタリング・サービス/ツールからは数段進化した概念になると考えたほうがいいと思います。
全てのメトリクスには、モニタリング値の他に各種のtagが付加され保存され、人間がシステムに対し適応する変更や外部のサービスから送られる情報はeventとして類似のtagが付与され保存されていきます。この属性の異なる2つの情報を同一画面の表示しながら問題となりそうなイベントをドリルダウンすることができるのです。
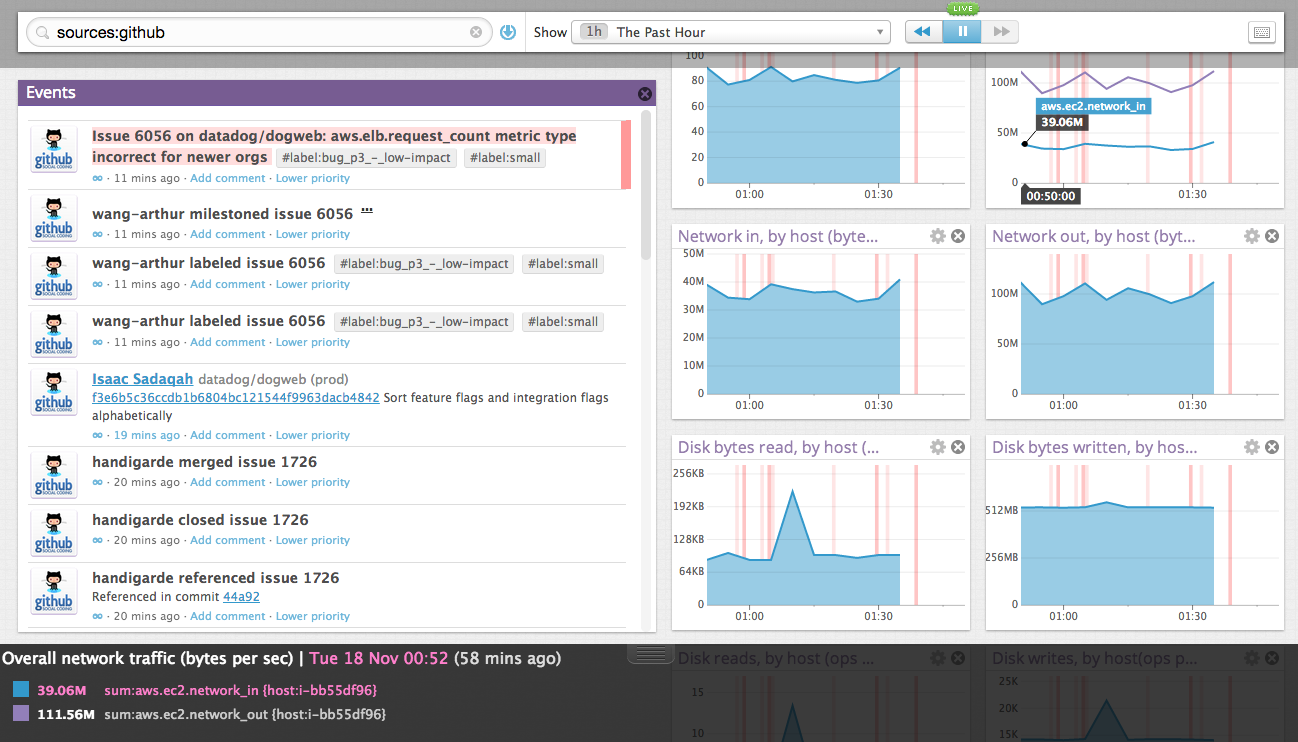
画面右側のグラフ上にあるピンクの線は、左側にあるイベントストリーム内の各イベントの発生タイミングに連動して書き込まれており、イベントとグラフの変化が一目瞭然の関係なっています。言い換えれば、ドクターが患者の開腹手術をする前に、レントゲン、CT、MRI、心電図、血液検査などの各種検査をしたのち、蓄積した情報を関連付け手術手順を検討してから手術に臨むように、どこの部分をどのように対策すればよいか事前にしっかりと検討してから、各サーバ上での変更をスタートることができるということになります。
