画像認識モデルを作成しているともう少し速くしたい、なぜか遅いと思うシーンがあります。
訓練時、推論時、どちらを速くしたいかによって取れるアプローチは異なりますが、いずれにせよどこに時間がかかっているかの計測が助けになることは多いです。
今回は処理時間解析の簡便な方法であるTensorflow Timelineの使い方と注意点について記載します。
計測環境
以下の環境で実験を行っています。
| 項目 | 内容 |
|---|---|
| GPU | GTX 1070 |
| GPU Driver | 367.57 |
| CPU | Core(TM) i5-4440 物理4コア 論理4コア |
| Cuda | Cuda 8.0 cuDNN 5.1.5 |
| Tensorflow | Commit 48fb73a1c94ee2409382225428063d3496dc651e |
Timelineの取得
本家の関連するテストコード を見ていただくのが一番わかりやすいです。
要点だけ抜粋すると、
import tensorflow as tf
from tensorflow.python.client import timeline
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
_, loss_value = sess.run([train_op, loss],
options=run_options,
run_metadata=run_metadata)
step_stats = run_metadata.step_stats
tl = timeline.Timeline(step_stats)
# Tensorの利用メモリもshow_memory=Trueでとれるが割愛
ctf = tl.generate_chrome_trace_format(show_memory=False,
show_dataflow=True)
with open("timeline.json", "w") as f:
f.write(ctf)
のように書くことで、tf.Session.runにおける実行時の時間利用状況がtimeline.jsonに出力されます。
なお、実際に計測する際は、何回か通常のsess.runしてから計測してください。起動直後に計測を行ってしまうと、初期化処理やQueueへのデータ追加処理等の影響によって、実情とは異なる時間利用状況を取得してしまいます。
Viewer
timeline.jsonを閲覧するにはChromeを用います。Chromeを起動し、chrome://tracing/ とURLバーに入力するとViewerが起動します。
Viewer上で、先ほど出力したtimeline.jsonをLoadすると、Timelineが表示されます。
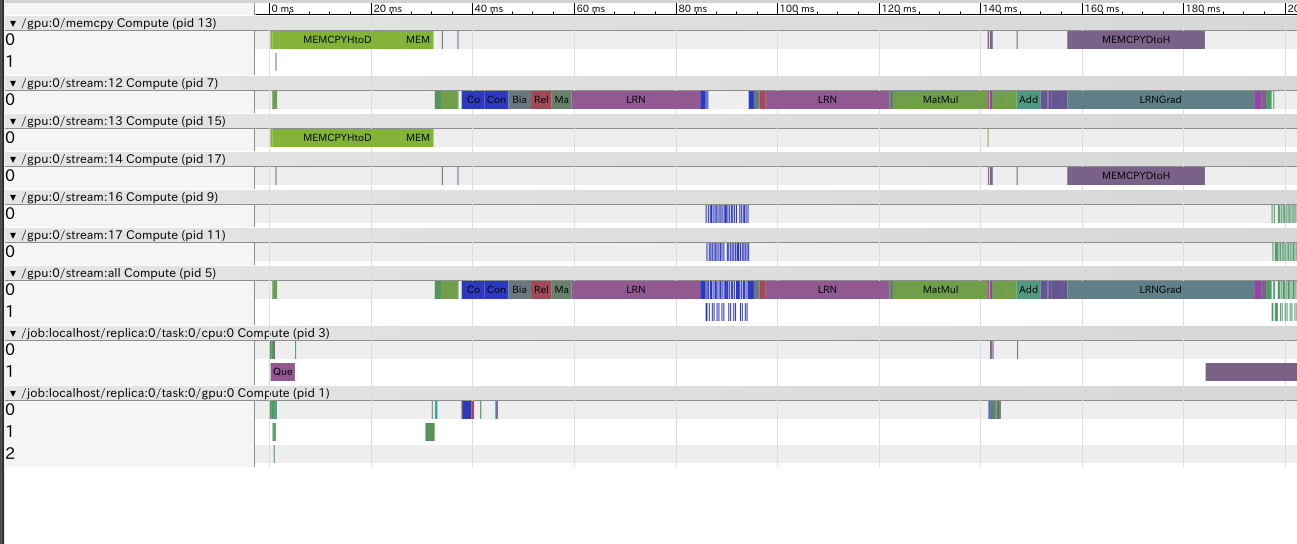
上記は、公式のcifar10サンプルを少し改造したモデルから取得したTimelineです。
Viewerの操作方法はいじっていれば大体わかります。
Timelineの各行はデバイスやCUDA Streamに対応します。(CUDA Streamに関してはこちらなどを参照してください)
例えば
- /job:localhost/replica:0/task:0/cpu:0 CPU上で行われる処理
- /job:localhost/replica:0/task:0/gpu:0 1枚目のGPU上で行われる処理
- /gpu:0/stream:12 1枚目のGPU上のstream id 11のCUDA Streamで行われる処理
となります。上記の例では、LRN(Local Response Normalization)関連の処理(LRN, LRNGrad)が重いことがわかります。LRNをネットワークから外すと速くなりそうです。
