なぜKaggleをやったのか
たまに仕事でPythonに接する機会がありましたが、
Pythonは様々なLibraryがあることに気づき、興味を持つことになりました。
そして、たまたまKaggleというコンテンツに惹かれて、
漠然としてチャレンジしてみたいと思いました。
Kaggleとは
簡単に言うと、世の中のData Scientistたちが作ったコードをお互いに共有したり、
競争したりするデータ分析プラットホームです。
それ以外は、ある会社が直面している問題および投資する技術の課題をあげて、
誰かが解決し、問題の正答に一番近い人に賞金を与えるコンペティションも行われています。
それで、初心者ができることは
筆者はWeb engineerなので、データ分析なんてやったこともないですが、
色々探した結果、Titanic: Machine Learning from Disasterという初心者向けコンペティションを見つけました。
ちなみに、コンペティションに関して補足すると、
普通はある期間内にデータ分析をやりますが、
今回のTitanicは期間がないので、気軽に参加できます。
では、早速始めましょうー
Kaggleを始める
必要なもの
-
Kaggleに接続してアカウントを作成してください。(すごく簡単)
-
JupyterNotebook インストール(anacondaでもいいし、ひとまず、JupyterNotebookであればOK)
-
ヤル気
コンペティションに参加する
Titanic: Machine Learning from Disasterに入るの下記のようにメインページに移動します。
このコンペティションのゴールはtitanicの生存者予測することです。
このように詳細情報の確認ができますが、筆者はすでにコンペティションに参加しているので、
右上の青いボタンに「Submit Predictions」となっていますが、
始めの方は「Join Competitions」が表示されるので、クリックして参加します。
データ確認
どのデータで分析するかを確認するために、Dataラベルに移動します。

今回使うデータを簡単に説明すると下記のようになります。
- train.csv(891人の生存結果がある乗客リスト)
- test.csv(418人の生存結果不明の乗客リスト)
train.csvを予測したモデルを基づいてtest.csvの生存結果を予測することになります。
他に必要な情報はカラムそれぞれがもっている意味です。
- Survival:生存結果、0(死亡)、1(生存)
- Pclass:チケットレベル、1等席、2等席、3等席
- Sex:male、female
- Age:nullある、小数ある
- SibSp:一緒に乗った兄弟(siblings)と配偶者(spouses)の人数
- Parch:一緒に乗った親(parents)と子供(children)の人数
- Ticket:チケット番号(text)
- Fare:金額
- Cabin:客室番号、nullある
- Embarked:船着場、Cは(Cherbourg)フランス地域, Qは(Queenstown)イギリス地域, Sは(Southampton)イギリス地域
データ分析
まず、データ分析する前に、生存者のタイプを考えてみましょう(仮説)。
理由はPython書く時に説明します。
普通災難映画をみると、女性・子供・お金持ちから救助するのをよくみるので、
この条件でデータ分析を行うと思います。
データ準備
これから実際にJupyterNotebookを使ってみます。
Pythonのデータ集計や操作するためにPandasを使います。
# pandas宣言
import pandas as pd
上記に説明したtrain.csvとtest.csvをよんでおきます。
# train data load(csvFileのPath気をつけてください)
train = pd.read_csv("train.csv", index_col = "PassengerId")
# 出力確認
print(train.shape)
# Macの場合 ctrl + Enterで実装 or Runボタンをクリック
train.head()

上記のように5行が表示されます。
次はtest.csv
# test data load
test = pd.read_csv("test.csv", index_col = "PassengerId")
# 出力確認
print(test.shape)
test.head()
データ視覚化
上記で説明した通りに、性別(Sex)、年齢(Age)、金額(Fare)で分析すると書きましたが、
実際にこのようなデータで生存予測ができるか確認しないといけないです。
方法は色々ありますが、今回はSeabornというPythonのデータ視覚化ツールでやってみます。
# Seaborn宣言
import seaborn as sns
# Seabornのリンクを確認するといろんな視覚化の例があるので、
# 必要だと思うAPIを使う
sns.countplot(data=train, x="Sex", hue="Survived")