サービス/ロールの概念は、tag付けによって日常的かつ柔軟に。
類似モニタリングサービスの解説によるとサービス/ロールによるインスタンスの分類や積み上げグラフの重要性が強調されているのを見かけますが、DatadogでもTag付けによってこれらのサービス/ロールによる分類や積み上げグラフ生成は簡単かつ日常的に実施されています。これらはむしろtagの利用方法の初級的な機能かもしれません。
例えば、サービス/ロールの積み上げグラフは:
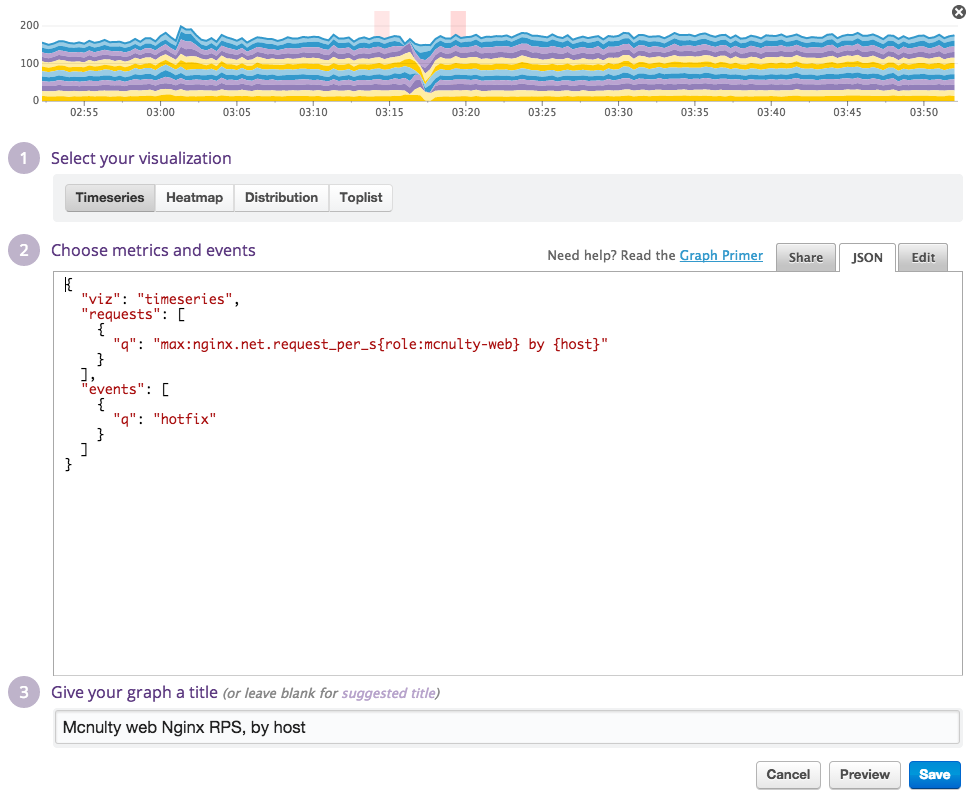
のようにクエリの書き方次第で、どのような内容の積み上げグラフでも描けてしまいます。またクエリの書き方によっては、それぞれの要素をオーバーレイしてグラフ化することもでますし、メトリクス同士の各種演算処理をすることもできます。更に、グラフの表現方法に関しても、'時系列折れ線', 'ヒートマップ', '分布図', '上位リスト'など、それらのグラフにふさわしい表現を選択するだけにもなっています。(これって、地味に強力な機能ではないでしょうか?)