Timeline詳細
ここからは筆者が動作とソースコードから類推した内容です。誤りを含む可能性があります
/job:localhost 系の詳細
Timelineの/job:localhost からはじまる行は、Tensorflowの各デバイスで行われる処理をまとめています。
Sessionのコンストラクタ引数のlog_device_placementをTrueにすると、デバイスとデバイス名の対応や、どのOperatorがどのデバイスで処理されるかがコンソールに出力されます。
下は/job:localhost/replica:0/task:0/gpu:0 がGTX1070に対応することを示したログです。また、Size オペレーターがCPU上で実行されていることがわかります。
/job:localhost/replica:0/task:0/gpu:0 -> device: 0, name: GeForce GTX 1070, pci bus id: 0000:01:00.0
I tensorflow/core/common_runtime/simple_placer.cc:827] input_producer/Size: (Const)/job:localhost/replica:0/task:0/cpu:0
Timelineにおいて、/job:localhost/replica:0/task:0/gpu:0 Compute (pid1)のようにデバイス名の横に表示されるpidは便宜上割り振られたもので、実際のプロセスIDではありません。
また、各行を展開した際に、「0」「1」という行が表示されます。それぞれの行はスレッドに対応しており、スレッド0とスレッド1は並列に動作可能です。
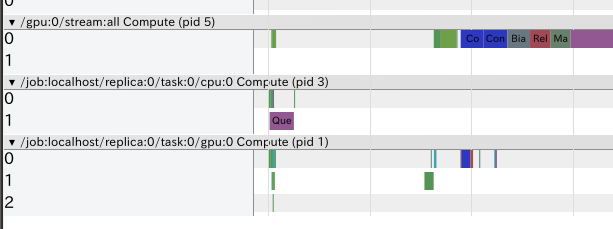
/job:localhost/replica:0/task:0/gpu:0 のように、GPUデバイスに対応する行は、GPUでの実行時間ではなく、CPUからGPUオペレーターの起動処理(GPUカーネルの起動など)にかかった時間を表しています。実際にGPUカーネルの実行にかかった時間は/gpu:0/stream:12のような行で示されています。
これらデバイスで行われる処理の時間は、多くはtensorflow/core/common_runtime/executor.cc L1365付近で収集されています。(非同期な処理を除く)
if (stats) nodestats::SetOpStart(stats);
device->Compute(CHECK_NOTNULL(op_kernel), &ctx);
if (stats) nodestats::SetOpEnd(stats);
/gpu:0/stream 系の詳細
Timelineの/gpu:0/stream からはじまる行は、GPUの各CUDA Streamで行われる処理時間を表しています。例えば、/gpu:0/stream:12は、0番目のGPUのStream ID 12を持つCUDA Stream上で各処理にかかった時間を表しています。
ただしstream:all は各streamでの処理をすべてまとめて記載したものです。
2枚目のGPUで処理された場合は、本来は/gpu:1/stream:* と表示されるべきですが、現在は、/gpu:0/stream:と表示されてしまいます。この問題は、ソースコード中にTODOとして記載されています(tensorflow/core/common_runtime/gpu/gpu_tracer.cc L559)。ちょっとソースコードをいじると、gpu:1と正しく表示されるようになるので、どうしても必要な場合は、書き換えてもよいかも?
