概要
本記事はTensorflow1系に慣れている方を想定した、Tensorflow2におけるsummaryの使い方の解説です。
Tensorflow 2.0は、Eager Modeという強力な機構が入りましたが、パフォーマンスを改善するためには、@tf.functionによるGraph Modeを併用する必要があります。本記事では、EagerとGraph両方において意図した通りにsummaryを出す方法を解説します。
本記事はすべてtensorblow 2.0 beta1で検証を行っています。
Eagerモードでのsummary出力
基本編
もっとも基本的なsummary出力コードは以下のようになります。
import tensorflow as tf
writer = tf.summary.create_file_writer(logdir="log")
writer.set_as_default()
x = tf.Variable(1, name="x")
for i in range(100):
x.assign_add(1)
tf.summary.scalar("x", x, step=i, description="first variable")
tf.summary.create_file_writerとset_as_defaultを用いることで、それ以降のsummary出力先を指定することができます。その後、tf.summary.scalarで実行時のxの値を出力します。
TF1系との大きな違いは, scalarの引数にstepが入ったことでしょう。TF1系と異なり、global stepの概念が無くなっているため、個々の命令において何step目の出力か明記する必要があります。
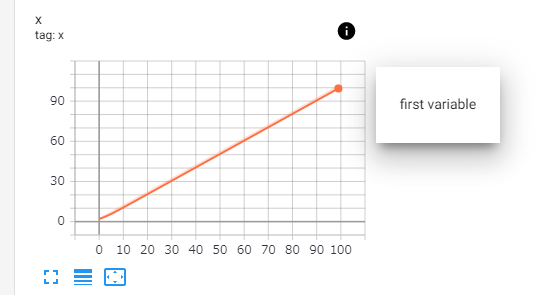
また、descriptionで出力の説明文を入れられるようになったのは面白い変化です。下図のようにTensorboard上でiボタンを押すと説明が見られるようになりました。
step指定の省略
ここのsummary.scalarにおいてstep数を明記するのは煩雑ですし、階層が深い関数では何step目かという情報を持っていないことがあります。そこでset_step関数を用いることで、デフォルトのstepを指定することができます。
for i in range(100):
x.assign_add(1)
tf.summary.experimental.set_step(i)
tf.summary.scalar("x", x, description="first variable")
set_stepは値ではなく参照を保持するため, ループ内で毎回set_stepする必要はありません。stepを表す変数をnumpy.arrayに
することで、ループ外で一度set_stepするだけでよくなります。
global_step = np.array(1, dtype=np.int64)
tf.summary.experimental.set_step(global_step)
for i in range(100):
global_step += 1
x.assign_add(1)
tf.summary.scalar("x", x, description="first variable")
ただし, global_stepは必ずtf.Variableやnumpy.arrayのようなmutableなオブジェクトを渡してください。もし, global_stepにただの数値をしてしまった場合, tf.summary.scalarはset_step時の値を参照し続けます。以下は不適切な例です。
global_step = 1
tf.summary.experimental.set_step(global_step)
for i in range(100):
global_step += 1
x.assign_add(1)
tf.summary.scalar("x", x, description="first variable")
summaryの階層化
summaryが増加した際に、たくさんのsummaryが並んでいると邪魔なので、summaryをいくつかのグループに分割することが可能です。スラッシュ/区切りのsummary名をつけることで、summaryはグループ化されます。
以下のコードではvariablesというグループに複数のsummaryをまとめています。
tf.summary.scalar("variables/x", x, step=i, description="first variable")
tf.summary.scalar("variables/y", y, step=i, description="second variable")
summary名に階層を入れる代わりに、summary_scopeを用いることも可能です。なお、summary_scopeではだけでなく、これまで通りname_scopeでもsummaryは階層化されます。
with tf.summary.experimental.summary_scope("variables"):
tf.summary.scalar("x", x, step=i, description="first variable")
tf.summary.scalar("y", y, step=i, description="second variable")
周期的にsummaryを出力する
summaryを学習の各iterationで出力すると、ログファイルサイズが膨大になってしまいます。そこで、100 iterationsごとに1度summaryを出力するような措置が必要になります。これをEagerで実現する、最も簡単な方法はif文をscalarの前に置くことです。以下は7 iterationsに1度summaryを出力しています。
x = tf.Variable(1, name="x")
global_step = tf.Variable(1, dtype=tf.int64)
tf.summary.experimental.set_step(global_step)
for i in range(100):
global_step.assign_add(1)
x.assign_add(1)
#if global_step % 7 == 0:
if tf.equal(global_step % 7, 0):
tf.summary.scalar("x", x, description="first variable")
重要なのはglobal_step%7 == 0 ではなく, equalを用いている点です。global_step%7 == 0とした場合, global_step%7はTensorを返す(global_stepがVariableなので)のですが、Tensorと数値の比較は常にFalseとなるため、summaryが一切出力されなくなります。