森を見て、木をも見る自由度。
クラウド時代にインフラを管理していく上で重要なのが、"ホストのクラスタ"を見て、単一ホストも見る自由度ということになると思います。
インフラ内で稼働しているインスタンス数が時間と共に変化し、各ホストが協調して動作している状況では、クラスタ全体としての状況変化を瞬時に把握することは、非常に重要になるはずです。その上で状況変化をもたらしている原因を分析する過程では、クラスタを構成しているホストの状況情報を詳しく見ていく必要も出てくるでしょう。
すでにDatadogが持っているtag付け機能は、この様な状況下で最大の威力を発揮すると思います。
- tagの組み合わせにより、クロスメトリスのダッシュボードを自由自在に作成し、お好み登録。
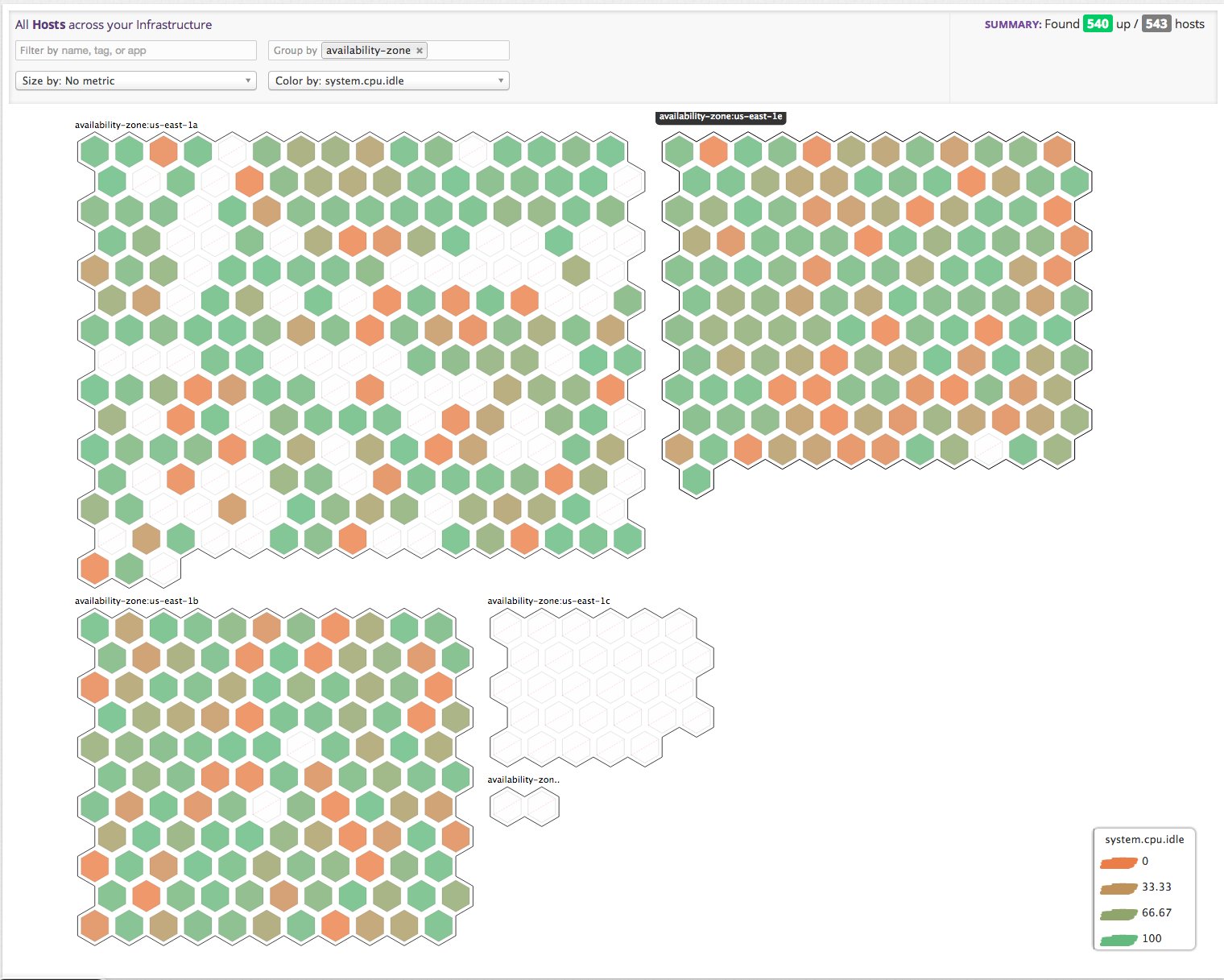
- tagの組み合わせによりシステムの構成要素をダイナミックにクラスタ化し、可視化&ドリルダウン。
- tagの組み合わせにより、イベントストリームとグラフを使ったドリルダウン。
関連サービスとの豊富な連携機能。
Datadogには、80種を超えるIntegrationが既に準備されています。(毎月2~3個のIntegrationが追加されている)
その中には、ミドルウェアのメトリクスを収集するもの以外に、他のサービスと連携するためのIntegrationが多々あります。
例えば:
- Service Input
- github & bitbucket
- chef & puppet
- New Relic, Nagios, splunk
- fastly
- etc.
