#はじめに
LightGBMの次はRandomForestを使います。諸事情があって両者とも決定木系を選択しました。アンサンブル学習を見据えるとLightGBMの次はK-NN、ニューラルネットなど系統が異なるモデルを使う方が良いかもしれません。正解率は0.79186でした。
!pip install pydotplus
%matplotlib inline
from sklearn.preprocessing import OrdinalEncoder
from sklearn.model_selection import StratifiedKFold, GridSearchCV
import matplotlib.pyplot as plt
import pandas_profiling
import seaborn as sns
import numpy as np
import pandas as pd
# 決定木
import pydotplus
from sklearn.tree import DecisionTreeClassifier
from IPython.display import Image
from sklearn import tree
# ランダムフォレスト
from sklearn.ensemble import RandomForestClassifier
train = pd.read_csv("/kaggle/input/titanic/train.csv")
test = pd.read_csv("/kaggle/input/titanic/test.csv")
pid = test["PassengerId"]
# 訓練データフラグを設定
train["IsTrain"] = True
test["IsTrain"] = False
# 欠損補完用にtrain,testを結合
dataset = train.append(test)
# PassengerId列の削除
dataset.drop("PassengerId",axis=1, inplace = True)
#欠損補完
LightGBMの時は補完する特徴量は1つでしたが、今回は3つ補完します。
・欠損している特徴量
Cabin:1014、Age:263、Embarked:2、Fare:1
・補完する特徴量
AgeBand、Embarked、FareBand
Age, Fareはビニングして新たな特徴量にしてから補完します。試行錯誤した結果、連続値より離散値の方が良い精度が出たのでこのように対応しました。Cabinは補完方法を考えるのに時間がかかりそうだったので一旦後回しにします。
##年齢幅(AgeBand)
Mr, Msなどの敬称ごとに平均年齢を算出しAge_bandを求めて補完していきます。
まずは、Name列から敬称列を作成します。次に、フランス語の敬称が混ざっているので英語に置き換えます。Mlle(お嬢様)⇒Miss(未婚女性), Mme(既婚女性)⇒Mrs(既婚女性)
# 敬称列を全データセットに追加
titles = pd.Series(dtype="object")
for fullname in dataset["Name"]:
title = pd.Series(fullname.split(", ")[1].split(".")[0]) # 空白削除が必要
titles = titles.append(title)
titles.reset_index(inplace=True, drop=True)
dataset.insert(3,"Title",titles)
#敬称を英語に統一
dataset["Title"] = dataset["Title"].replace("Mlle","Miss")
dataset["Title"] = dataset["Title"].replace("Mme","Mrs")
③LightGBMに記載されているものとほとんど同じ操作ですが、敬称ごとの人数、平均年齢を算出します。
def cal_age():
t_num = pd.DataFrame(dataset.groupby('Title').count()["IsTrain"]).sort_values("IsTrain", ascending=False)
t_num["Ratio"] = (t_num["IsTrain"] / t_num["IsTrain"].sum()).round(2)
ave_age = pd.DataFrame(dataset.groupby('Title').mean()["Age"])
df = pd.concat([t_num, ave_age], axis=1)
df = df.rename(columns={'IsTrain':'Count', 'Age':'Ave_age'}).reset_index()
return df
t_num = pd.DataFrame(dataset.groupby('Title').count()["IsTrain"]).sort_values("IsTrain", ascending=False)
t_num["Ratio"] = (t_num["IsTrain"] / t_num["IsTrain"].sum()).round(2)
ave_age = pd.DataFrame(dataset.groupby('Title').mean()["Age"])
df = pd.concat([t_num, ave_age], axis=1)
df = df.rename(columns={'IsTrain':'Count', 'Age':'Ave_age'}).reset_index()
dic = {"Capt":"船長","Col":"大佐","Sir":"男性","Major":"少佐","Lady":"夫人"
,"Rev":"聖職者","Dr":"医者、博士号","Don":"高位聖職者","Jonkheer":"貴族(オランダ語)","Mrs":"既婚女性","the Countess":"伯爵"
,"Mr":"男性","Ms":"女性全般","Mlle":"お嬢様(フランス語)","Mme":"既婚女性(フランス語)","Miss":"未婚女性","Master":"少年"}
df.insert(1,"Japanese",df["Title"].map(dic))
# 敬称の占める割合の降順
df.sort_values("Ratio",ascending=False).head()
 Mr,Mrs,Miss,Masterが全体の95%以上を占めていました。データ数が少ないものは信頼性が少ないので、それ以外をOthersとして再集計します。信頼区間推定しておけばよかったと思いました。
Mr,Mrs,Miss,Masterが全体の95%以上を占めていました。データ数が少ないものは信頼性が少ないので、それ以外をOthersとして再集計します。信頼区間推定しておけばよかったと思いました。
# Mr,Mrs,Miss,Masterその他をOthersとして再集計
dataset["Title"] = dataset["Title"].map(lambda x: x if x in ("Mr","Mrs","Miss","Master") else "Others")
title_age = cal_age()
title_age_band, new_feature = make_age_band(title_age, "Ave_age")
title_age_band.head()

