はじめに
こんにちは、この記事はUnipos Advent Calender 2021の16記事目です
UniposではデータをDataStoreとSpannerにもち、それらのデータを集計するためにBigQueryにデータを転送しています
この記事ではSpannerからBigQueryへのデータ転送について紹介します
公式ドキュメント に詳しいことは書いてありますが、このブログでは具体的な操作、具体的な値について書いていきます
事前準備
BigQuery Connection APIを有効にする
Spanner情報の追加
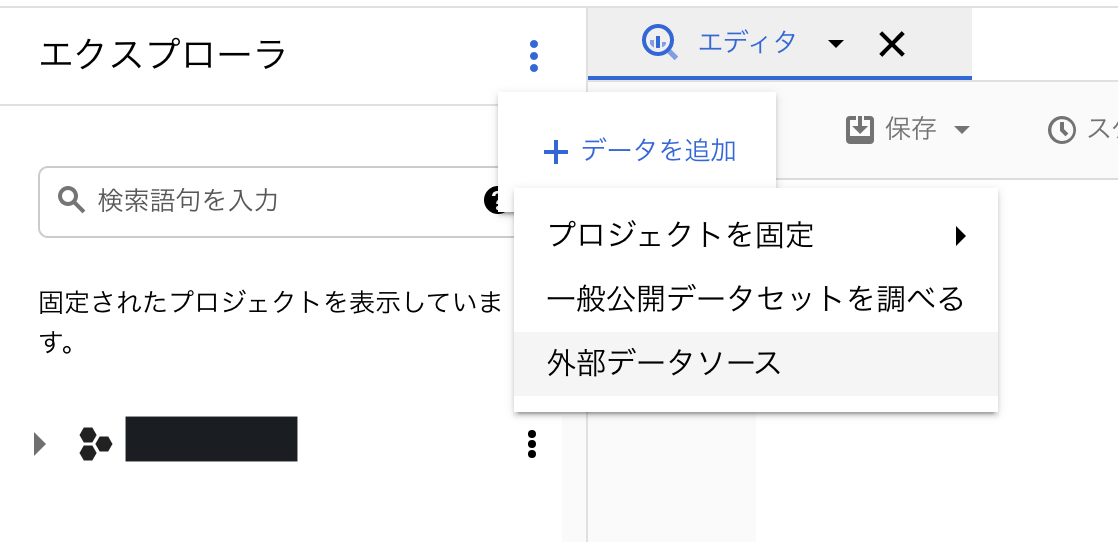
- BigQueryのエクスプローラの「3点リード」→「データを追加ボタン」→「外部データソース」の順にクリック
- 情報を入力する
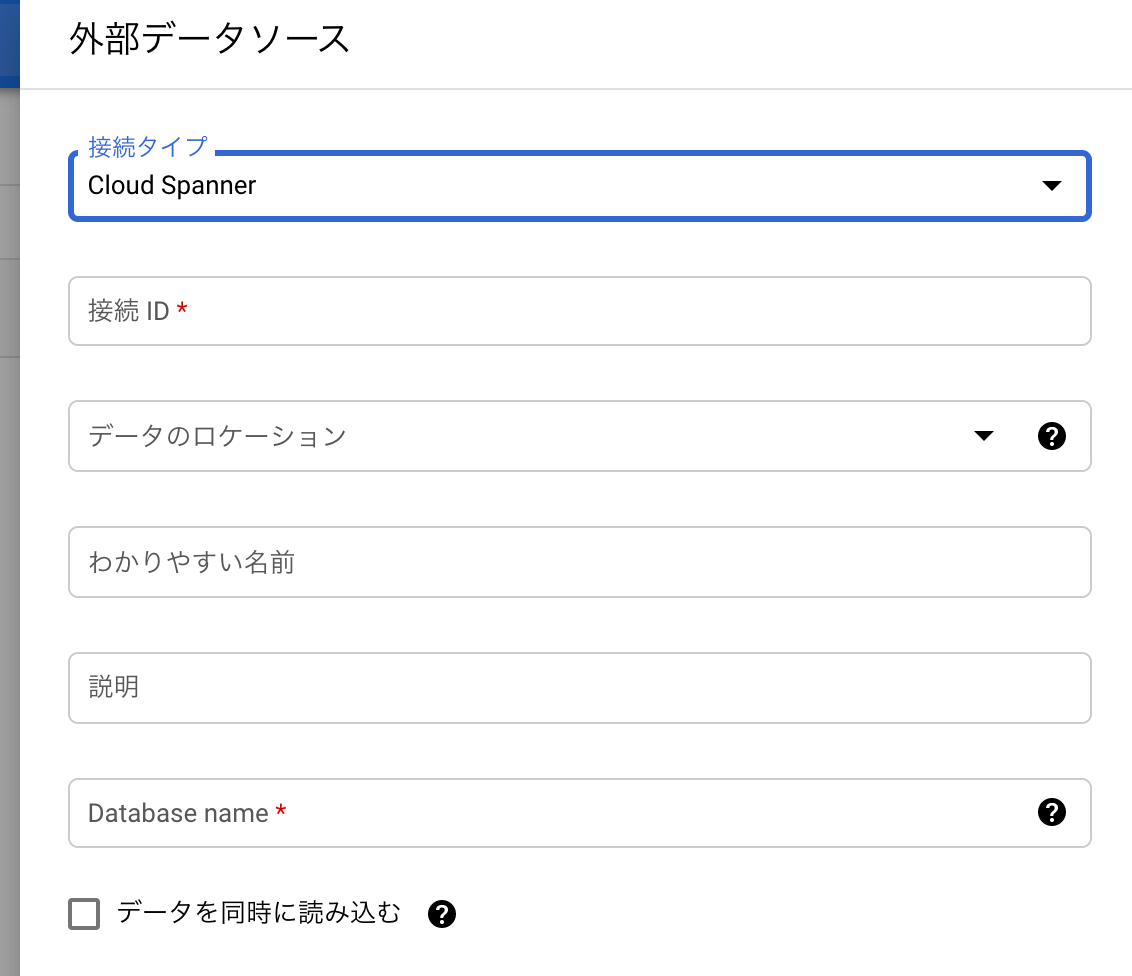
- 接続タイプ :
Cloud Spanner - 接続ID :
英数字、ダッシュ、アンダースコアで構成される文字列 - データのロケーション :
BQのロケーション - わかりやすい名前 :
表示名 - 説明 :
説明 - Database name :
projects/$PROJECT_ID/instances/$INSTANCE_ID/databases/$DATABASE_ID- Spannerの
$PROJECT_ID、$INSTANCE_ID、$DATABASE_IDを↑の文字に埋め込み入力
- Spannerの
- データを同時に読み込む : チェックがあると並列に実行してくれるが制約あり(注意点で後ほど詳しく説明します)
- 接続タイプ :
動かしてみる
先程の外部データソースの入力でIDをspanner-dbにしたとすると、
以下のようにしてSpannerからクエリすることができます