仮に他のモニタリングSaaSを使っていても、このIntegration機能を使って最低限必要な情報をDatadog側に統合し、他のメトリクスと合わせて同一画面で状況を判断するベースにすることができます。
- communication Output
- HipChat
- slack
- pagerduty
- campfire
- etc.
"@"マークの後に出力したい先を指定すれば、さらなるコミュケーション経路が簡単に選択でき、相手の状況に合わせたコミュニケーションチャネルが確立できる。
これらのコミュニケーションチャネルの出力されたグラフをクリックすれば、即座にダッシュボード上の該当グラフに移動でき、そこからドリルダウンを始めることができる。
物理サーバー環境とクラウド環境が混在する環境でも一括モニタリング。
Datadog Agentは、クラウドインスタンス、ベアメタルクラウド、物理サーバーと区別なくインストールすることができます。物理サーバー用に既に導入済みのNagiosの情報も取り込めるように、Integrationも公式に公開されています。(勿論、Nagiosで監視されている物理サーバーにDatadog Agentをインストールすることもできます) 異なるインフラにまたがるメトリクスの情報を統合してモニタリングすることができます。また物理サーバーシステムのクラウド移行の際も、Datadog Agentインストールと必要最低限のtag情報の設定のみで、今まで通りにモニタリングが継続できます。
自分たちで使っているので、必要なものがわかる。
Datadogでは、自分たちのサービスを運用のワークフローに取り込んで実際に使っています。(他のサービスも併用している部分もありますが…)
日常的に、ダッシュボードを表示したモニターの前でミーティングが始まります。僕が、この投稿を書いている横にある大型モニターの前で、社員が足を止め随時モニターを眺めていたりします。

運用チームのデスクでは、それぞれの独自に設定したダッシュボードが表示され、作業を進めています。社内でコミュニケーションのために使っているHipChatには、時折アラートが飛んできて、運用関係者と開発関係者の議論がその場ではじまります。そのデスクトップでは先に紹介した、イベントストリームとグラフを表示した画面でドリルダウンをしていたりします。
最後の最後は、自分で試すしかない。
僕は、3年以上に渡りDatadogを使ってきました。しかし、独自のメトリクスを送り込み、自分専用のダッシュボードを作り、モニター表示し、アラートを出すところまでで満足していました。"システム運用にはモニタリングが不可欠"といいつつDatadogの本当に価値のある部分を見過ごしてきました。DatadogのCTOのAlexisとの会話の中では何度も出てきた内容なのですが、実際にDatadog内で日常的におこなわれているドリルダウンを目の当たりにし、Tagを使って意味のあるグラフを書き始めるまでは、その重要性に気がつきませんでいた。
「本当に恥ずかしい!」と思いました。
どんなに素晴らしい機能やドリルダウン手順も実際に自分で試してみるまでは、簡単に腑に落ちないものです。
もしもこの投稿を読んでDatadogの本当の魅力について知りたいと思うなら、signupページからフリートライアルに申し込んでみてください。きっと僕がここに投稿している意味を理解してもらえると思います。