確認してみるとfemaleがmaleより生存率が高いことがわかります。
# 年齢と料金の関連性を確認
sns.lmplot(data=train, x="Age", y="Fare", hue="Survived", fit_reg=False)

オレンジ色のところは生存率が高い
一方で青色のところは生存率が低いことがわかります。
Y軸(Fare)が100以上だと、点が少ないため、ひとまず、その以上のデータをなくしてみます。
# 200以上の生存率は少ないため、 100以下のデータで行う
# その後、sns.lmplotでまた確認する
low_fare = train[train["Fare"] < 100]
Preprocessing
上記の分析が終わったら、データ予測モデル作業をやってみます。
データをDecisionTreeのMachine Learningアルゴリズムに格納するために、
データをMachine Learningアルゴリズムが読み取れる形で変換しないといけないです。
その過程をPreprocessingと言います。
ちなみに、DecisionTreeを簡単に説明すると、意志決定を助けることを目的として作られたアルゴリズムで、主にゴールに一番近いものを探すために使うということです。
では、性別のPreprocessingから始めます。
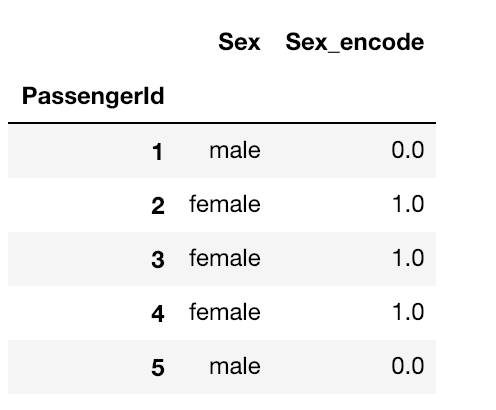
今のデータはtextタイプになっているが、DecisionTreeが理解できるように、数字を入れる作業が必要になります。なので、maleは0、femaleは1を入れてみます。
# Sex_encodeというカラムに性別を数字で格納
train.loc[train["Sex"] == "male", "Sex_encode"] = 0
train.loc[train["Sex"] == "female", "Sex_encode"] = 1
print(train.shape)
train[["Sex", "Sex_encode"]].head()
test.csvにも適用します。
test.loc[test["Sex"] == "male", "Sex_encode"] = 0
test.loc[test["Sex"] == "female", "Sex_encode"] = 1
print(test.shape)
test[["Sex", "Sex_encode"]].head()
次は、金額のPreprocessing作業をします。
上にはDecisionTreeが理解できるように、数字を入れる作業を行いましたが、
それ以外にも空はエラーになるので、値を埋める作業も一緒に行うべきです。
# 両方確認したら、test.csvのみ空になっていた
train[train["Fare"].isnull()]
test[test["Fare"].isnull()]

# NaNに値を埋めるために、Fare_fillinカラムを作成
train["Fare_fillin"] = train["Fare"]
# test.csvにも適用する
test["Fare_fillin"] = test["Fare"]
# FareがNaNになっている乗客を検索後、0を入れる
test.loc[test["Fare"].isnull(), "Fare_fillin"] = 0
# 0が入っているか確認
test.loc[test["Fare"].isnull(), ["Fare", "Fare_fillin"]]

最後に、年齢のPreprocessing作業をします。
先ほどデータ視覚化のように、生存率高かった20歳以下で絞り込みます。
# Age 20歳以下を学生とする
train["Student"] = train["Age"] < 20
print(train.shape)
train[["Age", "Student"]].head(5)