CUDA Streamで行われる処理の時間はtensorflow/core/common_runtime/gpu/gpu_tracer.cc L583付近で収集されています。計測自体はCUDAの機能を用いて行われています(gpu_tracer.cc L526)。
環境によっては、CUDA Streamからの情報収集はなぜか失敗した経験があります。再起動をすると収集に成功するケースもあり、不安定な挙動を示していましたが、原因は究明できていません。
事例
Timelineを用いることで役に立った事例をいくつか紹介します。
ネットワーク構成の変更
典型的なTimelineが役に立つケースは、処理時間をもう少し削りたいときにネットワーク構成のどこを変更するか決めるときです。
私がネットワークを縮小する必要に迫られた際は、入力サイズが大きい第一層のチャンネル数を減らすことで計算時間が縮小できるのでは? と予想していました。しかし、Timelineを用いた結果、入力チャンネル数が大きい第二層の方が処理時間が長いことがわかったため、そちらのチャンネル数を減らすことで対応しました。
マルチGPU処理のデバッグ
2枚のGPUで学習を行うプログラムを書いた際、GPU使用率が低い値で推移してしまうことがありました。Timelineを表示してみると、GPU間で本来必要のない通信が行われていることがわかりました。原因は確かCPUに確保すべき変数をGPUに確保していたことだったと思います。これを修正することで、パフォーマンスとGPU使用率が向上しました。
また、1枚のGPU上に独立した複数のネットワークを構築することでパフォーマンスが向上するのでは? という仮説を検証した際も、Timelineは役に立ちました。Timeline上で確認すると、GPU上で行われる計算処理は単一のCUDA Streamで実行されており、GPU上で並列処理されないことがわかりました。なお、ひとつのCUDA Streamにまとめられてしまう理由は、StackOverflowで事情が語られています。
Operator配置の判断
画像を縮小してからGPUに送るか、画像を送ってからGPUで縮小するかの判断が難しいケースがありました。Timelineを表示することで、GPUで縮小することによって得られるメリットよりも、大きい画像を転送するデメリットと、大きい画像をQueueDequeueManyするデメリットの方が大きいことがわかり、CPUで縮小する決定がくだせました。