敬称ごとのAgeBandで補完します。
d = dict(zip(title_age_band["Title"], title_age_band["AgeBand"]))
dataset.loc[dataset["Age"].isnull(),"AgeBand"] = dataset.loc[dataset["Age"].isnull(),"Title"].map(d)
##出港地(Embarked)
出港地は乗客クラスに関係があるかもしれないと考えてクロス集計しました。
# クロス集計
pcls_emb = pd.crosstab(train['Pclass'],train['Embarked'],normalize='index')
display(pcls_emb)
欠損している人はPclass=1なのでその時の最頻値Sで補完します。

# 補完
dataset['Embarked'] = dataset['Embarked'].fillna("S") # 最頻値の場合は複数の値を返す可能性があるため[0]が必要
##料金幅(FareBand)
乗船料金はチケットクラスに関連がありそうなので、チケットクラスごとの料金を確認します。
sns.barplot(x="Pclass", y="Fare", data=dataset) # エラーバーは95%信頼区間
plt.show()
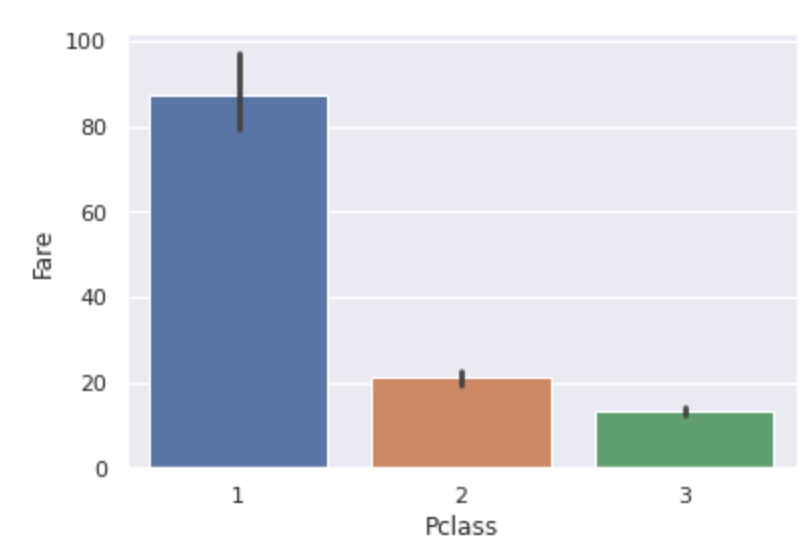
Pclassが下流階級になるほど料金が安くなっています。単なる平均値ではなくチケットクラスごとの平均値で補完することにします。欠損している人のチケットクラスは3でした。
fare = dataset.loc[dataset['Pclass'] == 3, "Fare"].mean()
fare_df = pd.DataFrame(pd.Series(fare), columns={"Fare_mean"})
fare_df, new_feature = make_fare_band(fare_df, "Fare_mean")

Pclass=3の平均値の料金幅で補完します。
dataset['FareBand'] = dataset['FareBand'].fillna(fare_df.loc[0, "FareBand"])
#データの準備
# 便宜上使用する特徴量
f1 = ["Survived","IsTrain"]
# 予測のための特徴量
f2 =["Sex","Pclass","Embarked","IsCabinNan","Family","IsAlone","AgeBand","IsAgeNanEst","FareBand"]
# 全データの更新
dataset = dataset[f1 + f2]
#ラベルエンコーディング
la_en = ["Sex","Embarked","IsCabinNan","IsAlone","AgeBand","IsAgeNanEst","FareBand"]
# ラベルエンコーディング
oe = OrdinalEncoder()
encoded = oe.fit_transform(dataset.loc[:,la_en].values)
dataset.loc[:,la_en] = encoded
# 訓練用データの抽出
train = dataset[dataset["IsTrain"]==True].drop(["IsTrain"],axis=1)
# ラベルと訓練用に分割
X_train = train.drop("Survived",axis=1)
y_train = train["Survived"]
X_test = dataset[dataset["IsTrain"]==False].drop(["IsTrain","Survived"],axis=1)
#モデルの構築と予測
# パラメータ設定
param_grid = {
"n_estimators":[1]+[i for i in range(10,110,10)], # 決定木の数
"max_depth":[i for i in range(1,18,3)],
}
skf = 3
# グリッドサーチ
model = GridSearchCV(estimator=RandomForestClassifier(),
param_grid=param_grid,
cv=skf) # 交差検証の回数
# 訓練
model = model.fit(X_train, y_train)
print("=====Model Parameters====",model.get_params,sep="\n")
print("=====Best Prameters====",model.best_estimator_,sep="\n")
print("=====Best Score====",model.best_score_,sep="\n")
=====Model Parameters====
<bound method BaseEstimator.get_params of GridSearchCV(cv=3, estimator=RandomForestClassifier(),
param_grid={'max_depth': [1, 4, 7, 10, 13, 16],
'n_estimators': [1, 10, 20, 30, 40, 50, 60, 70, 80, 90,
100]})>
=====Best Prameters====
RandomForestClassifier(max_depth=7, n_estimators=30)
=====Best Score====
0.819304152637486
検証データでスコアが0.819だったので十分と判断し、テストデータを予測してSubmitします。
# 予測
pred = model.predict(X_test).astype(int)
pred = pd.DataFrame({"PassengerId": pid, "Survived":pred})
pred.to_csv("submission_randomforest.csv", index=False)
#おわりに
特徴量をビニングし、欠損補完する対象を増やしRandom Forestで予測しました。正解率は0.79186という結果になりました。複数のモデルが出そろったのでアンサンブル学習に移ります。