# test.csvにも適用する
test["Student"] = test["Age"] < 20
print(test.shape)
test[["Age", "Student"]].head(5)
少し長くなりましたが、今までの作業を改めてまとめると
性別(Sex)、金額(Fare)、年齢(Age)のPreprocessing作業を行いました。
機械学習
DecisionTreeを学習させるために、二つのデータタイプが必要です。
- Label:Target Variableと言われ、正解を求めるカラムを入れるところ(今回の場合 Survivedになる)
- Feature:Labelを得るために、役に立つ値を入れるところ(今回の場合、性別、年齢、金額になる)
そして、データタイプを作るために、三つの形で行います。
- X_train: trainデータのfeature
- X_test: testデータのfeature
- y_train: trainデータのlabel
label_name = "Survived"
label_name
# feature_namesにFeatureとして使うカラムを格納
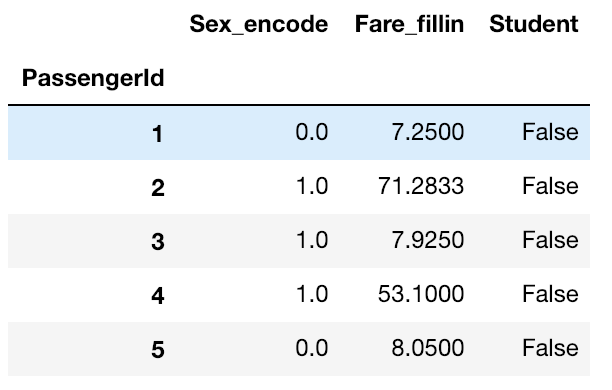
feature_names = [ "Sex_encode", "Fare_fillin", "Student"]
feature_names
# feature_namesでtrainデータのfeatureを取得
X_train = train[feature_names]
print(X_train.shape)
X_train.head()
# test.csvにも適用する
X_test = test[feature_names]
# label_name을でtrainデータのlabelを取得
y_train = train[label_name]
# scikit-learn(sklearn)の tree ModuleからDecisionTreeClassifierを取得
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth=8, random_state=0)
# DecisionTreeClassifierを学習
# fit という機能でtrainデータのfeature(X_train)とlabel(y_train)を入れる
model.fit(X_train, y_train)
# fitが終わったら、predictの機能でSurvivedを予測する
# その後、testデータのSurvivedを返して、predictionsという変数に格納
predictions = model.predict(X_test)
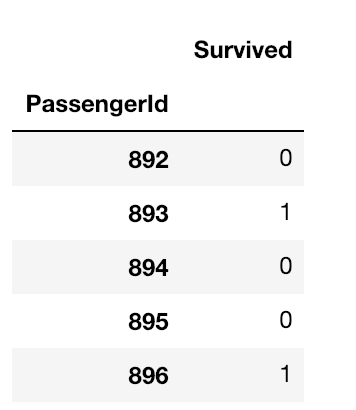
# Kaggleが提供している提出向けcsvを読み取る
# PassengerIdは testデータと一緒で, Survivedはmale(0), female(1)が入っている
submission = pd.read_csv("gender_submission.csv", index_col="PassengerId")
print(submission.shape)
submission.head()
# kaggleに提出するcsv作成
submission.to_csv("submit_181210.csv")
Kaggleに結果を提出
Submit Predictionsページに移動して、先ほど作成したcsvをUploadします。
そして、Make Submissionをクリックすると提出されます。

その結果

ちまにみ、1に近いほど高い点数になりますが、
まぁ、この点数で満足します。:)
おまけ
もっと高い点数になるためには
Kaggleのページをみるとkernelsやdiscussionのラベルで、
いろんな方法で解決している内容があるので、参考になると思います。
あと、Preprocessingする前に、
いくつかの仮説を立てましたが、いろんなカラムがあるので、
例えば、チケットレベル(Pclass)の上の等席が生存率高いなのか
SibSp、Parchの家族関連で何かの関連性があるのかなど
いろんな方法でアプローチできるかと思います。
まとめ
Kaggleをやってみて、非常に勉強になったところはPandasでした。
文法はもちろん、データの集計などの確認ができるので、
もし業務でExcelの資料をもらったら、Pandasを使ってまとめることができるのではないかと思いました。
そして、機械学習の認識が変わりました。
数学ができないと無理だとずっと思っていましたが、
実際にデータ分析のゴールにたどり着くまでに
それに合う機械学習モデルを見つけて、学習させたり、
また、別のモデルを探してみる面白さに気づきました。
参考
How should a beginner get started on Kaggle
決定木分析についてざっくりまとめ_理論編
機械学習(Machine Learning)とは?非エンジニアが振り返ってみた。