このif文を用いた方法は直感的であるものの、summaryの数が増えると管理が面倒になります。そこでもっとも現実的な方法は、record_ifを用いる方法です。ソースコードを見ると大体使い方がわかります。
should = lambda : tf.equal(global_step % 7, 0)
with tf.summary.record_if(should):
for i in range(100):
global_step.assign_add(1)
x.assign_add(1)
tf.summary.scalar("x", x, description="first variable")
record_ifに与えた関数が、summaryの呼び出しのたびに評価され、結果がTrueになるとsummaryが出力されます。実はrecord_summaries_every_n_global_stepsという関数を使えばもっと簡潔に記述できるのですが、API一覧に記載されていないため、あまり使わない方が良いと思います。
from tensorflow.python.ops.summary_ops_v2 import record_summaries_every_n_global_steps
with record_summaries_every_n_global_steps(7, global_step):
for i in range(100):
global_step.assign_add(1)
x.assign_add(1)
tf.summary.scalar("x", x, description="first variable")
Graphモードでのsummary出力
Graphモードでのsummary出力も、基本はEagerモードと同様です。以下を実行すると、y のsummaryが記録されます。
@tf.function
def process(x):
y = x * 10
tf.summary.scalar(name="y", data=y)
return y
writer = tf.summary.create_file_writer(logdir="log")
writer.set_as_default()
global_step = tf.Variable(0, name="global_step", dtype=tf.int64)
tf.summary.experimental.set_step(global_step)
x = tf.Variable(1, name="x", dtype=tf.int64)
for i in range(100):
x.assign_add(1)
global_step.assign_add(1)
y = process(x)
一見すると、ほぼEagerモードと同様に動作するように見えますが、実はEagerモードにない制約が増えています。global_stepをtf.Variableでなくnp.arrayにした場合、正常に動作しません。np.arrayを用いるとprocess関数中のsummary.scalarのstepは最初にprocessが呼び出されたときの値で固定されてしまいます。
以下のコードは、Graphモードでは正常にsummaryが出力されませんが、tf.functionをコメントアウトしEagerモードに
すると正常に動作する例となっています。
@tf.function
def process(x):
y = x * 10
tf.summary.scalar(name="y", data=y)
return y
writer = tf.summary.create_file_writer(logdir="log")
writer.set_as_default()
global_step = np.array(0, dtype=np.int64)
tf.summary.experimental.set_step(global_step)
x = tf.Variable(1, name="x", dtype=tf.int64)
for i in range(100):
x.assign_add(1)
global_step += 1
y = process(x)
Graphモードにおける周期的なsummary出力
周期的なsummary出力でも、Eagerモードと比較してGraphモードでは制約が増えています。以下はEagerモードでの例と同様に、7回に1回summaryを出力するコードです。
@tf.function
def process(x):
y = x * 10
tf.summary.scalar(name="y", data=y)
return y
writer = tf.summary.create_file_writer(logdir="log")
writer.set_as_default()
global_step = tf.Variable(0, name="global_step", dtype=tf.int64)
tf.summary.experimental.set_step(global_step)
x = tf.Variable(1, name="x", dtype=tf.int64)
should = lambda: tf.equal(global_step % 7, 0)
with tf.summary.record_if(should):
for i in range(100):
x.assign_add(1)
global_step.assign_add(1)
y = process(x)
こちらも先ほどと同様、global_stepをnumpy.arrayにすると動作しなくなるため注意してください。
なぜこのように動作するのか
TF1系に慣れていないと上記の動作は少し不可解に思えるかもしれません。このようにglobal_stepの型がnumpyのときとtf.Variableのときとで動作が変化するのは、@tf.functionがついた関数の初回呼び出し時に計算グラフが構築され、以降の関数呼び出しでは構築された計算グラフが実行されるためです。
この計算グラフ構築時に、numpyでglobal_stepを渡すと、計算グラフ中では定数として扱われます。一方でtf.Variableで渡すと、計算グラフの実行のたびに値が評価されます。
まとめ
本記事ではTensorflow2.0でのsummaryの基本的な出し方を解説しました。
TF1系と比較すると難しくなったようにも見えますが、TF1系でもsummary周りはわりと難しかったので、慣れればこれはこれでありだと思います。