なお、Tensorflowのdequeueに関する議論はIssuesでも行われており、この周辺のIssueは結構勉強になります。
QueueDequeueManyが長いケース
Timelineを使っているとたまに目立つのがQueueDequeueManyが処理時間の大半を占めるケースです。
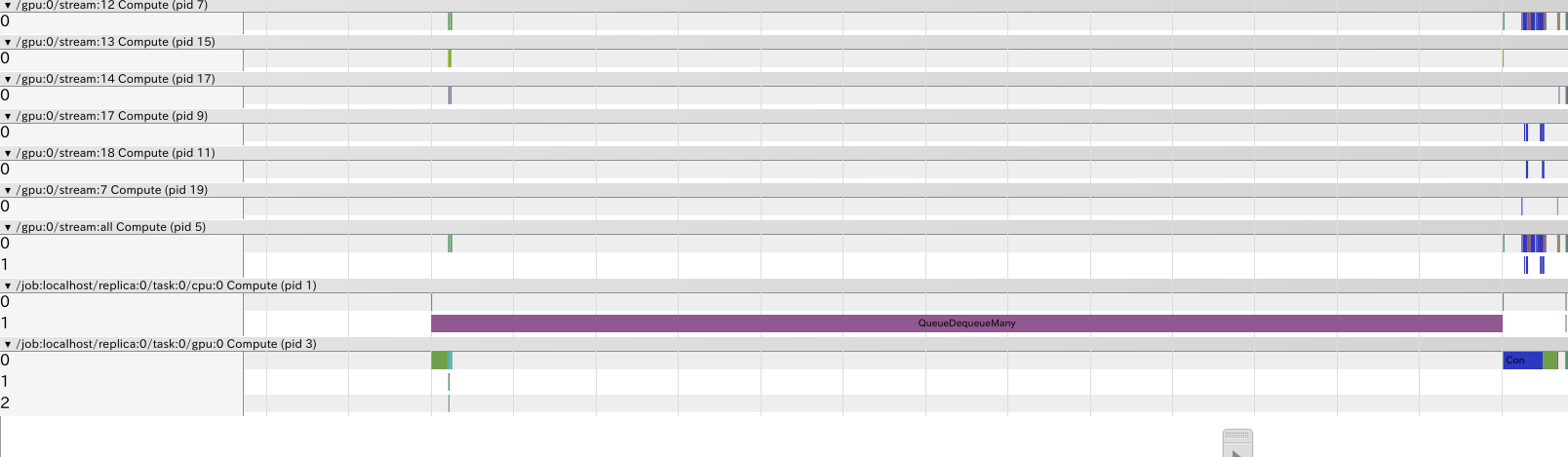
これはQueueDequeueManyの処理が重いわけではありません。QueueDequeueManyはQueueからTensorを取り出す際に、TensorがQueueに含まれていないとEnqueueされるまで待機します。この待機時間がQueueDequeueManyの処理時間に含まれてしまうため、あたかもQueueDequeueManyが重い処理に見えてしまいます。
実際は、QueueへのEnqueueが間に合っていないことが処理時間を伸ばしている原因なので、Enqueue前の処理、例えば画像の前処理などが重すぎないか、あるいはEnqueueするスレッド数が少なすぎないかなどの確認が必要です。
なお、Enqueueが間に合っているかどうかの確認は、もしbatchやshuffle_batchの内部Queueが対象であればTensorboardから確認する方が楽でお勧めです。
batch や_shuffle_batch_ は内部にキューを所持しており、下図ではそのキューの充填率が表示されています。
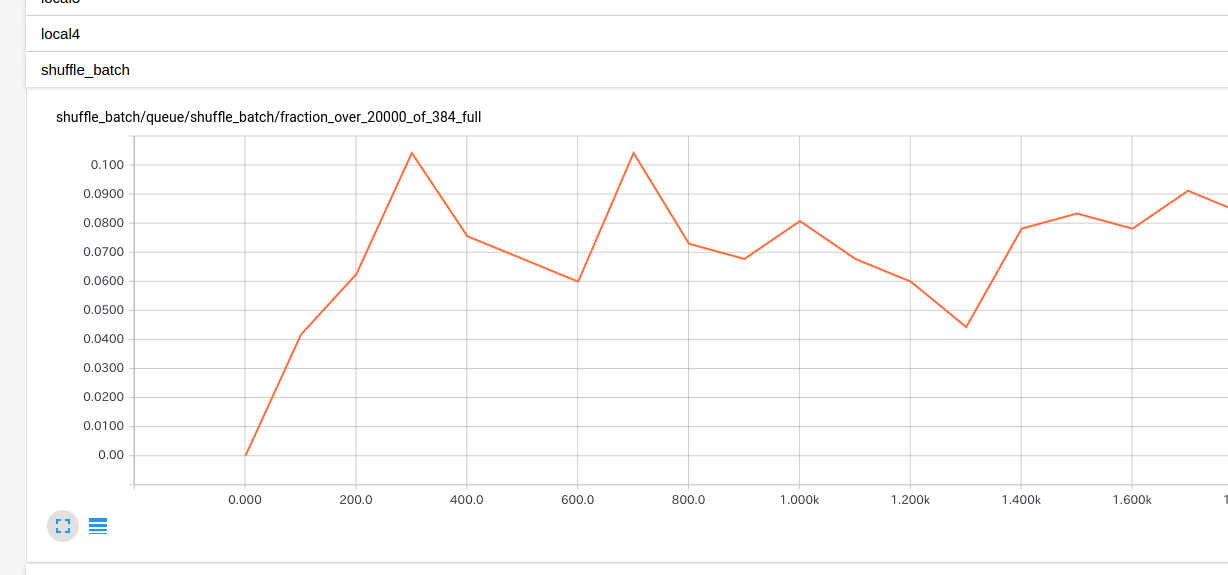
このグラフの値は、キューに入っているデータ数 ÷ キューのサイズ です(./tensorflow/python/training/input.py L682)。 これが小さい値のときはEnqueueが間に合っていないことが多いです。
まとめ
本記事ではTensorflowでのパフォーマンス解析についてTimelineを中心に記述しました。
最近はTensorboard上に統計情報を表示する方法等も出現してきていますが、Timelineの表示の方が今はまだ便利なように感じます。
手軽なわりに発見があって面白いTimelineの利用を一度はやってみてはいかがでしょうか。