SELECT * FROM EXTERNAL_QUERY(
'asia-northeast1.spanner-db',
'''SELECT * FROM User'''
)
EXTERNAL_QUERYの第一引数で$location.$id、第二引数でSpannerで実行したいクエリを入力することで対象のSpannerDBでクエリを実行することができます
そして、クエリしてきたデータをBQにinsertすることもできます
注意点
SpannerとBQのTIMESTAMPの桁数の違い
SpannerのTIMESTAMPではナノ秒までの情報を持っていますが、BQではミリ秒までしか持っていません、なのでこのfederated queryを使ってSpannerからBQにデータ転送する場合、ナノ秒は切り捨てられてしまいます
「データを同時に読み込む」について
Spannerの情報入力で、「データを同時に読み込む」というチェックボックスがありましたが、書いてあるとおり、チェックを入れるとデータを並列に読み込んでくれます
ですが、チェックを入れることによって、実行できるクエリはクエリ実行プランの最初の演算子が分散ユニオンの場合のみになります
公式ドキュメントによると分散ユニオンとは「1つ以上のテーブルを複数のスプリットに分割し、各スプリットのサブクエリをリモートで個別に評価してから、すべての結果を結合」するものです
つまりは最初の処理を分散できるものはデータを同時に読み込めるが、できないクエリに関してはエラーになります
select * from User where Age > 20
のような単純なクエリであれば問題はないですが、
select ID from User where Age > 20 union all select ID from SpecialUser where Age > 20
のようなクエリだと実行することができません